
基于行为分析的钓鱼页面检测技术研究
2014-01-05 05:52赵功勋杨义先
成都信息工程大学学报 2014年5期
赵功勋,陈 运,杨义先
(1.成都信息工程学院计算机学院,四川成都610225;2.北京邮电大学,北京100876)
0 引言
随着互联网技术及应用的普及,以及电子商务的飞速发展。越来越多的商业活动开始通过网络进行交易,由于巨大的经济利益,网上交易在给人们带来方便的同时,也成了不法分子的攻击目标。从中国反钓鱼联盟(APAC)发布的数据来看,截止到2014年2月,联盟累计认定并处理的钓鱼网站多达170203个。
网络钓鱼[1](Phishing)是指钓鱼者利用具有欺骗性的电子邮件或者仿造正规的网站进行网络诈骗。通过引导用户点击,最终链接到自己精心设计的钓鱼页面达到欺骗的目的。通常是获得类似于银行账户名,信用卡号等敏感信息。现今,常见的网络欺诈手段如下:(1)注册和真实域名十分相似的网址,如钓鱼者假冒网站域名和真实域名十分相似,这样的方式很隐蔽,不容易被用户察觉,因此该方法的欺骗率很高。如www.lcbc.com.cn假冒www.icbc.com.cn。(2)伪造与正规网站具有高相似度的页面。假冒网站通常会利用正常页面的大多数信息,如正规网站的logo、图表、新闻内容和链接等,在页面的很少部分进行更改,如账号密码输入界面,达到迷惑用户的目的。(3)通过编写在网页的脚本,对页面进行修改,最终链接到钓鱼页面。
目前,对于钓鱼页面的检测,有基于黑白名单库,基于页面链接[2],基于网页文本特征,基于机器学习[3],视觉相似度[4-5]等方法。基于视觉相似度的检测方法,虽取得一些效果。但存在很多问题,特别是在将整体页面做成图片进行欺诈的情况下,检测难度大,目前很难实际大范围应用。另外,对于脚本代码的检测,是需要人工进行分析,同样在应用方面受到受限。
基于钓鱼者行为的钓鱼页面检测能够很好的与以上各种检测方式互为补充,也能以较高的准确率对钓鱼页面进行检测。通常,攻击者希望用较低的代价部署大规模的钓鱼页面,因此尽量绕过各种平台的检测成为攻击者着重考虑的目标,为达到较高的攻击成功率,考虑利用网页之间的链状结构关系进行网络钓鱼,很好的躲避了检测。然而,由于这种钓鱼页面规模性的引入,在某种程度上成为可以被用来追踪的钓鱼者行为特征。基于这种现实情况,挖掘钓鱼页面的链状结构信息,提取结构特征、建立模型,作为检测钓鱼页面的方法,提高钓鱼页面的检测能力。
1 钓鱼者行为特征
网页钓鱼者行为特征简单表示为一个树状的有向图,用(r,v,e,t)表示。其中:r表示原始钓鱼页面,页面用URL(Uniform Resoure Locator)表示。r是有向图的根节点。网页链接节点集用v表示,每个节点代表一个链接,链接到网络中的某项资源。e是所有有向边的集合。对于任意vi∈v,如果用户对于vi的请求导致页面vj的请求,则有vj∈v且< vi,vj>∈e。t代表汇接点的集合。
汇接点代表一条路径的最后一个节点,一个汇接点就是最终代表的钓鱼页面,也标志着一次成功的网络钓鱼。描述钓鱼者的行为特征如图1所示。
利用网页的频繁子图[6]结构进行数据分析,获取页面之间的链状结构关系已成为近几年来研究的热点课题,与利用页面链接植入木马的情景类似[7]。利用频繁子图的相关挖掘算法,提取钓鱼页面的链接树结构,获得共性的图状结构特征。如果待检测的页面与系统库的钓鱼页面具有相似的子图结构,那么可以判断这些相似的子图结构能够在某方面反映二者具有相同的钓鱼特征。通过提取这些相同子图特征,作为判断未知页面是否为钓鱼页面的标准,结合传统的钓鱼页面检测技术,提高钓鱼页面的检出率。

