
一种改进的人工鱼群聚类算法
2014-01-05 05:52李小培张洪伟邹书蓉
成都信息工程大学学报 2014年5期
李小培,张洪伟,邹书蓉
(成都信息工程学院计算机学院,四川成都610225)
0 引言
数据挖掘中的聚类是将数据样本按照最近邻原则划分到不同的类簇中,并达到相同簇中数据对象相似度最大,不同簇中数据对象相似度最小的目的[1]。由此,可以迅速发现数据对象之间的种种关系,从而方便研究和处理。虽然聚类分析算法因为待聚类的数据样本的属性类型和聚类目的而有差异,但是通常可归结为以下几类[2]:基于网格的方法、基于密度的方法、划分方法、层次方法、基于智能的方法等[3-7]。传统的聚类算法虽然各有所长,都能处理适合自身算法的特定问题,不可否认的是仍然有许多不足之处。比如说对数据样本中的噪声数据和孤立点处理能力较弱,随着数据样本集的不断增长导致算法执行效率降低,样本集的输入次序影响聚类结果等。随着社会不断进步,智能技术快速发展,它能够处理高维高复杂性数据、对初始样本集不敏感、收敛速度快且正确率高,越来越多的人尝试着用智能算法解决聚类问题[8]。
李晓磊[9]2002年首次提出基于智能思想的人工鱼群算法。算法的基本思想是:一片水域中食物浓度最高的地方也是鱼类生存数目最多的地方。根据这一特点构造人工鱼的4种基本行为:随机行为、觅食行为、聚群行为和追尾行为。通过人工鱼的个体寻优达到凸显整个鱼群最优解的目的。该算法的主要特点有对初始值的设定不敏感、能够处理高维高复杂性问题、寻找最优解的速度快等。人工鱼群算法已经在神经网络、聚类分析、图像分割等领域得到广泛的应用[10-12]。
1 K-Means聚类算法
假设在N维数据空间中,样本集X有n个数据样本xi={xi1,xi2,…,xiN},i=1,2,…,n,也就是说每个数据样本都有N个属性值。这n个数据样本构成数据的样本集是一个n×N矩阵。根据每个样本都应被分配到离自身最近的类簇中这一原则,将样本集中的数据记录划分到P个互不相交的子集中。每个子集Ck={xki|xki⊂X},其中xki表示被划分到第k=1,2,…,P个子集中的数据样本。这P个子集互不相交,而且它们的补集是整个数据集,其数学模型如下:

K-Means是聚类算法中的经典[13-14],主要步骤:
(1)在样本集{x1,x2,…,xn}中随机选择K个样本记录,作为K个类簇中心。
(2)计算出样本xi,i=1,2,…,n到各个类簇的距离,并将样本xi划分到距离自己最近的类簇中,即如果‖xi-cj‖< ‖xi-cl‖ ,j=1,2,…,K ,l=1,2,…,K 且 l≠ j。那么就将样本 xi划分到 cj中。
(3)根据各个类簇中所含的样本及样本数目,重新计算K个类簇的中心,令c'i=ci。
(4)计算各个类内误差之和。
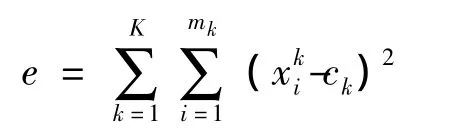
(5)如果各个类簇中心不再变化或算法达到一定的迭代次数,还可以是e<ε,ε是一个很小的正数,则算法停止。
2 人工鱼群算法
假设有n条数据记录,每条数据记录有N个属性,将这些数据记录聚成K个簇。共有T条人工鱼,人工鱼的视野、拥挤度因子、步长、觅食行为的最大尝试次数、人工鱼算法的最大迭代次数分别用 visual、delta、step、try-number、MaxGen表示。人工鱼的随机、觅食、聚群、追尾行为的描述如下。
(1)随机行为:随机行为是4种行为中最简单的一种行为,不一定能够移动到最优解,但是它能够解决陷入局部极值的困难。
(2)觅食行为:人工鱼Xi在visual邻域内寻找较优的位置Xj,如果Xj的目标函数值小于Xi,那么人工鱼就向Xj移动,否则继续寻找。如果在try-number次没有找到,则人工鱼执行随机行为。
(3)聚群行为:人工鱼Xi在visual邻域内寻找自己的伙伴并统计伙伴的数目nf。如果nf=0,人工鱼就执行觅食行为,否则计算出人工鱼的聚类中心Xj。计算Xj的目标函数值Yj。如果满足条件,那么Xi就向Xj移动,否则执行觅食行为。
(4)追尾行为:人工鱼Xi在视野范围内寻找伙伴并记下伙伴数据nf。找出目标函数值最小的伙伴Xj,并计算出Xj对应的Yj。如果,那么人工鱼就向Xj移动,否则执行觅食行为。
3 改进的人工鱼群聚类算法
