
基于流形学习和改进VPMCD的滚动轴承故障诊断方法
2014-04-02 07:13潘海洋李永国程军圣
振动工程学报 2014年6期
潘海洋 杨 宇, 李永国, 程军圣
(1.湖南大学汽车车身先进设计制造国家重点实验室, 湖南 长沙 410082;2.安徽工业大学机械工程学院, 安徽 马鞍山 243032))
引 言
对于滚动轴承故障诊断来说,其振动信号往往表现出非平稳和非线性特征,若直接提取原信号的特征值会影响诊断精度,因此,必须先对原始振动信号进行处理。在非平稳信号的分析中,经验模态分解(Empirical mode decomposition,简称EMD)、局域均值分解(Local mean decomposition,简称LMD)和本征时间尺度分解(Intrinsic time-scale decomposition,简称ITD)方法都是自适应的非平稳、非线性信号处理方法[1]。但上述方法在理论上都还存在或多或少的缺陷,如EMD的过包络、欠包络、端点效应和频率混淆问题[2];LMD的信号突变和端点效应问题[3];ITD方法没有对算法本身及固有旋转分量的物理意义进行阐述。因此,在阐述ITD方法及其固有旋转分量物理意义的基础上,提出了改进的ITD算法——局部特征尺度分解算法(Local characteristic-scale decomposition,简称LCD)[4]。关于LCD算法的有效性及其在端点效应和分解时间方面均优于EMD的结论已在文献[4]中详细讨论。
通过对振动信号LCD分解,得到若干内禀尺度分量并提取其特征,从而构成高维特征向量,这些高维数据的大量使用,给故障的识别带来了很大的麻烦,许多有效的信息淹没在高维数据中,难以被有效利用,且影响分类效率。目前对于高维数据,常采用降维方法提取能反映故障状态有效信息的低维特征,降维方法一般可以分为两种,即线性和非线性降维。线性降维方法是假设数据存在于全局线性中,即数据集中的各特征值之间是独立的,主成分分析(Principle components analysis,简称PCA)就是一种比较常用的线性降维方法[5]。但是,在实际情况中,高维数据往往是具有非线性结构的,因此,主成分分析方法的使用具有局限性。流形学习是典型的非线性降维方法,旨在发现高维数据中的内在规律性,其思想是少数独立变量在高维空间中共同作用形成了一个流形,如能够有效地展开空间的流形或者挖掘内在的主要变量,就可以对该高维数据集进行压缩降维。流形是在微分几何学的基础上形成的,实质上是局部可坐标化的拓扑空间,可以看成是在欧氏空间中的非线性推广。因此,流形学习可以有效地对高维数据进行降维,拉普拉斯特征映射算法是一个常用的流形学习降维方法[6],它采用图拉普拉斯算子的谱性质进行求解,寻求在某种意义上可以最佳地保持局部领域信息的低维表示,挖掘出高维数据中具有内在规律性的低维特征。
