
基于和声算法异构Hadoop集群资源分配优化
2014-04-03 01:44李锋刚魏炎炎杨龙
计算机工程与应用 2014年9期
李锋刚, 魏炎炎, 杨龙
Li Fenggang 1,2, Wei Yanyan 1,2,Yang Long1,2
1.合肥工业大学 管理学院,合肥 230009
2.教育部过程优化与智能决策重点实验室,合肥 230009
1. School of Management, Hefei University of Technology, Hefei 230009, China
2. Key Laboratory of Process Optimization and Intelligent Decision-making, Ministry of Education, Hefei 230009, China
1 引言
自2007年IBM宣布云计算计划之后,云成为目前工业界和学术界研究的热点,云计算的理念为计算资源公共化的商业实现,目前工业界有代表性的云计算实例有Google的云计算平台、IBM的“蓝云”、微软的Azure等[1]。在云计算的数据中心成千上万或者更多台计算节点或服务器组成计算集群,这样的集群有具大的处理能力,并且可以根据用户的需求动态分配计算或者存储资源,因此如何更有效的分配资源成为人们研究的问题。由于云计算是从网络计算演化而来,而在网络环境中资源分配问题又是人们研究的热点[2],并且云和网格在有一定的联系的基础上又存在很多异同,所以研究云环境中资源分配问题有一定价值。
MapReduce是云计算的编程模型和任务调试方式。Hadoop是Yahoo开发的MapReduce调试方式和GFS的开源实现。现有的Hadoop调度器都是建立在同构集群假设前提之下,并且没有考虑数据的区域性,但是实际情况并不是这样[3]。考虑不同处理机计算速度,不同机器之间数据传输以及因数据聚集带来I/O传输和网络消耗问题[4],如何在满足用户需求的条件下更好的分配资源成为一个重要问题,其分配策略的优 劣直接影响到云计算架构的工作性能和优越性。传统MapRedcue调度策略为一种事后的控制,当出现慢节点(straggler)之后,再通过启动备份任务的方法重新执行,虽然这种调度能普遍的提高响应时间,但是还存在一定的问题。本文考虑计算资源性能和其外部条件,利用和声搜索算法对该计算资源的响应时间进行预测,目的为分配合适的资源到合适的计算节点,以期望能够提高各个节点完成分配任务的时间并减少慢节点的产生,做到整体响应时间的最小化。
2 相关知识
作为分布式计算、并行计算和网格计算的发展,云计算是一种基于互联网的商业计算模式, 它将计算任务分布在大量计算机构成的资源池上,并且以抽象虚拟和动态增长的方式为用户提供需要的计算能力、存储能力或其他服务。按照服务类型云计算可以分为三大类:基础设施即服务(IaaS)、软件即服务(SaaS)和平台即服务(PaaS)[5]。
Hadoop是Apache开源组织的一个分布式计算框架,可在大量廉价的硬件设备组成的集群上运行应用程序,目前现有的Hadoop平台都是以集群的同构为前提,都假设在此集群中各节点的性能和处理能力完全一样、各节点外部环境如带宽或网络环境都完全一样[6]。
MapReduce是云计算中分布式计算编程模型,其应用也是非常的广泛,如在谷歌利用 MapReduce来做分布 Grep、分布排序、Web访问日志分析、反射索引构建、文档聚类、机器学习等[7]。MapReduce模型通过将输入数据分割为许多块,并对不同的块执行 Map和 Reduce操作来完成整体的任务。由于每个 Map操作都针对不同的原始数据,所以 Map操作之间可以保持较高的并行性。Reduce操作是对 Map操作所产生的结果进行合并,由于每个Reduce所处理的Map中间结果是互不交叉的,所以 Reduce操作也有一定的并行性。