文中算法的基本思想:在N维空间中,将n个数据记录分成K类,每条人工鱼就代表一个类簇中心,它是一个K×N的矩阵。首先对每条人工鱼进行初始化。然后让每条人工鱼选择追尾、聚群、觅食、随机行为中的一种执行,执行完相应操作后利用K-Means算法进行优化并计算出人工鱼的食物浓度,不断重复人工鱼的位置更新和K-Means算法优化操作,直到算法结束。
3.1 改进的人工鱼群聚类算法中的元素说明
(1)决策变量:每条人工鱼个体就是一个决策变量,同时也代表K个类簇中心。故人工鱼的位置向量Xi=(ci1,ci2,…,ciK),ci,i=1,2,…K表示第i个聚类中心,是一个N(每条数据记录的属性个数)维的矢量。即每条人工鱼都是一个K×N的矩阵。
(2)目标函数:按照最近邻原则将数据样本划分到某条人工鱼个体的相应类簇中,并计算出各个数据样本与最近类簇中心的方差和,这就是该条人工鱼的目标函数值,即目标函数值的计算公式,其中mk是第k个类簇中样本的个数,xki代表属于第k个类簇的样本,cjk表示第j条人工鱼的第k个类簇中心。
(3)两条人工鱼之间的距离:计算两条人工鱼之间距离时采用欧氏距离进行计算。人工鱼Xi=(ci1,ci2,…,ciK),人工鱼Xj=(cj1,cj2,…,cjK)之间的距离计算公式为
(4)人工鱼的r邻域:在人工鱼群集合T中,某条人工鱼Xi的邻域指的是与该条人工鱼的距离小于r的其他人工鱼的集合,表示为 N(Xi,r)={Xj|distance(Xi,Xj)< r,Xj∈ T}。
(5)人工鱼的聚类中心:假设人工鱼Xi的邻域内有nf条人工鱼,这nf条人工鱼都称为人工鱼Xi的伙伴,Xi的伙伴中心可表示为
3.2 人工鱼群算法的改进
为了加快人工鱼群算法的求解速度并且改善人工鱼群算法的聚类精度,对人工鱼群算法做如下改进。
(1)人工鱼群算法使用动态移动步长。当人工鱼的下一个位置的函数值比当前位置函数值小时,应该让人工鱼移动步长变大,让人工鱼移动(1+Yi-Yj)×step,其中Yi是人工鱼当前位置的函数值,Yj是人工鱼下一个位置的函数值。可以加快人工鱼找到最优解。
(2)为了让人工鱼更快地发现最优解,在觅食、聚群、追尾3种行为中加入全局最优人工鱼的信息,即人工鱼移动时将向全局最优人工鱼和visual邻域内最优人工鱼的位置移动。这不仅加快求解速度也提高求解精度。
3.3 文中算法步骤
使用改进的人工鱼群算法和K-Means算法进行结合。不仅克服了K-Means算法对初始类簇中心敏感的缺陷也改善了人工鱼群算法容易陷入局部极值、后期收敛速度慢的弱点。两者结合求解聚类问题的具体步骤如下。
(1)初始化算法中的相关参数,包括人工鱼的规模(T)、视野(visual)、拥挤度因子(delta)、移动步长(step)、觅食行为最大尝试次数(try-number)、文中算法最大迭代次数(MaxGen)类簇个数(K)、样本个数(n),样本属性个数(M)。
(2)初始化人工鱼种群。人工鱼的初始类簇中心采用随机将样本划分到某个簇中,然后计算各个簇的样本平均值并将其作为该簇的中心,得到的K个簇作为一条人工鱼,不断重复以上过程直到产生T条人工鱼为止。
(3)根据目标函数计算公式求出每条人工鱼的函数值,并记录函数值最小的人工鱼信息。
(4)人工鱼尝试执行聚群行为和追尾行为,如果聚群行为的目标函数值小于追尾行为,人工鱼执行聚群行为,否则人工鱼执行追尾行为。
(5)执行完相应行为后,用K-Means算法进行优化,并计算人工鱼的目标函数值。
(6)如果人工鱼的目标函数值小于全局最优人工鱼的目标函数值,则更新全局最优人工鱼信息。
(7)判断是否每条人工鱼都已经循环完毕,如果不是,则转到步骤(3)。
(8)判断是否达达到算法的最大迭代次数,如果否,转到步骤(3),如果是,算法结束。
4 仿真实验
UCI机器学习数据库是加州大学欧文分校提出,是一个常用的标准测试数据库。所用实验数据为UCI数据库中的iris和glass两个经典数据集。Glass数据集共有214条数据记录,6个类标签,每个数据记录有9个属性;iris数据集含有150条数据记录,3个类标签,每条数据记录有4个属性。
实验所用的运行环境为,处理器:P22.99GHz;内存大小1.97GB,操作系统Windows XP,使用Java编程语言,Eclipse-SDK-4.2.2 运行平台。
