
一种基于QoS综合匹配的Web服务选择方法
2013-12-18 07:24:56,,
石家庄铁道大学学报(自然科学版) 2013年4期
, ,
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
1 QoS驱动的Web服务选择方法
随着功能相同而非功能属性(QoS)不同的Web服务的增多,如何从中准确地选出满足用户需求的最优服务是研究领域的一个热点。很多学者开始研究以QoS属性作为选择服务指标的各种方法[1-4],并取得了一定的成果。
最初的服务选择方法是基于QoS属性值计算的,通过构建数学模型计算出每个候选服务的属性值,选择属性值最大的服务作为最佳服务[1],该法缺少语义支持不利于实现服务的自动发现。为解决上述问题,研究者开始将语义中的本体技术应用到服务选择研究中[2],致力于构建QoS本体,设计基于本体的服务选择方法。L Taher et al提出基于QoS相似度的Web服务选择方法[3-4],但它只是考虑了服务QoS 数值方面的匹配,缺乏考虑QoS参数概念的语义相似度。
上述方法的缺点导致用户花费时间和精力却筛选不到更符合自身需求的服务。对语义和数值进行综合考量并考虑服务请求者的个性化需求,提出了一种基于语义和数值综合匹配的Web服务选择方法,包含QoS语义和数值综合匹配、构建多属性决策矩阵、个性化服务选择这几个阶段。
2 QoS语义和数值综合匹配
考虑到QoS参数包括QoS概念和QoS数值两部分,因此QoS的综合相似度是由QoS属性概念的语义相似度和QoS属性的数值相似度共同决定的。首先进行了两个QoS参数的语义匹配,当语义上存在可比性时,才进行下一步的数值处理和数值匹配。
2.1 QoS语义匹配
在QoS本体树中语义相似度可以用来衡量两个概念的相关程度。语义相似度随着语义距离的增大下降速度很快,采用下式为语义相似度的计算公式[5]
S(ci,cj)=1/edis(ci,cj)
(1)
式中,dis(ci,cj)为本体树中概念词ci与概念词cj之间的语义距离;S(ci,cj)为本体树中概念词ci与概念词cj之间的语义相似度。式(1)取值在[0,1]区间内,α为可调节参数。如果ci=cj则dis=0,S(ci,cj)=1; 如果ci≠cj则dis(ci,cj)采用通用余弦相似度度量距离算法[6]计算,如果dis(ci,cj)=∞,S(ci,cj)=0。
在实际选择过程中,很多不相关QoS属性参数作为本体树中的节点存在有限语义距离,导致两者之间语义相似度不为0。如“吞吐率”和“价格”在语义概念上来看是没有任何比较意义的,但是在本体树中,若二者存在语义距离,这导致语义相似度不为0,因此设计一个QoS属性参数之间的相容性参数u来描述两个语义概念是否有比较的必要性。u的取值取决于dis(ci,cj)是否大于由QoS本体的设计者根据实际经验给出的语义距离的临界值L,当两个QoS属性参数之间的语义距离大于L时,u=0;否则,u=1。 因此,语义综合相似度函数SSem(ci,cj)为相容性参数u和语义相似度S(ci,cj)相乘的积,如公式(2)所示。
SSem(ci,cj)=uS(ci,cj)
(2)
式中,S(ci,cj)为两个QoS属性参数之间的相似度,u为两个QoS属性参数之间的相容性参数。引入此公式后,避免了那些没有比较意义的QoS属性比较过程,提高了效率。
2.2 QoS数值匹配
