
基于话题的事件相似度计算
2014-02-09 07:45:50徐建民吴树芳
计算机工程与设计 2014年4期
徐建民,张 猛,吴树芳
(1.河北大学数学与计算机学院,河北保定071002;2.河北大学管理学院,河北保定071002)
0 引 言
相似度是反映两个或多个实体间相似程度,寻找事物联系的一种方法,它被应用于自然语言处理、信息检索、机器翻译、人工智能等多个领域。最近几年来在TDT领域以事件为单元的事件本体[1]的研究正在兴起,事件间联系对事件本体的构建起着重要的作用,上海大学的单建芳等人提出了事件相似度的概念。
传统的事件相似度计算主要基于事件要素计算,常用的要素包括动作、对象、时间、环境、断言和语言表现六要素,其计算方法为:分别对六要素进行相似度计算,然后线性组合得到两事件的相似度[2]。但该方法在TDT领域存在不足之处,即它只孤立地考虑了事件内容,从事件内容上判断相似与否,没有考虑事件与事件之间的联系,在TDT领域同一话题下的两事件有着属于同一话题的属性。为了弥补传统方法的不足,论文根据模板知识对传统方法进行了改进,提出了一种新的基于话题的事件相似度计算方法,该方法融合了事件内容相似度、事件与话题相似度、事件时间相似度。并引入了参数α,β,γ,ε分配权重进行线性组合[3],得到最终的事件相似度。实验结果表明,与传统事件相似度计算方法相比,论文提出的方法能更准确地判断出同一话题下事件的相似性。
1 基础知识
1.1 相关概念
以下是论文涉及的几个基本概念:
定义1 话题是指一个种子事件或活动,以及所有与之直接相关的事件或活动[4]。
定义2 事件是指由某些原因、条件引起,发生在特定时间特定地点的一系列相关报道或文档[4]。事件包含若干要素,其中时间要素是区分不同事件的重要参考依据[5]。其组织构成如图1所示。
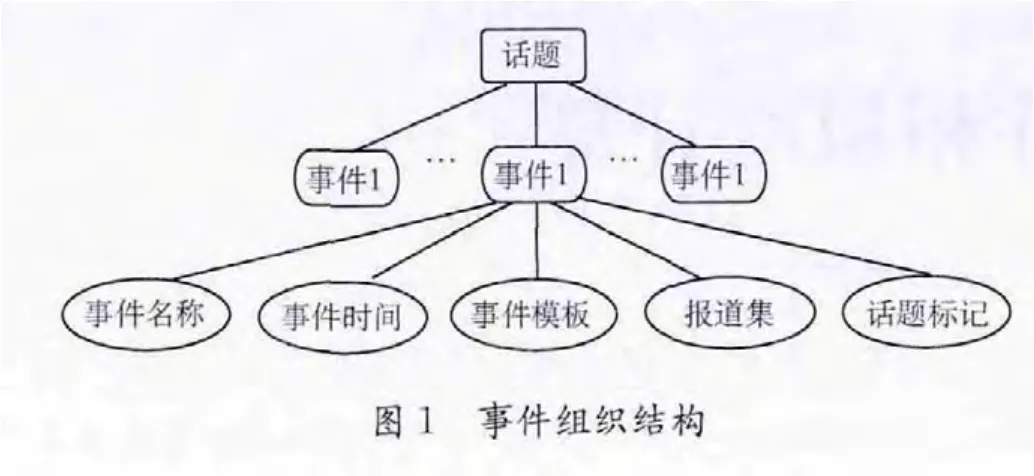
定义3 事件模板是指表示事件的向量,由许多事件要素术语和权重对组成。表示形式为knowm={(term1,weight1),(term2,weight2),,(termn,weightn)}。
定义4 事件时间分为区间时间和时刻时间。区间时间是一个时间区间[t1,t2],其中t1为最早报道该事件的时间,t2为报道该事件最近的文档时间。时刻时间即瞬时时间,是一个时间点。一般情况下t表示时刻时间,T=[t1,t2]表示区间时间。
定义5 话题模板是指表示话题的向量,同事件模板一样,是由许多术语和权重对组成。表示形式为topic={(term1,weight1),(term2,weight2),,(termn,weightn)}。
定义6 话题标记说明了该事件所属的话题。即同一话题下的事件有着相同的话题标记值,不同话题下的事件话题标记值不同。
1.2 模板设计
本文实验讨论的数据是新闻语料,新闻报道通常包含如下信息:何人、何时、何地、何因、何事等[6]。首先通过词频的方法提取报道要素术语(时间要素单独提取),然后从提取的报道信息术语中获得事件要素术语和表示话题的术语,具体如下所示:
(1)报道术语提取与权重计算
对每篇报道按照分词系统进行分词统计词频,运用式(1)计算每个术语的权重,并依据频度大小获得前20个术语来表示此报道
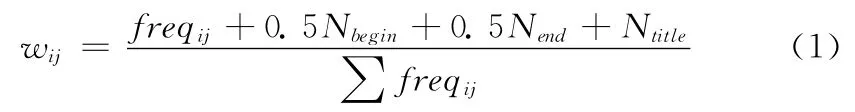
式中:wij——术语termj在报道si中的权重,freqij——术语termj在报道si中出现的频度,Nbegin——该术语在报道si开头出现的频度,Nend——该术语在报道si结尾中出现的频度,Ntitle——该术语在报道si标题中出现的频度,∑freqij——报道si中所有术语的频度之和。处在文本不同位置的术语其表达能力不同,经验值给定Nbegin、Nend、Ntitle的系数分别为0.5、0.5、1。
(2)事件要素术语提取与权重计算
如图1所示每个事件由多个报道组成,本文采用向量空间模型,用事件模板表示事件。本文在提取事件要素术语时,采用前k条的原则:即把事件下每篇报道已选的术语重新组织起来,构成事件术语库,对该库中的所有术语按照权重进行排序(重复的术语权重相加),取前k(经验值给定为20)个术语组成的模板knowm来描述其所属事件E,即