使用iris数据集做实验时,文中算法设置的相关参数如下:人工鱼群规模T=30,类簇个数K=3,人工鱼视野visual=5,拥挤度因子delta=15,移动步长1,最大尝试次数try-number=5,最大迭代次数MaxGen=100,KMeans算法的最大迭代次数为200。
使用glass数据集做实验室,人工鱼群规模T、最大尝试次数 try-number、算法最大迭代次数 MaxGen、K-Means算法的最大迭代次数、拥挤度因子delta的设置同上,其他参数的设置如下:类簇个数K=6,人工鱼视野visual=25。2个实验程序分别独立运行30次。
考虑到把30次的结果全部罗列出来篇幅太长,故选取其中的10次运算结果罗列出来如表1所示。同时还并将K-Means算法和文中算法的聚类性能进行比较,如表2所示。

表1 K-Means和本文算法对iris和glass数据集的10次运算结果

表2 K-Means算法和文中算法的聚类性能比较
从表1可以看出,文中算法能够很好的改善聚类结果,如第1、4、5次仅用K-Means进行聚类,得到的类内间距为152.369、152.369、142.859,而将人工鱼群算法和K-Means算法进行结合后计算的类内间距分别为78.941、78.941、78.941,类内间距分别减小48.2%、48.2%、44.7%。用数据维数较少的 iris数据集进行实验时,K-Means算法计算的结果比较接近最优解,如2、3、6、7、8、9、10次计算的结果与最优解仅仅相差0.004。但是当数据维数增多,数据记录数也增多时,K-Means最优解的误差也相差较大。如对于glass数据集而言,10运行得到的误差从小到大依次为:42.837、44.951、45.23、46.41、52.134、64.229、204.276、224.058、225.291、258.774。从表1中还可以看出,对于同一个数据集,追尾行为、聚群行为、觅食行为、随机行为执行次数变化很小,这为最优解的稳定性奠定基础。
从表2可以看出,不论是对Iris数据集进行测试还是对glass数据集进行测试,文中算法在30次的独立测试中每次都能达到最优解。而K-Means算法没有一次能够收敛到全局最优解。
为了进一步测试文中提出的改进的人工鱼群聚类算法的性能,文中算法和改进的遗传聚类算法[15]、遗传指导算法(GGA)、人工免疫C-均值聚类算法就程序独立运行30次花费的时间(s)、最优值、平均值、平均值和最最优值的标准差Javr进行比较。比较结果如表3所示。其中改进的遗传聚类算法参数设置如下:交叉概率Pc=0.9,变异概率Pm=0.005,种群大小Psize=30。GGA和人工免疫C-均值聚类算法的结果在文献[13]中已给出。
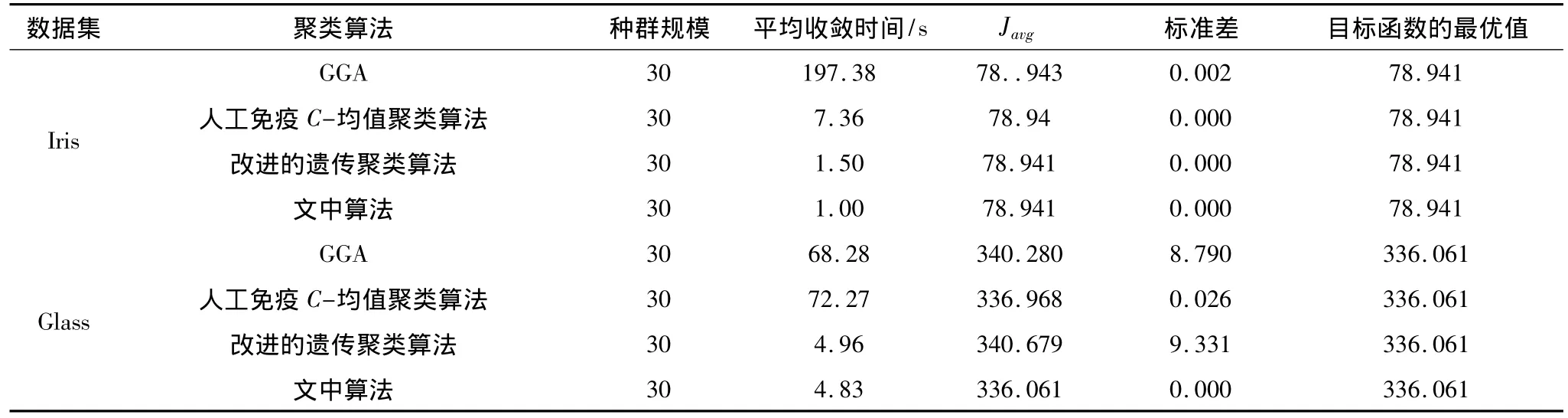
表3 K-Means算法和文中算法的聚类性能比较
表3的结果可以说明,对于iris数据集,改进遗传聚类算法和文中算法都取得了最优解,收敛速度和精度都要由于遗传指导算法和人工免疫C-均值聚类算法。但是文中算法的收敛速度比改进的遗传聚类算法还要快。对于glass数据集,文中算法不仅最优值优于GGA和人工免疫C-均值聚类,而且算法运算时间远远小于二者。虽然改进的遗传算法也达到了最优值,但是并不是程序每次运行都能达到最优值,而文中算法却可以每次都能达到最优解,且运行时间短。
图1和图2是用文中算法对Iris数据集合wine数据集进行聚类时,目标函数值与进化代数之间的关系。从图中可以看出本文算法收敛速度非常快。

图1 iris数据集的函数值随迭代次数变化过程

图2 glass数据集的函数值随迭代次数变化过程
4 结束语
提出的改进的人工鱼群聚类算法,是在聚类数目已知的前提下,对数据样本进行聚类。作为经典划分聚类算法的K-Means虽然具有简单、易实现等优点,但是也存在诸多缺点,如对初始值的选取提交敏感、聚类精度不高等。人工鱼群算法是一种新型的仿生智能优化算法,可以很好的解决K-Means算法遇到的问题,两者结合起来可以做到扬长补短。为了加快聚类的速度并改进聚类的精度,对人工鱼群的视野、移动步长、觅食、聚群、追尾行为进行改进,并与K-Means算法进行融合。实验使用了UCI机器学习数据库中的经典数据集,通过表1-3以及图1-2可以看出文中算法求解结果稳定,聚类效果较好。虽然文中算法聚类性能较高,但是仍然需要做进一步的研究,如确定算法中相关参数对聚类结果的影响,进一步提高聚类的收敛精度和速度等。
