
改进的目标检测与自动跟踪方法研究
2014-02-09 07:47:14张明杰康宝生
计算机工程与设计 2014年4期
张明杰,康宝生
(1.西北大学信息科学与技术学院,陕西西安710127;2.西安邮电大学管理工程学院,陕西西安710061)
0 引 言
针对目标检测和图像分割方法,研究人员做了大量的研究工作[1-4]提出了许多实际的方法,但是提出的方法中都是针对某一具体问题的,还没有一种通用的方法。例如国内外主要运用的方法有:对称差分法[5]、帧间差分法、背景差法[6]、基于活动轮廓的方法[7]、光流场法和块匹配方法、机器学习的方法[8]等方法,这些方法各有优缺点,它们可以联合使用。
目标跟踪技术就是在时域上进行跟踪,在连续帧中将相同的目标对应起来。跟踪的难点在于环境和目标的复杂性,因此算法直接影响着跟踪的准确性和鲁棒性。随着人们对跟踪系统的稳定性、鲁棒性要求的提高,研究一种精确、高性能、鲁棒性好的运动目标跟踪方法仍然是计算机视觉领域所面临的一个巨大挑战。目前常用的跟踪方法是预测方法,如基于滤波理论的目标跟踪方法,基于Mean Shift方法[9]、基于增量学习的方法[10]、基于卡尔曼滤波器的方法[11]、基于偏微分方程方法、基于Monto Carlo的方法[12]以及多假设跟踪的方法[13]等。
在单目静态、复杂的环境下,目标遮挡通常会引起目标检测错误。为了克服遮挡的影响,我们提出一种目标检测和跟踪方法,可以提高视频监控系统的跟踪的准确性。首先使用动态背景差分算法检测目标是否存在,然后使用目标的合并和分离状态解决遮挡条件下的错误跟踪。最后,实现了一个改进的重叠跟踪方法,通过对相邻目标质心的距离的分析来完成对象标定和目标的自动跟踪。
1 算法概述
本文提出的算法的框架图如图1所示。首先,使用动态背景差分模型分割每一帧中的运动目标。为了克服光照变化,设置一个与差分图像中兴趣区域检测相关的动态阈值,这个阈值根据每一帧中背景和前景像素的分布迭代计算。获得前景区域后,定义出现、离开、合并、分离4个状态,根据下一帧中目标的出现情况,将4个状态分别分配给检测的运动目标。特别,目标确定为合并和分离状态时,为了减少遮挡的影响,通过分析前一帧中目标中心的距离来实现进一步继续跟踪。最后,为了得到目标跟踪的结果,4种状态的目标被标定。再由标定的目标完成跟踪。

图1 本文提出的算法的框架
2 目标检测
在背景差分阶段,通过当前帧减去背景图像得到差分图像,并且通过差分图像的阈值识别前景区域。因此,两个变量对应于环境中光照变化:一个是建立动态背景模型,另一个是选择一个合适的阈值来提取前景目标。背景建模和阈值均根据帧内容自适应确定。
2.1 背景建模
自适应建立背景模型依据后续帧的像素灰度值的一致性分析。设Fm(x,y)为第m帧(x,y)处的像素灰度值,Bm(x,y)代表从前一帧计算的相应的背景像素的灰度值,每一个背景像素的灰度值更新如下

式中:m——当前帧的序号。
式(1)也表示累计帧的背景像素平均值。在我们的实验中,初始化建立背景模型,使用的是视频序列中的前100帧。然后,通过获得和它们相应的背景像素的平均值来得到背景图像。当m逐渐变大时,被运动目标占有的像素平滑接近背景模型的真实像素。
2.2 差分图像阈值
一个差分图像通过当前帧和二值背景图像的差分获得。为了检测前景区域,阈值的计算需要考虑帧的内容的随机变化。根据背景和前景区域的分布,迭代计算每个差分图像的阈值。估计阈值的步骤如下:
(1)通过平均差分图像的像素值获得初始的阈值,然后利用初始阈值将图像分割成前景区域和背景区域。观察这两个区域的分布,属于背景和前景区域的像素被分别计算,分别表示为μB和μO
