
网络搜索中用户搜索意图识别的研究
2014-02-09 07:47齐富民谢晓尧
计算机工程与设计 2014年4期
齐富民,谢晓尧,吴 静
(贵州师范大学贵州省信息与计算科学重点实验室,贵州贵阳550001)
0 引 言
如何使搜索结果快速准确尽可能的符合搜索者的意图,是现阶段需要解决的问题。关于搜索意图识别问题,前人已经做过相关的研究,如文献[1]中提出利用搜索上下文来预测用户的搜索意图,该方法虽在一定程度上可以达到用户搜索意图识别的目的,但是存在相关技术缺陷,如,当使用上下文的方法来进行搜索意图识别时,搜索结果将受前一次用户的搜索关键词的影响,若两次搜索的原始意图完全不同,那么后一次搜索结果的准确率将大打折扣。文献[2]中提出使用基于用户搜索日志的方法,利用对用户的搜索日志的分析来预测用户的搜索意图,该方法从用户本身的搜索日志入手考虑,在一定程度上达到了搜索意图识别的目的,但是在很多时候,简单通过用户的搜索日志来分析搜索意图,不同的人具有不同的搜索习惯和需求且搜索出来的结果具有很强的主观性,实验结果表明该搜索意图识别方法得到的搜索结果正确率不高。文献[3]中提出基于决策树的方法进行用户搜索意图识别,该方法虽然对搜索意图识别有一定的帮助,但是在处理高纬度数据方面效率较低,且在查询出的结果方面意图覆盖面不广。如无法一次尽可能多的查询出用户想要的结果,只能依据决策树的构建来完成查询操作,有一定的局限性。针对以上搜索引擎中对用户搜索意图识别研究中暴露出来的诸如搜索结果关联影响、搜索意图预测依据单一、搜索意图预测模型范围局限等问题,本文利用最小二乘支持向量机对开源的网络爬虫(nutch)爬取到数据进行预先归类以及对用户输入进行处理,通过参考答案和学生给出答案的对比模式来解决分类意图识别的问题。在此过程中对于最小二乘支持向量机的参数设置一直是研究的热点[2-5],当用户在客户端提交搜索关键词时,服务器端通过对关键词进行归类预测,再从已经归类处理过的网页文件中搜索出相关结果,最后将相关符合项列出来。如此,对用户搜索意图识别问题进行分解,即同样的特征向量库和分类技术分别用于网页文件离线处理和用户输入处理。
1 最小二乘支持向量机用于搜索意图识别
本文利用最小二乘支持向量机(least squares support vector machine,LSSVM)解决用户搜索意图识别的问题,将LSSVM作为搜索意图识别器,应用于用户搜索意图识别模型中的网页文件离线处理和用户输入处理两个方面。
1.1 用户搜索意图识别
用户的搜索意图识别是指用户访问某一类数据资源或服务时,数据资源或服务的提供商有导向的为用户提供其所需,是一种为用户提供便捷的技术手段。目前用户搜索意图识别可归结为几种类型[8-10]:
查询互动型:这种方式基于网页机器人,用户输入指定的关键词,网页机器人提供与之相关的主题链接,其实质是一种搜索服务,不同点在于用户可根据搜索结果和网页机器人提供的纠正选项,通过人机交互达到识别搜索意图的目的。
导航型:目前国内搜索引擎提供商等都提供了综合的信息导航服务网站,其将用户经常可能会使用到的网站进行归类,为用户提供分类向导,达到预测用户搜索意图的目的。
