
HDFS数据存放策略的研究与改进
2014-02-09 07:47罗鹏,龚勋
计算机工程与设计 2014年4期
罗 鹏,龚 勋
(四川大学计算机学院,四川成都610065)
0 引 言
随着社会信息化程度的不断提高,各种形式的数据急剧膨胀[1]。因为数据量的快速增长,在网络上出现了越来越多的数据密集型应用,如何安全可靠及有效地存储海量数据是云计算[2]的一个重要研究方向,而HDFS(hadoop distributed file system)[3,4]就是解决海量数据存储问题的一个开源分布式文件系统。
HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。它提供高吞吐量来访问应用程序的数据,适合拥有超大数据集的应用。为了避免机器故障给数据带来毁灭性的灾难,HDFS将文件分块,且每个数据块以多个数据副本的形式存储在多个数据节点上[5]。针对数据存放的问题,HDFS将每个数据节点以机架为单位进行组织,并添加到网络拓扑中。在选择数据节点时,默认存放第一个数据块副本到本地机架,并随机选择远端机架存放其他数据副本,从而减轻了网络的负担,同时也降低了数据的风险。
但是,HDFS在选择数据存放节点时,没有考虑到集群中数据节点性能、网络状况和存储空间的差异性[6],从而造成集群整体负载不均衡,数据节点的资源无法合理利用。因此,本文在综合考虑每个数据节点CPU负载、内存负载、网络负载[7]和存储空间负载[8]的基础上,提出一种改进的数据存放策略。
1 HDFS数据存放策略
HDFS采用基于元数据服务器的组织结构进行工作。名称节点(namenode)负责存储和管理文件系统的元数据,数据节点(datanode)负责存储和管理数据[9]。当客户端需要写入数据时,客户端先访问名称节点,请求写数据操作。在通过名称节点的权限检查后,名称节点选择合适的节点,返回给客户端。
1.1 机架感知[10]理论
由于大型HDFS实例一般运行在跨越多个机架的集群上,不同机架上的两台机器之间通信需要经过交换机,在大多数情况下,同一个机架内的两台机器间的带宽会比不同机架的机器间的带宽大。因此,名称节点在选择合适的数据节点时,为了提高网络带宽的利用率、保证数据的可靠性,应用了机架感知的理论。该理论一个重要的前提是HDFS运行于一个具有树状网络拓扑结构的集群上。集群可以由多个数据中心组成,每个数据中心有多个机架,每个机架上有多个数据节点。
机架感知的网络拓扑结构示例图如图1所示。

图1 机架感知的网络拓扑结构
图1展示了两个数据中心的网络拓扑结构。其中Di(i∈[1,2])、Ri(i∈[1,4])都是交换机,DNi(i∈[1,12])是数据节点。
设rackid表示节点在网络拓扑结构中的路径。如图1所示,DN1的rackid=/D1/R1/DN1。每个rackid中都包含了该节点的父节点以及每个层次的祖先节点。
为了衡量两个节点的距离,HDFS采用了一个简单的方法,两个节点间的距离就是它们到最近的共同祖先的距离总和。通过机架感知的过程,名称节点可以确定每个数据节点所属的rackid,通过rackid可以计算数据节点之间的网络距离。