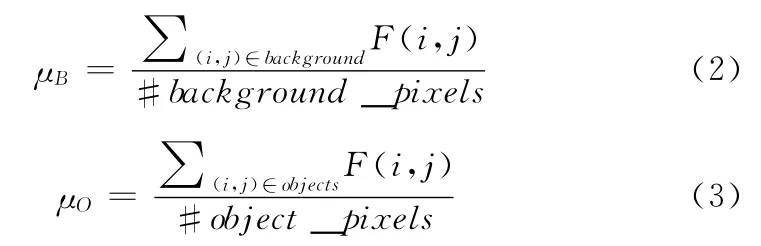
(2)设临时变量T,T=(μB+μO)/2。
(3)更新的T设置为差分图像的阈值。
(4)重复(1)到(3),当μB接近于μO时结束。
获得二值前景图像之后,我们使用形态学方法消除噪声,并且修复破碎的轮廓区域。
假设A表示原图像,B表示结构元素,数学形态学的腐蚀、膨胀、开运算和闭运算的滤波方法如下:
腐蚀运算记为AΘB,表达式如式(4)所示
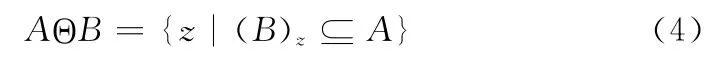
膨胀运算记为A⊕B,表达式如式(5)所示

开运算用A B表示,它是先进行腐蚀运算在进行膨胀运算,定义如式(6)所示。
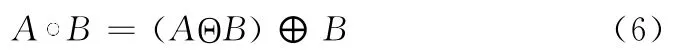
闭运算用A·B表示,闭运算是先进行膨胀运算,再进行腐蚀运算,定义如式(7)所示
在这里我们选择八邻域结构元素,利用数学形态学的腐蚀、膨胀、开运算和闭运算的滤波性质,选择先闭后开的形态学的滤波方法。通过这种方法能够较好的消除噪声和修复破碎的轮廓区域。
3 目标跟踪
在视频监控系统中,我们所最关心的是获得目标的空间位置和监视他们随时间变化的轨迹。因此,为了避免在遮挡环境下错误跟踪目标,通过考虑目标质心之间的距离,我们实现了一种改进的重叠跟踪方法[14]。
3.1 改进的重叠跟踪方法
使用背景差分方法得到分割结果后,根据区域轮廓的完整性,从前景图像中识别出感兴趣区域。另外,从感兴趣区域中检测人物区域需要考虑人体的物理约束,包括区域的外形和像素灰度值的动态范围。当对象符合约束时,我们可以由椭圆半径,质心和距离等位置参数构造覆盖这一区域的最小椭圆。
如图2所示,在改进的重叠跟踪方法中,我们设置4种跟踪状态:新目标、离开目标、合并目标、分离目标,这4种跟踪状态来理解当前帧。新目标表示对象进入视频场景,离开目标表示对象离开视频场景。对于合并和分离目标状态,目标的接触在相邻帧中被检测。在当前帧中目标合并和分离状态的判断也要考虑目标状态,它通过继续跟踪在前一帧中出现的目标来实现。依靠前一帧中标定的人物对象的位置的连续性,我们分配标签给单个目标。
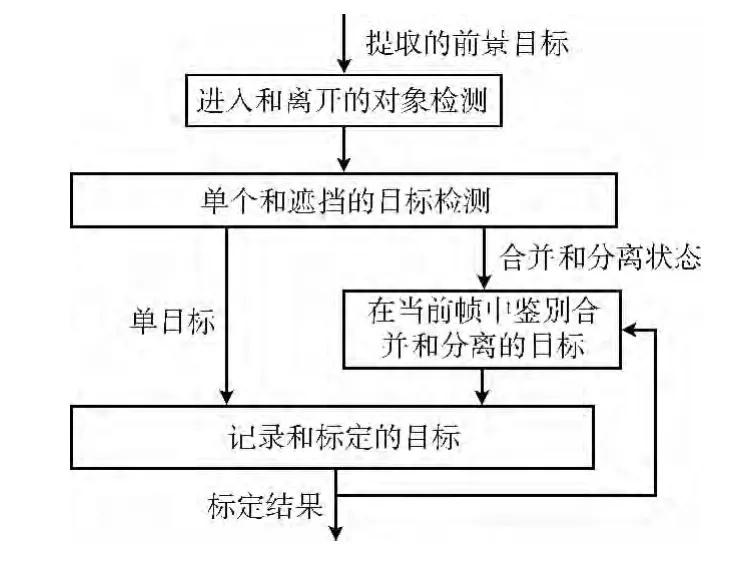
图2 跟踪和标定目标流程
3.2 分析目标质心的距离
和传统的重叠跟踪方法相比,我们改进的跟踪方法实现跟踪前一帧中的标定目标。在当前帧和前一帧中,我们分析合并和分离状态的目标之间的质心距离。在3.1节中提到表示目标的椭圆的长轴和短轴求平均,可以得到一个动态半径s=(w+h)/2,这里w和h分别表示椭圆的长轴和短轴。在当前帧中,合并状态目标的识别是通过分析两个相邻椭圆的质心距离是否小于前一帧中它们动态半径之和。另一方面,对于确定分离目标,看它是否符合两个相邻椭圆的动态半径之和大于当前帧中它们质心的距离。
分析了当前帧中目标的状态之后,最后分配标签给单个目标。而且,每一个目标的标签被记录,并且为下一帧中跟踪目标提供参考。

图3 3个视频序列的背景差分和跟踪结果
4 实验结果
我们使用公共测试数据集中的3段视频序列对本文提出的方法进行验证。其中两个序列是不同视角的商场走廊视频,另一个是室外街道视频。算法在Matlab2009下编写,实验的硬件平台为Pentium Dual-Core,2.6GHz,内存为2G。图3是实验序列的背景差分图像和跟踪的结果。从图3的结果可以看出动态运动目标检测方法能有效的、可靠地分离目标,并且可以获得较好的跟踪效果。
