
一种运动轨迹引导下的举重视频关键姿态提取方法
2014-03-06 05:42王向东张静文毋立芳徐文泉
图学学报 2014年2期
王向东, 张静文, 毋立芳, 徐文泉
(1.国家体育总局体育科学研究所,北京 100061;2.北京工业大学电控学院,北京 100124;3.北京航空航天大学体育部,北京 100191)
一种运动轨迹引导下的举重视频关键姿态提取方法
王向东1, 张静文2, 毋立芳2, 徐文泉3
(1.国家体育总局体育科学研究所,北京 100061;2.北京工业大学电控学院,北京 100124;3.北京航空航天大学体育部,北京 100191)
该文研究并提出了一种轨迹引导下的举重视频关键姿态自动提取方法。针对举重训练,首先提取稳定的杠铃轨迹,进一步分析杠铃轨迹和关键姿态之间的关系,将杠铃轨迹和基于姿态集的方法相结合进行关键姿态检测。根据运动轨迹的曲线极值点提取关键视频画面,而对于其他非轨迹极值点处的关键画面采用基于姿态集的姿态估计和目标检测方法,对每个关键姿态分别训练了一个线性的支持向量机分类器,建立图像的多尺度扫描模式,并提出了统计计算相似度的方法来处理帧间相似度问题,实验表明该文方法在姿态检测的准确性和效率方面都有很大改善。
轨迹;姿态;关键帧;支持向量机
竞技体育比赛越来越激烈,为了提高体育训练的效率,有必要在体育训练中引入科学、定量的方法。许多竞技体育训练中,需要对运动员动作的准确性进行分析,这就需要提取关键的动作姿态,并进一步根据人体关节位置,提取相应训练参数。
关键姿态提取本质上是姿态估计或姿态识别问题,国内外有许多学者对这一问题进行了研究,这些方法可以分为基于特征的方法和基于人体模型的方法。基于特征的方法直接从图像中提取人体的姿态特征,并通过机器学习建立不同类型姿态的分类器用于姿态识别和估计。常用的人体姿态特征有轮廓统计特征[1-2]、圆形方向直方图特征[3]、姿态集[4-5]等等。前两种特征需要根据对象的轮廓边缘来提取,要求精确的人体分割,而背景、环境的影响使得精确度的人体分割面临很大的挑战。姿态集[6]是一个给定视角下的人体姿态的一部分,每个姿态集都是由图像的梯度直方图[7]HOG特征训练学习的一个分类器,图像的 HOG[8]特征对图像局部出现的方向梯度次数进行计数,这种特征计算是基于空间一致性的密度矩阵来提高准确率,因此被广泛采用。基于模型的方法首先建立人体姿态空间表示,用图像特征描述人体的各个部分,通过图像特征推断求解所对应的空间姿态,确定人体姿态。在文献[9]中采用了人体的棍状模型,通过数据库,多角度、多姿态训练得来的运动先验树模型,确定姿态的空间表示,身体部分模型采用密集采样的形状上下文描述符子并用 AdaBoost训练得到显著分类器。文献[10]扩展了最初图形结构的模型,加入了人体半肢颜色对称的限制,通过两次迭代过程,最终确定了人体姿态。
本文针对举重运动员训练,提取关键姿态。举重运动一般分六个阶段[11]:预备提铃、伸膝提铃、引膝提铃、发力、下蹲支撑和起立,相邻两个阶段的切换帧为关键帧。如图1所示,其中有些姿态对应于杠铃运动轨迹的极点位置,有些则不然,这就说明有些关键姿态可以通过杠铃轨迹来确定,有些就需要用其他的方法来提取关键帧。

