
稀疏LSSVM及其在语音识别中的应用
2014-02-09 07:47:12王真真张雪英刘晓峰
计算机工程与设计 2014年4期
王真真,张雪英+,刘晓峰
(1.太原理工大学信息工程学院,山西太原030024;2.太原理工大学数学学院,山西太原030024)
0 引 言
语音识别就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术,现已广泛应用于通信、国防、家电和医疗等领域。
最小二乘支持向量机(least square support vector machine,LSSVM)[1]作为标准支持向量机(support vector machine,SVM)[2]的一种改进类型,通过求解一系列的线性方程组得到一个简单的优化问题,避免了求解SVM的计算复杂和需花费大量存储空间的二次规划问题。然而,由于LSSVM使用二次损失函数作为损失函数导致它丧失了SVM的一个优势——解的稀疏性,它将几乎所有的训练样本当做支持向量并参与模型预测,降低了模型预测速度。为此,Suykens、Kruif等人提出了各种支持向量的稀疏化方法[3-6]。然而这些稀疏化方法都是迭代剪枝方法,每次剪枝后需要再次训练样本,因此随着训练样本集的增大、迭代次数的增加,耗时明显增多。
本文提出了一种新的LSSVM稀疏方案(IS-LSSVM),从样本特征维数和样本点个数两方面同时进行稀疏化且只需要训练模型一次。韩语语音的实验结果表明,该方法能明显缩短语音识别时间,优于传统的稀疏化方法。
1 LSSVM分类器和稀疏LSSVM
1.1 标准LSSVM分类器
引入拉格朗日乘子αk,构建拉格朗日函数
对式(2)分别求解关于w,ek,b和αk这4个变量的偏导数,并令4个偏导数都等于0,得到下面矩阵形式的KKT系统

其中,核函数一般选取高斯核函数

由LSSVM最优化条件可以得出在LSSVM中支持向量值αk正比于样本点的误差ek,而在SVM中许多支持向量的值为零,因此LSSVM的解失去了SVM解的稀疏性。
1.2 经典的LSSVM稀疏化方法
研究LSSVM稀疏化的必要性:①减少模型分类所需的训练样本数目,减少存储空间的浪费;②用具有代表性的少量样本代表所有的训练样本,避免模型的过拟合;③减少模型的支持向量,可以在模型预测阶段降低支持向量的分析复杂度和提高模型分类速度。因此越来越多的学者从事LSSVM稀疏化方面的研究,其中Suykens等人提出的稀疏化方法(SS-LSSVM)是所有稀疏化算法中最经典的方法。它的编程思想简单,容易实现,且在模式识别中取得了较好的稀疏化效果[8]。因此,在本文的实验部分将本文提出的IS-LSSVM同SS-LSSVM进行了比较,以说明IS-LSSVM的有效性。SS-LSSVM稀疏化算法的具体实现步骤如下:
(1)在n个样本点上训练LSSVM(n表示所有训练样本的总数);
(3)在剪枝后的样本集上重新训练LSSVM;
(4)返回步骤(2),直到用户定义的性能指标下降。
对于多分类问题,对每个二分类器分别进行上述剪枝过程。
2 IS-LSSVM
IS-LSSVM算法的整体流程如图1所示,图1中的虚线框表示IS-LSSVM算法的改进之处,其中ICA特征降维是为了降低建模复杂度,ICA快速剪枝是为了筛选支持向量。

图1 IS-LSSVM算法的整体流程
2.1 ICA特征降维
独立成分分析(independent component analysis,ICA)[9]的核心思想是假设数据是由一组相互独立的源信号线性混合得到,并以互信息作为统计独立的测量标准分离出这些独立源。