设distance(rackid1,rackid2)表示rackid1与rackid2之间的网络距离。
如图1所示,distance(/D1/R1/DN1,/D1/R1/DN1)=0(同一个节点)。
distance(/D1/R1/DN1,/D1/R1/DN2)=2(同一机架上的不同节点)。
distance(/D1/R1/DN1,/D1/R2/DN4)=4(同一数据中心不同机架上的节点)。
distance(/D1/R1/DN1,/D2/R3/DN7)=6(不同数据中心的节点)。
1.2 数据存放策略
设数据块的n个副本,分别存放在rackid为RACKID1,RACK-ID2,……,RACK-IDn的节点上(n∈N*),distance(RACK-IDi,RACK-IDj)表示RACK-IDi与RACK-IDj的距离,其中i≤n,j≤n(i、j∈N*)。
HDFS数据存放策略具体流程如下:
步骤1 如果Client是集群中的数据节点,那么Namenode选择Client主机存放数据块的第一个副本。
步骤2 如果Client不是集群中的数据节点,Namenode随机选择集群中的任意一个Datanode(数据节点)存放数据块的第一个副本。
步骤3 Namenode计算distance(RACK-ID1,RACKIDk),其中k∈N*,k≤n并且k≠1,随机选择与第一个副本存放节点不在同一个机架的数据节点作为第二个数据块副本的存放节点。
步骤4 Namenode计算distance(RACK-ID2,RACKIDk),其中k∈N*,k≤n,k≠1且k≠2,随机选择与第二个副本存放节点在同一个机架的数据节点作为第三个数据块副本的存放节点。
步骤5 对多于3个副本的情况,Namenode为其它副本随机选择集群中的任意一个还没有被选中Datanode作为数据块副本存放节点。
以上情况,在每个Datanode选中后,如果出现节点存储空间不足、网络连接负载过重或者所在机架选择的Datanode数量过多的问题,则重新选择一个数据节点。
2 改进的数据存放策略
2.1 问题描述
HDFS的数据存放策略基于以下两个基本原则:
原则1:存在两个或两个以上机架的情况下,如果数据块副本数量多于1个,则数据块副本至少分布在两个不同的机架上。
原则2:选择距离较近的数据节点,即“临近原则”。HDFS的数据存放策略在保证以上两个基本原则的基础上仍存在以下问题:
(1)HDFS数据存放策略在选择数据块副本存放节点的算法上随机性较大。
(2)HDFS数据存放策略虽然考虑了数据节点的网络连接数,却是在随机选择了数据节点之后再进行衡量,导致集群负载的均衡性不太理想。
基于上述问题,在保证原则1和原则2的前提下,本文提出一种综合考虑数据节点负载,优先选择负载最小的数据节点作为副本存放节点的数据存放策略。
2.2 改进策略
定义1 存放成本用于衡量一个数据节点存放数据块副本的优先程度,数据节点负载越大,存放成本越高,优先程度越低。