提取并挖掘出低维数组特征过后,随之而来的就是模式识别,模式识别作为滚动轴承故障诊断的另一重点,目前常用于故障诊断的模式识别方法有神经网络和支持向量机等,但它们都有一些无法克服的缺陷,且诊断结果受主观影响较大。另外,上述模式识别方法都忽视了特征集中数据之间的内在关系。然而,在所提取的机械故障振动信号特征中,其特征值之间大都具有一定的内在关系,而且这种内在关系在不同的系统或类别(相同的系统在不同的工作状态下)间具有明显的不同。基于特征值之间的这种内在关系,提出了一种基于Kriging的多变量预测模型模式识别方法(kriging-variable predictive model based class discriminate,简称KVPMCD)。KVPMCD的实质就是通过特征值之间的相互内在关系建立数学模型,对于不同的类别可以得到不同的数学模型,从而可以采用这些数学模型对被测试样本的特征值进行预测,把预测结果作为分类的依据,进一步进行模式识别。该方法克服了原多变量预测模型(Variable predictive model based class discriminate,简称VPMCD)中模型的单调性[7],VPMCD模式识别方法仅有4种回归模型进行预测,当特征值之间关系较为复杂时将导致预测精度降低。Kriging函数是作为一种估计方差最小的无偏估计模型[8,9],通常是由3种回归模型和7种相关模型组合而成,回归模型构建了预测模型的主结构,相关模型是在全局基础上创建的局部偏差,用来弥补单纯采用回归模型的缺陷,使得所建立的模型更加逼真,从而可以建立反映特征值之间复杂关系的KVPMCD模型。
将LCD,LE流形学习和KVPMCD方法引入滚动轴承故障诊断,首先经过LCD分解降低了振动信号非线性和非稳定性对故障特征提取的影响,接着通过LE算法特征压缩,得到具有内在规律的低维特征,而KVPMCD的原理恰恰是基于特征值内在关系建立的预测模型。因此,最后把得到的低维特征向量输入KVPMCD分类器进行诊断识别。从而实现了将LCD,LE流形学习算法和KVPMCD相结合应用于滚动轴承故障的全程连续诊断。
1 基于LE算法的KVPMCD滚动轴承故障诊断方法
1.1 LE流形学习算法
拉普拉斯特征映射算法作为一种典型且有效的流形学习方法,以保持局部空间结构领域信息不变为宗旨,在很大程度上保持了原空间中数据的局部最优分布情况。LE方法的基本原理是:数据在高维空间中距离比较近的点映射到低维空间中的点也应该离得比较近,其损失函数为两点间的加权距离,然后借助图拉普拉斯算子的谱性质进行求解,能够挖掘出嵌入在高维数据中具有内在规律的低维几何分布特征。LE算法具体步骤如下[6]:
(1)构造近邻图。设定一领域参数k,采用k近邻或者ε领域的方法计算每一个样本点xi的领域Γ(i),1≤i≤n。
(2)构造邻接权值矩阵W。设定热核方程参数t,使用热核方式给每一条边赋予权值Wij,从而构建矩阵W为
(1)
(3)特征映射。计算出图拉普拉斯算子的广义特征向量,求低维嵌入。求解广义特征值问题Lf=λDf。其中D为对角矩阵,且Dii=∑Wij(i≠j),得到L的第2个至第d+1个特征值对应的特征向量,即为所得到的数据集对应d维嵌入坐标。
