
M2DPCA与CCLDA相结合的人脸识别
2014-04-03 07:32冯华丽刘渊
计算机工程与应用 2014年12期
冯华丽,刘渊
(1.无锡商业职业技术学院教育信息化中心 江苏 无锡 214153;2.江南大学数字媒体学院 江苏 无锡 214122)
1 引言
21世纪是信息技术、网络技术的世纪。随着计算机及网络的高速发展,信息的安全性、隐蔽性越来越重要。网络信息化时代的一个大特征就是身份的数字化和隐蔽化。如何有效、方便地进行身份验证和识别,已经成为人们日益关心的问题,也是当代必须解决的关键性社会问题。人脸识别是生物特征识别技中最自然、最直接的手段,,与其他身份识别方法相比,具有直接、友好和方便等特点,易于为用户所接受,多年来一直受到研究者的广泛关注。另外,人脸识别由于其在公安部门、安全验证系统、信用卡验证,档案管理、人机交互系统等方面的广阔应用前景,因而成为当前模式识别和人工智能领域的一个研究热点。
特征提取是人脸识别技术中一个基本而又十分重要的环节,如何寻找有效的特征是解决识别问题的关键[1]。其中比较典型的算法有主成分分析(Principal Component Analysis, PCA)[2],该方法的目的是通过线性变化寻找一组最优的单位正交向量基(即主分量)用它们的线性组合来重构原样本,并使重构后的样本和原样本的均方误差最小。但PCA算法只考虑了人脸的整体分布,没有利用样本类别的标签信息,因此分类效果并不十分理想。Peter等人提出了线性鉴别分析(Linear Discriminant Analysis, LDA)[3]方法,该方法充分利用了训练样本已知的类别信息,从而寻找最有助于分类的投影方向子空间。但以上方法往往只考虑了图像中的像素信息而忽略了图像中像素之间的上下文关系。近年来的研究表明,图像在高维空间都具有特定的流形,受到上下文信息的限制,因此上下文约束对于图像表示是非常重要的。其中比较典型的方法有马尔科夫随机场[4-6],然而由于其计算量比较复杂所以限制了其应用。此后,Wang等人[7]又提出了一种基于图像像素分布信息的图像匹配算法,但并未将这种算法应用到图像降维中。因此 Zhen等人提出了一种将上下文约束与鉴别分析方法相结合的CCLDA算法[8],并用于人脸识别中取得了很好的效果。
本文在上述工作的基础上,将模块化 2DPCA与上下文约束线性鉴别分析方法相结合,并将其用于人脸识别。该方法的特点是:首先将原始样本图像矩阵分成若干了子模块图像,然后对这些子样本采用 2DPCA算法,这样不仅可以较好地保留了人脸图像的局部特征,同时可以减少计算量,避免CCLDA算法中的小样本问题。另一方面,CCLDA算法在 LDA算法的基础上考虑了样本图像结构中的上下文约束关系,因此更有利于分类。
本文后续章节安排如下:第二小节介绍基于模块化2DPCA和CCLDA的人脸识别算法;第三小节对实验结果进行了分析;最后总结了本文地研究工作,并对人脸识别方法的发展进行了展望。
2 基于模块化2DPCA与CCLDA的人脸识别方法
在本文中,我们提出了一种基于模块化2DPCA和CCLDA的人脸识别算法。为了减少运算复杂度,保留样本的局部信息,首先采用模块化 2DPCA进行降维,然后对降维后的样本采用CCLDA方法来进行特征提取,从而为识别提供更有利的分类信息。算法的主要思想如图1所示:
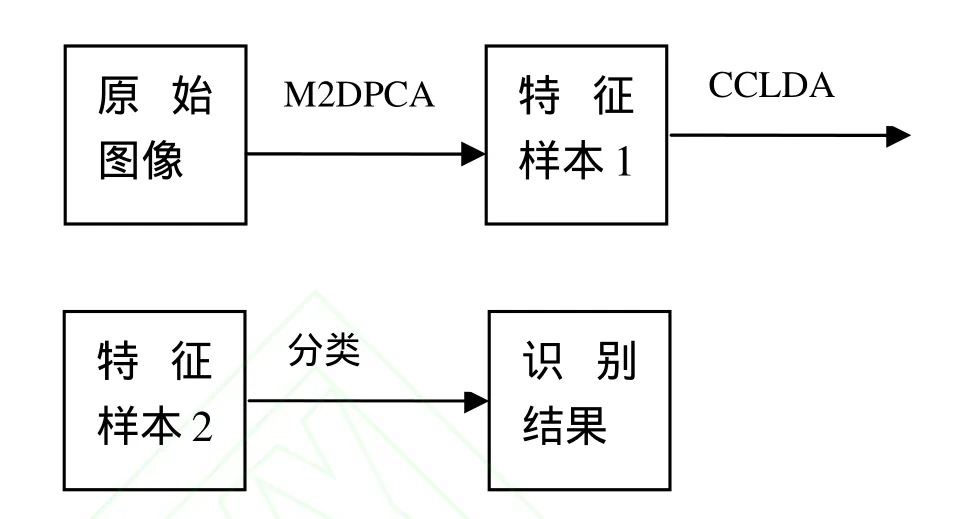
图1 本文新算法的主要思想框图
2.1 基于模块化2DPCA的特征提取
模块化2DPCA的思想是先将一个m×n的图像矩阵A分成p×q模块图像矩阵[9],即:

其中,每个子图像矩阵Akl是m1×n1矩阵,p×m1=m,q×n1=n。然后将所有训练图像样本的子图像矩阵看作训练图像样本采用 2DPCA算法进行特征提取。


则训练样本的子图像矩阵的总体散布矩阵Gt为:
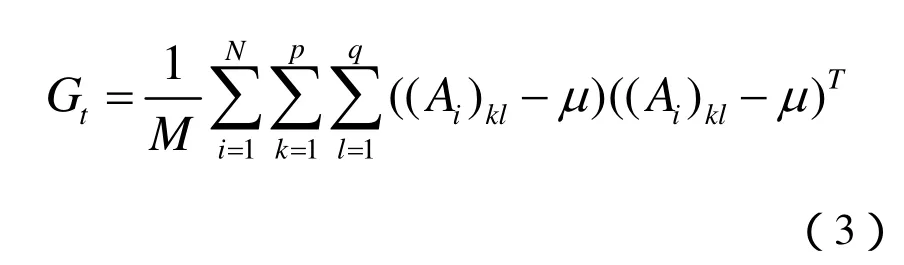
与2DPCA类似,我们令W=[w1, w2,...,wd]为模块化2DPCA的最优投影矩阵。训练样本 Ai投影到W上的特征矩阵 Yi为:
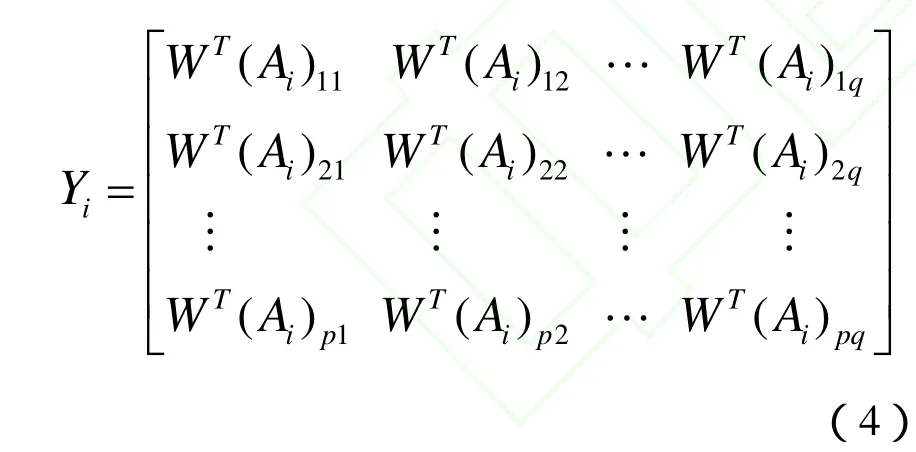
为了进行以下步骤,需要将矩阵 Yi按列向量一次排成一个列向量yi,易知yi∈Rd×p×n,这个过程称为矩阵的向量化处理。
2.2 基于CCLDA的人脸识别
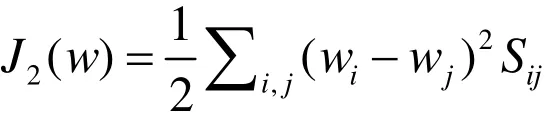