为了评价跟踪的准确性,我们分别使用了本文提出的方法、ground truth方法和Yilmaz等提出的方法[11]实验,比较它们的检测率和均方误差(RMS)。检测率和均方误差可以通过如下公式计算每一帧的检测率和均方误差
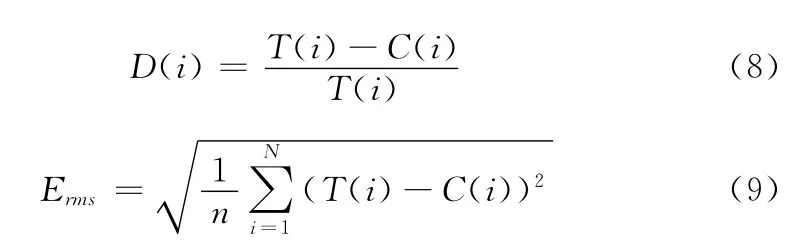
式中:D(i)——第i帧的检测率,T(i)和C(i)——目标真实位置和使用各种跟踪方法目标的位置结果。Erms——视频序列中目标的均方误差。3个视频序列的平均检测率和RMS如表1和表2所示,可以看出,在3个序列中,本文提出的方法和Ground Truth方法、卡尔曼滤波方法相比,本文提出的方法具有更高的检测率和较低的错误率。本文提出的方法在跟踪方面性能更好。3个视频序列的时间开销见表3,3个序列中,本文方法较之Ground Truth方法和卡尔曼滤波方法,其运行时间少、效率高。
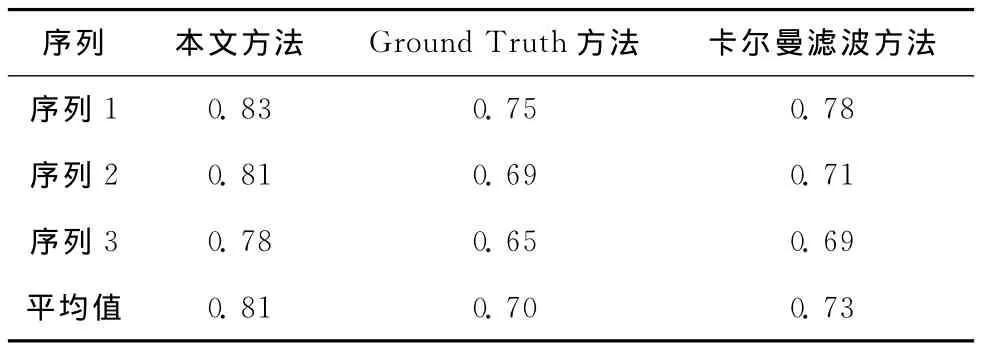
表1 3个视频序列的平均检测率的比较
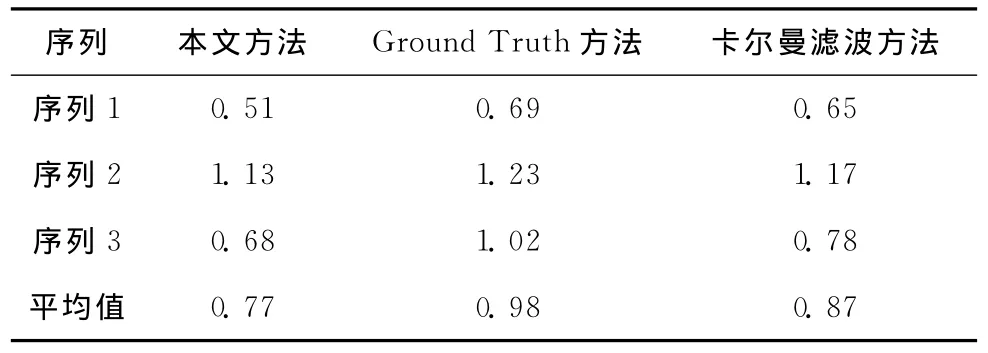
表2 3个视频序列的RMS的比较
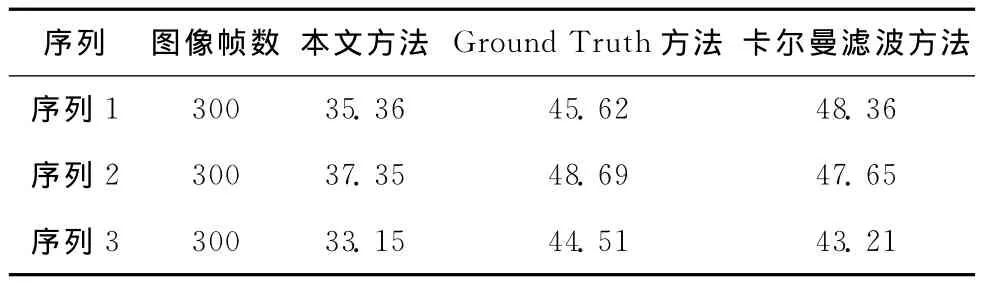
表3 3个视频序列运行时间的比较(单位:s)
5 结束语
本文提出了一种视频监控系统中单目静态视频场景的目标检测与自动跟踪方法。前景区域通过一个动态背景差分模块进行分割,这个模块适用于光照变化的条件。通过选择合适的动态阈值获得前景目标。为了跟踪目标,我们实现了一种改进的重叠跟踪方法,用于提高在目标分开和合并时遮挡条件下的跟踪效果。实验结果表明本文提出的方法在跟踪方面性能更好。
[1]LakshmiDevasena C,Revathi R.Video surveillance systems-a survey[J].International Journal of Computer Science Issues,2011,8(4):635-642.
[2]Cristani M,Raghavendra R,Del Bue A.Human behavior analysis in video surveillance:A social signal processing perspective[J].Neurocomputing,2013,100(1):86-97.
[3]HOU Zhiqiang,HAN Chongzhao.A survey of visual tracking[J].Acta Automatica Sinica,2006,32(6):603-618(in Chinese).[候志强,韩崇昭.视觉跟踪技术综述.自动化学报,2006,32(6):603-618.]
[4]Krahnstoever N,Yu T,Patwardhan K A,et al.Multi-camera person tracking in crowded environments[C]//Proc Twelfth IEEE 1nt Performance Evaluation of Tracking and Surveillance Workshop,2009:1-7.
[5]Zivkovic Z.Improved adaptive Gaussian mixture model for background subtraction[C]//Proceedings of the 17th International Conference on Pattern Recognition.2004,22(2):28-31.