检索型:这种就是我们常见的搜索引擎,其将相关的包含关键词的网页罗列出来,达到用户搜索意图识别的目的。
捆绑型:用户在下载或查询某数据资源时,资源提供商顺带在资源文件或包中捆绑相关的信息,猜测用户搜索意图。
本文的搜索意图识别问题属于检索型,基于B/S架构,客户端输入关键词后,服务器端对用户的输入根据自身已经训练好的预测模型对客户端的输入进行预测,根据预测的结果从相关的主题中找出最为符合的项目送回客户端。
1.2 最小二乘支持向量机
支持向量机(support vector machine,SVM)[4,5]是Vapnik等人提出来的一种统计学VC维理论的机器学习方法,SVM可以将低维度不可分割的集合映射到高维度,进而在高维度找出线性可分的超平面。LSSVM是在SVM的基础之上发展而来的。LSSVM用线性方程组的形式实现最终的决策函数,提高了问题的求解速度,适用于大规模问题。其与SVM的不同点是:LSSVM引入的损失函数εi不同以及约束条件不同,如下所示[4]
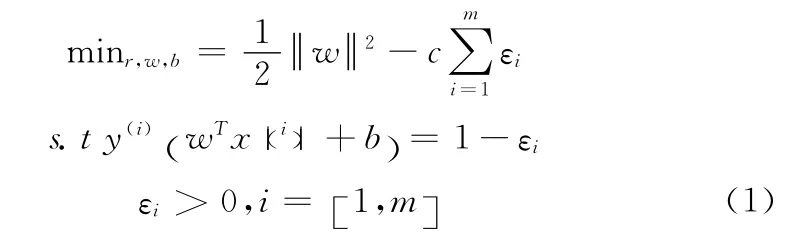
此时满足KKT条件,式(1)通过拉格朗日函数来求解,如下所示
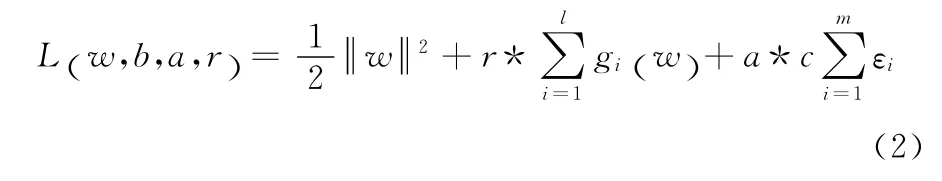
对式(2)进行拉格朗日求解,此求解过程相当于解线性方程组。
最终LSSVM算法的决策函数可以由式(3)表示[4]
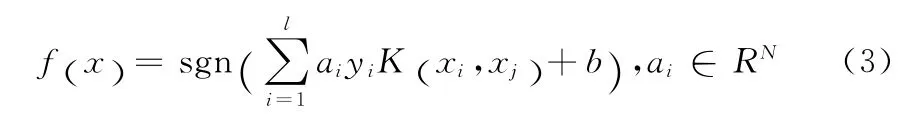
式中:K(xi,xj)——核函数,本文中利用的是RBF核函数,其引入是为了解决当文本的维度过高时,产生的维度灾难问题。本文利用LSSVM对语料库中的语料进行分类识别并建立分类模型。首先将语料库中的词汇按照分类别进行词频统计,然后将统计结果归一化处理,生成便于LSSVM处理的归一化数据,再将这些带有分类标识的向量集合作为训练样本用于训练分类模型。最后将分类模型用于用户输入的归类。
在LSSVM分类器中,分类的结果是否准确以及分类器的泛化能力的大小受到分类器中核函数宽度参数以及对错误样本容忍度参数的影响,故下面章节利用粒子群优化算法寻找这两个参数。
2 粒子群优化算法设置分类器的参数
本文中使用粒子群优化算法(particle swarm optimization,PSO)的目的主要是解决LSSVM的核函数参数和泛化参数设置问题。因为LSSVM参数设置的好坏影响到分类器分类准确率,而分类器的准确高低直接影响到用户分类意图识别的准确率。下面从两个方面对粒子群优化算法进行叙述。
2.1 经典PSO用于LSSVM参数设置
粒子群算法是由美国心理学家Kennedy和电气工程师Eberhart等人于1995年提出的一种全局优化进化算法,其基本思想源于对鸟类捕食行为的模拟[5]。
设粒子群的规模为S,其维度为D且在D维空间内存在可能的最优值,粒子移动的目的在于在找出全局空间中能使目标函数的适应值达到最优极值点时所携带的参数值。第i个粒子的飞行位置用Xi={xi1,xi2,…,xij,…,xiD}表示,其中i=[1,s],j=[1,D],第j个粒子的飞行速度与方向用Vi={vi1,vi2,…,vij,…,viD,}表示,其中i=[1,s],j=[1,D]。全局有两个记录目标函数的变量gbestc和gbestg,这是文章中支持向量机所需要寻优的两个参数。局部对应两个变量pbestc和pbestg。用这4个变量分别记录目前最优的全局变量和局部变量。粒子群优化算法中的速度更新公式以及当前位置的更新公式如下[9,10]