图1 钓鱼者行为特征图

图2 钓鱼网页链接结构实例
图2是一个伪造在线购物网站进行钓鱼的页面链接结构图,通过网页的外链,用户最终被引导至网络钓鱼者设计好的页面,获取用户账号密码等敏感信息。对应到公式(r,v,e,t)中,r表示节点1,即https://login.taobao.com/member/login.jhtml,代表原始的钓鱼页面。v在图2中体现为初始钓鱼页面的外链,如节点2、3、4.在图2中表示的边集合e为节点1到2的边,1到3的边,1到4的边的集合。汇结点t对应图2中的节点12,即最终的窃取帐号页面。
1.1 频繁子图挖掘
给定集合和支持度阈值minsup,频繁子图挖掘的目标是找出所有子图支持度s(g),满足s(g)>minsup的子图g(其中子图g的支持度定义为包含它的所有图所占的百分比,GD为图的集合,g'为同构图集合)。
频繁子图模式的挖掘非常耗时,因为模式的搜索空间是指数的。为了解释这项任务的复杂性,考虑包含d个实体的数据集。在频繁项集挖掘中,每个实体是一个项,可能产生2的d次方个候选项集。在频繁子图挖掘中,每个实体是一个顶点,顶点到其他顶点的边的最大值为 d-1。假定唯一的顶点标号,则子图的总数是,其中,Cid是选择i个顶点形成子图的方法数,而是子图的顶点之边的最大值。
将图的边 e=(vi,vj)表示为形式 (vi,ni,vj,nj,m)的 5 元组,也即图的DFS编码。其中2个节点标识vi,vj,2个节点标号ni,nj,1个边标号m。例如

图3 标号图的表示方法

1.2 算法复杂度比较
与 GSpan[9-10],CloseSpan[11-14]和FFSM[15]挖掘频繁子图算法相比,GraphGen 算法的时间复杂度是,表1为几种挖掘算法复杂度的对比。
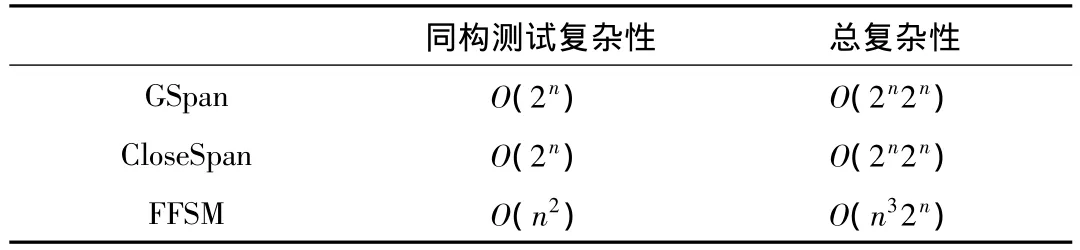
表1 几种算法时间复杂度比
gSpan算法思想如下:(1)计算输入图中所有边的支持度,删除输入图集合中的非频繁边,以频繁边作为初始子图。(2)对k频繁子图的最小DFS码的DFS树进行最右路经扩展,每次增加一条边,得到k+1候选子图。(3)若k+1候选子图不是最小DFS码形式的,则该图是冗余的,从候选子图中删除。(4)在计算频繁子图的支持度时,记录k频繁子图的所有可能情况,这样k+1候选子图的支持度就可以通过对k频繁子图的所有可能情况进行最右路径扩展获得。(5)当某条频繁边的所有子节点都生成后,将该边从输入图集合中删除,减少输入图的集合。算法gSpan通过一个列表维护频繁子图的同构图,这样做能够很好地减少制约算法执行效率的测试同构次数,但是,算法并不能完全避免子图的同构测试,且对于边集的扩展,算法的复杂度也很高O(2n),图同构的复杂度为O(2n),因此总的时间复杂度是O(2n2n)。
CloseGraph算法类似于gSpan算法,用闭频繁图集代替频繁图集,以减小频繁子图的挖掘的数量及搜索空间,并在gSpan的基础上引入等价出现和提前终止的概念。与gSpan算法的思想一致,只是在剪枝的过程中增加一个对闭图的判断,如果判断条件成立,则对图g扩展,不用再对图g进行最右路径扩展。因此在算法的时间复杂度上,二者没有多大差别。
算法FFSM利用标准邻接矩阵(Canonical Adjacent Matrix,CAM)对图进行描述.因此,FFSM不但将子图同构问题转化成对矩阵的操作,也将图扩展过程巧妙的转化为矩阵的联接操作与矩阵的扩展操作,因为利用矩阵的联接以及扩展完成图的扩展,所以扩展边的时间复杂性为O(2nm2n),图同构测试的时间复杂性为O(m2),总的时间复杂度为O(2nm4n)。具有m个节点的完全图包含m(m-1)/2条边,因此,其时间复杂性转化为用频繁边数表示的情况为O(n32n)。
利用的算法是基于如下的步骤:采用深度优先算法生成频繁子树,算法的复杂度为O(2n),通过参考文献提出的方法,将子图同构[16-19]测试的时间复杂度控制在。然后对前一步生成的频繁子树进行扩展,以广度优先方式扩展边用来形成频繁子图。综上,顺序完成以上两步的算法时间复杂度为经过测试,在对1万多个样本的频繁子图挖掘的过程中,不到1分钟就可以找到所有的频繁子图。
2 系统流程结构图
钓鱼页面检测系统由以下几部分构成,系统能够有效地检测钓鱼页面的结构,已经应用在实际的钓鱼页面检测中。
(1)钓鱼页面链接分析提取模块
(2)频繁子图挖掘系统
(3)钓鱼网页频繁子图模式库
(4)子图特征匹配模块
(5)其他处理模块
钓鱼页面链接分析提取模块利用网络爬虫,爬取钓鱼页面链接结构,分析url相互链接关系,形成url链接关系结构图。
频繁子图挖掘子系统基于GraphGen频繁子图模式挖掘算法,针对数万级别的网页钓鱼页面链接结构进行分析,挖掘频繁模式,提取共同的频繁子图模式,通过人工分析和验证,得到频繁子图模式库,作为判断可疑网页是否为钓鱼网页的标准。
钓鱼页面频繁子图模式库是基于大量已知的钓鱼页面形成的页面链接结构知识库。
子图特征匹配模块式辅助检测,通过提取url的图状链接关系,获得不同页面之间的关系结构图,基于频繁子图模式库,进行子图特征匹配。如果某一频繁子图模式能够和页面的结构相匹配,那么就判定该页面是钓鱼页面。
其他处理模块可以是传统的基于黑白名单库,url特征等进行钓鱼页面检测。作为一种补充,用来判断在特征子图库中没有匹配到的页面。经过其他处理模块判断为钓鱼url的网页结构添加到已有的频繁子图模式库,用以更新模式库。图4为系统流程结构图。
3 实验结果
系统实验采用的是华为的反钓鱼平台,实验数据集来自APWG,APAC,PhishTank等网站获取的钓鱼页面的url。系统针对1万多个url进行分析,包括国内外银行网站以及网购网站,如ebay、淘宝等。通过提取网页的url链接结构图,使用GraphGen频繁子图模式挖掘算法,选取某个支持度阈值(选择阈值为100)进行频繁子图的挖掘。经过分析筛选,确定了50个子图的模式,并将前10个不同模式的出现次数记录下来,如表2所示。