图1 举重运动过程及关键字姿态帧
针对上述现象,我们提出了一种轨迹引导下的关键姿态提取方法。首先用一种点相关统计特性的目标跟踪方法[7]跟踪杠铃的中心点,得到运动轨迹。根据运动轨迹的曲线极值点提取关键视频画面,而对于其他非轨迹极值点处的关键画面采用基姿态集的姿态估计和目标检测方法,主要利用图像的HOG特征,训练每个姿态的支持向量机分类器,建立图像的多尺度扫描模式,根据统计结果确定最佳关键帧。
1 举重训练视频中杠铃运动轨迹与关键姿态的关系分析
图2为一段举重视频对应的杠铃运动轨迹,运动过程中的关键姿态如图3所示,为了方便后续分析,为图2建立图像坐标系。原点位于图像左下角,水平向右为x 轴正方向,竖直向上为y轴正方向,可以看出,在运动员举重过程中,杠铃在x方向运动不明显,主要表现为y方向的运动,因此我们描绘举重过程中,杠铃的y坐标随时间变化的情况,如图4所示,并且在图中顺序的标注相应的5关键姿态帧,其中图3中的5个关键姿态帧分别对应了图4运动轨迹的5个点。

图2 杠铃中心点的运动轨迹和图像坐标系

图3 举重视频中的5个关键姿态

图4 举重视频杠铃中心点y值变化和5个关键姿态帧
分析对应的 5个关键姿态与杠铃运动轨迹的关系,从图中可以看出,关键姿态帧中的下蹲和起立的姿态正好在曲线的极值点处,根据运动轨迹,第4、5个关键姿态可由曲线的极值点提取出来,而前 3个关键姿态则不能根据运动轨迹提取。
综上分析,直接根据杠铃运动轨迹可以确定两个关键姿态,另外3个关键姿态与轨迹极点无关,需要引入另外的特征,因此我们设计了一种关键姿态检测方案,该方案综合杠铃轨迹和姿态集特征,能够稳定地提取关键姿态。
2 轨迹和姿态集相结合的关键姿态自动提取方案
2.1 方案框架
我们的方案结合了杠铃运动轨迹和姿态集训练方法。首先跟踪杠铃运动,这里采用武文斌等[7]提出的基于点相关统计特性的目标跟踪方法,进一步跟踪结果描绘杠铃运动轨迹,然后,根据杠铃运动轨迹确定第4和第5关键姿态,同时确定前3个关键姿态的搜索范围,采用基于姿态集的方法依次提取3个关键姿态,方案框图如图5所示。

图5 方案框图
2.2 基于姿态集的关键姿态提取算法
基于姿态集的关键姿态提取算法属于机器学习方法,也包括模型训练和姿态提取两部分,算法的框架如图6所示。

图6 基于姿态集的关键姿态检测算法框架
对于一种姿态,我们收集同类姿态对应样本作为训练集,其他姿态和背景作为负样本,图7为一组正负样本示例。提取所有样本的HOG特征[8],一种姿态训练一个分类器,每一个分类器都是一个线性的 SVM,由于我们采用了整个人体的姿态特征,因此训练的模型的稳定性较好。

图7 发力姿态的训练集样本示例
为了进一步提高算法的鲁棒性,我们设计了二次训练的框架,即用初次训练的结果对训练样本进行测试,把姿态不符合要求的检测窗口作为hardnegtives加入负样本中重新进行SVM分类器训练。
2.3 基于多尺度统计相似度的姿态检测算法
为了保证姿态检测的尺度不变性,我们对一帧图像在不同尺度上进行姿态检测。图8是多尺度检测金字塔示意图,在同一尺度下,将检测窗口以一定步长在图像平面滑动,提取对应窗口的HOG特征输入到相应姿态的分类器,即可判定该窗口是否为相应关键姿态。
设p(x,y,li,FK)代表某帧视频的一尺度下的某个位置, φ( w ,h,p,Fk)表示该帧画面中点在 p的位置窗口为w×h的HOG特征向量,W为姿态分类器的支持向量机的权重,定义:
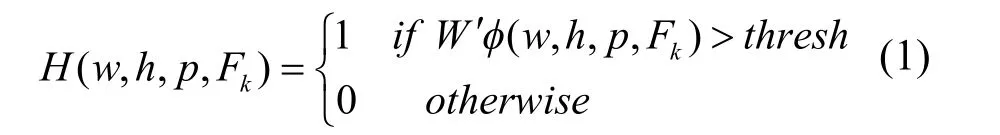
则定义在第K帧上分类器的检测点数为:


图8 多尺度扫描金字塔
在姿态检测阶段,由于空间姿态的渐变特性,可能会在连续多帧图像中检测到某一姿态的相似姿态,针对这一问题,文献[5-6]都是对检测结果进行聚类,最后给出物体的所在位置,而我们的方法则不是对检测结果进行聚类。我们提出了统计相似度的概念。将全部尺度下,相应姿态对应分类器输出相加,即得到该姿态的统计相似度ScoreK,统计相似度最大的视频帧的姿态,即为对应的关键姿态。

3 实验结果分析
3.1 实验数据
我们收集了 30段举重视频作为实验数据,这些视频有的是比赛视频、有的是训练视频,采集环境、背景都有很大不同,图9为实验训练集的几个视频。
随机选取其中的 22段视频作为训练集,8个视频序列作为测试集,每个姿态提取 30个正样本,然后将每个样本进行水平镜像操作,这样每个姿态包含 60个正样本,随机抽取视频中的300~400个窗口作为负样本。

图9 实验视频示例
3.2 二次训练的作用
为了对比一次训练的分类器和二次训练的分类器的性能,对相同的视频序列,用某一个关键姿态对应的两个分类器进行姿态检测,其统计相似度值如图10所示。
从图10可以看出,虽然两个分类器得到的统计相似度峰值相同,但显然一次训练的分类器有许多较大的干扰值,这也大大增加了误检的概率。相比之下,二次训练的分类器干扰值就少很多,也小很多,这也在一定程度上保证了检测结果的稳定性。
3.3 对比实验
对比了本文提出的方法和基于姿态集的方法,对比实验结果见表1。基于姿态集的方法对姿态4的检测结果并不好,这是由于不同运动员下蹲姿态变化较大,因此很难提取稳定的结果。而本文提出的方法,利用轨迹极点提取姿态4和5,准确度非常高。在本文中基于姿态集提取姿态1, 2, 3时,也采用了基于姿态集的方法,因此检测结果没有变化。
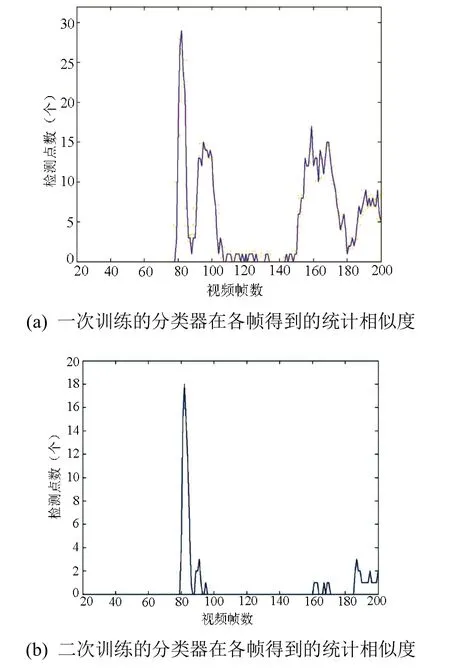
图10 两次训练的分类器检测结果对比
图11给出了一组检测结果示例图,图中前3个姿态用矩形框标出了关键姿态的准确位置,这是根据姿态及训练的样本得到的,后面两个姿态直接由轨迹极点得到,因此没有标出关键姿态的准确位置,这并不影响后续应用。
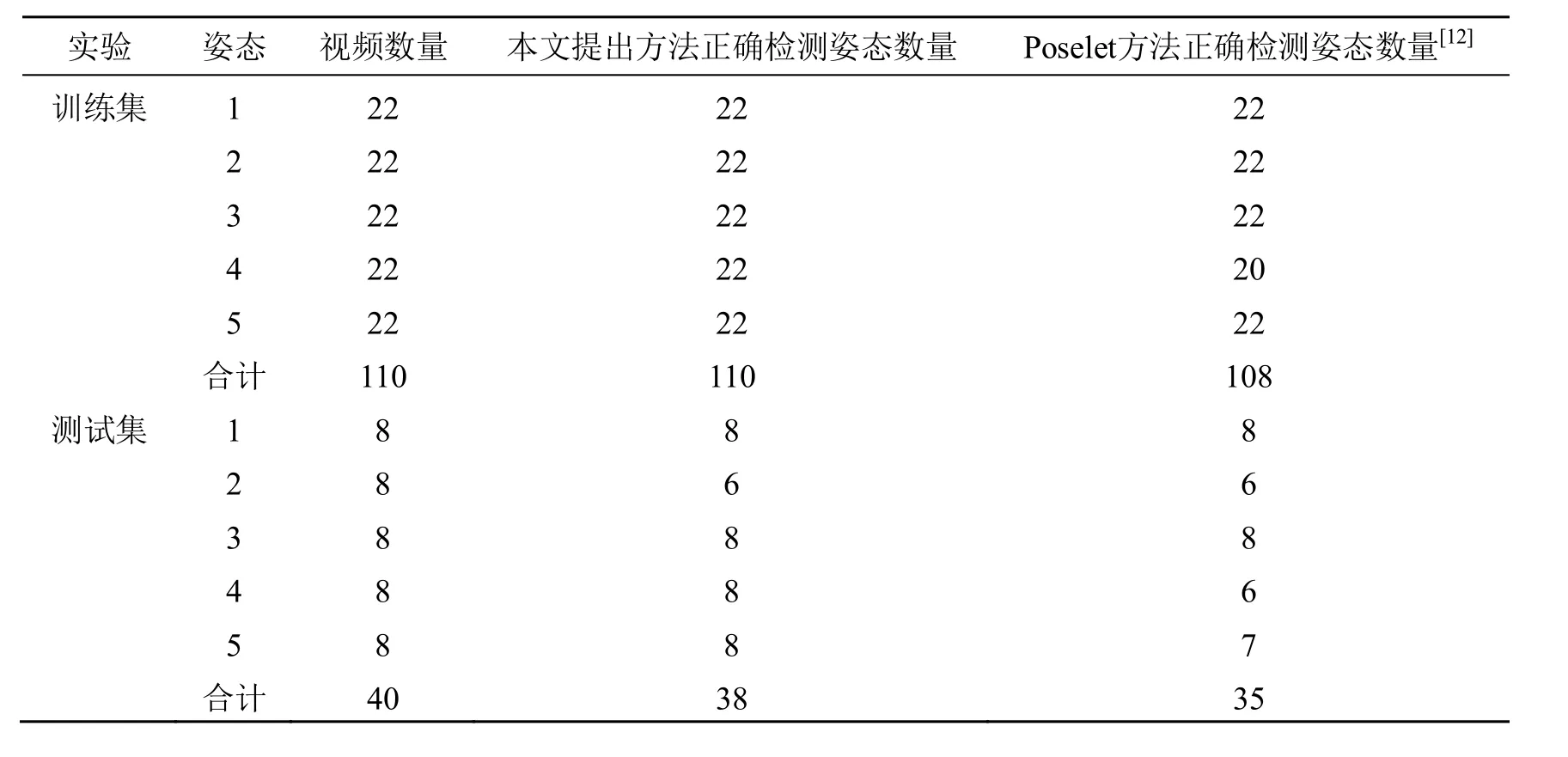
表1 实验检测结果