其中η是平衡训练鉴别能力与上下文限制的系数。Sij表示像素i与像素j之间的相似性,对于一幅原始的图像,假设图像相邻位置的像素有相同的特性,并且反映了图像的相同结构。因此,对于像素不同的权重我们采用如下的方式定义Sij:

其中fi表示每一幅样本中像素i位置所组成的特征向量,σ的值通常取这些特征向量f的平均距离。当相同位置的像素的权重相差很大时,限制函数J2(w) 的值将会很大。在一般情况下,由于Sij的对称性,所以J2(w)可以表示为

这里的Lw=D-S是一个拉普拉斯矩阵,D是对角化矩阵,Dii=∑jSij。因此,CCLDA的目标函数可以表示为:
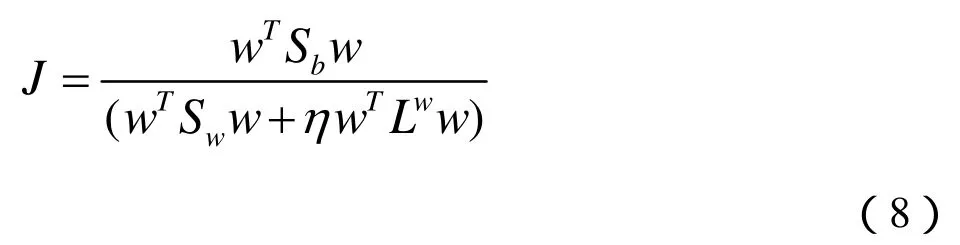
因此最佳投影矢量w可以转化为解以下的特征值的问题。

2.3 分类
首先将待测数据向量Z按照公式(1)分成p×q个样本子图像,然后按照公式(4)投影到2DPCA提取的子空间W上,并转化为得到新的样本向量z。然后分别将投影后的训练样本yi和测试样本z投影到CCLDA特征空间。最后采用最近邻分类方法进行分类识别。
3 实验结果与分析
为了验证所提算法的可行性和有效性,我们分别在ORL人脸数据库和XM2VTS人脸库中做了实验,实验结果表明,与其他算法相比,新方法在人脸识别上有明显的优势。
3.1 基于ORL人脸数据库的实验结果
我们在剑桥ORL人脸数据库[10]做了实验。ORL人脸库包含40个人的400幅面部图像,由英国剑桥大学的AT&T实验室采集,其中部分志愿者的图像包括姿态、表情和面部饰物的变化,图像的分辨率为92×112,灰度级为256。图2是ORL人脸库中的一些图像,比较充分地反应了同一个人不同人脸图像的变化和差异。实验中将图像库中的人脸图像分为训练样本和测试样本两部分,从中任意选取几幅人脸图像组成训练样本集,其余的作为测试样本集。

图2 ORL人脸库部分图像

表1 ORL人脸数据库识别率

图3 ORL人脸库算法识别率比较
表1中Gi表示每一类训练样本数目。通过表1和图3的实验结果我们可以得出以下几个结论:
(1)首先本文所的提出算法在识别率上有了很大的提高,与其他算法相比,有明显的优势。
(2)其次,从图和表中可以看出,其他算法在训练样本足够的情况下,可以取得较高的识别率,而我们的算法即使在较少的训练样本情况下,识别率也很理想的,可以达到90%左右。此外,当训练样本数超过5时,识别率可以达到100%,这是非常理想的。
(3)最后可以发现,不同的子模块数对本文算法的识别结果有一定的影响,但算法总体识别效果还是比较理想的。
3.2 基于XM2VTS人脸数据库的实验结果
XM2VTS人脸库[11]包括人脸库包括295人在4个月时间内4次录制的人脸和语音数据。每次采集都包括2个头部旋转视频和6种不同语音视频片段。从每个时期中提取两幅图像构成了这个用于人脸验证或者识别的人脸库,分辨率为55*51。图4是该库中的几幅图像。