如下对 MapReduce处理流程做简单介绍[5],并如图1所示:(1).MapReduce首先将输入文件分成 M块,每块大小为 16M~64M,每块大小可通过参数设定;(2).在处理操作中首先分配一个 Master(主控程序),Master选择空闲的 Worker(工作机)来分配 M个Map任务和R个Reduce任务;(3).每个分配了 Map任务的 Worker读取并处理Master分配给其的数据块,对数据块进行Map操作,并生成中间结果以
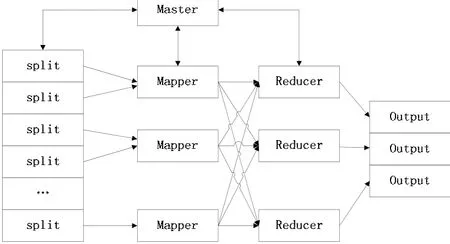
图1 MapReduce处理流程
下面对MapReduce容错机制给予分析:
由于 MapReduce是在成百上千台计算机上处理海量数据,所以需要有很好的容错机制来保持算法的稳定性和安全性。MapReduce的容错是基于“重新执行失败的操作”的原则而设计。Master节点是整个 MapReduce的核心,如果不进行任何容错机制,一旦 Master失效整个MapReduce操作将会前功尽弃。为了防止这种致命性的错误,Master节点会周期性设置检查点(Checkpoint)并导出目前的控制数据。当 Master失效时将检查最近检查点并重新执行失败操作。Worker失效是一种更常见的状态。其容错机制为:Master定期发送 ping命令以检查 Worker的有效性,如果 Worker没有应答,则Master将此 Worker标记为失效,并将分配给此 Worker的工作分配给其他空闲Worker重新执行。
3 问题描述及建模
如何提高MapReduce操作的效率,或者说如何花费最少的时间寻找合适的Worker来完成用户的需求为本文的研究目的。在MapReduce的整个执行过程中,我们需要考虑如下因素对总响应时间的影响:(1).输入文件数据分块的大小;(2).可用Worker的数量及Map Worker和Reduce Worker的数量;(3).Master节点的自身特性如处理能力、带宽和线路质量;(4).各个Worker的自身特性如处理能力、带宽和线路质量;(5).待处理数据和Worker的地理位置分布;(6).中间数据和其对应的Reduce节点的地理位置分布;(7).输出文件的位置;(8).Master节点稳定性和检查点的设置步长;(9).Worker节点的稳定性和询问周期;
为了简单起见,本文根据所关注的核心问题,考虑节点的性能(处理能力)、节点的外部条件(带宽、线路质量及位置)及输入数据块大小为主要因素来进行计算资源分配优化。
我们可以将在本集群中的所有可以由Master节点调度的节点域看成一个无向图G(V,E),其中V是所有可由Master调度的节点集合,E是连接各Worker节点的网络集合。寻找每个Map或者Reduce操作最优的Worker,也就变成在E中寻找一条最优路径e的操作[8]。又由于每个Map或者Reduce的可选节点网络集合是不同的,必须在V中排除那些已经分配给其他Map或者Reduce操作的非空闲节点,我们将第i次节点选择中可用节点网络集合记为Ei,其节点集合记为Vi。
在影响MapReduce效率的因素中有如下因素直接影响E中寻找一条最优路径e的选择:
1) Vi中每个节点的处理能力,由节点的性能如处理器主频、内存大小、缓存大小和可用磁盘空间等因素决定。
2) Vi各节点的网络状态,如网络带宽和网络延迟等。
3) 需要处理的数据块的大小及相对Vi中各节点的位置分布。如下我们对计算节点选择的影响因素
进行公式化,转化为相应的时间因素:
1) 节点预计执行时间time_cost(ei):指路径ei尽头的计算资源处理该作业预计耗费时间,由节点处理能力决定。节点完成任务需要的时间为节点性能中瓶颈因素所决定。
2) 网络延迟time_delay(ei):指路径ei产生的最大网络延迟。
3) 数据获取时间time_getdata(ei):由路径ei的长度、网络带宽和数据块的大小共同决定,和数据块的大小及e的长度成正比关系,和网络带宽成反比关系。
公式化为如下形式:

考虑如上三个因素 MapReduce执行过程中节点选择公式为:

约束条件:

其中 ei为第 i条路径选择,Ei为第 i次路径选择中可行路径集合;time(ei)为第 i条路径完成指定任务需要的时间;