[6]Davis J,Sharma V.Background-subtraction using contourbased fusion of thermal and visible imagery[J].Computer Vision and Image Understanding,2007,106,162-182.
[7]Bresson X,Esedoglu S,Vandergheynst P,et al.Fast global minimization of the active contour/snake model[J].Journal of Mathematical Imaging and Vision,2007,28(2):151-167.
[8]Hao Z,Wen W,Liu Z,et al.Real-time foreground-background segmentation using adaptive support vector machine algorithm[C]//Artificial Neural Networks,2007.
[9]Fashing M,Tomasi C.Mean shift is a bound optimization[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(3),471-474.
[10]Ross D,Lim J,Lin R,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1-3):125-141.
[11]Yilmaz A,Javed O,Shah M.Object tracking:A survey[J].ACM Computing Surveys,2006,38(4):1-45.
[12]Wu Y,Huang T S.Robust visual tracking by integrating multiple cues based on co-inference learning[J].International Journal of Computer Vision,2004,58(1):55-71.
[13]Blackman S S.Multiple hypothesis tracking for multiple target tracking[J].IEEE Aerospace and Electronic Systems Magazine.2004,19(1):5-18.
[14]Van der Tuin V.Computer-aided security surveillance design of the quo vadis object tracker[D].Enshede,Netherland:University of Twente,2007.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
汽车工程师(2021年12期)2022-01-17 02:29:54
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
当代陕西(2020年14期)2021-01-08 09:30:42
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
贵州师范学院学报(2016年4期)2016-12-01 03:54:07
信息安全研究(2015年3期)2015-02-28 20:17:57
太空探索(2014年1期)2014-07-10 13:41:50
