
多搜索引擎权重计算及搜索结果排序质量评估
2014-04-03 07:32:36谢坤武
计算机工程与应用 2014年12期
李 超 ,谢坤武
LI Chao1,2,3,XIE Kunwu1,2
1.湖北民族学院 计算机科学与技术系,湖北 恩施 445000
2.湖北民族学院 科技学院,湖北 恩施 445000
3.河海大学 计算机与信息学院,南京 211000
1.Deparment of Computer Science and Technology,Hubei Minzu University,Enshi,Hubei 445000,China
2.School of Computer Science and Technology,Hubei Minzu University,Enshi,Hubei 445000,China
3.College of Computer and Information,Hohai University,Nanjing 211000,China
1 引言
目前,用户在进行信息检索时,存在如下现象:(1)在进行信息检索时,无论是全文搜索引擎还是元搜索引擎,大多数查询趋向于短查询[1]。由于查询词的多义性,使得搜索结果往往涉及多个主题内容。返回结果数量往往较大(考虑到保密、搜索效率、用户遍历习惯情况等因素,各搜索引擎往往只提供部分索引内容),且用户通常没有足够的时间及耐心去遍历很多的检索结果,而往往只关注检索排列在前面的少量结果。(2)由于WWW的庞大,目前大多数搜索引擎按照与用户查询的相关度进行排序,返回结果太多,而对搜索引擎日志的分析表明多数用户只会浏览10~30个搜索结果[2]。另外,各搜索引擎返回的搜索结果靠前的部分往往比后面的更能满足用户的要求。(3)各搜索引擎覆盖内容往往只涉及部分资源,即使是元搜索引擎也只集成了少数搜索引擎的搜索结果,各搜索引擎返回的结果及排序存在很大差异。(4)各搜索引擎所采用的技术、算法往往不同且不公开,适用范围存在差异。针对某个查询请求,不同搜索引擎搜索结果的重叠率不到34%[3]。
搜索结果的重复识别及排序对于搜索服务质量的影响很大,搜索结果的排序在很大程度上决定着元搜索引擎的服务质量。为了实现搜索结果的整合与排序,目前主要结合文档内容、初始排序、分析用户点击行为、查询请求和查询意图[4-5]等因素,以及采用赋予成员搜索引擎权重等方法[6-7]。其中基于查询请求、文档内容和结合用户点击行为等方法,比较复杂且会导致服务器或(和)客户端高能耗及时延。而采用直接赋予搜索引擎权重[8-10]等方法,主要依靠用户和技术人员经验实现,主观性强不能体现用户个性化搜索要求。为此,提出跟踪用户搜索情况,在开源搜索引擎Nutch[11]平台上集成了多个成员搜索引擎,并透明、动态地赋予各成员搜索引擎权重,满足用户一定程度的个性化需求,同时提高搜索服务质量。通过跟踪用户遍历情况,论证了该方法的可行性和有效性。
2 搜索引擎权重计算模型
2.1 搜索结果用户遍历情况统计
为了掌握用户对搜索结果的浏览及满意度情况,对母语为中文的部分用户群体进行了问卷调查(后面实验通过客户端部署的Agent跟踪用户的搜索遍历习惯,可以发现比较近似的结果),得到了近1 000份有效调查问卷,统计结果如表1所示。

表1 用户查看搜索引擎返回结果的数量及满意情况1)
通过统计发现,多数用户遍历搜索结果时只会查看搜索结果的前100个(所占比例约90%),2/3以上的用户可以通过搜索引擎得到有用信息,大约有2/5的人通过搜索引擎结果能搜索到满意结果。因此,在进行多搜索引擎搜索结果的排序时,可以根据用户遍历搜索结果的情况,选取一定数量(与用户遍历数量存在一定的关联,但不一定相同)的搜索结果并进行排序,把整合后的结果返回给用户。
2.2 用户点击行为分析
基于客户端部署的Agent实现用户点击行为的跟踪,可以忽略多用户和群体行为[12-13]、识别非正常网络用户及行为[14]等任务。对于用户的点击行为,Joachims等[15]指出,用户点击行为不能用来判断查询与文档间的存在绝对相关性,只能用于评估相对相关性。无论查询与用户点击对象是绝对相关性,还是相对相关性,对于完成搜索引擎权重影响不大(关注的是用户遍历结果的来源以及来源的比例,从而确定搜索引擎重要性,即权重)。为此,主要记录用户点击对象的来源,而不用去进行会话(Session)切分、主题识别等工作。可以根据历史遍历情况(在网络、计算资源充裕情况下可以进行实时跟踪分析),结合用户遍历Web的内容,实现多成员搜索引擎返回结果的有效整合。该方法可以有效利用网络带宽及能耗,避免了对实时响应服务能力的要求。
2.3 搜索引擎权重计算模型及结果排序