1.2 VPMCD模型
在机械故障诊断中,提取p个不同的特征值X=[X1,X2,…,Xp]来描述一个故障类别,由于特征值之间存在的内在关系,因此,在不同的故障类别中,会受到其他特征值的影响而产生不同的变化,在此类问题中,特征值之间可能存在一对一的关系:X1=f(X2);或者一对多的关系:X1=f(X2,X3,…)。为了识别系统的故障模式,需建立数学模型。原VPMCD方法中,为特征值定义的变量预测模型VPMi为一个线性或者非线性的回归模型,文献[7]中提出了4种数学模型。以p个特征值为例,对4种模型中任意一个模型采用特征值Xj(j≠i)对Xi进行预测,都可以得到
Xi=f(Xj,b0,bj,bjj,bjk)+e
(2)
式(2)称为特征值Xi的变量预测模型VPMi。其中,特征值Xi称为被预测变量;Xj(j≠i)称为预测变量;e为预测误差;b0,bj,bjj和bjk为模型参数。
1.3 Kriging模型
Kriging模型假设系统的响应值与自变量之间的真实关系可以表示成如下的形式
f(x)=g(x)+z(x)
(3)
式中g(x)为确定性漂移,它是一个确定性部分,在Kriging模型中通常称为回归模型,回归模型有3种形式:零阶回归模型(Zero order polynomial);一阶回归模型(One order polynomial);二阶回归模型(Two order polynomial)。它们是所建立Kriging模型的主要框架。z(x)称为涨落,它提供对模拟局部偏差的近似,是和“相关模型”有关的一个函数,相关模型是传统关系函数的一种变化形式,它可以用来描述变量之间的空间结构变化,也可以描述其随机性变化[10],它是在全局模型基础上创建的均值为零,但是方差不为零的局部偏差,只有选择合适的相关函数,才能保证模型具有较高的准确性。利用不同的相关模型对采样点的特征值进行建模,并计算不同测试条件下估计值的均方误差,相关模型有7种:指数模型(Exponential);广义指数模型(Generalized exponential);高斯模型(Gaussian);线性模型(Linear);球体模型(Spherical);立方模型(Cubic);样条模型(Spline)。
1.4 VPMCD中最小二乘拟合和Kriging插值拟合比较
假设一个二次交互模型函数z=3-x2-y2+7x+5y-xy,x∈[0.5,5],y∈[0.5,5],则可画出一空间曲面。
为了比较两种拟合方法的拟合效果,首先从曲面上任意选取50个点,则可组成一个50×3的矩阵,然后代入VPMCD中的二次交互回归模型,通过最小二乘回归拟合出参数,接着把矩阵回代建立的模型中,得到一个新的多项式函数,即最小二乘拟合出的曲面,如图1(b)所示。用同样的50个点,选定Kriging模型的回归模型、相关模型及相关模型参数,然后通过所建立的Kriging模型插值得到一个拟合曲面,如图1(c)所示。图1中直观地表达了两种插值拟合方法的效果,下面从误差检验上比较一下两种方法的有效性,选用预测点的均方根差、经验累积方差和平均相对误差作为参考量[11],其比较结果如表1所示。