式(4)中

式中:w——惯性权值因子,用来控制全局搜索步长的能力。c1和c2——学习因子,c1和c2的大小表示粒子对全局或者局部的飞行速度和方向的偏好程度。r1和r2——两个随机数,这两个因子的加入使得速度变动更具备随机性。
可以根据粒子群更新式(4),看出式(4)的第二项和第三项,除了受到c1和c2的影响外还受到两个随机参数的影响,这样就削弱了c1和c2的影响,变成了一个近似概率性的问题,这样计算出来的Vij(t)就有可能超出寻优域的边界值,这样做的好处是减少陷入局部最优的概率,但是带来了新的参数越界问题,这将增加边界搜索的聚集密度,从而造成寻优不充分。
2.2 改进型PSO用于LSSVM的参数设置
基于以上经典PSO算法的分析,我们得知其主要存在两个方面的问题:一方面,粒子群的寻优粒子如果过少,寻优将不充分。另一方面,寻优域过大将导致陷入局部最优的概率变大,且在陷入局部最优时逃离局部最优的过程有可能由于参数越界问题导致寻优参数聚集到边界上,从而造成找不到LSSVM所需的最优参数。PSO算法在用户意图识别器LSSVM的参数选择问题上,本文对PSO的寻优策略从局部最优搜索和全局最优搜索两方面进行了改进。
(1)局部搜索改进
局部搜索的改进主要是为了解决粒子在逃离局部最优时携带参数的越界问题。为了后面的叙述方便,将后期需要用到的内容定义如下:
定义 设粒子群移动的次数称为寻优代数,用N表示。寻优的范围称为寻优域,用D∈[xi,xj]表示。xi,xj表示第i个需要寻优参数的寻优边界的最小值以及寻优边界的最大值。粒子群每一次移动的长度,用di表示。每次实际移动的长度,用dci表示。
式(4)中随机函数的引入,使得速度更新的大小和方向的变化变得不可测。如果此时速度超出了寻优域边界,那么在更新粒子群当前位置的时候,粒子群将超出寻优域边界。为了解决这个问题,传统的做法是使得超出边界的粒子携带的参数等于边界,这样当超出边界的粒子过多时就会造成边界聚集的现象,浪费寻优机会。本文的做法是引入sigmoid函数利用将原本成比例的数据映射到[0,1],仍然保持了一定的比例关系,在超出边界时不是人为地将参数设置在边界上,而是动态地进行更改,sigmoid函数如下所示
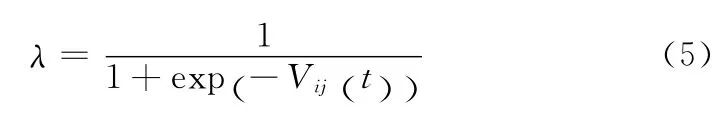
依据以上思路,本文将PSO算法的位置更新式(4)中的w变换成式(6)所示
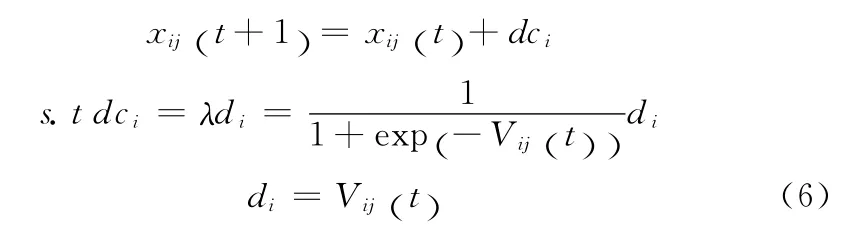
式(6)可以看到dci=[0,1],此时如果单纯的用dci表示速度大小和方向可以得知sigmoid函数永远为正,粒子群只能向正方向运动。此时我们将式(4),变换成式(7)所示
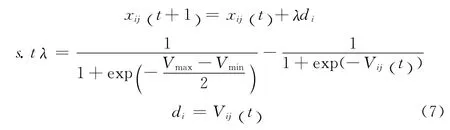