模板knowm中的术语term的权重计算主要采用均值的方法[7],公式如下

式中:weightj——术语termj在事件中的权重,wij——术语termj在事件下报道si中的权重,ne——事件中报道的总数量。
(3)话题要素术语提取与权重计算
本文用话题模板表示话题。话题模板的术语提取同样采用前k条的原则:首先把话题下的每篇报道中已抽取的术语提取出来构建成话题术语库T={term1,term2,…termr},对该库中的所有术语按照权重进行排序(重复的术语权重相加),取前k(经验值给定为20)个术语组成的集合Kx来描述其所属话题topic,即
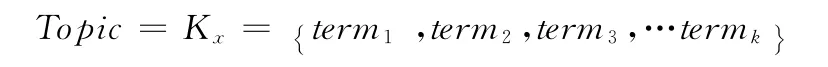
集合Kx中的术语term的权重计算主要采用均值的方法,公式如下

式中:weightj——术语termj在话题中的权重,wij——术语termj在话题下报道si中的权重,nT——话题中报道的总数量。
2 事件相似度计算
传统的事件相似度计算将内容要素分别按照语义相似度、语法相似度、词语序列相似度采用不同公式进行计算,本文利用事件模板计算事件内容相似度,并在此基础上融合了事件和话题的相似度。具体如下:
2.1 传统计算方法
传统的事件相似度计算时,将事件内容要素分成动作要素、对象要素、时间要素、环境要素、语言表现要素和断言要素[2]。分别采用不同的相似性函数进行相似度计算,最后线性组合,合理分配权重得到最终的事件相似度值。
2.2 同一话题下的事件相似度计算方法
本文提出的新事件相似度计算方法需要计算事件的内容相似度、事件和话题的相似度、事件的时间相似度。
2.2.1 事件的内容相似度
定义7 事件内容相似度是指两事件模板向量采用余弦公式对两事件进行的相似度计算。即两事件E1,E2分别为

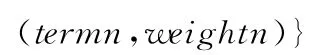
事件内容相似度为

2.2.2 事件与话题的相似度
定义8 事件与话题的相似度,即事件模板向量与话题模板向量采用相似性函数进行的相似性计算。
两事件模板向量在采用余弦公式计算相似度时,公式中的∑(weightt1,e1*weightt1,e2)[8]部分表示相同术语的权重相乘再求和,而同一话题下的两事件还有一共同的属性------属于同一话题,本文通过话题模板体现。两事件模板中不同的术语权重不相乘,但这些不同的术语可能在话题模板中出现,也就是说两事件模板向量与话题模板向量有着必然的联系。我们通过计算话题模板向量与事件模板向量的相似度来表达这种关系,体现两事件模板向量中不同术语所起的作用。
事件E1与话题的相似度计算为