本文支持单值、模糊单值、区间值三种QoS数值表达方式。如,响应时间为单值属性;安全性描述为一个集合{高,中,低}对应的数值描述为{3,2,1},为模糊单值属性;价格区间100元以内,为区间型属性。本文将数值进行统一划归成精确型单值数据来表示。
2.2.1 QoS数据去模糊化
不同QoS属性参数特性不同,成本型QoS属性值越小代表Web服务质量水平越好,例如响应时间、费用等;效益型QoS属性则正好相反,例如吞吐量、可用性等QoS属性参数。去模糊化的过程中要对这两种类型的属性分别处理。
假设有m个具有相同功能的Web服务集合为S={S1,S2,…,Sm}。QoS属性参数集合为Q={Q1,Q2,…,Qn}。其中qij=[qijL,qijR]为Web集合中第i个Web服务的第j个QoS属性的区间值,i=1,2,…,m;j=1,2,…,n。转化后的相应实数值设为qij′。
对于效益型QoS区间属性数据转化为实数。转化公式如下
(3)
对于成本型QoS区间属性数据转化为实数。转化公式
(4)

2.2.2 QoS数据预处理
最终是通过多个属性综合值来评判服务的质量,采用多属性决策理论中的比重变换法对QoS数据进行归一化处理
(5)
式中,qij′表示经过归一化处理后的QoS数据;对于效益型数据qij表示Web服务集合中第i个Web服务中第j个QoS属性参数的取值;对于成本型数据,qij表示Web服务集合中第i个Web服务中第j个QoS属性参数取值的倒数。Q表示效益型和成本型数据集合。
2.2.3 QoS数值匹配
在进行完上述两步处理后,再计算精确型QoS数值相似度比较简单,公式如下
(6)
式中,i∈[1,m],j∈[1,n];DSem(mr,mp)表示QoS数值相似度函数;mr表示服务请求者请求的QoS数值约束;mp表示服务提供者提供的QoS数值约束;rj表示服务请求者所请求的第j个QoS属性参数的取值;qij表示第i个候选Web服务中的第j个QoS属性参数的取值。
3 多属性QoS匹配

矩阵M说明如下:
(1)行表示候选Web服务,列表示每个候选Web服务的一种QoS属性参数。
(2)Mm×n中的元素qij表示服务请求者请求的QoS属性参数与第i个候选Web服务中的第j个QoS属性参数相匹配的综合相似度。
(3)元素qij作为QoS的综合相似度是由概念语义综合相似度和数值相似度共同决定的。QoS综合相似度函数QMatch(mr,mp)为QoS语义综合相似度SSem(mr,mp)与QoS数值相似度DSem(mr,mp)的聚合乘积。当QoS语义可比时,数值匹配才有意义。当QoS语义相似度SSem(mr,mp)不变,QoS数值相似度越大越匹配;当QoS数值相似度DSem(mr,mp)不变,语义相似度越大越匹配。因此QoS综合相似度函数如下所示
QMatch(mr,mp)=SSem(mr,mp)×DSem(mr,mp)
(7)
式中,mr表示服务请求者定义的QoS属性参数;mp表示具有相同功能的候选Web服务集合中提供的QoS属性参数。
考虑服务请求者的个性化需求,采用权重分配法来描述请求者的愿望。将所构建的多属性决策矩阵与服务请求者所设定的权重分配数值进行相乘然后再将计算出的单个QoS属性评价结果相加,得到Web服务综合评价值。如评价公式(8)所示
(8)
式中,Sorce(Si)为综合评价函数,i=1,2,…,m;qij表示服务请求者请求的QoS属性参数与第i个候选Web服务中第j个QoS属性参数相匹配的综合相似度;wj表示服务请求者对所请求的QoS属性参数中第j个QoS属性的关注程度,且满足w1+w2+…+wn=1。第j个QoS属性的权重wj其取值范围在[0,1]区间内,如果值越趋近于1,则表示服务请求者的个性化需求对此项的要求越高。