[1] 周涛,陆惠玲.数据挖掘中聚类算法研究进展[J].计算机工程与应用,2012,48(12):100-108.
[2] 李秀芳,李志成.基于数据挖掘的聚类算法研究[J].计算技术与自动化,2006,25(3):41-44.
[3] Huang Jianghua,Zhang,Junying.Distributed Dual ClusterAlgorithm Based on Grid for Sensor Streams[J].International Journal of Digital Content Technology and its Applications.2010,4(9).
[4] Yu Yongqian,Zhao Xiangguo,Chen Hengyue,et al.Self-expanded clustering algorithm based on density units with evaluation feedback section[J].Wuhan University Journal of Natural Sciences,2006,11(5).
[5] Xiaoyun Fan,Baoshan Cui,Kejiang Zhang,et al.Water Quality Management Based on Division of Dry and Wet Seasons in Pearl River Delta[J].Clean Soil Air Water,2012,40(4).
[6] 陈旭玲,楼佩煌.改进层次聚类算法在文献分析中的应用[J].数值计算与计算应用,2009,11(4):277-281.
[7] 熊勰,刘光远,温万惠.基于智能算法的生理信号情感识别[J].计算机科学,2011,38(3):266-268.
[8] 吕谋,董深,韩伟,等.基于智能算法的多水源泵站在线优化控制技术[J].系统工程理论与实践,2010,30(1):140-144.
[9] 李晓磊,邵之江,钱积新.一种基于动物自治体的寻优模式:鱼群算法[J].系统工程理论与实践,2002,22(11):32-38.
[10] Wang C R,Zhou C L,Ma J W.An Improved Aritificial Fish-swarm Algorithm and its Application in Feed-forward Neural Networks[J].Proceedings of the Fourth International Conference on Machine Learning and Cybernetics,2005:2890-2894.
[11] 苏锦旗,吴慧欣,薛惠锋.基于人工鱼群算法的聚类挖掘[J].计算机仿真,2009,2(26):147-150.
[12] 丁生荣,马苗,郭敏.人工鱼群算法在自适应图像增强中的应用[J].计算机工程与应用,2012,48(2):185-187.
[13] 张琳,陈燕,汲业,等.一种基于密度的K-means算法研究[J].计算机应用研究,2011,28(11):4071-4085.
[14] 陈光平,王文鹏,黄俊.一种改进初始聚类中心选择的K-means算法[J].小型微型计算机系统,2012,6(6):1320-1322.
[15] 陆林花,王波.一种改进的遗传聚类算法[J].计算机工程与应用,2007,43(21):170-172.
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
铁道通信信号(2019年6期)2019-10-08
中外文摘(2017年19期)2017-10-10
中学生数理化·中考版(2017年12期)2017-04-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
电测与仪表(2016年3期)2016-04-12
电测与仪表(2016年20期)2016-04-11