图11 一组检测结果示例
4 总 结
针对举重训练的应用,本文提出了一种杠铃运动轨迹与姿态集方法相结合的人体关键姿态提取方法,分析了关键姿态和杠铃运动轨迹的关系,对于和杠铃轨迹极点直接相关的姿态,直接由运动轨迹确定,对于其他非轨迹关键姿态,则通过姿态集学习方法进行姿态检测。试验结果表明:①本文方法在姿态检测的准确性和效率方面都有很大改善。②本文结果可以应用于举重训练中训练参数的提取,手工确定关键帧中关节位置,则可提取定量训练参数。③本文进一步研究工作将集中在人体关节位置的自动提取方面,以待全面实现训练参数的自动提取。
[1] Cheema S, Eweiwi A, Thurau C, Bauckhage C. Action recognition by learning discriminative key posese [C]//ICCV, Barcelona, 2011: 1302-1309.
[2] Wang Yang, Jiang Hao, Drew M S, Li Zenian, Mori G. Unsupervised Discovery of Action Classes [C]//CVPR, 2006: 1654-1661.
[3] Ikizler N, Cinbis R G, Pehlivan S. Recognizing human actions from still images [C]//CVPR, Haspolat, 2008: 1-4.
[4] Bourdev L, Maji S, Brox T, Malik J. Detecting people using mutually consistent poselet activations [C]// ECCV city: Heraklion, Crete, Greece, 2010: 168-181.
[5] Yang Weilong, Wang Yang, Mori G. Recognizing human actions from still images with latent poses [C]// CVPR, 2010: 2030-2037.
[6] Bourdev L, Malik J. Poselets: body part detectors training using 3D human pose annotations [C]// ICCV, 2009: 1365-1372.
[7] 武文斌, 毋立芳, 王晓芳, 王向东. 一种点相关统计特性的目标跟踪方法[J]. 中国科技论文, 2012, 7(1): 28-32.
[8] Dalal N, Triggs B. Histograms of oriented gradients for human detection [C]//CVPR, 2005: 886-893.
[9] Andriluka M, Roth S, Schiele B. Pictorial structures revisited: People detection and articulated pose estimation [C]//CVPR, 2009:1014-1021.
[10] Ramanan D. Learning to parse images of articulated bodies [C]//NIPS, 2007: 1129 -1136.
[11] 王向东, 毛 勇, 刘梦飞, 尚 健. 优秀女子举重运动员抓举技术的运动学研究[J]. 成都体育学院学报, 2009, 35(2): 51-53.
[12] Wu Lifang, Zhang Jingwen, Yan Fenghui. A poselet based key frame searching approach in sports training videos [C]//APSIPA ASC, Hollywood, 2012: 1-4.
A Key Pose Frame Extraction Approach Combined with Trajectory from Weightlifting Video
Wang Xiangdong1, Zhang Jingwen2, Wu Lifang2, Xu Wenquan3
(1. Sports Research Center, General Administration of Sport of China, Beijing 100061, China; 2. Department of Electronic Information and Control Engineering, Beijing University of Technology, Beijing 100124, China; 3. Institute of Physical Education, Beihang University, Beijing 100191, China)
In this paper, a trajectory guided scheme is proposed to extract the key poses frame automatically. First, the barbell trajectory is extracted from the weight lifting sport video. Then the barbell trajectory and poselet are combined for pose extraction. Some key poses are extracted from the extreme point of the barbell trajectory. But the other poses are extracted by using the poselet based algorithm. SVM(Support Vector Machine) classifiers based HOG(Histogram of Gradient) is trained for each pose. Then the pose is detected in the multi-scale images. Statistical similarity is computed in multi-scale to measure the possibility and determine which is the best key frame. It resolves the problem of higher inter-frame similarity. The experimental results show that the proposed scheme can improve both the precision and performance of pose extraction.
trajectory; pose; key frame; support vector machine
TP 391
A
2095-302X (2014)02-0256-06
2013-10-28;定稿日期:2014-01-14
国家自然科学基金资助项目(61040052);北京市优秀人才资助项目(2009D005015000010)
王向东(1973-),男,山西太原人,研究员,博士。主要研究方向为运动生物力学与运动技术诊断。E-mail:wxd219@gmail.com
徐文泉(1969-),男,北京人,副教授,硕士。主要研究方向为运动训练学与心理学。E-mail:1969110@sina.com
猜你喜欢
浙江体育科学(2022年3期)2022-05-08
学生天地(2020年3期)2020-08-25
特别文摘(2019年6期)2019-03-16
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
体育师友(2011年2期)2011-03-20