α、β、χ为权重值,并且α+β+χ=1;CL、DL和GL为其边界限制条件。
4 算法描述
4.1 基本和声搜索算法(BHS)
和声搜索算法(Harmony Search,HS)[9]是由Geem Z W等人提出的一种启发式智能优化算法,在许多组合优化问题中得到了成功应用[10-13]。在音乐演奏中,乐师们凭借记忆, 通过反复调整乐队中各乐器的音调, 最终达到一个美妙的和声状态。Geem 等人受这一现象启发, 提出了基本和声搜索(Basic Harmony Search, BHS) 算法。
BHS 将乐器的音调类比作优化问题的决策变量Xij, 将各乐器的和声类比于解向量,其中n为决策变量的个数, 评价类比于目标函数F(Xi) ,和声记忆库HM 类比于种群, 乐曲的创作过程类比于种群进化过程[14]。和声记忆库的形式如下:

随着算法应用的越来越广泛,也有一些学者对算法进行了改进,以寻求更好的计算结果和性能。对 HS算法的改进主要集中在两个方面:一方面为动态调节算法中的某些参数;另一方面是在变量微调时改变随机数的选取方式[15]。本文在实验中将同时应用基本和声算法和一种改进的和声算法优化资源分配问题。
4.2 算法流程
BHS 从随机产生的和声记忆库开始,通过对和声记忆库思考、随机选择音调,以及和声调节来产生新解,再通过新解与和声记忆库中的最差解比较来决定是否更新和声记忆库,和声搜索算法解决问题分为以下步骤:(1).问题公式化; (2).算法参数设置;(3).随机的记忆库初始化;(4).随机选择、记忆的考虑、调整;(5).记忆库更新;(6).算法迭代及终止。
4.3 算法参数设置
1).和声记忆库的大小(HMS):指此算法同时处理的解向量的个数;(2).创作次数(MI):即算法迭代的次数;(3).和声记忆库思考概率(HMCR):指和声搜索算法从记忆库中取值概率,则以(1-HMCR)的概率从变量定义域中取值对和声记忆库进行更新;(4).音调微调概率(PAR):为对从记忆库中取出的值进行微调的概率,则以(1-PAR)的概率保持记忆库原来的数据不变。在BHS中一些固定的参数值被应用到问题的求解中,也有一些研究者提出了可变的参数,如PAR随着迭代的进行线性增长,这样可以一定程度上提高算法性能。动态PAR参数式为(t为迭代的次数):
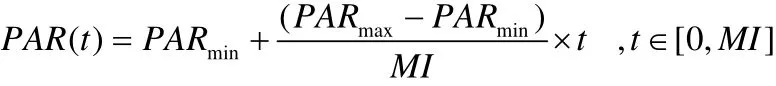
(5).调节频宽(FW):无论是对和声记忆库中还是定义域中取出的值进行微调的频宽。改进的和声搜索算法中有些将FW随着迭代的进行指数递减,参数公式为:
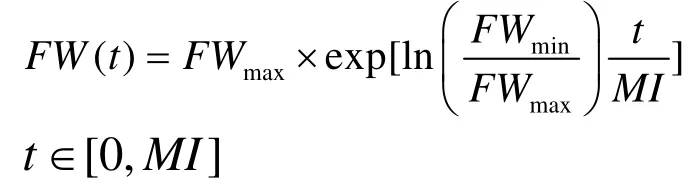
4.4 记忆库(HM)的初始化
为了保证算法的收敛速度和有效性,初始和声记忆库必须保证种群的分散性和均匀性。初始和声记忆按下式均匀产生:

其中Xij为第i个候选解向量中第j个决策变量的取值。rand[0,1]为在0到1上的均匀分布随机数。
4.5 新和声的生成
新和声是基于记忆考虑、随机选择和微调扰动3个规则产生的。记忆考虑可按如下的公式生成新和声变量:
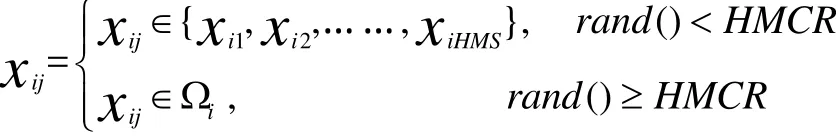
其中rand()为在[0,1]上均匀分布随机数,当特定情况下rand()的值小于HMCR,则第i个变量从和声记忆库中已存在的Xi中取值;否则从Xi的值域Ωi中随机选择。
微调扰动以如下规则进行:

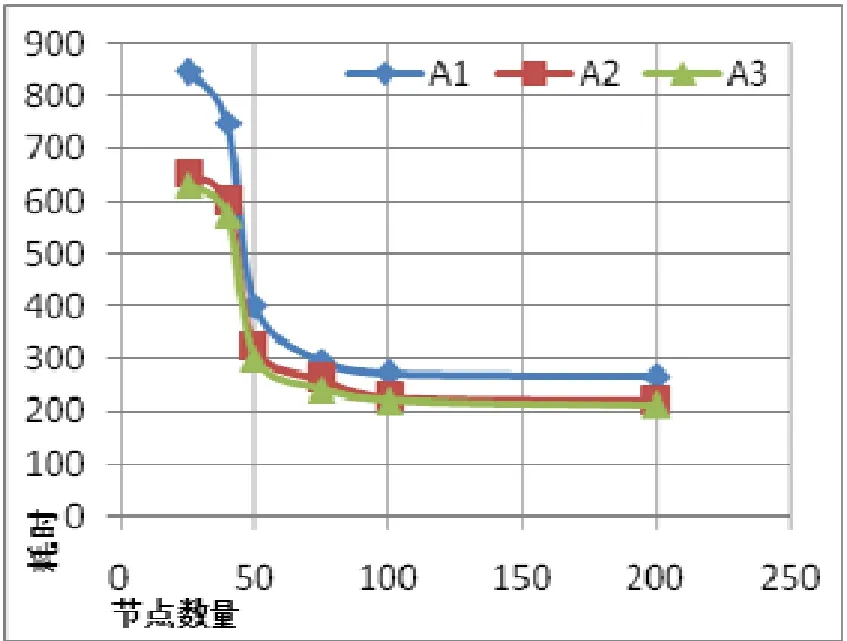
若随机数rand() 对于最小化问题,以如下规则更新和声记忆库: 当迭代次数达到预先设定的 MI次之后,则算法迭代终止,和声记忆库中最优解为求解问题的最终解。 由于真实Hadoop平台及其计算资源性能和外部环境度量的复杂性,并且云环境局部可以看作一个特殊的网格,因此我们利用Gridsim[16]来仿真云计算的局部域,以检查我们算法的有效性。Gridsim在大规模分布式计算机集群仿真中非常常见,并且仿真效果也比较理想。本文通过Gridsim的GridResource类模拟云计算中的计算资源和网络资源,并通过设定GridResource类中参数不同来模拟异构节点;通过GridInformationServices来管理这些模拟的资源。 