通过式(7)可以得出dci将在一个有正有负的区域上运动,这样规约出来后速度具备大小的同时也拥有了方向,其图形如图1所示。

图1 粒子速度规约
从图1可以看出,这种规约方式步长在参数的最大值和最小值所对应的sigmoid函数之间,因为其寻优步长细,搜索精细,故适合局部寻优。
(2)全局搜索的改进
全局搜索改进的目的主要在于解决粒子群搜索不均匀问题以及针对不同问题粒子群数目确定的问题。为了解决这些问题,本文将粒子群的寻优域进行分割,如图2所示。
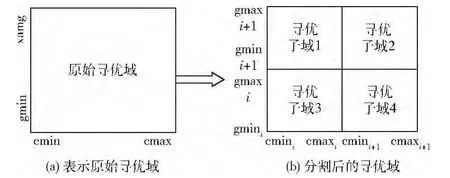
图2 全局步长的解决方案
从图2可以看出改进型PSO算法将原始的寻优问题转化为分散的多个子寻优问题进行求解,这样不仅可以解决前面全局搜索分析中遇到的问题,而且可以将大问题分割化,便于后期工作的拓展(如分布式计算)。
3 搜索引擎中用户搜索意图识别
3.1 系统架构
对于用户的搜索意图识别问题,如果站在服务器存储数据以及数据检索的角度来看。其目的是将输入文本进行归类预测,使得预测的结果与检索数据库中某一类别搜索结果尽量吻合,进而在吻合的类别中进行全文检索,从而达到提升用户搜索体验的目的。文中搜索引擎用户输入意图识别分为两部分,一部分是服务器端网页文件离线分析,另一部分是在线的用户输入意图预测。只有这两部分的预测结果吻合才能够提升体验效果。本文整个搜索引擎的架构如图3所示。
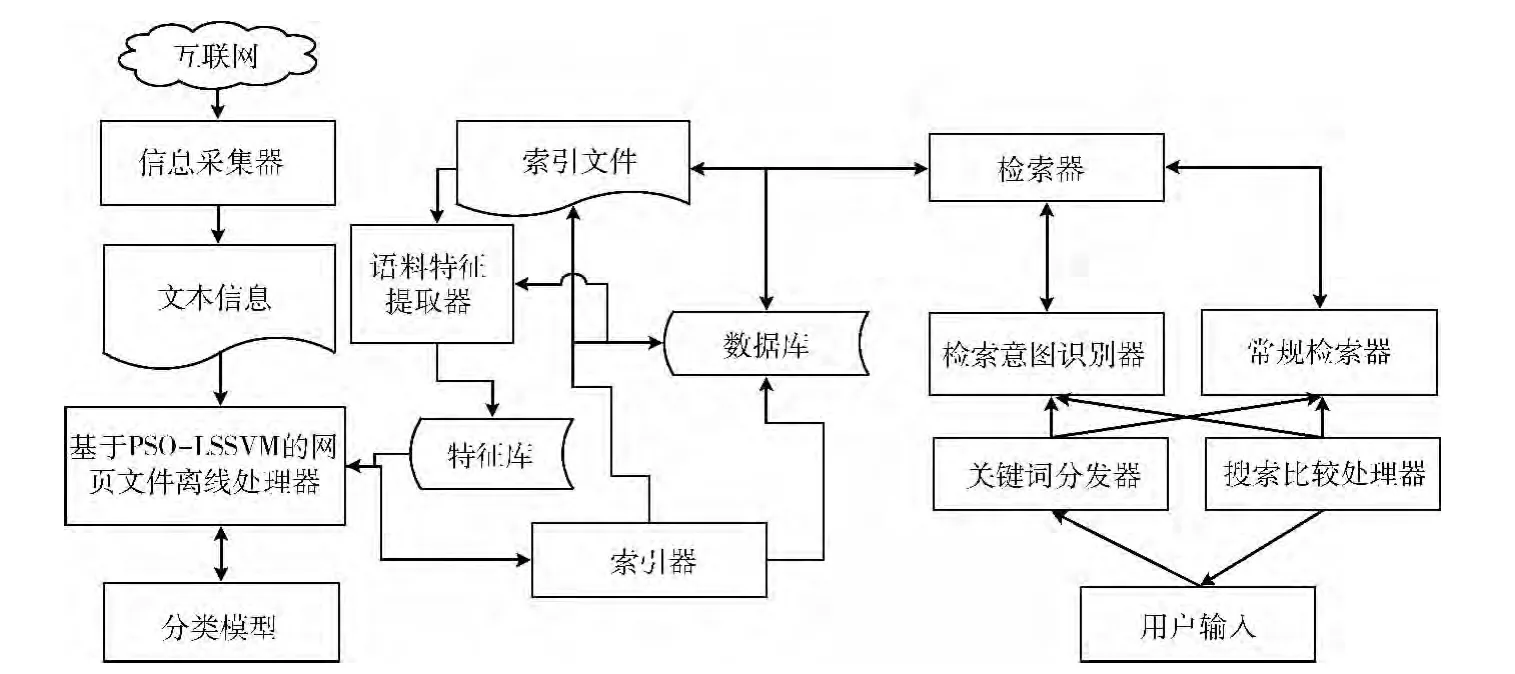
图3 分类器在搜索引擎中的应用
图3与一般的搜索引擎的模型不同点在于:首先,架构中加入了基于PSO-LSSVM的网页文件离线处理器和搜索意图识别器,这两个部件是用户搜索意图识别问题的两个组成部件。其次,为了更好的使预测器准确率不断提升,本文在搜索架构中加入了语料特征提取器,用于语料特征库的自学习,语料特征库的不断扩大,分类器的分类准确率越高。基于PSO-LSSVM的网页文件离线处理器主要解决离线文件归类问题(相当于考试中给出参考答案的过程);搜索意图识别器主要解决用户输入意图识别的问题(相当于考试中学生给出自己答案的过程)。只有当两个部件的处理结果相吻合时,才能够发挥这种搜索架构的优越性,达到用户搜索意图识别的目的。最后,在用户输入的后端加入了关键词分发器和搜索比较处理器,这两个处理器的目的在于当语料特征库中的特征不完备时,根据搜索比较器的处理结果将搜索结果进行排序,这样在不失去普通搜索引擎优势的前提下可以达到用户搜索意图识别的目的,从而提高用户搜索体验。
3.2 网页文件离线分析
文件离线分析其归类是否准确关系到搜索意图判断的准确率。本文对此问题进行了相应的探讨,先对爬虫抓取回来的结果进行预处理,其中很重要的一个步骤就是文本分类处理,在这篇文章中引入了改进型粒子群算法结合LSSVM来对抓取页面进行分类。因为爬虫抓取的数据量较大[6-8],故在线分类处理时显然不合适的,因此在提供搜索服务时采取离线方式进行,将分类结果存入检索数据库,为用户输入意图预测提供对比。文件离线分析的步骤如下:
(1)通过爬虫获取网页文件到本地,对文件按照类别特征库提取出相应的特征字符,存放于特征文件中。