事件E2与话题的相似度计算为

Sim(topic,e1)表示话题模板向量与事件E1模板向量的相似度,Sim(topic,e2)表示话题模板向量与事件E2模板向量的相似度。表示话题模板向量的模,表示话题模板的大小。ti∈topic∩knowm表示词ti是话题模板与事件模板共同的元素。
2.2.3 事件的时间相似度
考虑到时间因素的重要性,文章在计算事件相似度时融入了时间因素。本文在计算事件相似度时,将其融入到相似度计算中。两事件的时间关系和时间相似度有如下八种关系,根据事件E1的事件类别不同可分别用t1、t、T1表示事件时间,同样E2用t2、T、T2表示事件时间。
(1)当t1=t2时,Sim-time=1;
(2)当t1≠t2时,Sim-time=0;
(3)当t∈T时,Sim-time=
(5)当T1=T2时,Sim-time=1;
(6)当T1T2时,Sim-time=
(7)当0<T1∩T2<min{T1,T2}时,Sim-time=
(8)当T1∩T2=0时,Sim-time=0。
2.2.4 基于话题的事件相似度计算
本文在计算事件相似度时,将事件内容相似度、事件与话题相似度、事件时间相似度分为两组考虑。第一组:分别计算事件内容相似度、两事件与话题的相似度,权重因子为α、β、γ。第二组:考虑事件的时间相似度,权重因子为ε。则同一话题下的两事件的相似度计算如下

鉴于事件内容相似度、事件与话题相似度、事件时间相似度对最终相似度都有不同程度的影响,我们约定4个因子满足如下关系:①α+β+γ+ε=1;②α=β<γ>ε;③ε=0.1。权值的具体设定根据环境由用户设定,且权值的取值与事件的话题标记有关系。因为当两事件的话题标记不相同时,表示两事件不属于同一话题,α和β取值只能为零,这时式(7)为传统计算方法。本文实验则通过计算同一话题下两事件的相似度,来比较两种方法的优略。
3 实验及分析
本文实验采用的测试集是从新浪网上搜集的600篇新闻报道,主要包括了钓鱼岛、食品安全、交通事故、十一国庆4个话题,其中钓鱼岛话题下包含有经济影响、军事反应、日本将钓鱼岛国有化、游行4个事件,食品安全话题下包含有地沟油、老酸奶、牛奶、苏丹红4个事件,交通事故话题下包含有826交通事故、十一高速交通事故、温州动车3个事件,十一国庆话题下包含有高速拥堵、华山捅人、长城人海3个事件。4个话题中的每个事件包含约40篇新闻报道。针对以上4个话题,论文实验主要分为两个部分:第一部分,设定参数α,β,γ,ε取值,并在不同取值时计算新方法的事件相似度值,同时用传统方法计算事件相似度值;第二部分,两种方法同时与专家给定的相似度值比较。
表1给出了实验中用到的α,β,γ,ε几种组合方式,4个参数的确定满足论文给出的基本假设。
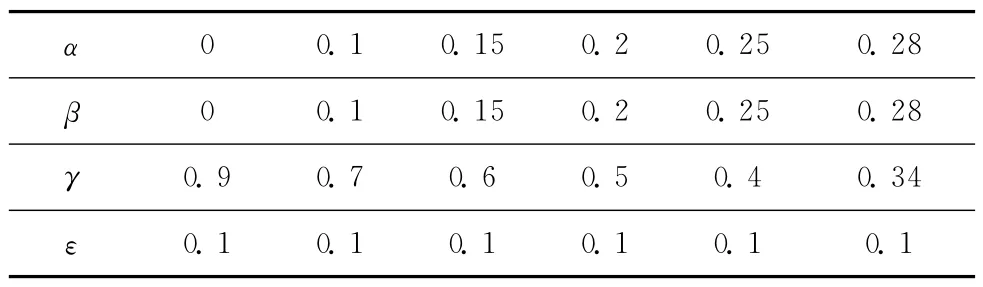
表1 α,β,γ,ε取值
表2为选取的十组事件在α取不同值时,用新方法计算得到的事件相似度及均值,表中的十组事件为同一话题下的事件对,均为相似事件。本文提出的方法只在计算同一话题下的两事件相似度时与传统方法比有优势。不属于同一话题的两事件,新旧两种方法计算结果一样。

表2 新方法事件相似度
当α=0时β=0、γ=0.9、ε=0.1,式(7)为Sim(e1,e2)=γSim-con(e1,e2)+εSim-time,是传统计算方法,表3是以上十组事件用传统方法计算的结果。

