
视频字幕提取技术在广电监测中的应用
2014-03-13 06:10李春朋齐忠文王翾
中国传媒大学学报(自然科学版) 2014年2期
李春朋,齐忠文,王翾
(1.中国传媒大学广播电视数字化教育部工程研究中心,北京 100024;2.国家新闻出版广电总局哈尔滨监测台,哈尔滨 150089)
1 引言
随着现代广播电视数字化技术的迅猛发展,全国各地市都已经或者正在建立自己的数字系统。监测工作的重心已有过去的播出质量效果监测为主逐渐向着兼顾内容监测发展,不仅要确保节目的正常播出,还需要了解和掌控各套节目的内容。字幕是视频内容的高度概括,如果能被自动的检测、分割、识别出来,可以很容易的实现对播出内容的掌控。所以,视频字幕提取技术被看做当前广电实现内容监测的主要技术之一,引起了大家的关注与研究。
本文对于字幕提取各个相关技术的研究现状及其有关方法进行了综述分析,针对广电监测,以新闻视频为例,设计视频字幕提取的有关算法,进行了实验仿真分析。针对网络传输易造成图像质量下降的因素,选取不同分辨率的视频进行了测试,验证了字幕提取技术在广电内容监测中的应用。
2 新闻视频的字幕特点分析
新闻视频是日常生活中接受外界信息的重要途径之一,其字幕有很多固定的特点。本文选取新闻视频进行实验仿真,必须分析新闻视频字幕的有关特点,以便在后续的实验分析中结合其特点选取行之有效的方法。
新闻视频的字幕可以分为两类,场景字幕和标注字幕。场景字幕是摄像机拍摄到的,是图像的一部分,如新闻视频中所拍摄的文字,车牌号等,如图1所示,字幕出现的时间、位置大小都不固定,并且与背景对比不大,此种字幕比较复杂,难以识别检测,并且没有实际意义,一般我们不会提取此字幕。标注字幕是通过后期合成加入视频中的,包含了对当前新闻视频内容的高级语义的信息描述。此类字幕包括:新闻视频的片头片尾字幕,采访中的人物对话,和概括新闻事件人物时间地点的标题字幕,其中标题字幕是我们需要的一类,如图2所示。
视频中字幕所包含的特征十分丰富,尤其是标注字幕,因为它都是后期加上去的,一般都会遵循一定的规则。对于新闻中标题字幕的特征[1],主要有以下几点:
(1)新闻视频中的字幕都有一定的尺寸,同一个新闻节目,字幕的尺寸是固定的,宽和高有一定的比例,字与字之间的空隙也是一定的,并且采用通用而且规范化的粗笔画字体如黑体和宋体。
(2)字幕与背景之间有较强的边缘,字幕都有一个单一颜色的矩形框作为背景,此背景的颜色与视频中大背景有较强的对比,并且字的颜色与字幕背景的颜色也有一定的对比度。
(3)字幕的位置在同一套新闻视频中是固定的。
(4)字幕的显示都有一定的持续时间,根据统计,字幕的持续时间最少为5秒,一般在5秒到20秒不等。
以中央电视台新闻联播为例,从图2中可以看到,文字以白底为主,到文字末尾会有渐进的背景颜色掺入,文字颜色为蓝色,与背景有较大差别,有很强的识别度。