定义2 负载因子用于计算数据节点存放成本的参数,包括CPU负载、内存负载、网络负载和存储空间负载。
数学模型如下:
设数据节点的集合DN={DN1,DN2,DN3,…,DNm},DNi为该集合的任一数据节点,DNi∈DN,m为HDFS集群中数据节点的数量。数据节点DNi的CPU负载为CPUi,平均值为DNi的内存负载为Memi,平均值为DNi的网络负载为Neti,平均值为DNi最近k次CPUi负载的集合CPUi={CPUi1,CPUi2,…,CPUik},DNi最近k次Memi负载的集合Memi={Memi1,Memi2,…,Memik},DNi最近k次Neti负载的集合Neti={Neti1,Neti2,…,Netik},则
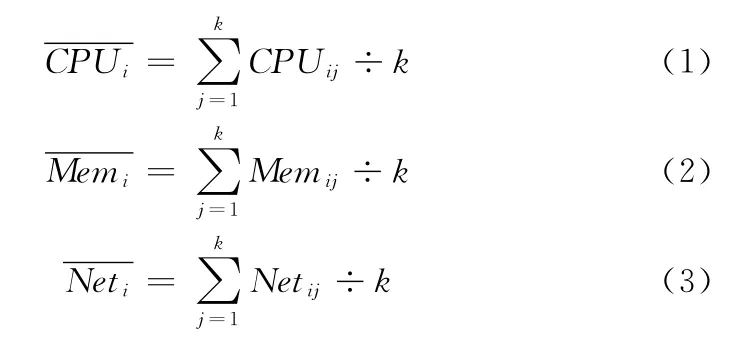
其中,k的值,本文默认为5,即计算最近5次的负载因子的平均值。
设WCPU、WMem、WNet、WS分别表示数据节点的CPU、内存、网络、存储空间负载的权值系数。DNi的存储空间负载为Si。
数据节点DNi的存放成本Ci可定义为

其中,WCPU、WMem、WNet、WS的具体值,需要通过实验的测试结果,选择最优化的一组权值系数。
2.3 算法描述
步骤1 Datanode每间隔60s,采集CPU运行时间,CPU空闲时间,内存总量,内存使用量,网络上行流量、网络下行流量,以及存储空间的使用信息。
步骤2 计算间隔时间内CPU利用率、网络带宽利用率,以及在采集时间点时内存的利用率、存储空间的利用率。并计算近5次CPU利用率、网络带宽利用率和内存利用率的平均值。
Datanode处理流程如图2所示。
步骤4 Namenode收到Datanode发送的心跳包,根据公式(4),计算数据块副本存放成本。
步骤5 在Client向Namenode发送写数据请求时,Namenode选择最优数据节点,返回给Client。
Namenode选择数据块副本存放节点的伪代码如下所示:(注:numOf Replication表示副本数量,且副本数量大于1的情况下,数据节点不能被重复选择)


在选择一个数据块副本的存放节点时,由于改进后的策略,需要在机架上选择存放成本最低的Datanode,而原始的HDFS策略只是在机架上随机选择Datanode存放数据块副本。对于有N个节点的数据中心,前者的计算量正比于数据中心的节点数量,后者的计算量也与数据中心节点存在线性关系,两者的复杂度都为O(N)。
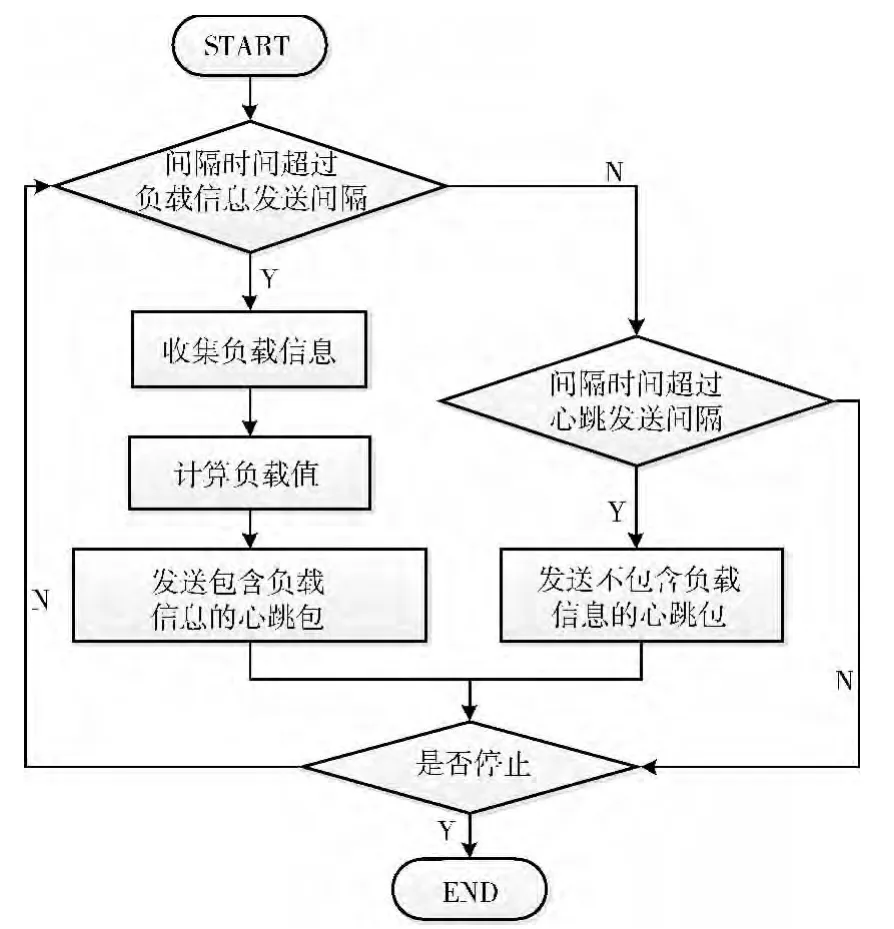
图2 Datanode处理流程
3 实 验
3.1 实验环境
实验的拓扑结构如图3所示,HDFS分布式文件系统搭建在A、B、C这3个机架上。slave1与master位于机架A,slave1负责测试数据的上传。slave2与slave3位于机架B,slave4与slave5位于机架C。其中,名称节点是机器master,slave1~slave5是数据节点。
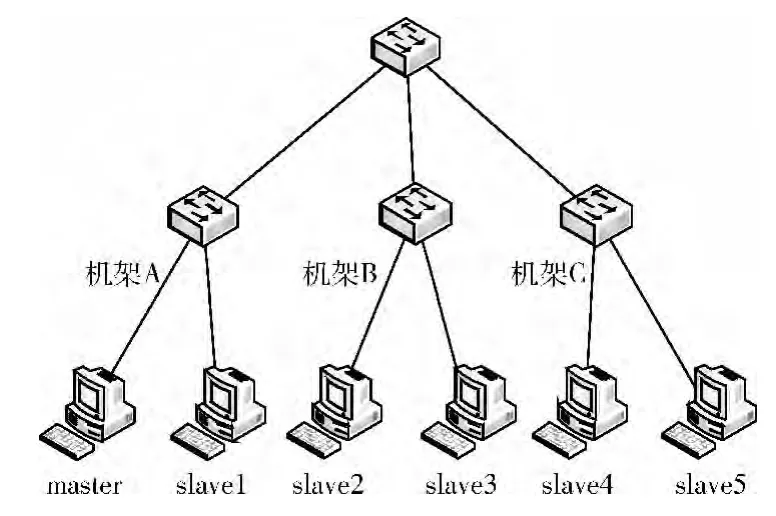
图3 实验拓扑
6个测试机器的软硬件配置和安装环境如下:
虚拟机:VMware Workstation 7.1.2 build-301548
操作系统:32位的CentOS 5.4系统
Java运行环境:JDK 1.6.0_20
分布式环境:Hadoop 0.20.203.0
CPU:2.93GHZ
内存:1GB
网络带宽:100 Mb/s
3.2 实验内容及结果分析
3.2.1 可行性验证
在本实验中,分别获取了HDFS在两种策略下,处理不同大小的上传数据所耗费的时间。实验中的时间开销是通过多次测试,获取的平均值。实验数据通过位于机架A的slave1进行上传,数据大小包括:256MB,512MB,1GB,2GB,3GB。结果如图4所示。

图4 两种策略的时间开销对比
由于本实验采取3个副本存放数据,所以在两种策略中,第一个副本都是存放在本地(即slave1)上。如图4所示,在测试数据为256MB时,两种策略的时间开销基本相同,随着测试数据量的增多,两者时间开销的差距逐渐增大。改进的策略相比HDFS策略,后者在数据节点较少的情况下,由于随机的选择数据存放节点,容易导致部分数据节点网络负载偏重,而其他数据节点空闲,从而出现数据副本在节点间传输相对偏慢的情况,而前者综合考虑了每个数据节点的负载,使得集群的网络带宽等资源得到更合理的利用。由此可说明改进的数据存放策略是可行的。
3.2.2 比较负载的均衡性
本实验分别比较在两种策略下,整个集群所有数据节点的CPU负载、内存负载、网络负载和存储空间负载的均衡性。实验中,slave1上传1G的测试数据,并在图5~图8中,列出了各个数据节点在两种策略中的各项平均负载值的对比。图9通过式(4)计算每个数据节点的平均存放成本值,从整体上,可以看出在两种策略下,整个集群负载的均衡性。
(1)CPU负载
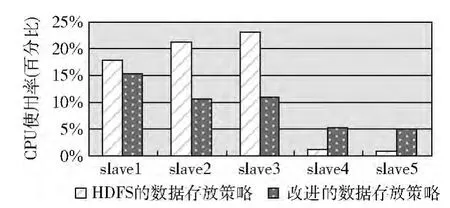
图5 CPU平均负载对比
(2)内存负载
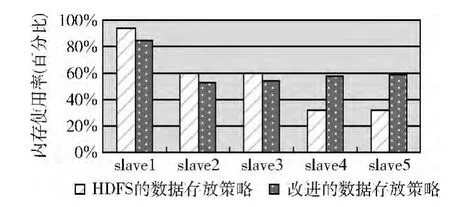
图6 内存平均负载对比
(3)网络负载
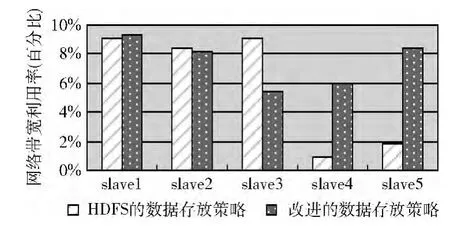
图7 网络平均负载对比
(4)存储空间负载
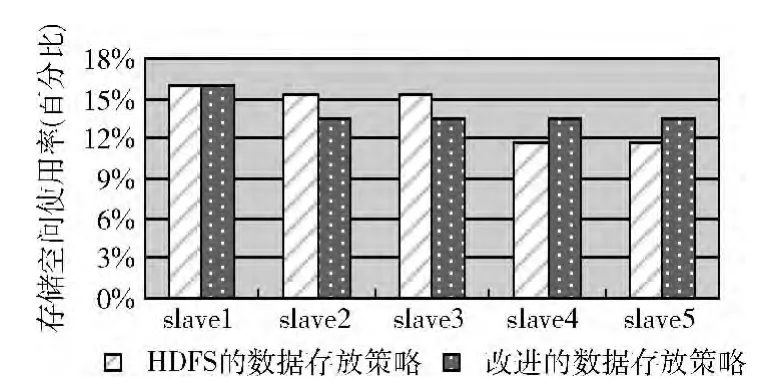
图8 存储空间负载对比
(5)数据节点平均存放成本比较
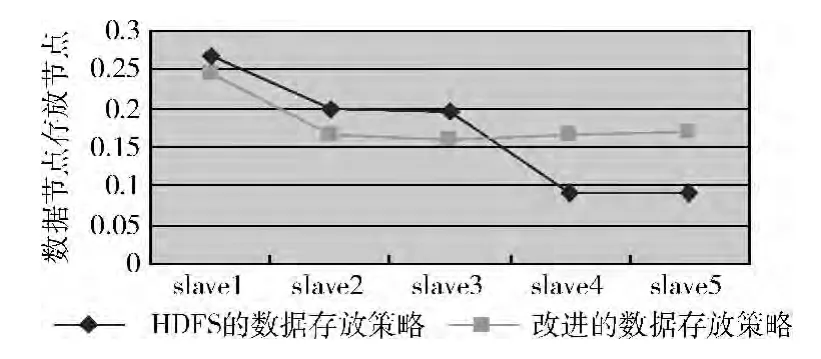
图9 数据节点平均存放成本对比
通过反复实验,参考CPU负载、内存负载、网络负载、存储空间负载的统计结果,根据各项负载因子的负载能力,波动情况及其重要性,分别设置WCPU=0.1,WMem=0.2,WNet=0.3,WS=0.4。
由于数据节点slave1作为上传测试数据的客户端,根据两种策略的算法,slave1会存储所有数据块的第一个副本,所以slave1的负载在所有数据节点中是最高的。
slave2与slave3、slave4与slave5分别在同一个机架,根据两种策略的算法,slave2与slave3、slave4与slave5被选中的概率是相等的,所存储的数据量也是相同的。因此,从图5~图8可以看出,同一个机架上的数据节点负载情况是基本一致的。