4 实验仿真与分析
采用Protégé3.4.8构建简单的QoS属性本体树;使用Jena2.6.2对本体树中的层次进行验证,如WatingTime 和ExecutionTime为ResponseTime的两个并列子节点。假设用户请求的Web服务r对于QoS属性参数要求为:费用(Price)为10元、兼容性(Compatibility)为0.12至0.20之间、吞吐率(Throughput)为11.7和响应时间(ResponseTime)为0.8 s。具体候选QoS属性参数如表1所示。
基于QoS综合匹配的语义Web服务选择方法过程中,两个QoS属性参数之间相关性的临界距离L,本文将其设定为1。QoS语义匹配成功后,对相应的QoS数值进行匹配。
若服务请求者对于所请求的Web服务需求的权重分配为:费用(Price)占0.4、兼容性(Compatibility)占0.1、吞吐率(Throughput) 占0.2.和响应时间(ResponseTime)占0.3。根据用户分配权重得出的Web服务评价结果:S1=0.759 93,S2=0.705 45,S3=0.987 90,S4=0.577 75,S5=0.449 44,S6=0.646 85,S7=0.757 47,S8=0.454 05,S9=0.618 33,S10=0.869 55。可见S3为最符合该用户需求的候选服务,S10较符合用户要求。
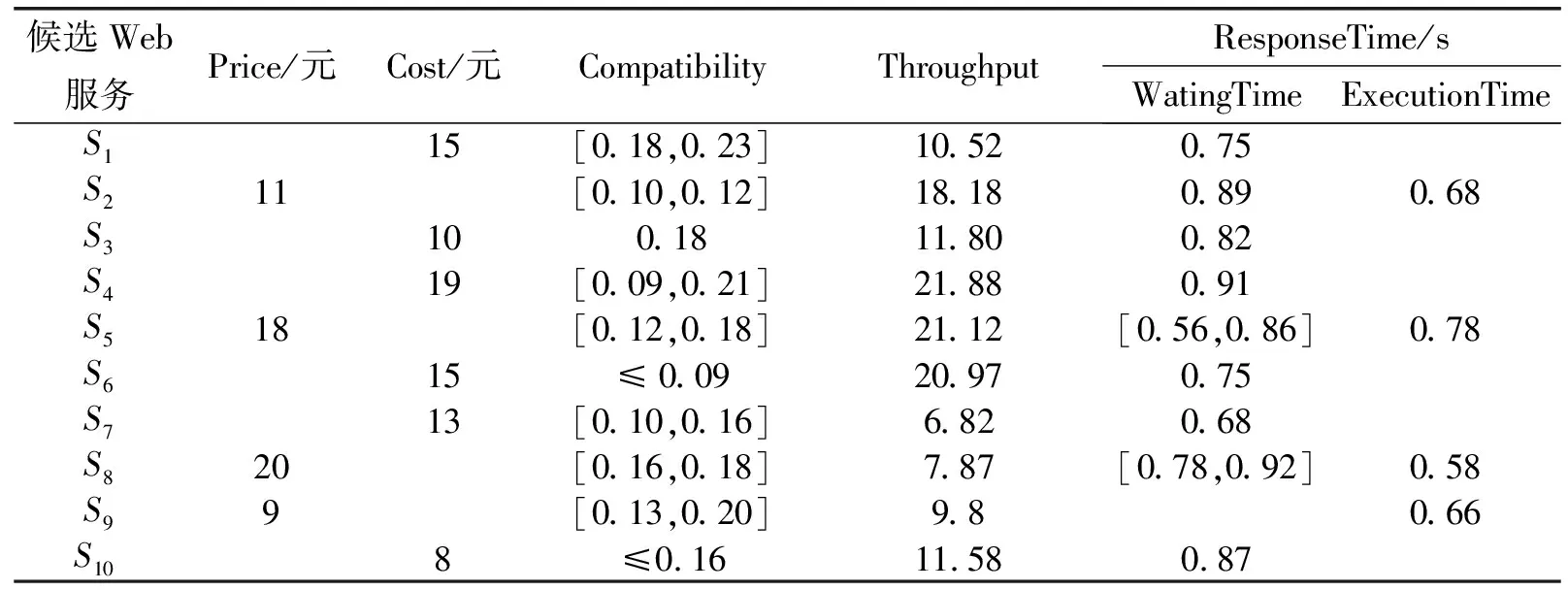
表1 候选Web服务的QoS属性参数值
若用户权重分配依次为:0.1、0.2、0.3、0.4,则得出的评价结果:S1=0.813 28,S2=0.588 25,S3=0.981 62,S4=0.601 53,S5=0.421 00,S6=0.618 70,S7=0.748 18,S8=0.442 31,S9=0.530 62,S10=0.933 18。可见S3为最符合该用户需求的候选服务,S10较符合用户要求。
从以上两次用户权重的分配来看,S3均很好的满足了用户的需求,这表明S3在这四个属性中的匹配度均高于其他的服务。现在人为来考虑单个属性值在QoS数值上的相似程度。费用数值相似程度S3>S2>S9>S10,由于S3=10恰好跟用户需求相同所以匹配度为1;兼容性在数值上没有扩大范围的候选服务有S3、S5、S8、S9,S3恰为单值数据可以看作恰好满足了区间型数据的核;吞吐量数值相似程度S3>S10>其他服务;响应时间需求为0.8 s可以看到S3=0.82 s,完全可以匹配用户需求而且相较于其他服务而言为精确型单值数据。请求者期望所选择的服务中QoS属性的侧重度为费用大于其他三种属性所占比例时,结果明显S3从各个方面来说是最满足服务请求者需求的服务。
根据算法仿真实验,本文提出的方法可以有效的给用户推荐满足且服务质量较高的Web服务。
5 结束语
本文提出了一种多属性QoS综合匹配方法用于解决Web服务选择问题。在语义匹配后给出QoS数值相似度计算方法,采用去模糊化方法将异构QoS数值参数统一转化为单值型QoS数值,解决异构QoS参数值之间的匹配问题。构建多属性决策矩阵解决QoS属性多样化,并考虑了服务请求者个性化需求。本方法侧重于区间型QoS数值,对于参数值得确定人为因素影响也较大,还需要进一步的考虑。
参 考 文 献