图4 XM2VTS人脸数据库中的图像

表2 XM2VTS人脸数据库识别率

图5 XM2VTS人脸库算法识别率比较
表2中Gi表示每一类训练样本数目。通过表2和图5的实验结果我们可以发现,采用我们算法在XM2VTS人脸数据库上得到的识别结果,与其他算法相比,提高了很多,有明显的优势。而且本文算法,不仅在较少训练样本的情况下可以取得较高的识别率,而且当训练样本数足够时,识别率均可达到 100%。而且不同的子模块化样本数,对算法在XM2VTS上的实验结果影响不大,说明我们的算法具有较好的稳定性。

表3 在XM2VTS人脸库上的运行时间比较:
通过表3各算法在XM2VTS人脸数据库上的运行时间可以发现:
(1)随着训练样本数目的逐渐增多,各算法特征提取的时间和运行的总时间也随着增加。
(2)在以上几个算法的运行时间中,由于 MPCA算法既要对样本进行分块,又要将分块后的子样本转化为向量来处理,导致计算量复杂,因此特征提取和运行时间都相对较长。
(3)本文所提算法的运行时间受模块化2DPCA算法中子模块数目的影响,但是总体运行时间较快,与其他计算算法相比,运行时间效率几乎差不多,特别是当划分为2*4个子模块时,各方面运行时间几乎都是最少的,因此具有较高的效率。
总之,通过在ORL人脸数据和XM2VTS人脸数据库的实验结果表明,本文所提出算法不仅提高人脸识别的正确率,同时减少计算的复杂度,提高了识别的时间效率。
4 结束语
本文提出了一种模块化2DPCA和CCLDA相结合的人脸识别新方法。该方法一方面吸取了CCLDA考虑了样本图像结构之间的上下为你约束关系,可以更好地分类提供有效信息;另一方面,吸取了模块化 2DPCA算法可以保留样本的局部信息,减少计算量以及避免小样本问题等优点。实验表明,该算法具有较好的识别效果。但是由于与模块化 2DPCA相结合,因此不同的子模块数对算法的识别率有一定的影响,如何有效的划分样本子模块数,是我们需要进一步研究的问题。
[1]ROSENFELD A.Survey:image analysis and computer vision[J].Computer Vision and Image Understanding.1997,62(1);33-93
[2]M.Turk, A.Pentland, Eigenfaces for Recognition[J], Cognitive Neuroscience, 1991,3(1), 71-86.
[3]Peter N.Belhumeur, Joao P.Hespanha, David J.Kriegman, Eigenfaces vs.Fisherfaces:Recognition Using Class Specific Linear Projection [J], IEEE Trans.PAMI.1997,19(7), 711-720.
[4]Dass S.C., Jain A.K., Markov face models [C].IEEE International Conference on Computer Vision.2001,vol.2,680-687.
[5]Dass S.C., Jain A.K., Lu X., Face detection and synthesis using Markov random field models[C].IEEE International Conference on Pattern Recognition, 2002, vol.4, 201-204.
[6]Huang R., Pavlovic V., Metaxas D., A hybrid face recognition method using markov random fields [C].IEEE International Conference on Pattern Recognition,2004, vol.3, 157-160.
[7]Wang L., Zhang Y., Feng J., On the Euclidean distance of images [J].IEEE Trans.PAMI.2005,27(8), 1334–1339.
[8]Zhen Lei, Stan Z.Li.Contextual Constraints Based Linear Discriminant Analysis [J].Pattern Recognition Letters.2011, 32, 626-632.
[9]陈伏兵, 杨静宇等.基于模块2DPCA 的人脸识别方法[J].中国图象图形学报, 2006, 11(4) :581-585
[10]Jian Yang, David Zhang, et al.Two-Dimensional PCA:A New Approach to Appearance-Based Face Representation and Recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1),131-137.
[11]K Messer, J Kittler, J Luettin ,et al .XM2VTSDB:The extended M2VTS database[C].Audio and Video Based Biometric Person Authentication Conference(AVBPA99) ,Surrey, 1999
猜你喜欢
作文中学版(2022年1期)2022-04-14
学生天地(2020年31期)2020-06-01
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
电子制作(2019年14期)2019-08-20
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