(2)对特征文件进行归一化处理,对各特征文件中的特征项进行统计后归一化到[0,1]区间,并将归一化结果建立特征向量存放于数据库中。
(3)利用改进型PSO-LSSVM算法对训练样本进行建模得到模型用A表示。
(4)用得到的模型A,将数据库中的归一化特征向量进行分类预测,将相应的网页文件在数据库中建立索引,设置相应的网页类别为预测到的类别,至此网页文件离线处理完毕。
处理过程图形如图4中抓取网页文件离线处理器部分所示。
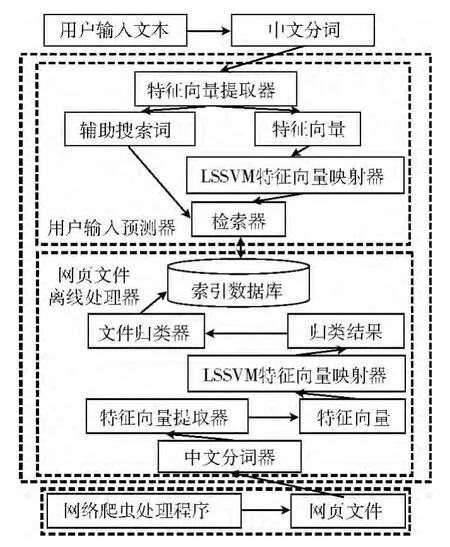
图4 搜索意图识别
从图4可以看出用户搜索意图识别依赖于分类模型,如果分类模型不准确则提升用户搜索体验的效果就有限。
3.3 用户输入意图预测
当用户在键入搜索关键词进行搜索时,如果预先可以得知关键词的所属类别,那么就可以根据相应的类别最大限度查找出最优匹配的结果。用户输入意图的识别,需要两部分相结合,一部分是用户输入的识别(相当于客户端输入识别),另外一部分是离线的文件分类(相当于服务器数据识别),用户输入意图预测器的工作步骤如下:
步骤1 用户通过人机接口界面输入搜索关键词。将接受到的关键词送入关键词分发器,由关键词分发器将关键词分发至预测器和常规检索器。
步骤2 搜索引擎接受来自分发器传入的搜索关键词,将数据送入中文分词器进行处理,中文分词器将搜索关键词进行切分处理,在中文分词器切割的过程中结合词库等辅助切割,提高切割准确率。
步骤3 用户输入预测器接受来自步骤2的处理结果,对其切割结果联合特征数据库进行统计分析,根据特征数据库提取出特征向量,将前一步的辅助搜索词进行记录。特征值提取以及词频归一化步骤如下:
(1)词频统计:实验中将语料库中的教育类、汽车类、财经类、IT等几大类别的语料进行词频统计,设用xi表示以上类别中的第i个类别,如xi表示教育类。
(2)归一化处理:设m个样本有n个指标,则可以利用(1)中的类别词频生成词频矩阵Xij,其中i=[1,m],j=[1,m]。本文利用Z-score方法对数据进行归一化操作,如下所示[11-15]
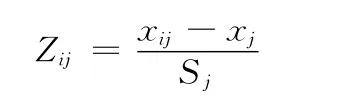
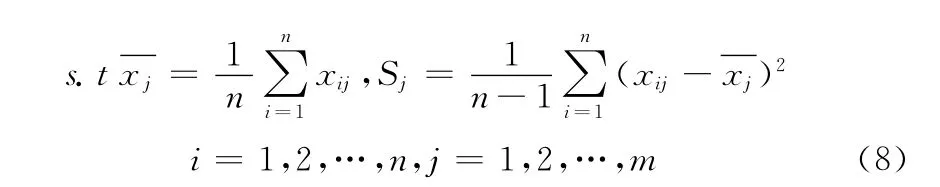
(3)特征向量获取:首先依据(2)获取的归一化数据,获取各个指标的相关性矩阵R,如下所示
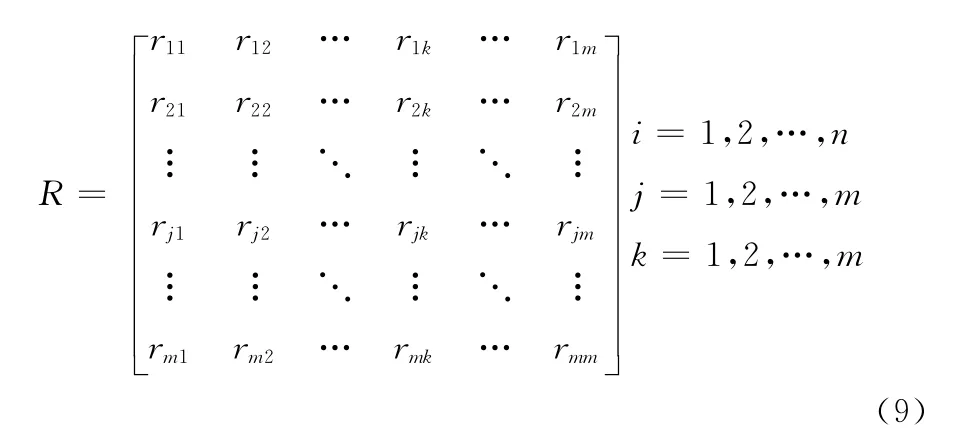
式(9)中
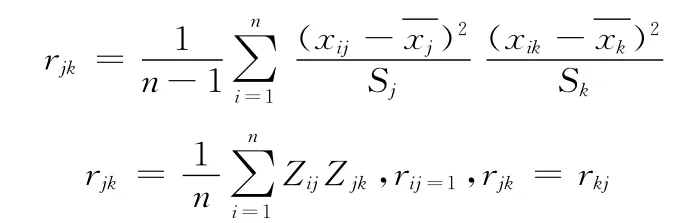
(4)依据相关矩阵R确定主成分,求解其特征根与特征向量。
(5)确定主成分的个数,依据所求得的方差贡献率来确定,特征词汇的个数依据满足式(10)的k来确定

式中:λg——式(4)中所求特征根。
步骤4 如果用户输入的关键词较短,则先将用户的输入从索引数据库中进行全文检索,将结果暂存。如果用户输入的搜索关键词比较长,那么依据特征向量,利用用户输入预测部件中的LSSVM特征向量映射器来分析出用户输入是属于哪一个领域,得到所属领域标识之后,在该领域的索引数据库中进行全文检索。将结果暂存,便于优先显示相关领域的全文匹配结果。