语音样本的不同特征之间往往存在不同程度的信息重叠,去除特征间的冗余信息一方面可以降低建模复杂度、提高建模速度,另一方面也可以去掉语音样本中部分干扰噪声,提高建模精度。ICA不仅利用语音样本的二阶统计信息还利用语音样本间的高阶统计信息,以保证提取的语音样本新特征之间相互独立。FastICA[10]是ICA的一种快速实现方法,本文在进行LSSVM建模之前采用FastICA对语音样本进行特征降维,提取出新的语音样本特征,具体步骤如下:
(1)预处理
2)PCA白化:去除语音样本的相关性并得到降维的白化信号

(2)采用FastICA算法求解白化信号珦XtrainN×n1的分离矩阵W并计算源估计S∧

(3)语音样本特征降维

经过以上步骤,训练集和测试集的样本特征由M维降到N维。
2.2 ICA快速剪枝
2.2.1 快速剪枝和神经网络
本文提出的筛选支持向量方法的思想来源于多层前馈神经网络删除冗余隐藏节点的快速剪枝算法[11]。
隐含层有h个隐节点且第j个隐节点的活化函数为fj(X),输出层为线性输出,则输出函数可表示为
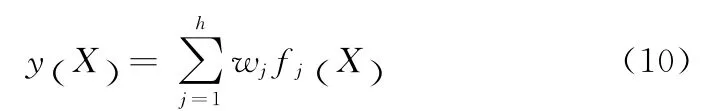
该快速剪枝方法通过主成分分析(principal component analysis,PCA)从An×h的h列中提取出含信息量较多、比较重要的m列,并将与其相对应的m个隐节点保留,其余隐节点作为冗余节点删除。
2.2.2 ICA快速剪枝和LSSVM
由式(4)可以看出,LSSVM可以看作一个三层前馈网络:隐节点的个数为n,第k个隐节点的活化函数输出函数y(x)是隐含层输出的加权和,权重等于拉格朗日乘子αk。因此上节中的快速剪枝算法适用于LSSVM的稀疏化。
本文提出的ICA快速剪枝在上节的快速剪枝方法的基础上做了两方面的改进:ICA取代PCA进行核矩阵列向量的提取,以提高列向量间的独立性;将剪枝掉的样本点的分类信息转移到保留的支持向量上,以提高IS-LSSVM算法的识别率。
(1)ICA作为PCA的一种改进算法,它的优点是:充分利用了数据的二阶和高阶统计信息;ICA提取出的独立源(ICs)不仅是不相关的而且是独立的。因此用ICA提取训练样本构造的核矩阵列向量之间的独立性更强,更接近于核矩阵的基向量。又由于ICs不是按重要性依次排列,为此采用2006年Wang Jing等人提出的基于高阶统计特性的独立成分排序算法HOS-ICA[12]对ICs进行排序。
(2)LSSVM的求解系统(如式(3)所示)的第k行可以表示为
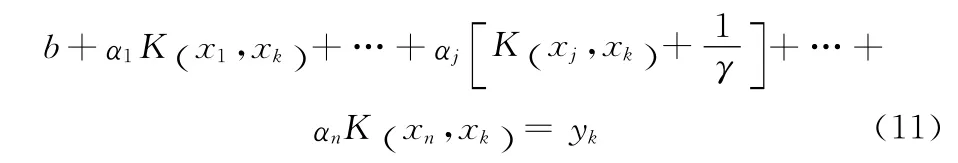
从式(11)可以看出,如果删除核矩阵的第j列,则相应的权重αj也将被删除,那么与之对应的训练样本点xj不再参与下一步的LSSVM的分类识别,因此被删除的样本点的分类信息不能被充分利用。为了尽量提高IS-LSSVM算法的识别率,采用最小二乘法将删除的样本点的分类信息转移到保留的支持向量上,具体实现如下:设Km矩阵由IS-LSSVM算法筛选出的核矩阵K的m个列向量组成,Kd矩阵由K中其余列向量组成,是与Km中列向量对应的乘子向量,是与Kd中列向量对应的乘子向量。则LSSVM对训练样本集的输出函数可以表示为
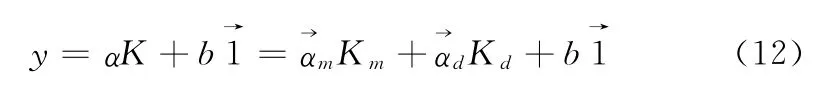
令ΔαKm=珗αdKd,得出
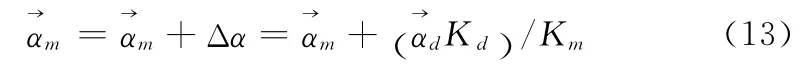
稀疏化后的LSSVM的分类决策函数为
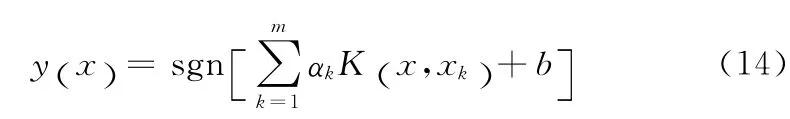
2.2.3 ICA快速剪枝步骤
(2)计算核矩阵的独立源:通过FastICA算法计算核矩阵K的所有ICs,并采用HOS-ICA算法对ICs的各列按重要性降序排序,记为KICs;
(3)对所有训练样本点按重要性排序:
1)计算K各列与KICs各列的相关性。记KICs的第i列为首先计算当k=1时与K的所有列的相关系数,选择相关系数的绝对值最大的列记为i1;然后依次计算当时,与K中所有剩余的未被选中的列的相关系数,选择相关系数的绝对值最大的列记为ik且以避免K中已经被选中的列再次被选中;
2)按序号ik对K的各列排序,排序结果记为,相应的支持向量乘子向量α排序为,训练样本排序为
(5)信息转移:按式(13)将非支持向量的分类信息转移到保留的支持向量上;
(8)剪枝算法结束,m即为稀疏化后保留的支持向量个数。
对于多类分类问题,因为每个二分类器的核矩阵K是一样的,只需要将步骤(3)和步骤(4)中的α按行运算即可。
3 实验结果及分析
本实验采用韩语非特定人孤立词语音库对IS-LSSVM算法进行测试,并且与标准SVM、标准LSSVM和经典稀疏化算法SS-LSSVM进行了比较。
韩语语音库:词汇量分为10词、20词、30词、40词和50词;由16个人每人每词发音3遍得到所有的语音文件,其中前9个人的语音文件作为训练集,后7个人的语音文件作为测试集;噪声为人为添加的高斯白噪声,且信噪比为30dB;语音信号采样率为11.025k Hz,帧长N=256点,帧移M=128点,采用MFCC方法提取1024维的语音特征。
本实验的运行环境为双核Pentium(R)Dual-Core CPU、2GB RAM的PC机,软件平台为MATLAB 2010a。SVM采用SVM-KM工具包[13],LSSVM采用LSSVMlab 1.8工具包[14]。SVM的多类分类编码采用一对一编码,LSSVM、SS-LSSVM和IS-LSSVM采用最小输出编码。所有算法的核函数均采用高斯核函数。惩罚参数γ和高斯核函数的宽度参数σ采用10折交叉验证方法选取。每个实验运行5次,实验结果取平均值。IS-LSSVM算法采用ICA进行语音特征降维时,对于10词、20词数据集设置累积贡献率为85%,30词、40词和50词数据集设置累积贡献率为90%。
表1描述了不同词汇量下语音样本的个数。表2-表5分别是采用不同的识别算法对韩语语音库建模需要的样本特征个数、支持向量数目、识别率和识别时间进行测试的实验结果。

表1 韩语数据库
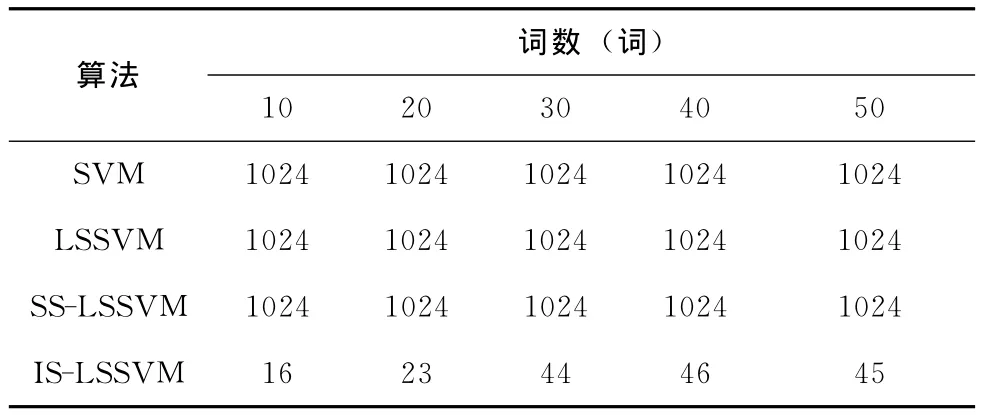
表2 不同识别算法下各个词汇建模需要的样本特征
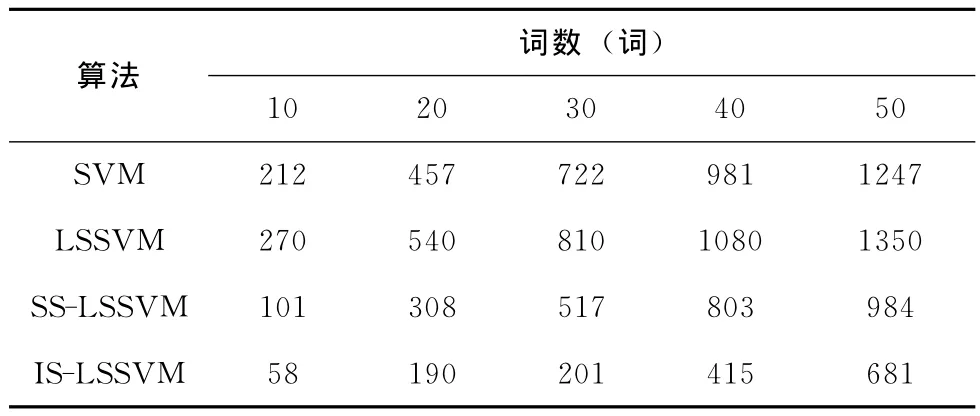
表3 不同识别算法下各个词汇建模所支持的向量数目
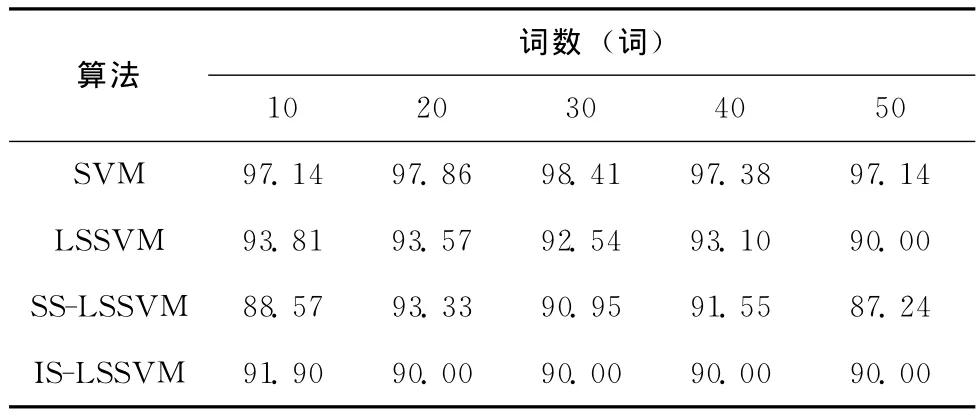
表4 不同识别算法在各个词汇下的识别率(%)
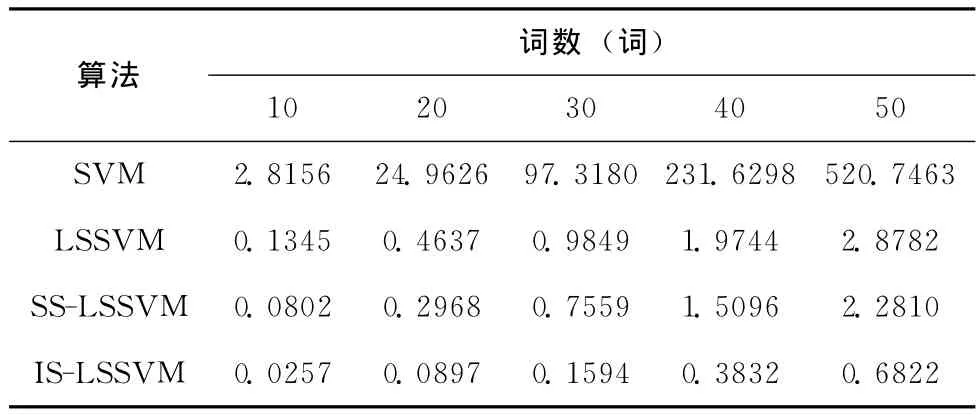
表5 不同识别算法对各个词汇中的测试集的识别时间/s
由表2可以看出IS-LSSVM算法与其它3种算法相比,因为采用ICA特征降维,因而建模所需的样本特征个数明显降低,这不仅可以降低建模复杂度还有利于节省识别时间。
由表3可以看出,4种识别方法中LSSVM建模所需要的支持向量数最多,等于训练样本的个数,SVM的支持向量是训练集的子集,验证了LSSVM丧失了SVM的稀疏性的理论;SS-LSSVM和IS-LSSVM建模所需的支持向量数目均少于SVM和LSSVM,说明这两种方法均实现了LSSVM的稀疏化;IS-LSSVM的支持向量数目少于SS-LSSVM,说明IS-LSSVM算法稀疏化效果优于SS-LSSVM;IS-LSSVM是4种识别算法中稀疏效果最好的。
由表4可以看出,4种识别方法中标准SVM对所有词汇量的识别率都是最高的,平均识别率97%左右;LSSVM次之;两种LSSVM的改进算法SS-LSSVM和IS-LSSVM对测试集的识别率不相上下,平均识别率90%左右,低于LSSVM的识别率,这是因为所有的LSSVM稀疏化算法都会不同程度的删除部分样本来实现稀疏化,但这同时也会丢失该部分样本的分类信息,因而导致识别率有所降低。