改进后的数据存放策略相比原始的HDFS数据存放策略,由于处理实验数据耗费时间相对较少,所以,如图5~图8所示,从整个集群来看,CPU平均负载,内存平均负载,网络平均负载,前者的数值更高。
图9展示了slave1~slave5所有数据节点的平均存放成本。从图中可以看出,slave1的平均存放成本是最高的,slave2与slave3、slave4与slave5平均存放成本是基本相同的。改进的数据存放策略相比HDFS数据存放策略,由于综合的考虑了每个数据节点的性能差异,所以在数据节点的选择过程中避免了连续多次选择性能较低的节点,更好的利用了集群的网络资源,以及各个数据节点的本地资源。如图9所示,改进后的策略,集群负载的均衡性得到了很好的优化。
4 结束语
文中介绍了HDFS分布式文件系统数据存放的相关内容。针对HDFS的数据存取策略没有考虑节点的差异性导致节点负载不均的问题,提出了改进的方法。该方法综合考虑了节点的CPU负载,内存负载,网络负载和存储空间负载,通过设置负载因子的权值提高HDFS的数据存放性能。
本文的不足是没有对负载因子权值的选取进行更深入的研究。权值的选取与HDFS运行环境相关,所以需要结合实际情况反复进行实验,才能得出更加精确的数据存放策略,进一步提高HDFS分布式文件系统数据存放的性能。
[1]Wade.IDC's latest research report:“Digital Universe in 2020”[EB/OL].[2012-12-26].http://info.chinabyte.com/487/12496987.shtml(in Chinese).[Wade.IDC最新调研报告:“2020年的数字宇宙”[EB/OL].[2012-12-26].http://info.chinabyte.com/487/12496987.shtml.]
[2]CHEN Kang,ZHEN Weimin.Cloud computing:System instances and current research[J].Journal of Software,2009,20(5):1337-1348(in Chinese).[陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.]
[3]Apache.Apache Hadoop[EB/OL].[2013-07-10].http://hadoop.apache.org/.
[4]Dhruba Borthakur.HDFS architecture guide[EB/OL].http://archive.cloudera.com/cdh4/cdh/4/mr1/hdfs_design.pdf,2008.
[5]Rahman R,Alhajj R,Barker K.Replica selection strategies in data grid[J].Journal of Parallel and Distributed Computing,2008,68(12):1561-1574.