步骤5 用户输入预测器的检索器部分按照步骤4的结果,从相关领域中检索出用户想要的网页文件。并依据分类结果优先显示分类结果中全文匹配数据,送给搜索比较处理器进行处理。
步骤6 搜索比较处理器接收到常规搜索和搜索意图识别器的处理结果后对其结果进行比较,将意图识别器匹配度较高的放在最前显示,其后显示常规搜索中最匹配的网页链接,至此,完成用户搜索意图识别的任务。
4 实验仿真与分析
4.1 实验步骤
步骤1 训练集的获取
文章中使用的训练样本是基于搜狐研发中心的搜狗词库(该词库是搜狗实验室提供的开放式词库,该版本有157202条词目,分为N名词、V动词、ADJ形容词、ADV副词、CLAS量词、ECHO拟声词、STRU结构助词、AUX助词、COOR并列连词、CONJ连词、SUFFIX前缀、PREFIX后缀、PREP介词、PRON代词、QUES疑问词、NUM数词、IDIOM成语等17种词性组成)结合开源分词库对搜狐研发中心的搜狗文本语料库(该语料库是搜狗实验室提供的基于搜狐分类目录手工编辑的网页分类结果组织成的网页、分类结果及基准分类算法在内的综合数据集合)里面的C00020教育、C000007汽车、C000008财经、C000010 IT几大类别进行分词、量化得到训练样本。
本实验对搜狗语料库中所有教育类语料进行词频统计以及特征抽取,抽取了教育类特征词汇诸如:课程、必修课、选修课、课程表、课堂讨论、毕业典礼、毕业论文等,本文分别用1,2,3,4,5,6,7表示。教育类特征向量构成示意见表1。
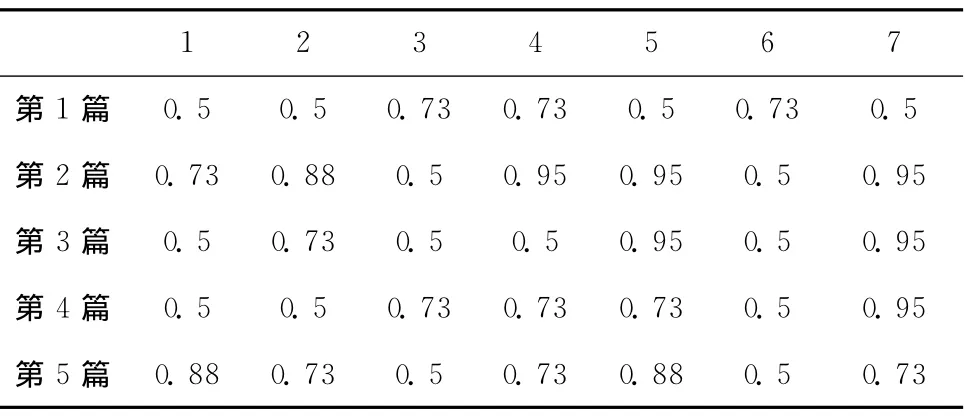
表1 教育类训练集量化样本
表1是本实验从语料库中抽取的教育类语料经过词频统计后用式(8)将其归一化后的部分结果,表中的数据越接近1表示该词汇在该栏目中出现的次数越多。
步骤2 测试集的获取
为了使实验数据更加具有科学性,实验采用Nutch将web站点上的页面抓取下来后,利用基于搜狗词库以及开源分词库将文本进行分词与校正,这样处理后的数据融合语料库中的数据作为测试集。
利用提取出来的特征向量对模型实施测试,因为LSSVM处理的是二分类问题,故文章的实验中将LSSVM运用多次,将类别两两比较,迭代的方式用于多分类问题的处理。
步骤3 分类模型的建立
对表1中样本数据建立分类模型(LSSVM),其最优分类间隔参数是不断通过用PSO算法来寻找的,直到分类错误率控制在可接受的范围内为止(根据本问题实际情况,本文容错率设置为0.08%)。
步骤4 测试集对训练好的模型进行测试,测试使用交叉检验的办法,将训练集分成若干份进行交叉检验,以保证模型的推广性。
由于实验的处理计算量大而且处理时实时性要求不高,故实验采用离线训练的方式。
4.2 实验结果与对比
(1)改进后的粒子群最小二乘支持向量机结果比较
文中搜索意图识别的效果依赖于分类效果,为了突出实验效果,首先使用普通的支持向量机(SVM)、神经网络分类器、普通的PSO-LSSVM以及本文改进后的PSO-LSSVM等算法,对同样规模的文章进行分类效果比较,首先将训练集分为6等,每一等级的文章数量不同,实验中分别取10,50,150,200,500,1000进行对比,总体的训练样本每一等级都从训练样本中取3份相同大小的集合用于交叉检验,第一次训练时,用第一和第二份作为训练集,第三份作为测试集;第二次训练时,用第二份作为测试集,第一和第三份作为训练集;第三次训练时,用第二和第三份作为训练集,第一份作为测试集。实验的对比结果见表2。