由表5可以看出,4种识别方法中IS-LSSVM对测试集识别时间最短,明显缩短了标准LSSVM的识别时间;SSLSSVM也缩短了LSSVM对测试集的识别时间,但是效果没有IS-LSSVM好;SVM测试集识别时间最长,这与SVM的求解模型是二次型规划问题有关。
实验结果表明,IS-LSSVM在相对保持语音识别率的基础上,有效提取了语音样本特征和支持向量,大大降低了测试时间。总体来看,IS-LSSVM优于其它3种算法。
4 结束语
为了改善语音识别系统的实时性,提出了一种新的最小二乘支持向量机稀疏化算法,其特点是:对训练样本的特征和样本点数均进行降维;只需要训练LSSVM分类器一次;将非支持向量的信息转移到支持向量上,以改善稀疏化对分类器分类能力的影响。韩语语音库的实验结果表明,该算法通过ICA特征降维有效减少了样本特征、降低了建模复杂度,ICA快速剪枝有效剔除了冗余支持向量,最终在保持识别精度的前提下,大大缩短了语音识别时间。下一步打算在该算法的预处理中加入样本预选取,在建模时用序贯最小化等快速训练算法实现等。
[1]Mitra V,Wang C J,Banerjee S.Text classification:A least square support vector machine approach[J].Applied Soft Computing Journal,2007,7(3):908-914.
[2]DING Shifei,QI Bingjuan,TAN Hongyan.An overview on theory and algorithm of support vector machines[J].Journal of University of Electronic Science and Technology of China,2011,40(1):1-10(in Chinese).[丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):1-10.]
[3]Carvalho B P R,Braga A P.IP-LSSVM:A two-step sparse classifier[J].Pattern Recognition Letters,2009,30(16):1507-1515.
[4]Kuh A,De W P.Comments on‘Pruning error minimization in least squares support vector machines’[J].IEEE Trans Neural Networks,2007,18(2):606-609.
[5]Xia X L,Jiao W D,Li K,et al.A novel sparse least squares support vector machines[J].Mathematical Problems in Engineering,2013.
[6]Li Y G,Lin C,Zhang W D.Improved sparse least-squares support vector machine classifiers[J].Neurocomputing,2006,69(13-15):1655-1658.
[7]Ahmed T,Wei X L,Ahmed S.Efficient and effective automated surveillance agents using kernel tricks[J].Simulation,2013,89(5):562-577.