为了比较算法的有效性,我们在用GridResource模拟的外部环境相同的情况下,将文中(1)式和(2)式在GridBroker中构造如下三种不同的策略来进行计算资源的选择,并比较各种策略的有效性和适用性。 三种策略及其参数设定: A1:随机选择计算资源:第i次节点选择中可用节点网络Ei中可用路径数为Ci,则我们以[0,Ci]的均匀分布对计算节点进行随机选择。 A2:基本和声搜索算法:我们将基本和声搜索算法参数设置为HMS=6,HMCR=0.9,PAR = 0.1,MI=Ci。 A3:改进的和声搜索算法:为了获得更好的收敛效果,我们利用动态调节算法参数的方法来改进和声搜索算法,设置其参数如下:HMS=5,HMCR=0.9,PARmin=0.01,PARmax=0.99,MI=Ci。 我们对1GB的文本应用MapReduce进行WordCount操作,数据块大小为32M,同时最大任务数(同时可并行运行的任务数,Task)为50。分别模拟集群中节点数量分别为25、40、50、75、100、200,且各节点的计算能力、网络带宽和位置并不完全相同。完成MapReduce的所有任务需要的时间如下表1所示(单位秒(s),表头A表示集群中节点数量、B表示三种不同分配策略)。 表1 Task=50,MI=Ci时仿真实验数据 由仿真实验结果表1我们可以看出,应用和声搜索算法(A2、A3)进行计算资源分配要比随机选择策略(A1)在响应时间上有很大优势;而基本和声搜索算法(A2)和改进和声搜索算法(A3)在执行效率上基本相同,后者稍优。根据如上数据我们可画出如图2所示仿真结果曲图(耗时单位为秒)。 图2 Task=50,MI=Ci时仿真结果曲线图 图2中横坐标表示集群中节点的数量,纵坐标表示Map-Reduce执行完设定Task需要的时间。从图2可以看出,当节点数小于Task数目时,随着节点数目增多至Task数目附近耗时下降明显;当节点数目大于任务数目时,随着节点数目的增多,对总耗时没有显著的影响。考虑和声搜索算法迭代次数MI对实验结果的影响,我们在其他条件不变的情况下设置Mi=2Ci,再次进行实验,得到结果如表2: 表2 Task=50,MI=2Ci时仿真实验数据 由两次实验可以看出随着迭代次数的增加完成所有任务的耗时有稍量下降,可以通过适当提高迭代次数获得更好的资源分配效果,但是效果并不显著。 异构Map-Reduce环境中资源分配策略直接影响到其响应时间,如何利用有效的策略将计算任务分配到计算资源是亟待解决的问题。文中对计算资源分配问题进行建模,利用和声搜索算法来优化资源分配,以期缩短MapReduce的整体响应时间,提高云计算平台的效率。从仿真结果可能看出,此算法明显优于资源的随机选择策略,并且可以利用改进的和声搜索算法获得比基本和声算法稍好的性能。 [1]. 田宏伟,解福,倪俊敏. 云计算环境下基于粒子群算法的资源分配策略[J]. 计算机技术与发展,2011. 21(12):22-25. [2].梁俊斌,苏德富.基于云模型的网格资源分配策略[J]. 计算机工程与应用,2005(5):147-150. [3]. Jiong, X., et al. Improving MapReduce performance through data placement in heterogeneous Hadoop clusters[C]. 2010 IEEE International Symposium on Parallel&Distributed Processing, Workshops and Phd Forum, Atlanta, GA, USA, 2010/4/19-23. [4].陈全. 异构环境下自适应的 Map-Reduce调度[J]. 计算机工程与科学, 2009. 31(A1),168-175. [5].刘鹏, 慈祥. 云计算[M]. 