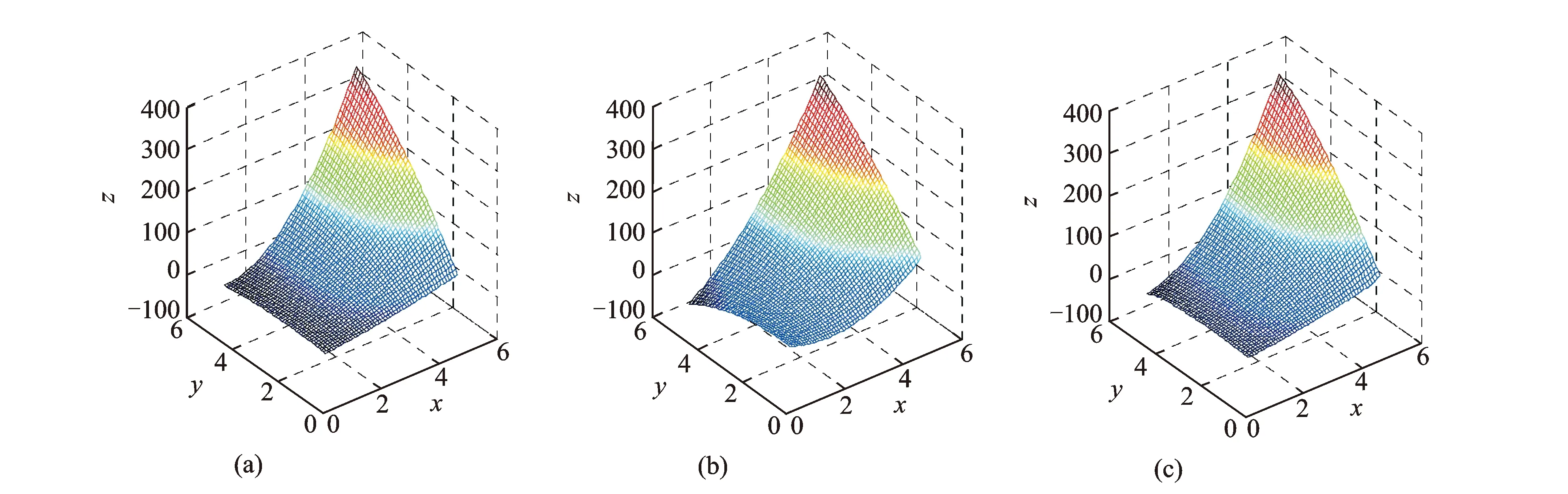
图1 函数的原曲面图和两种拟合方法得到的曲面图对比
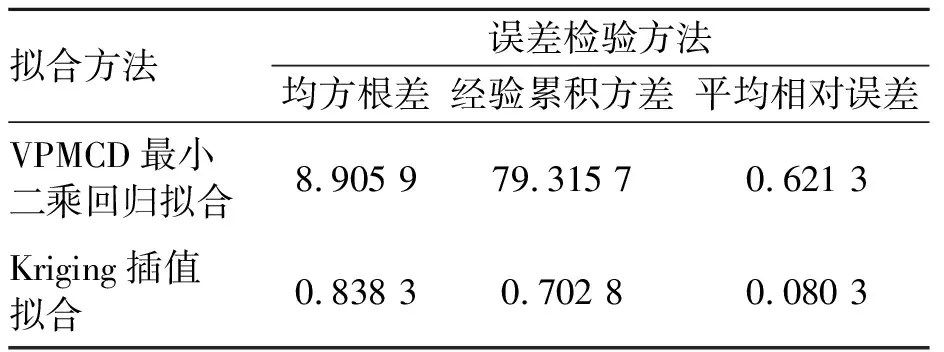
表1 两种拟合方法在三种误差检验法下的误差数值比较
分析比较图1可知,由于随机产生的数值较为复杂,通过VPMCD建立预测模型,拟合出的曲面出现失真,而Kriging插值得到的曲面由于存在相关函数的原因,对回归模型进行了补充,使得拟合出的曲面和原曲面十分相似。而在表1中,列举了两种拟合方法的三种误差检验值,无论是那种误差检验法,Kriging插值拟合所得到的误差值都很小,明显优于VPMCD的最小二乘回归拟合。因此,Kriging模型展示了比VPMCD现有模型的优越性,从而证明基于Kriging函数的KVPMCD比原VPMCD具有更强的适应性。
1.5 基于Kriging模型的KVPMCD模式识别方法
①对于g类分类问题,共收集n个训练样本,每一类样本数分别为n1,n2,…,ng。对所有训练样本提取特征量X=[X1,X2,…,Xp],每一类样本特征量的规模大小分别为n1×p,n2×p,…,ng×p。
②选择第k(1≤k≤g)类训练样本的特征量Xj(i=1,2,…,p)作为被预测变量,选择剩下的p-1个特征量Xj(j≠i)作为预测变量。
③令回归模型类型m=1(1≤m≤M) (Zero order polynomial,One order polynomial,Two order polynomial三种模型分别用数值1,2,3标记),相关模型的模型类别r=1(1≤r≤R)(Exponential,Generalized exponential,Gaussian,Linear,Spherical,Cubic,Spline七种模型分别用数值1,2,3,4,5,6,7标记),建立一个数学模型。
④先后分别令r=r+1和m=m+1,直至r=R,m=M结束。预测变量的组合方式共有M×R种可能,因此对于特征量可建立nk=M×R个数学方程。
⑤对于每一个特征量Xi建立的nk个方程,然后把第k类训练样本的特征量进行回代,利用Kriging模型得到特征量Xi的预测值Xipred。
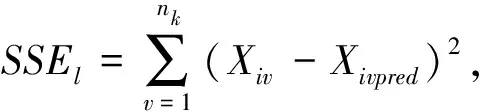
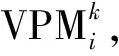
⑧将所有训练样本作为测试样本分别对每一个VPM矩阵进行回代分类测试,选择分类正确率最高的VPM矩阵所对应的回归模型类型和相关模型类型作为最佳变量预测模型的类型。至此,各种类别下的所有特征量的最佳变量预测模型的类型、预测变量都得以确定。

2 基于LE算法和KVPMCD方法的滚动轴承故障诊断方法