图4 系统流程结构图

表2 子图模式出现频度

图5 频繁子图模式实例
由表2可以看出,模式a出现的次数最多,进一步分析可知,模式出现频率比较高的网页中需要用户提供个人的敏感信息登陆框,该模式主要出现在一些大型购物网站的页面结构中,钓鱼者通常喜欢频繁的攻击这些网购网站,引导用户,最终将页面链接到精心设计的钓鱼页面上。
模式b(图5)代表游戏赌博点卡充值类的钓鱼url,页面http://www.levillas.com/中的2个链接http://www.tb8899.com/?Intr=34952和http://www.ceo2010.com/?Intr=28628具有相同的页面结构,均是通过用户注册,银行账号,手机号等用户输入框获取用户敏感信息,用户完成注册后,在提交页面时,页面跳转后的url和跳转之前的url一样,很明显,钓鱼者改变了页面的url,这是一种欺诈手段。
正规的银行网站因其多用户,较大数据量的原因,网站的结构设计通常很复杂,同样,网站漏洞的修复、维护及业务的调整使得网页的拓扑结构变得更加繁杂,页面自然存在大量的链接。相对于银行网站,伪造的钓鱼页面除了少数的相似页面外,拓扑结构通常都非常简单。图6~7分别表示RBC官网和模仿的钓鱼页面链接结构图。

图6 正规银行网页结构

图7 钓鱼网页链接结构
为了检测运用子图匹配模式进行检测的效率,将统计的数据记录如表3所示。从表3可以看出,通过频繁子图模式检测钓鱼页面的检测率在80%左右,这表明通过频繁子图的方式可以对钓鱼页面进行有效的检测。该算法中对于阈值参数的选择,可以通过实验的调整,结合数据挖掘中的回归问题,选取合适的阈值,避免过分拟合输入数据。进一步测试可以得到,在某个阈值处,该方法对于测试数据可以得到比较好的检测率。大于或者小于该阈值,检测率下降。因此,通过频繁子图的方式进行钓鱼页面的检测可以有效的检出钓鱼页面。