[1]王安华,国林,晓娟,等.基于服务质量的Web 服务发现研究与实现[J〗.计算机工程与设计,2007(21):5112-5114.
[2]CHEN ZHOU,LIANG TIEN CHIA,BU SUNG LEE.DAML-QoS ontology for web services[C]//Proceedings of the International Conference on Web Services(ICWS04).San Diego,California:IEEE Computer Society,2004:472-479.
[3]Taher L, Khatib H El .A framework and QoS matchmaking algorithm for dynamic web services selection[C]//Proceedings of the 2 nd International Conference on Innovations in Information Technology (IIT'05).[S.l.]:[s.n.],2005.
[4]MICHAEL MAXIMILIEN E,MUNINDAR P S.Toward autonomic web services trust and selection[C]//Proceedings of the 2nd International Conference on Service Oriented Computing.New York:ACM Press,2004:212-221.
[5]GANJISAFFAR Y,ABOLHASSANI H,NESHATI M.A similarity measure for OWL-S annotated web services[C]//Proceedings of IEEE/WIC/ACM International Conference on Web Intelligence.Hong Kong:IEEE Computer Society,2006:621-624.
[6]Ganesan P,Garcia-Molina H,Widom J. Exploiting hierarchical domain structure to compute similarity[J]. Transaction on Information Systems, 2003.21(1):64-93.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
太原科技大学学报(2021年4期)2021-08-30 07:27:00
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:38:06
中国音乐学(2020年4期)2020-12-25 02:58:06
通信学报(2020年11期)2020-12-10 11:31:20
计算机工程与设计(2020年5期)2020-05-23 10:03:18
山西大学学报(哲学社会科学版)(2018年3期)2018-05-18 09:16:40
电信科学(2016年8期)2016-12-01 07:14:24
山西大同大学学报(自然科学版)(2016年4期)2016-11-27 02:20:52
文学教育(2016年27期)2016-02-28 02:35:15