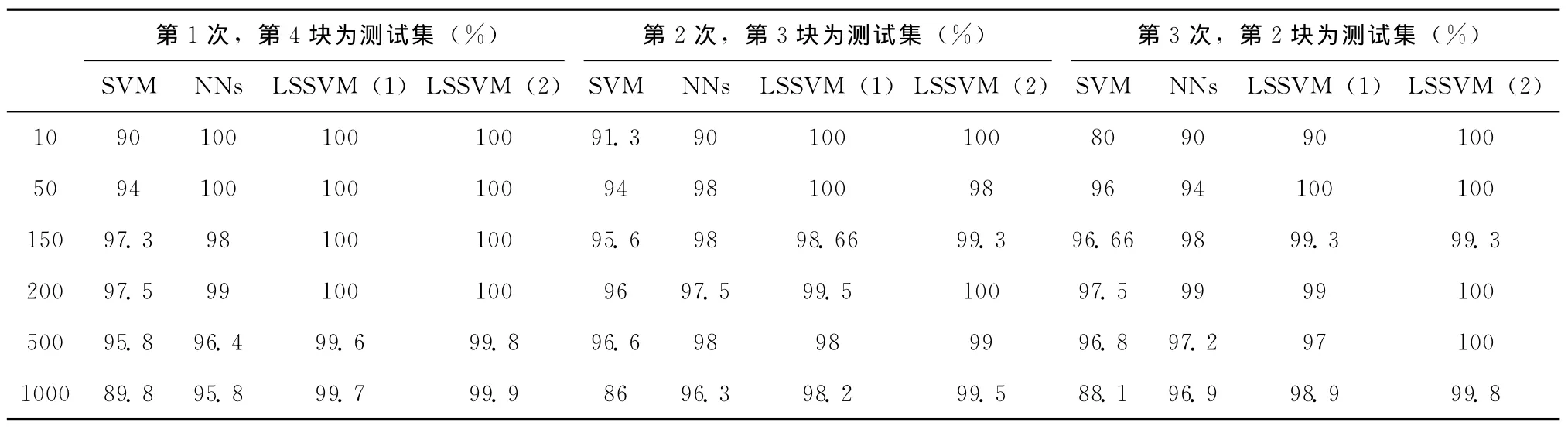
表2 改进型PSO-LSSVM 与其它分类算法用于文本分类的对比
表2中LSSVM(2)表示的是改进后的PSO-LSSVM,LSSVM(1)表示的是为改进前的PSO-LSSVM算法,NNs是神经网络,SVM表示普通的支持向量机。
根据表2实验结果,将实验数据进一步进行分析,得到SVM,NNs,LSSVM(1),LSSVM(2)效果对比情况,见表3。
从表3可以看出SVM的分类效果不尽理想,这种现象的发生在于人为选取参数的不合理。NNs与LSSVM(1)的平均适应度都不如改进后的PSO-LSSVM。
(2)分类结果与用户分类意图识别的关联性实验
从搜狗语料库中随机抽取文章,依据分类特征库结合分词工具摘取文章中的关键词进行词频统计以及归一化处理,利用本文的搜索模型进行测试搜索,我们得到一个关于文章分类准确率与用户搜索意图是否匹配以及搜索时间等方面关系表,见表4。
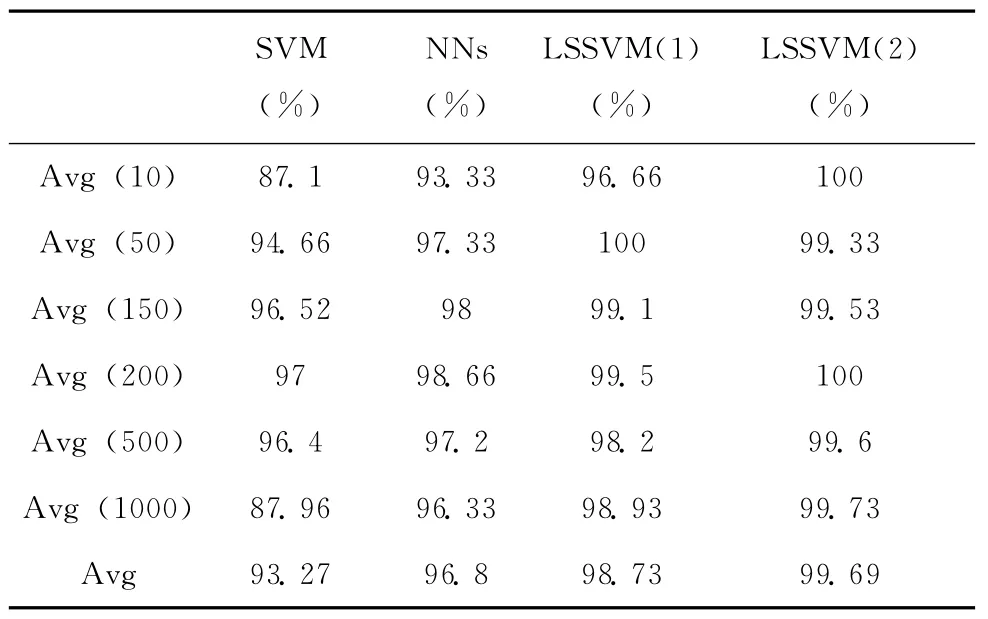
表3 SVM,NNs,LSSVM(1),LSSVM(2)交叉分类准确率对比
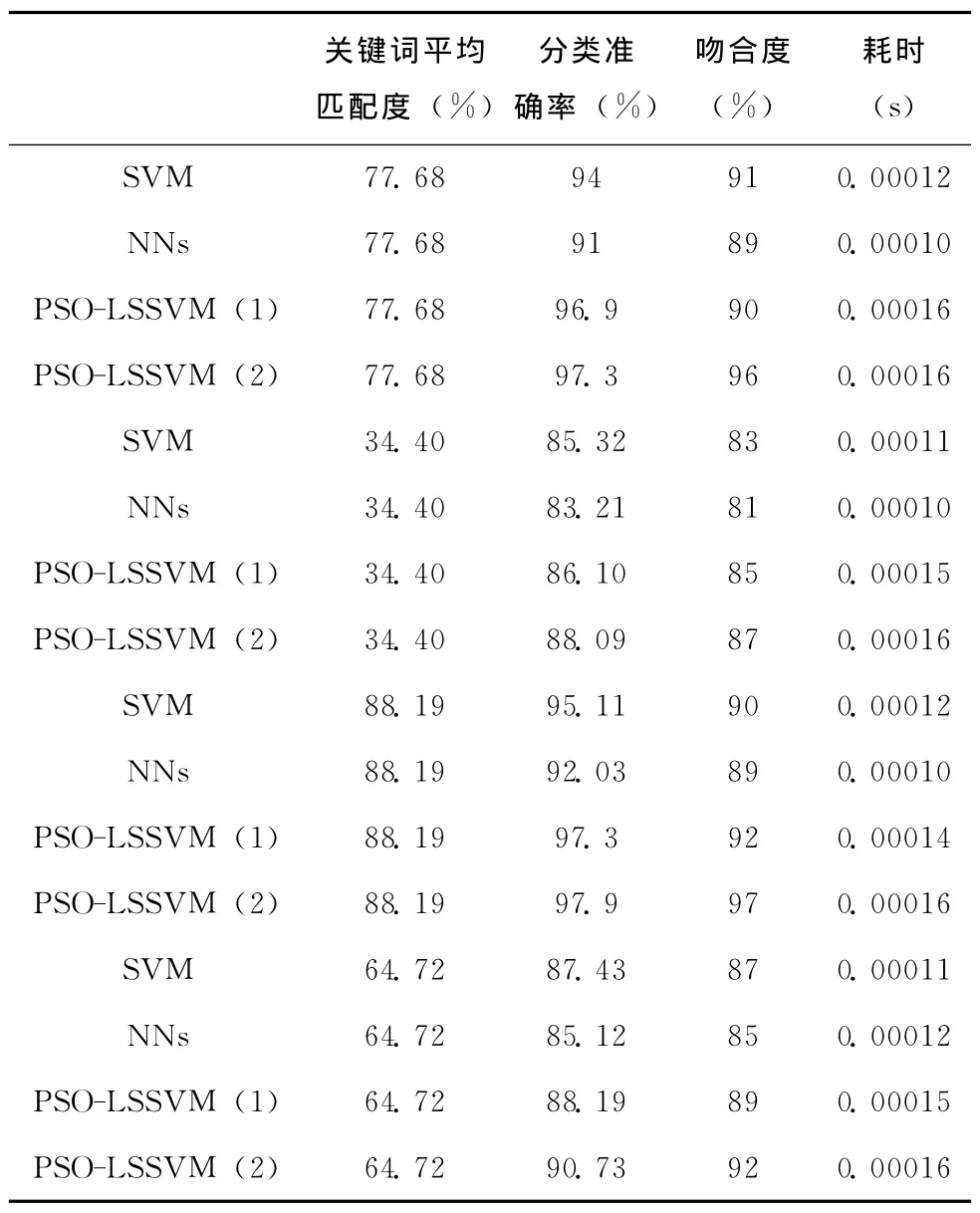
表4 分类准确率,吻合度,查询时间关系
表4中吻合度表示当前搜索结果与用户本身的搜索意图吻合度,吻合度是依据用户搜索后点击链接和翻页频率计算出来的。从表4可以看出搜索关键词与特征库的匹配度高低影响到分类器的准确率,平均匹配度越高,分类准确率越高,其搜索出来的结果与用户的期盼吻合度越高。经过不同分类器的比较测试得知,用与神经网络相比支持向量机更加适合于用户搜索意图识别问题,实验结果表明本文的PSO-LSSVM(2)分类准确度最高,查询结果的吻合度也最高,但是查询时间略长。
5 结束语
本文提出将改进型PSO-LSSVM算法应用于用户搜索意图识别,通过参考标准答案和学生答案相比较的模式来解决搜索意图识别问题。与现有的搜索技术不同在于:使用改进后的PSO-LSSVM算法对服务器端的文本和用户输入进行领域类别标记,服务器端按照标记优先从引擎中进行数据检索。利用词库以及分词技术,将搜狗语料库中的资源进行提取特征项并建立分类模型。将得到的模型用于用户分类意图识别。在优先显示全匹配的情况下,依据分类的结果显示相关领域的内容,从而提升用户随搜索效果的满意度,这样可以在既不影响传统搜索架构效果的同时提升用户搜索体验。
[1]Park K,Jee H,Lee T,et al.Automatic extraction of user's search intention from web search logs[J].Multimedia Tools and Applications,2012,61(1):145-162.