图1 场景字幕

图2 标准字幕
3 视频字幕提取中关键技术的综述分析
视频字幕提取主要包括字幕事件检测,字幕区域定位和提取,字幕分割,字幕识别等相关技术。国内外很多学者对字幕提取进行了研究,对于其相关技术提出了很多方法。
3.1 字幕事件检测
在一个视频序列中,许多图像中不含有字幕并且很多图像中的字幕是重复的,如果对每一帧图像都进行字幕的定位和提取,必然会浪费很多时间。字幕检测作为视频字幕提取技术的第一步,可以避免对每一帧图像都进行耗时的字幕区域的定位和提取,以及后续的字幕识别,从而提高算法的效率。
对于字幕事件检测,Kim[7]等人提出一种算法:用场景转换检测方法从视频中选择一帧作为包含文本的候选帧,在场景图像中每隔2秒选取一帧作为含有字幕的候选图像,然后对比两帧图像,判断是否含有字幕。蔡波[4]等人提出用相邻两帧图像之间的局部欧式直方图的差值来检测字幕事件。
总结现有的字幕检测算法,大部分都是根据字幕像素在时间域的变化来检测图像中是否含有字幕,但是这种算法受限于字幕的位置、形状和大小,极易受到场景转换的影响。
3.2 字幕区域的定位和提取
字幕区域的定位及提取是字幕提取技术的关键环节,其正确性直接影响最终的识别效果。但由于字幕在字体、大小、对齐方式和排列方式方面具有很大的变化,以及有时受背景与标题对比不明显,图像分辨率低下的影响,到目前为止,很难找到一个最优算法来定位字幕区域。许多研究工作者做了很多研究工作,如Smith等人提出了一种在视频帧中检测文本的算法[2]。该算法将文本看作是具有聚类边的水平矩形结构并利用这个特征识别帧中文本,并且利用在连续多帧中出现的相同文本来增强检测性能。T.Sato等人提出如下算法[3]:首先用一个3×3水平差分滤波器对整个图像进行处理,再用合适的二值化门限提取垂直边缘特征,通过检测聚合部分和计算它周围的矩形指定出独立的字幕区域。蔡波等人提出一种算法[4]:该方法首先进行边缘检测、阈值计算和边缘尺寸限制,最依据文字象素密度范围进一步滤去非文字区域的视频字幕。
对比分析现有的几种方法,我们可得:(1)利用纹理特征的方法,能够检测出复杂背景下的文字,但计算量大,稳定性不好。(2)基于模糊C-均值聚类算法,很难找到合适的C—均值聚类算法的初始聚类中心,并且需要利用到新闻字幕条的颜色特征。然而不同节目的新闻字幕条颜色差异很大,如新闻联播是白底蓝字,北京新闻是红底白字,很难找到统一的标准,因此需要根据节目不同选取不同的初始聚类中心。(3)基于机器学习的方法,其检测效果较好,但算法复杂,需事先有样本进行学习分类器的训练。(4)基于边缘检测的方法,简单易行,但需要参数的约束设置,错检和漏检率比较高。
3.3 字幕分割和字幕识别
字幕分割也是图像分割的一部分,就是把字幕区域图像分成若干个特定的、具有独特性质的区域。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。其中阈值分割是一种简单高效的图像分割技术,阈值分割[6]有很多种方法:最大类间方差法,基于熵的阈值分割法、最小误差法,共生矩阵法,矩量保持法,简单统计法,概率松弛法,模糊集法以及与其他方法相结合的阈值分割法。
字幕识别是整个提取技术的最后一步,这一技术的识别效果直接关系到整个提取方法的优劣性的评价。现有的关于OCR识别的方法错综复杂,一定时间内很难研究和改进出最优的算法,同时现有的OCR识别软件效果已经很不错。所以,我们暂且没有对于这一部分进行研究,而是选在现有的OCR识别软件完成字幕识别。
4 广电内容监测中视频字幕提取的实现
视频字幕提取包括很多步骤,每一个步骤又有很多算法。一个算法在视频类型、大小、分辨率等方面不同时,所展现出的效果往往是不同的。对于广电内容监测,必须考虑准确性,时效性等多方面的因素。所以需要结合视频的类型,分析现有的算法,综合考虑其对于整个过程的影响,最终确定各个环节的算法。该实现主要包括两方面的内容:算法设计和仿真实现。
4.1 广电内容监测中视频字幕提取算法的设计
4.1.1 字幕事件检测的算法
本文的实现过程以新闻视频为例,通过上面的新闻视频的特点分析,我们得出:新闻标题字幕帧中的字幕和背景对比明显,标题字幕周围会有一个单一颜色的矩形框与背景分别开,经边缘检测[5]后会出现边框,通过边框可以完成字幕帧的初步检测,如图3所示。