拾取滚动轴承振动信号并经过LCD分解后,接着就要对得到的若干ISC分量提取包含故障有效信息的特征。特征提取作为故障诊断中的关键环节,只有选择合适的特征才能准确区分滚动轴承的工作状态和故障类型。用来描述系统非线性特性的参数较多,复杂度相对较为简单;峭度和模糊熵也常用来处理非线性问题。因此,本文中采用组合的方法,即提取信号的复杂度、峭度和模糊熵。它们之间可相互补充、相互印证,更有利于识别故障信号,增强可靠性。提取每个分量的特征,组成特征向量矩阵。由于特征向量的维数较多,直接用分类器进行模式识别,不但影响分类效率,而且高维数据掩盖了有效信息。因此,接着采用LE流形学习算法对特征向量矩阵进行降维,挖掘出具有内在规律的低维向量矩阵,然后用KVPMCD分类方法对滚动轴承的状态进行识别。
基于LE流形学习和KVPMCD的滚动轴承故障诊断方法步骤如图2所示。
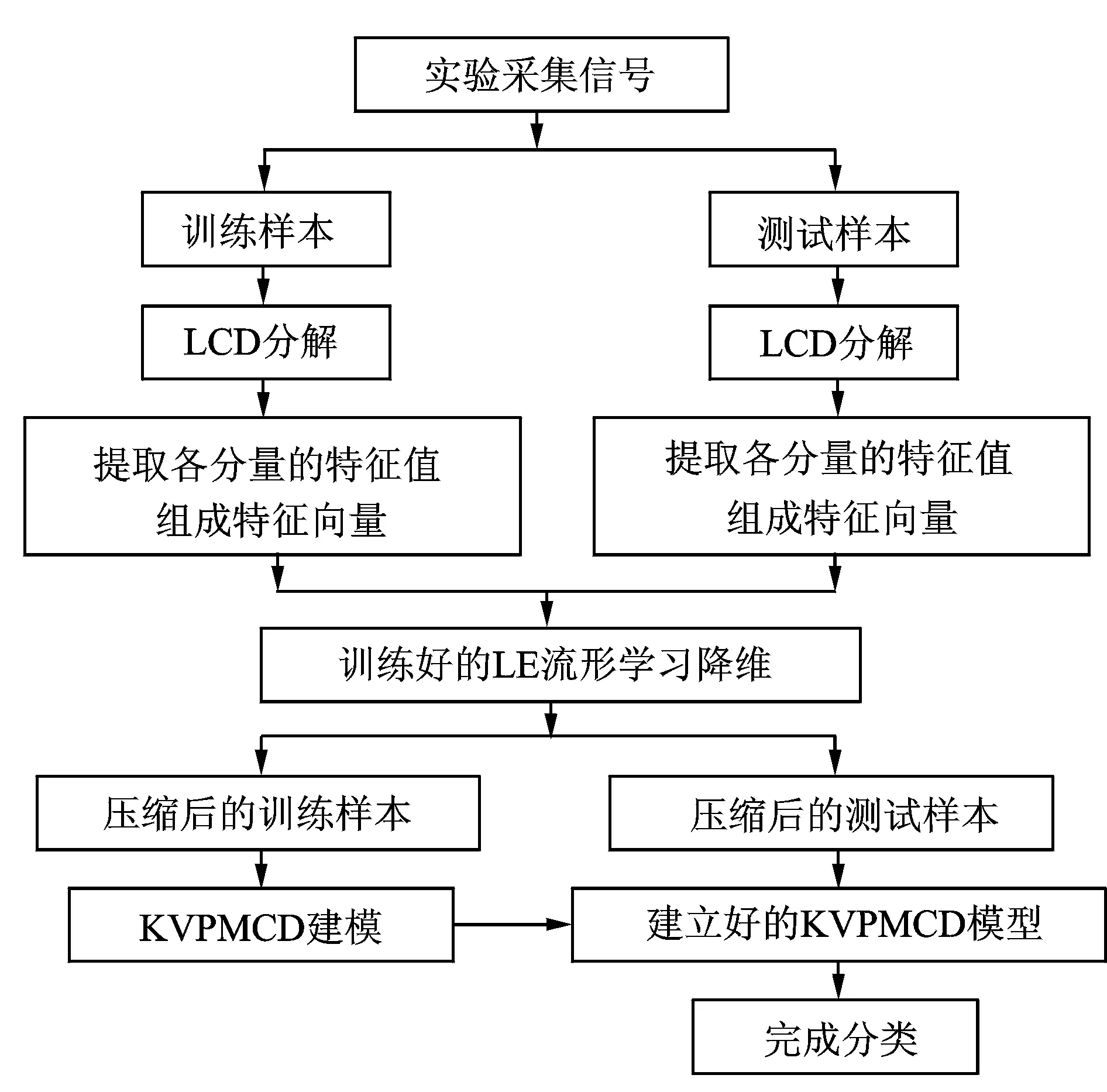
图2 滚动轴承故障诊断原理图
①在一定转速下以采样率fs对滚动轴承正常、内圈故障、外圈故障和滚动体故障4种状态进行采样,每种状态采集N组样本。
②首先利用LCD方法对原始振动信号进行分解,得到若干ISC分量。然后提取包含信号主要信息的前几个ISC分量的复杂度、峭度和模糊熵作为特征值,每个信号提取j个特征值,组成特征值向量,每种状态下得到N×j阶的特征值矩阵。
③用LE流形学习算法对特征值矩阵进行降维,设定好参数,通过特征压缩,得到一个全新的压缩特征集N×i。
⑤剩下的作为测试样本,用训练好的数学预测模型对测试样本进行分类,根据KVPMCD分类器的输出结果来确定滚动轴承的工作状态和故障类型。
3 实例分析
为了验证本文所提方法的适用效果,选用美国凯斯西储大学(Case Western Reserve University)电气工程实验室的实测滚动轴承振动加速度数据[12],数据源于6205-2RS型深沟球轴承,采样频率为48 kHz,转速为1 772 r/min,电机负载为0.746 kw,损伤尺寸为0.018 mm,故障深度为0.028 mm。选取正常、内圈故障、外圈故障和滚动体故障4类状态下的振动信号各200组数据作为样本。内圈故障下的滚动轴承振动信号如图3所示。
图3 内圈故障状态下滚动轴承振动信号时域波形
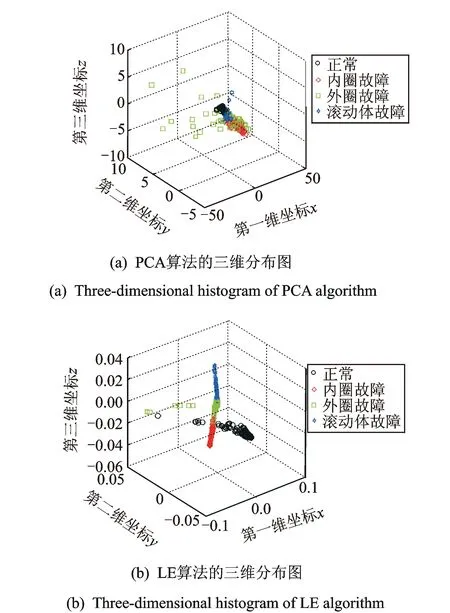
图4 两种算法压缩三维的分布图
首先对所采集的非平稳、非线性滚动轴承振动信号进行LCD分解,得到振动信号在时域和频域的局部化信息,每个信号可以分解得到若干ISC分量,选取包含主要状态信息的前3个ISC分量,然后提取每一个ISC分量的复杂度、峭度和模糊熵,因此一个信号可以提取9个特征。每种状态的样本信号提取9个特征参数,构成原始特征空间。采用LE方法对原始特征空间进行特征压缩,通过计算和实验优化选择,取邻域参数k=4,热核方程的参数t=4,嵌入维数d=3。