(2)当α取值较大时,而执行的搜索请求次数较少(即n较小)时,各搜索引擎的权重基本上取决于α的值,即各搜索引擎权重基本一致。当α较大时,而执行的搜索请求次数逐渐增加时(或n趋于无穷大时),αe-β(n-1)的值趋于0,此时各搜索引擎的权重主要取决于搜索结果中用户满意或感兴趣搜索结果的来源。在用户遍历偏好难以确定或者不确定(用户前期执行搜索请求及遍历量较小情况下),可以设置α为一个比较大的值。
(3)用户访问的搜索结果数量往往有限,而搜索结果本身数量较大,为此,可以用历来用户搜索遍历数量的最大值或者均值,代替。

2.4 内容相同或相似Web页面的处理
在用户遍历的结果中,可能存在许多内容相似甚至相同的Web页面,而用户往往只去浏览靠前的Web页面,在进行搜索引擎权重计算时将产生偏差。为此,可以借助URL、Web内容重复识别技术[16],对上面的模型进行一定的改进。当用户访问一个Web页面时,判断是否有来自其他搜索引擎返回的URL相同(内容肯定相同)、URL不同但内容相同或者高度相似的页面,从而更好地实现搜索引擎权重计算。关于这部分的内容,本文不作详细介绍。
3 搜索结果排序质量
设在赋予搜索引擎不同权重WS1和WS2情况下,经过排序得到搜索结果分别为 RS1和RS2,RS1=<rs1,rs2,…,rsu>,RS2=< rs′1,rs′2,…,rs′u>,其中 u 为返回的结果数量。显然,在不同的排序情况下,用户点击或下载的页面在次序和数量上可能不一致。同时,用户遍历时不一定按照返回结果的次序遍历(全部或部分)结果。为此,设用户点击遍历的页面序列为:DoR1=<s1,s2,…,sN0>和DoR2=< s′1,s′2,…,s′N1>。其中 N0和 N1为在权重分别为DoR1和DoR2情况下用户遍历序列总数,显然v0≤u,v1≤u。为了定量地分析搜索引擎权重对搜索结果排序质量的影响,使用向量空间模型,把排序差异转化为向量空间的匹配问题,两个排序结果的相似度S用向量间的夹角来度量。


(2)假设用户遍历了10个结果,依次为<e,d,i,b,a,g,f,j,c,h>,则可以把RS1和 DoR1分别转换为RS1=<1,2,3,4,5,6,7,8,9,10>,DoR1=<5,4,9,2,1,7,6,10,3,8>,则返回的搜索结果顺序与用户遍历情况的匹配度为:S=0.842。假设交换遍历次序,往往会得到不同的匹配度。从而可以发现,搜索结果服务质量,与搜索结果排列次序及用户遍历次序密切相关,与用户遍历结果的数量没有必然联系。
4 实验及分析
通过跟踪近150个用户的搜索遍历情况,过滤掉搜索频率较低(小于7次)用户,得到了118位搜索用户情况,对多数用户使用搜索引擎的频率、用户浏览页面的数量以及点击数量和搜索结果排序与遍历匹配度进行统计分析,并设定可调因子α=600,β=2,得到如下情况。
(1)用户使用搜索引擎的频率
用户使用搜索引擎的频率可以通过时间段内使用搜索引擎的人次来进行间接的反映。通过分析118个搜索频率较大的用户,得到2013年5月1日至28日期间,用户每日使用过搜索引擎的人次。从图1可以看出,使用搜索引擎的人次,基本保持平稳。个别时段,如节假日,会有一定的上升。

图1 不同日期使用搜索引擎的人次
(2)用户浏览页面及点击情况变化
为了掌握用户浏览搜索结果的数量以及点击数量,对其进行了统计,如图2(a)所示。同时,为了掌握用户的点击数量与浏览数量间的关系,得到了点击数量与浏览数量比值,如图2(b)所示,其中A代表用户浏览搜索结果的数量,B代表用户点击数量。