[6]Tom White.Hadoop:The definitive guide[M].2nd ed.ZHOU Minqi,WANG Xiaoling,transl.Beijing:Tsinghua University press,2011(in Chinese).[Tom White.Hadoop权威指南[M].2版.周敏奇,王晓玲,译.北京:清华大学出版社,2011.]
[7]LIN Weiwei.An improved data placement strategy of Hadoop[J].Journal of South China University of Technology(Natural Science Edition),2012,40(1):152-158(in Chinese).[林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报(自然科学版),2012,40(1):152-158.]
[8]ZHOU Jingli,ZHOU Zhengda.Improved data distribution strategy for cloud storage system[J].Journal of Computer Applications,2012,32(2):309-312(in Chinese).[周敬利,周正达.改进的云存储系统数据分布策略[J].计算机应用,2012,32(2):309-312.]
[9]WANG Yijie,SUN Weidong,ZHOU Song,et al.Key technologies of distributed storage for cloud computing[J].Journal of Software,2012,23(4):962-986(in Chinese).[王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986.]
[10]Apache.Rack aware HDFS proposal[EB/OL].https://issues.apache.org/jira/secure/attachment/12345251/,2008.
猜你喜欢
农业装备与车辆工程(2022年7期)2022-10-31
科学技术创新(2022年28期)2022-10-21
机械设计与制造(2022年10期)2022-10-12
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
电脑爱好者(2019年17期)2019-10-30
中国计算机报(2018年13期)2018-05-23
中国知识产权(2018年3期)2018-04-13
电子竞技(2009年13期)2009-09-28
电子竞技(2009年14期)2009-09-07