为了说明采用LE方法进行特征压缩的可行性,同时将采用LE方法进行特征压缩的样本与采用PCA方法进行特征压缩(同样取嵌入维数d=2和d=3)的样本进行比较,其压缩后所得的样本分布图见图4和5。从图4可以发现,相比于PCA方法,采用LE方法进行特征压缩后,虽然有个别混在一起,但总体来看4种状态的样本分得较开;PCA方法压缩得到的低维特征难以分类识别。对于图5中的二维压缩,情况较为类似图4,LE方法压缩的各种类型可以明显地分开;而PCA压缩的特征,内圈故障和外圈故障混淆在一起,难以分辨。可见LE方法比PCA方法更能提取用于区分样本的敏感特征。
上述对几种降维方法进行了直观的比较,验证了LE方法的可行性,下面进一步把LE流形学习算法和KVPMCD相结合应用于滚动轴承故障诊断识别,证明基于LE算法的KVPMCD更加有效。滚动轴承的4种状态各取200个样本进行实验,其中100组作为训练样本。首先设定LE 算法的参数,通过对训练样本的交叉验证,选出最优LE参数,其选择结果如图6所示。
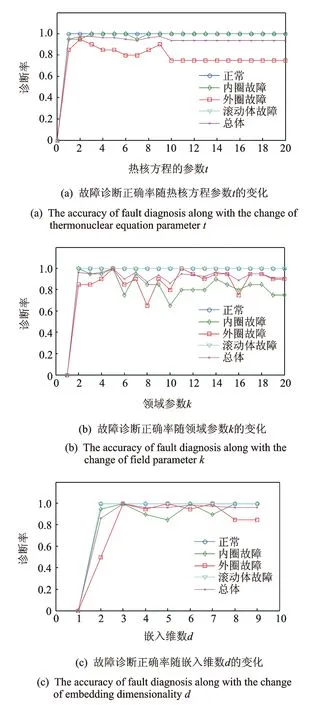
图6 故障诊断正确率随参数的变化
经过优化选择,设定邻域参数k=5,热核方程的参数t=2,嵌入维数d=3,接着用LE算法对特征集进行压缩,得到低维特征集。同样采用PCA方法(嵌入维数d=3)对所构成的原始特征空间进行特征压缩。然后采用KVPMCD进行训练,通过优化选择,对于LE算法压缩后的数据,相关模型参数取theta=0.000 1,PCA算法压缩后的数据,取theta=3.5,得到预测模型,预测模型包括回归模型和相关模型,通过实验,回归模型都是Two order polynomial模型,相关模型都是Spherical模型,接着对测试样本进行智能识别。本文引用K-fold cross-validati on(简称K-CV)检验对两种方法进行验证,取全部的200组数据进行验证。其识别结果如表2所示。
从表2中可以看出,基于LE算法的KVPMCD准确识别率明显高于基于PCA算法的KVPMCD识别率。LE流形学习通过对高维数据进行压缩,能够得到具有规律性的低维数组,从而满足KVPMCD模式识别方法的建模原理,使得把LE算法和KVPMCD相结合应用于滚动轴承故障诊断,取得了较好的分类效果。

表2 两种降维方法在10-CV检验法下的KVPMCD分类性能对比
综上所述,基于LE的特征压缩算法,把高维的故障样本压缩到低维空间,并且极大地保留了原信号的特征信息;另外,考虑到拾取的信号复杂性,原VPMCD建模不能充分反映特征值之间的真实信息,将Kriging函数应用于VPMCD得到KVPMCD,经过仿真数据的验证,KVPMCD确实比原VPMCD具有较好的效果,因此,实验证明,基于LE算法的KVPMCD是一种有效的滚动轴承故障诊断方法。
4 结 论
针对数据维数较高时给分类器带来的麻烦,以及原VPMCD方法中模型的缺陷,本文将LE流形学习和KVPMCD相结合应用于滚动轴承的故障诊断中,经研究得出以下结论:
(1)对所提取的高维特征通过LE流形学习方法进行特征压缩,得到具有内在规律性的低维特征,且保留了信息的本质特征,有利于故障的诊断。
(2)将Kriging函数应用于VPMCD中得到KVPMCD,当特征集中数据之间的关系较为复杂时,原VPMCD中4种回归模型很难准确建立预测模型,而KVPMCD方法采用以回归模型为主,相关模型为辅,从而建立更加真实的预测模型。
(3)针对LE流形学习算法压缩高维数据后得到具有内在规律的低维数据,恰好满足KVPMCD 的建模原理,将两者结合起来,可以有效地提取特征和建立模型。
对仿真信号和滚动轴承各种状态振动信号的分析结果表明,证明了KVPMCD比原VPMCD方法具有更好的建模效果,以及将LE算法和KVPMCD相结合的滚动轴承故障诊断方法可以准确、有效地对滚动轴承的工作状态和故障类型进行分类,从而为滚动轴承的故障诊断提供了一种新的方法。
参考文献:
[1] Mark G Frei, Ivan Osorio. Intrinsic time-scale decomposition: time-frequency-energy analysis and real-time filtering of non-stationary signals [J].Proceedings of the Royal Society, A, 2007, 463: 321—342.
[2] Cheng J S,Yu D J,Yang Y. Energy operator demodulating approach based on EMD and its application in mechanical fault diagnosis[J].Chinese Journal of Mechanical Engineering, 2004,40( 8):115—118.
[3] Lei Yaguo, He Zhengjia, Zi Yanyang.Application of the EEMD method to rotor fault diagnosis of rotating machinery [J]. Mechanical Systems and Signal Processing,2009, 23:1 327—1 338.
[4] 程军圣,郑近德,杨宇.一种新的非平稳信号分析方法——局部特征尺度分解[J].振动工程学报,2012, 25(2):215—220.Cheng Junsheng,Zheng Jinde,Yang Yu.A nonstationary signal analysis approach——the local characteristic-scale decomposition method[J].Journal of Vibration Engineering, 2012, 25(2): 215—220.