图2(a) 用户浏览与点击结果数

图2(b) 点击数占浏览比例
从图2(a)可以看出,通过动态地赋予元搜索引擎中各成员搜索引擎权重的方法,用户浏览数量和遍历数量经过一段时间下降后趋于平稳,浏览数量均值基本分布在20~30个左右。通过图2(b)可以看到,用户遍历数量与浏览数量的比值,同样经过一段时间下降后趋于平稳,并且基本分布在0.25~0.30之间。综合图2(a)和图2(b)可以发现多少用户会浏览20~30个搜索结果,而同时会去进一步点击其中的5~10个结果。
(3)搜索结果排序与遍历匹配度
为了对经过改进的排序策略进行质量分析,根据用户遍历数据及公式(3),对搜索结果排序与遍历的匹配度进行分析,得到如图3所示结果。

图3 搜索结果排序与遍历匹配度
从图3可以看出,通过动态地赋予元搜索引擎中各成员搜索引擎权重的方法,搜索结果排序与遍历匹配度得到了一定的提升,总体提升了10%左右。
(4)与基于内容相关度和固定权重排序法的比较
为了掌握与其他方法的差异,另外采用了基于搜求请求与Web页面内容的相关度和固定分配搜索引擎权重两种策略排序,分析统计分析了在实现重新排序的响应时间、搜索结果排序与遍历匹配度两个方面的情况。对于一定数量的结果进行排序,三种方法所耗时间(硬件配置信息略)结果如图4所示。