[2]Gupta V,Garg N,Gupta T.Search bot:Search intention based filtering using decision tree based technique[C]//International Conference on Intelligent Systems,Modelling and Simulation.IEEE,2012:49-54.
[3]WANG Daling,YU Ge,BAO Yubin,et al.Dynamically generalizing Web pages based on users'search intentions[J].Journal of Software,2010,21(5):1083-1097(in Chinese).[王大玲,于戈,鲍玉斌,等.基于用户意图的Web网页动态泛化[J].软件学报,2010,21(5):1083-1097.]
[4]JIANG Xue,SUN Le.Study on segmentation of user's query intents[J].Chinese Journal of Computers,2013,36(3):664-668(in Chinese).[江雪,孙乐.用户查询意图切分的研究[J].计算机学报,2013,36(3):664-668.]
[5]Gu C,Zhang S,Xue X.Network intrusion detection based on improved proximal SVM[J].Advances in Information Sciences and Service Sciences,2011,3(4):132-140.
[6]Liu L,Yang S,Wang D.Particle swarm optimization with composite particles in dynamic environments[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2010,40(6):1634-1648.
[7]Ojeda F,Suykens J A K,De Moor B.Low rank updated LSSVM classifiers for fast variable selection[J].Neural Networks,2008,21(2):437-449.
[8]Vokorokos L,BaláA,MadoB.Web search engine[J].Acta Electrotechnica et Informatica,2011,11(4):41-45.
[9]Ozmutlu S,Cenk Ozmutlu H,Spink A.Automatic new topic identification in search engine transaction logs using multiple linear regression[C]//Proceedings of the 41st Annual International Conference on System Sciences.IEEE,2008.
[10]CHEN Hua,LI Renfa,LIU Yufeng,et al.Algorithms recommend research on personalized search engine[J].Application Research of Computers,2010,27(1):49-53(in Chinese).[陈华,李仁发,刘钰峰,等.个性化搜索引擎推荐算法研究[J].计算机应用研究,2010,27(1):49-53.]
[11]ZHOU Peng,WU Huarui,ZHAO Chunjiang,et al.Research and design of agriculture search engine based on Nutch[J].Computer Engineering and Design,2009,30(3):610-612(in Chinese).[周鹏,吴华瑞,赵春江,等.基于Nutch农业搜索引擎的研究与设计[J].计算机工程与设计,2009,30(3):610-612.]
[12]WANG Feng,WANG Wei,ZHANG Jing,et al.Web crawler system based on Linux[J].Computer Engineering,2010,36(1):280-281(in Chinese).[王锋,王伟,张璟,等.基于Linux的网络爬虫系统[J].计算机工程,2010,36(1):280-281.]
[13]HUANG Yuan,LI Bing,HE Peng,et al.Mashup services clustering based on tag recommendation[J].Computer Science,2013,40(2):167-171(in Chinese).[黄媛,李兵,何鹏,等.基于标签推荐的Mashup服务聚类[J].计算机科学,2013,40(2):167-171.]
[14]WU Jieming,JI Dandan,HAN Yunhui.Research and design of vertical search engine for DCI based on Web[J].Computer Engineering and Design,2013,34(4):1481-1486(in Chinese).[吴洁明,冀单单,韩云辉.基于Web的DCI垂直搜索引擎的研究与设计[J].计算机工程与设计,2013,34(4):1481-1486.]
[15]LIU Yang,ZHANG Huaxiang.Improvement of Trust Rank algorithm based on combination of content features[J].Computer Engineering and Design,2013,34(4):1276-1279(in Chinese).[刘阳,张化祥.基于结合内容特征的Trust Rank算法改进[J].计算机工程与设计,2013,34(4):1276-1279.]
猜你喜欢
法律方法(2022年2期)2022-10-20
汽车实用技术(2022年14期)2022-07-30
电脑知识与技术(2022年15期)2022-07-02
福建基础教育研究(2022年4期)2022-05-16
昆明医科大学学报(2022年1期)2022-02-28
电脑爱好者(2020年23期)2020-12-30
中学生数理化(高中版.高二数学)(2020年1期)2020-02-20
分析化学(2018年12期)2018-01-22
飞碟探索(2015年8期)2015-10-15
电脑爱好者(2015年5期)2015-09-10