图3 边缘检测效果图
首先对几种边缘检测算子检测字幕边框的效果进行了分析对比,得出:Roberts算子检测出来的字较为清晰,但字幕边框有断裂现象。Sobel算子和Prewitt算子检测边框效果较好,但相比于Roberts算子,有的文字有缺笔画现象。canny算子检测出的文字不清晰,字幕边框效果也不好。综合考虑,进行字幕边框检测使用Prewitt算子。在提取字幕帧后,选择Roberts算子来进行字幕间帧差,剔除重复字幕帧。
经过Prewitt边缘检测后,图像中带有边缘框的字幕有两种,一种是本文主要检测的主题字幕,另一种是我们现在暂不考虑的人物采访时的对话字幕,这种字幕帧是需要去除。继续分析新闻视频的主题字幕,以中央电视台新闻节目为例,标题字幕和对话框字幕存在最大的区别是:标题字幕的字幕区域背景颜色是白色,字是蓝色。对话字幕的字幕区域背景颜色是白色,字也是白色。所以在边缘检测后,采用颜色统计的方法去除人物对话字幕帧,完成字幕帧进一步检测。
我们还要考虑另外一点,在新闻视频中,同一字幕会在连续几帧的固定位置出现,大约持续5到20秒不等。经过上面两步操作保留下来的帧图像会包含大量相同的字幕帧,为了减少后面的计算量,保证每一个字幕帧只被进行一次操作。本文每5秒抽取一帧,同时利用帧差法,将相同的字幕帧去除。
结合以上分析,字幕事件检测的大致流程是:利用FFMPEG将视频流转化为帧图像,每隔五秒抽取一帧,灰度化处理,分别用Prewitt算子和Roberts算子处理灰度图像,统计经过Prewitt算子边缘检测后图像中各行连续边缘像素的数量,设置阈值,判断是否有边框。在确定存在边框的前提下,统计原彩色图像大致字幕区域的字体颜色的数量,以中央电视台为例,统计蓝色的数量,设置阈值范围,判断是否为主题字幕帧。在确定为主题字幕帧后,就是将Roberts算子处理的边缘检测图像与前一帧的同样的图像相减,去除重复的字幕帧。最后将含有主题字幕的图像编号保存。大致步骤如图4所示:
4.1.2 字幕区域定位、提取的算法
结合前面的字幕事件检测的有关操作,本文选择采用边缘检测的方法完成字幕区域的初步定位,然后考虑标题文字的位置及区域大小、文字自身大小、文字区域像素密度等特征来完成字幕区域的定位。
由于新闻视频中的标题字幕都出现在图像的最下面的四分之一区域,所以定位和提取只考虑图像的最下面的四分之一区域。具体做法是:

图4 字幕事件检测步骤
步骤1:将标记好的带有主题字幕的图像进行灰度化,然后用Prewitt算子进行边缘检测。
步骤2:定位字幕行
·计算图像中各行边缘像素值,同时求行均值,记为t1。
·寻找出边缘图像中行边缘像素值大于t1的行,继续计算这些行边缘像素的均值,做为行区域定位的阈值,记为T。
·遍历图像的下四分之一区域,找出区域中满足大于T的行,标记好其位置。
·根据字幕区域大小限制以及字幕汉字高度一般要大于5个像素值且小于48个像素值,去除不相邻的行并合并间隔小于三的行区域,然后去除高度小于5和大于48的行区域,最后标记好满足上述条件的字幕行的位置。
步骤3:定位字幕列
将已标记好的各个字幕行区域在原字幕帧图像中提取出来,然后针对列向量,对这些图像重复步骤2的操作。标记好各个行区域中满足条件的列位置,从而完成字幕区域的定位。
步骤4:字幕区域提取
为了保证字幕的完整性,将字幕行区域上下增加两行,字幕列区域左右增加两列,并将其从原图像中提取出来,保存。如图5所示:

图5 提取出来的字幕区域
4.1.3 字幕分割和识别的算法
本文使用现有的OCR软件进行识别,只需把背景和目标区分开,所以选择基于阈值的分割法。在有关阈值的分割算法中,最常用并且效果比较好的是最大类间方差法,即Otsu算法,通过最大化类间方差选择一个全局最优的阈值,使得背景和目标之间分离性最好,实现图像的二值化。为了能够简单实现,在兼顾效果的同时提高运算速度,本文将类间距离公式做了简化,即
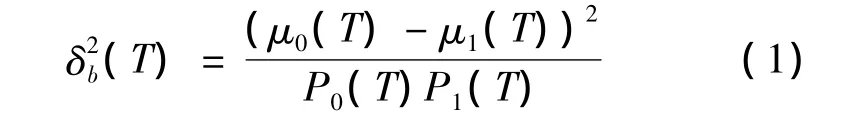
在完成字幕区域的图像二值化后,选取现有的比较成熟的OCR识别软件,将二值化图像送入OCR软件完成识别。
4.2 仿真实现
根据上文各个环节选择的有关算法,利用matlab及汉王OCR识别软件完成仿真实验。首先利用边缘检测技术及新闻视频字幕的特点进行关键帧的提取,即字幕事件检测,接下来就是对提取到字幕帧进行字幕区域的定位、提取,然后选择合适的阈值对提取出来的字幕区域进行二值化,完成字幕的分割,最后将二值化的字幕送入OCR软件,完成识别。实验流程如图6所示:

图6 字幕提取流程
5 实验结果分析
选取几段不同的新闻联播视频进行仿真测试,对于实现过程的各个部分的优劣性进行评价,由于本文并未对OCR识别进行研究,所以我们着重考虑字幕事件检测和字幕区域的定位和提取两个方面。
对于字幕事件检测,我们用查准率和查全率来衡量,查准率指正确检测出的字幕帧占检测出的字幕帧的比率,查全率指正确检测出的字幕帧数占实际的字幕帧总数的比率。实验结果如表1所示:

表1 字幕帧检测结果
通过上表我们可以得出,对于各段视频基本上都能将全部的字幕帧检测出来,即查全率几乎能达到100%,但检测出来的图像中含有很多重复的字幕帧和没有字幕的图像帧,即查准率不高。因此,我们选取的字幕帧检测算法不会发生漏检的情况,可以满足内容监测的全面性的需要,但是会发生错检的情况,把没有字幕的图像帧保存下来,这样会加大系统的存储量和运算量,这样会给系统的实时性带来很大的麻烦,需要我们在以后的研究中改进现有的算法,提高其准确率。
对于字幕区域的定位和提取,我们用正确检测出来的字幕帧进行实验,定位和提取字幕区域准确率在80%以上,错误主要是区域提取不完整。同时考虑网络环境对于该部分的影响,选取一段视频进行不同分辨率的变换,得到各种尺寸大小的图像,进行定位和提取。分辨率过高,定位和提取的效果不好,分辨率过低,分割的效果不好。当分辨率满足要求时,总体的定位和分割效果比较理想,错误主要集中在字幕的结尾处,字幕区域的底色渐渐融入背景,使字幕与背景对比度变差。
6 结论
对于字幕提取,有很多专家学者在研究,也提出了很多不同的算法。本文对其相关技术进行了综述分析,又以新闻视频为例,选取合适的算法进行了仿真实验。选取了不同分辨率的新闻视频进行了测试,指出了分辨率对字幕识别的影响。
但是本文选取的视频还比较单一,尤其是字幕事件检测算法对于视频的类型要求比较严格,算法的鲁棒性比较差。在以后的工作中,扩大视频的选材范围,对于字幕提取的相关算法进行改进,着手研究OCR识别部分。争取早日完成系统实现,进行实时的内容监测试验。
[1]李默,李弼程,苏大伟.新闻视频中标题条检测及文字内容提取算法[J].电视技术,1002-8692(2005)08-0147-03.
[2]M A Smith,T Kanade.Video skimming for quick browsing based on audio and image Characterization Camegie Mellonniv.Pittsburgh PA,Tech ReP,CMU -CS-95 -186,1995,6.
[3]T Sato,T Kanade,E K Jughes,M A Smith and S Satoh.Video OCR:indexing digital news libraries by recognition of superimposed captions.ACM Multimedia Systems:Special Issue on Video Libraries.1999,7(5):385 -395.
[4]蔡波,周洞汝,胡宏斌.数字视频中字幕检测及提取的研究和实现[J].计算机辅助设计与图形学学报,2003,15(7):898 -903.
[5]孙慧,周红霞,李朝晖.图像处理中边缘检测技术的研究[J].电脑开发与应用,2002,15(10):7-9.
[6]齐丽娜,张博,王战凯.最大类间方差法在图像处理中的应用[J].无线电工程,2006,36(7).
[7]Kim E Y,Kim K I,Jung K aIld Kim H J.A video indexing system using character ecognition.International C0nference on ConsIlⅡ ler Electronics,2000:358-359.
猜你喜欢
建材发展导向(2021年19期)2021-12-06
临床骨科杂志(2020年1期)2020-12-12
北京广播电视报(2019年8期)2019-03-27
通信产业报(2016年44期)2017-03-13
电脑爱好者(2016年24期)2017-01-05
唐山文学(2016年11期)2016-03-20
人间(2015年22期)2016-01-04
探测与控制学报(2015年4期)2015-12-15
科技视界(2014年25期)2014-04-27
雕塑(1999年2期)1999-06-28