图4 排序所耗时间对比
图4中,B_C、W和W_F分别表示基于搜索请求与Web页面内容相关度、本文方法以及固定权重法时对特定数量的搜索结果进行排序所耗时间。从图4可见,在排序目标确定的情况下,基于内容的方法,耗时较长,固定排序法耗时最短,本文所采用的方法,比固定权重法略长但很接近。
为了了解搜索结果排序与遍历匹配度,通过跟踪并分析了连续20天内、基于这三种方法的用户遍历与搜索排序结果的匹配度,取用户匹配度均值得到结果如图5所示。
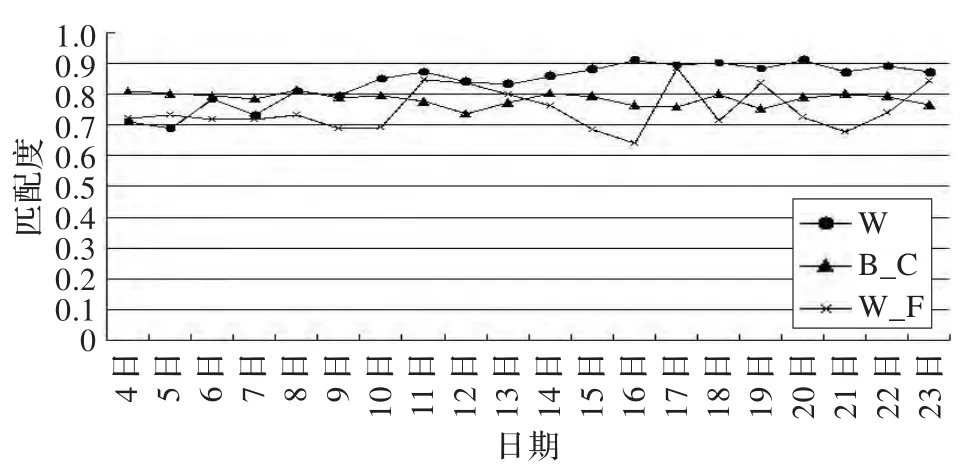
图5 匹配度变化图
图5中,B_C、W和W_F分别表示基于搜索请求与Web页面内容相关度、本文方法以及固定权重法时对特定数量的搜索结果进行排序时,用户遍历与搜索排序的匹配度。从图5可以发现:基于内容的排序的匹配度相对来说比较稳定,且多数情况下,比固定权重法匹配度要高;本文所采用的方法(统计的α的值大于500的用户搜求遍历情况)随着用户搜索及遍历次数增加,匹配度逐渐趋于稳定,且匹配度高于另外两种方法。在考虑响应时间及匹配度的情况下,通过图4和图5可以发现,本文方法比简单的基于搜索请求与内容相关度,以及固定权重的排序方法更优。通过设定不同的α和β的初始值,得到的结果略有偏差,但总体情况基本一致。
实验结果表明,通过挖掘用户历史搜索偏好,动态地赋予各成员搜索引擎权重进而实现搜索结果的整合方法,在对响应速度影响不大情况下,可以提高用户遍历的效率,论证了该方法的可行性和有效性。
5 结束语
在实现多搜索引擎搜索结果整合时,采用赋予搜索引擎权重时,目前的方法主要根据用户和技术人员经验实现,主观性强,不能体现用户个性化搜索要求。为此,提出通过挖掘用户搜索历史,动态地赋予各成员搜索引擎权重进而实现二次排序。基于该方法可有效实现多源的数据集成,也可以用于用户偏好挖掘、商品推荐等方面。当然,还有一些工作需要进一步进行或完善:(1)在搜索引擎初始权重赋值时,为了无区别对待搜索引擎,采用了初始等权重的方法。然而,因不同搜索引擎索引内容及技术不同,可以考虑在实现不同类型资源搜索时赋予各搜索引擎赋予不同的初始权重,然后进行多类型搜索权重折中,这也将是下一步的工作。(2)在现有工作基础上,进行现有主流搜索引擎权重赋值方法的实验对比分析,当然这将是一个工作量很大的任务。(3)因为Agent跟踪对象在地域、文化、教育等方面差异,点击事件存在噪音,跟踪用户及搜索请求的规模较小,以及对用户搜索资料收集不全面性等问题,统计数据可能与实际情况存在一定误差。
[1]Franzen K,Karlgren J.Verbosity and interface design[J].SICS Research Report,2000,1(1):1-5.
[2]Jansen B J,Spink A,Bateman J,et al.Real life information retrieval:a study of user queries on the Web[J].ACM SIGIR Forum,1998,32(1):5-17.
[3]Wu S,McClean S.Result merging methods in distributed information retrieval with overlapping databases[J].Information Retrieval,2007,10(3):297-319.
[4]Dai H K,Zhao L,Nie Z,et al.Detecting Online Commercial Intention(OCI)[C]//Proceedings of the 15th International Conference on World Wide Web,2006:829-837.
[5]Broder A.A taxonomy of web search[J].ACM Sigir Forum,2002,36(2):3-10.
[6]Zhao Chongchong,Zhang Zhiqiang,Xie Xiang.A new keywords method to improve web search[C]//12th IEEE International Conference on High Performance Computing and Communications.Melbourne,VIC:Institute of Electrical and Electronics Engineers,2010:477-484.
[7]Haveliwala T H.Topic-sensitive page rank:a context-sensitive ranking algorithm for web search[J].IEEE Transactions on Knowledge and Data Engineering,2003,15(4):784-796.
[8]Wu S,McClean S.Performance prediction of data fusion for information retrieval[J].Information Processing&Management,2006,42(4):899-915.
[9]Wu S,McClean S.Improving high accuracy retrieval by eliminating the uneven correlation effect in data fusion[J].Journal of the American Society for Information Science and Technology,2006,57(14):1962-1973.
[10]Meng Weiyi,Yu C.Building efficient and effective metasearch engines[J].ACM Computer Surveys,2002,34(1):48-89.
[11]Khare R,Cutting D,Sitaker K,et al.Nutch:a flexible and scalable open-source web search engine[EB/OL].[2013-06-20].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.105.5978&rank=1.
[12]Guo F,Liu C,Wang Y M.Efficient multiple-click models in web search[C]//Proceedings of the Second ACM International Conference on Web Search and Data Mining,2009:124-131.
[13]Agichtein E,Brill E,Dumais S.Learning user interaction models for predicting web search result preferences[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2006:3-10.
[14]Tan P N,Kumar V.Discovery of web robot sessions based on their navigational patterns[M]//Intelligent Technologies for Information Analysis.Berlin Heidelberg:Springer,2004:193-222.
[15]Joachims T,Granka L,Pan B,et al.Accurately interpreting click through data as implicit feedback[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2005:154-161.
[16]Fetterly D,Manasse M,Najork M.On the evolution of clusters of near-duplicate web pages[J].Journal of Web Engineering,2003,2(4):228-246.
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