表3 子图模式检测率
4 结束语
针对钓鱼网页的url链接结构,提出利用行为分析(挖掘网页url链接结构)得到的频繁子图进行挖掘,提取钓鱼页面的共同子图特征,并利用钓鱼页面特征检测系统进行检测,实验证明,该检测方法能够加强对钓鱼页面的检测能力,作为传统钓鱼页面检测方法的补充,提高了检出率。也可以将页面的频繁子图作为判断网页是否为钓鱼页面的一种特征,将网页url,视觉特性特征等其他特征作为判定钓鱼页面的总体特征向量,结合机器学习对可疑网页进行判定。对于基于频繁子图模式的钓鱼页面检测,系统的开销在于挖掘页面的频繁子图模式上,同时匹配模式库仍然占用了一定的时间,寻找更优化高效的频繁子图挖掘算法对于大规模钓鱼页面的检测很有必要。
致谢:感谢成都市高校院所科技成果转化项目(12DXYB340JH-002);深圳市产学研合作项目(CXY201106240019A)对本文的资助
[1] Anti-Phishing Working Group.Phishing Activity Trends Report[R].Q42,2009.
[2] J Ma,S L K,S Stefan,et al.Beyond blacklists:learning to detect malicious websites from suspicious urls[C].Proceedings of the 15th international conference on Knowledge discovery and data mining,2009:1245-1254.
[3] Sujata Garera,Niels Provos,Monica Chew,et al.A Framework For Detection an dMeasurement of Phishing Attacks[A].In:Christopher Kruegel,ed[C].Proc.of the WORM’07.USA:ACM Press,2007:1-8.
[4] W Liu,X Deng,G Huang,et al.An Anti-Phishing Strategy Based on Visual Similarity Assessment[J].IEEE Internet Computing,2006,10(2):58-65.
[5] W Liu,G Huang,X Liu,et al.Detection of Phishing Web Pages Based on Visual Similarity[C].Proc.14th Int’l World Wide Web Conf,2005:1060-1061.
[6] 张喜.应用于图分类的频繁图挖掘算法的研究[D].秦皇岛:燕山大学,2013.
[7] 韩心慧,龚晓锐,诸葛建伟,等.基于频繁子树挖掘算法的网页木马检测技术[J].清华大学学报(自然科学版),2011,(10).
[8] 李先通,李建中,高宏.一种高效频繁子图挖掘算法[D].哈尔滨:哈尔滨工业大学,2007.
[9] X Yan,J Han.gSpan:Graph-based Substructure Pattern Mining[C].Proc.of the 2002 IEEE Intl.Conf.on Data Mining,Maebashi City:Japan,2002:721-724.
[10] Yan Y Han J.gSpan:Graph-Based substructure pattern mining[C].Proc.of the 2002 Int’l Conf.on Data Mining(ICDM 2002).Maebashi,2002.
[11] Yan X,Han J.CloseGraph:Mining closed frequent graph patterns[C].Proc.of the 9th ACM SIGKDD Int’l Conf.on Knowledge Discovery and Data Mining(KDD2003).Washington,2003.
[12] 陈晓.基于CloseGraph的图分类算法研究[D].秦皇岛:燕山大学,2010.
[13] 董安国,高琳,赵建邦.图模式挖掘中的子图同构算法[J].数学的实践与认识,2011,(13).
[14] 周溜溜.基于图结构的数据挖掘研究及应用[D].南京:南京林业大学,2013.
[15] Han J,Wang W,Prins J.Efficient mining of frequent subgraphs in the presence of isomorphism[C].Proc.of the IEEE Int’l Conf.on Data Mining(ICDM 2003),2003.
[16] Ueda N,Aoki-Kinoshita KF,Yamaguchi A,et al.A probabilistic model for mining labeled ordered trees:Capturing patterns in carbohydrate sugar chains[J].IEEE Trans.on Knowledge and Data Engineering,2005,17(8):1051.
[17] Buss SR.Alogtime algorithms for tree isomorphism,comparison and canonization[C].Computational Logic and Proof Theory,Proc.of the 5th G.del Colloquium’97,Lecture Notes in Computer Science#1289.Berlin:Springer-Verlag,1997:18-33.
[18] Yang R,Kalnis P,Tung AKH.Similarity evaluation on tree-structured data[C].Proc.of the SIGMOD 2005.Baltimore,2005.
[19] Rückert U,Kramer S.Frequent free tree discovery in graph data[C].Symp.on Applied Computing archive,Proc.of the 2004 ACM Symp.on Applied Computing.SESSION:Data Mining(DM).2004:564-570.
[20] Jin R,Wang C,Polshakov D,et al.Discovering frequent topological structures from graph datasets[C].Proc.of the KDD 2005.Chicago,2005:606-611.
猜你喜欢
同济大学学报(自然科学版)(2019年2期)2019-04-02
计算机与数字工程(2019年3期)2019-03-26
中国惯性技术学报(2019年6期)2019-03-04
西华师范大学学报(自然科学版)(2018年3期)2018-09-26
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
小学生导刊(低年级)(2016年8期)2016-09-24
电子科技大学学报(2016年2期)2016-08-31
火控雷达技术(2016年3期)2016-02-06
小学科学(2015年6期)2015-07-01
小学科学(2015年6期)2015-07-01