表3 传统方法事件相似度
表4中给出了专家定义的事件相似度值。
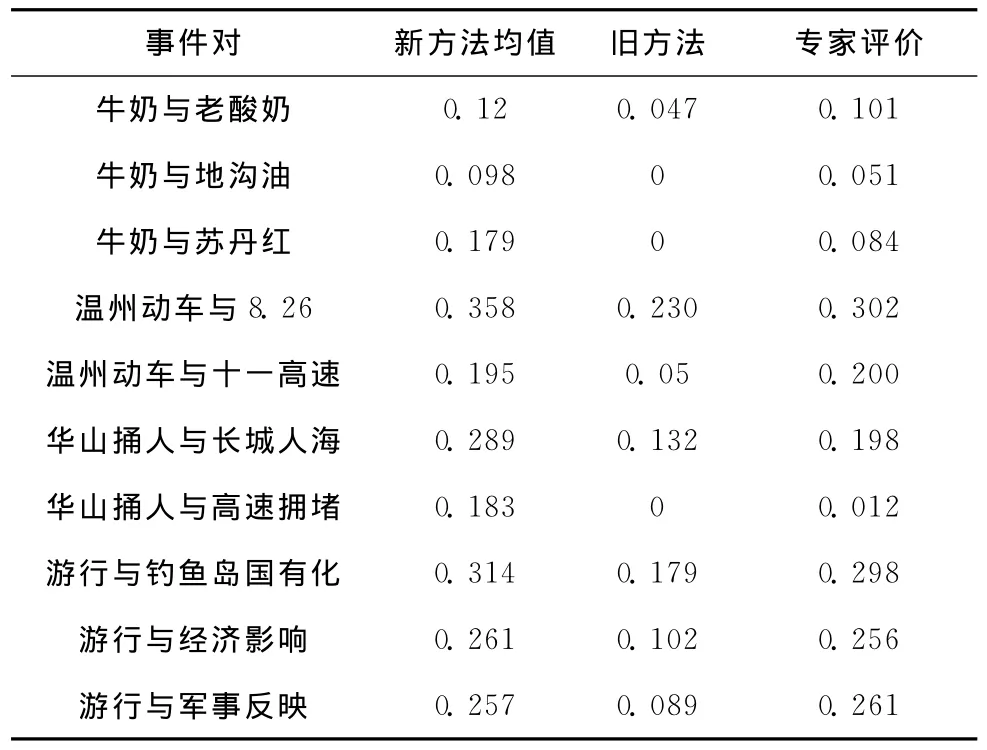
表4 相似度方法比较
从表2和表3中可以看出在计算同一话题的事件相似度时新方法计算的结果比旧方法要高一些,高的多少由α,β,γ,ε决定。
从表4中数据可以看出当计算同一话题的事件相似度时新方法在α,β,γ,ε取值适当时与专家的客观评价更接近。说明新方法更能准确的判断出同一话题下的两事件相似性。
4 结束语
本文抓住同一话题下的两事件属于一个共同话题这个特点,对传统的事件相似性计算方法进行了改进。引用模板知识,提取事件要素术语,计算两事件的相似度。并通过计算两事件与话题的相似度弥补传统方法存在的不足。计算过程中引入了参数α,β,γ,ε,分别对两事件内容相似度、两事件与话题相似度、事件时间相似度进行权衡,根据不同环境取不同值。实验结果验证了本文提出方法的正确性。但仍有不足之处,将来的工作主要集中在采用不同的相似性函数或距离函数计算相似度,综合比较找出最适合的相似性函数或距离函数[9]。并采用多向量的事件表示模型,利用支持向量机的方法整合计算事件内容相似度,且采用线性组合的方法得到最终的相似度[10]。
[1]Liu Zongtian,Huang Meili.An event ontology research[J].Computer Science,2009,36(11):189-192.
[2]Shan Jianfang,Liu Zongtian,Zhou Wen.Event similarity calculation[J].Microcomputer System,2010,31(4):731-734.
[3]Wang Zhenyu,Wu Zeheng,Tang Yuanhua.Topic detection based on vector and quadratic clustering[J].Computer Engineering and Design,2012,33(8):3214-3218.
[4]Chen Xuechang,Han Jiazhen,Wei Guiying.Topic detection and tracking pilot study[J].China Management Informationization,2011,14(9):56-58.
[5]Zhang Kuo,Li Juanzi,Wu Gang.New event detection based on indexing-tree and named entity[C]//SIGIR 2007 Proceedings,2007:215-222.
[6]Xue Xiaofei,Zhang Yongkui,Ren Xiaodong.A new event detection method research based on the factors of news[J].Journal of Computer Applications,2008,28(11):2975-2978.
[7]Zhao Hua,Zhao Tiejun,Zhang Zhu,et al.Topic detection research based on content analysis[J].Journal of Harbin Institute of Technology,2006,38(10):1740-1743.
[8]Ling Song,Jun Ma,Li Lian,Zhijun Zhang.Comprehensive document similarity computing research[J].Computer Engineering and Applications,2006,42(30):160-163.
[9]Zhang Yu,Liu Yudong,Ji Zhao.Measurement method of vector similarity[J].Technical Acoustics,2009,28(4):532-536.
[10]Zhang Xiaoyan,Wang Ting.The news topic representation model and study of correlation tracking technique[D].Doctoral Dissertation of National University of Defense Technology,2010:1-121.
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
导航定位与授时(2014年2期)2014-04-27 13:41:09
河南科技(2014年15期)2014-02-27 14:12:51
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