[5] TURK M, PENTLAND A.Eigenfaces for recognition [J].Journal of Cognitive Neuroscience, 1991, 3(1):71—86.
[6] Belkin M,Niyogi P.Laplacian eigenmaps for dimensionality reduction and data representation[J].Neural Computation,2003,15(6):1 373—1 396.
[7] Rao Raghuraj,Samavedham Lakshminarayanan. Variable predictive models—a new multivariate classification approach for pattern recognition applications [J]. Pattern Recognition, 2009, 42(1):7—16.
[8] Noel Cressie. The origins of Kriging[J]. Mathematical Geology, 1990, 22(3): 239—252.
[9] Gou Peng,Liu Wei,Cui Wei-cheng.A comparison of approximation methods for multidisciplinary design optimization of ship structures[J]. Journal of Ship Mechanics, 2007, 11(6):913—923.
[10] Rana A Moyeed,Andreas Papritz.An empirical comparison of Kriging methods or nonlinear spatial point prediction[J]. Mathematical Geology, 2002, 34(4):365—386.
[11] Zhang Renduo. Theory and Application of Spatial Variation[M].Beijing:Science Press,2005.
[12] Case Western Reserve University Bearing Data Center. Bearing Data Center Fault Test Data.[EB/OL].[2009-10-01].http:∥www.eecs.case.edu/laboratory/bearing.
猜你喜欢
数学杂志(2022年4期)2022-09-27
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
世界知识画报·艺术视界(2017年7期)2017-07-27
自动化学报(2017年11期)2017-04-04
振动工程学报(2015年2期)2015-03-01