北京: 电子工业出版社,2010:2-3/14-17. [6].Dean,J.et al,MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM, 2008. 51(1):107-113. [7].Lammel, R. Google's MapReduce programming model-Revisited[J].Science of Computer Programming , 2008. 70(1): 1-30. [8].华夏渝, 郑骏, 胡文心. 基于云计算环境的蚁群优化计算资源分配算法[J]. 华东师范大学学报(自然科学版),2010(1): 127-134. [9]. ZW, G., K. JH, and L. GV. A new heuristic optimization algorithm: harmony search.Simulation[J], 2001, 76(2): 60-68. [10]. Z. Geem, J. Kim, G. Loganathan. Harmony search optimization: application to pipe network design[J]. International Journal of Model Simulation, 2002, 22(2): 125–133. [11].Geem, Z.W. Optimal cost design of water distribution networks using harmony search[J].Engineering Optimization, 2006,38(3):259-277. [12].Fesanghary, M. et al. Hybridizing harmony search algorithm with sequential quadratic programming for engineering optimization problems[J]. Computer Methods in Applied Mechanics and Engineering,2008,197(33–40):3080-3091. [13].武磊,潘金科,等. 求解零空闲流水线调度问题的和声搜索算法[J]. 计算机集成制造系统,2009,15(10): 1960-1967. [14]. Xiao-Zhi, G.. A New Harmony Search method in optimal wind generator design[C]. XIX International Conference on Electrical Machines - ICEM 2010,Rome,2010/9/6-8:(1-6). [15].雍龙泉. 和声搜索算法研究进展. 计算机系统应用[J], 2011. 20(7):244-248. [16].Buyya, R. and M. Murshed. GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for Grid computing[J]. Concurrency and Computation:Practice and Experience,2002,14(13-15): 1175-1220.4.6 记忆库的更新

4.7 迭代终止
5 算法仿真及结果分析


5 结束语
猜你喜欢
科学技术创新(2021年18期)2021-06-23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
英语文摘(2020年10期)2020-11-26
微型电脑应用(2019年10期)2019-10-23
测控技术(2018年7期)2018-12-09
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
计算机应用(2016年10期)2017-05-12
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