[8]Luo R L,Cai W Q,Chen M,et al.The application of improved sparse least-squares support vector machine in speaker identification[C]//Proceedings of 3rd International Workshop on Intelligent Systems and Applications,2011:1-4.
[9]SHEN Yang,ZHAN Yongzhao,SHAN Shijuan.Research of license plate Chinese characters recognition based ICA[J].Computer Engineering and Design,2012,33(3):1127-1131(in Chinese).[沈洋,詹永照,单士娟.基于ICA降维的车牌汉字识别研究[J].计算机工程与设计,2012,33(3):1127-1131.]
[10]LIANG Shufen,JIANG Taihui.Blind separation of speech signal based on Fast ICA algorithm[J].Computer Engineering and Design,2010,31(13):3047-3050(in Chinese).[梁淑芬,江太辉.Fast ICA算法在语音信号盲分离中的应用[J].计算机工程与设计,2010,31(13):3047-3050.]
[11]Chen Y Q,Hu S X,Chen D Z.Fast pruning strategy for neural network size optimization and its application[J].Journal of Chemical Industry and Engineering,2001,52(6):522-526.
[12]Wang J,Chang C I.Applications of independent component analysis in endmember extraction and abundance quantification for hyperspectral imagery[J].IEEE Trans Geosci Remote Sens,2006,44(9):2601-2616.
[13]Canu S,Grandvalet Y,Guigue V,et al.SVM and kernel methods matlab toolbox[EB/OL].[2013-7-10].http://asi.insa-rouen.fr/enseignants/~arakoto/toolbox/index.html.
[14]Pelckmans K,Suykens J A K,Gestel T V,et al.LS-SVM-lab:A MATLAB/C toolbox for least squares support vector machines[EB/OL].[2013-7-20].http://www.esat.kuleuven.be/sista/lssvmlab/.
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
科技创新与应用(2020年6期)2020-02-29 10:39:27
海峡姐妹(2019年12期)2020-01-14 03:24:40
天津诗人(2017年2期)2017-03-16 03:09:39
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
计算物理(2014年1期)2014-03-11 17:00:18
