
基于词频和文本类别的互信息改进算法
2013-10-26 05:49:02李光耀谭云兰
井冈山大学学报(自然科学版) 2013年3期
谢 力,李光耀,谭云兰,2
基于词频和文本类别的互信息改进算法
*谢 力1,李光耀1,谭云兰1,2
(1.同济大学电子与信息工程学院,上海201804;2. 井冈山大学电子与信息工程学院,江西,吉安 343009)
分析了传统的互信息特征选择算法的不足,针对可能赋予低频特征词过高权重的问题,利用词频、集中度这两个强信息特征指标对算法进行改进,提出了一种基于词频和文本类别的互信息改进算法(Improved Mutual Information Algorithm based on Word Frequency and Text Category,简称改进的MIFC)。实验结果表明,改进的MIFC算法提取的特征空间比传统的互信息算法有更高的精确度。
互信息;特征选择;词频;文本类别;MIFC
0 引言
文本特征选择是指从高维的特征空间中选择出最能代表文本内容的特征项,是文本分类过程中一个至关重要的技术环节。好的特征选择算法不仅能够降低文本特征空间的维数,提高文本分类器分类的效率,还能去除对文本分类无效的特征,提高分类的精度[1]。目前文本分类有很多种特征选择算法,常用的有文档频率法、互信息法、信息增益法、期望交叉熵法和χ2统计法等。在研究互信息特征选择算法方面,国内外很多学者从不同角度提出了改进方案。Battiti在互信息法提取特征空间的基础上,计算特征项两两之间的关联度,对关联度大的特征项组二者取其一[2]。卢新国等提出了一种基于互信息特征选取的改进算法(IMI),加强了互信息为负值的特征项在分类中的作用[3]。刘海峰等从权重因子、修正因子和位置差异三个方面入手,重新调整了特征项的权重,提高了互信息法的特征选择效率[4]。
本文针对互信息算法选择特征后分类精度不高的不足,提出了一种基于词频和文本类别的互信息改进算法。实验结果表明,改进后的算法比原算法有更高的准确性。
1 文本特征选择相关技术
1.1 文本预处理
1.1.1 文本分词
在中文文本预处理过程中,一般可以选择字、词语或词组作为文本的特征项。用单个字作为特征项容易导致特征空间庞大,影响分类效率;用词组作为特征项容易导致特征空间稀少,损失很多重要信息。相比而言,用词语作为特征项比字具有更强的表达能力,而且在切分时要比词组更容易实现。因此,一般选用词语来提取中文文本的特征项,这个操作称为文本分词[5]。
1.1.2 词汇过滤
词汇过滤是指去掉对区分文本类别影响较弱的特征词(又称“弱信息词”),保留对区分文本类别影响较强的特征词(又称“强信息词”)。弱信息词包括介词、连词和助词等虚词,比如:“是”、“的”、“能”、“所”、“在”、“从而”、“并且”等。它们出现频率很高,但对于区分文本类别没有参考价值。强信息词主要包括名词和动词,是具有代表性的关键词汇,可以表达出文本的主题。
一个原始特征空间可能包含数十万个不同特征词,如果不对这些原始特征词进行过滤,不仅会增加特征提取算法的处理时间,而且对算法的精确度也会产生不利的影响。为了对原始特征空间进行降维,就必须去除弱信息词[6]。
1.2 互信息(MI)特征选择算法
互信息(Mutual Information)是根据某个特征词的出现情况来衡量它对某个文本类别的重要程度[7]。因为互信息算法度量了特征词和文本类别之间的关联信息,所以在统计语言模型中被广泛采用。特征词与类别的互信息MI(T,C)定义如下:
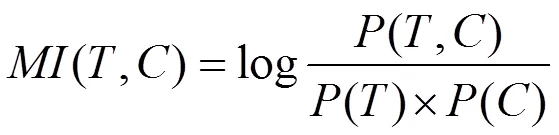
其中,(,)表示包含且属于的文本在训练文本集中出现的概率,()为包含的文本出现的概率,()为属于类文本的概率。如果用表示包含特征词T且属于类别的文本频数,为包含但是不属于的文本频数,表示不包含但是属于的文本频数,表示训练文本集中的文本总数,那么特征词和类别的互信息可由下式计算:

1.3 K近邻(KNN)文本分类算法
K近邻法(K Nearest Neighbor)是一种基于实例的机器学习方法,相关研究证明该算法是向量空间模型下最好的分类算法之一。KNN的分类过程可以理解成:先将训练文本集中的所有文本表示成向量空间。当一个待分类文本到达时,计算该文本与向量空间中每个文本的相似度,并将相似度值按降序排列,取出排在最前面的K篇文本。最后按这K篇文本的类别权重对待分类文本进行归类[8]。
在计算相似度时,将同类别的相似度相加求和,然后对计算结果进行排序,将待分类文本归到相似度和最大的那个类中。计算公式如下:
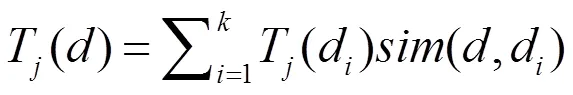
其中,表示选取的文本数,j(d)表示文本是否属于类(是为1,否为0),sim(,d)可以由向量夹角余弦(公式2.4)求得。其中,1i,2i分别表示文本1,2的特征空间中相应特征项的权重。两个向量夹角的余弦值越大,相似度越高。

2 互信息特征选择算法的改进
2.1 互信息算法的局限性
互信息算法主要研究的是含有特征词的文本出现在类别内的概率以及整个训练文本集里和出现的概率,并没有考虑的词频因素。这样,低频特征词的作用可能会被放大,导致对分类没有明显效果的词语获得了更高的互信息值而成为特征项,影响特征空间对文本的表示能力。
2.2 强信息特征标准
强信息特征是具有很强的文本分类能力和表述能力的词语,一般受以下三个指标影响[9]:
(1)频数:某个特征词在某类文本中出现次数越多,就越能代表这类文本。因此,应该选择在同类文本中出现频数最高的若干词语作为该类文本的特征项。
(2)分散度:对于某个类别有标引价值的特征,应该均匀地分布在该类别的各个文本中,而不是集中出现在某几个文本中。分散度表示某个特征词与某个类别之间的关联程度,可以通过互信息法公式(1.1)或(1.2)计算。若在类文本中分布地越分散,则(,)越高,对的分类价值越高。
(3)集中度:对于某个类别有标引价值的特征,应该集中出现在这个类文本中,而不是均匀地分布在各个类别的文本中。集中度表示特征项与所有类别之间的关联程度。与类别之间的关系会有以下三种情况:
①只出现在一个类别的文本中,则对这个类别的区分很有价值。
②出现在两个或多个类别的文本中,则对没有其出现的类别很有分类价值。
③出现在所有类别中,则对分类几乎没有价值。
从强信息特征的三个指标可以看出,对于某个特征词,其频数、分散度、集中度越大,则它对文本分类能力就越强。
2.3 基于词频和文本类别的互信息改进算法
根据强信息特征的特点,本文综合考虑了词频和集中度两个指标,提出了基于词频和文本类别的互信息改进算法MIFC,公式如下:
(T,C)(() ×R)/100 (2.1)
其中,表示出现在类文本中出现的频数, R表示的类别相关系数,表达式如(3.2)所示。为训练文本集中的类别总数, C为包含的文本所属类别的个数。

MIFC算法相较于MI算法,主要有两点改进:
(1)引入频数指标。统计在中出现的次数。若出现的次数越多,就越大,对的分类价值越大。
(2)引入集中度指标。根据集中度指标中特征项与类别之间的关系可知,若出现在测试文本集中的类别个数越少,则集中度越大,分类能力越强,应该给予更大的类别相关系数。同时,的类别相关系数与其出现的类别个数之间是一个非线性的关系,随着出现的类别个数增多,其类别相关系数减小地越快(如图1所示)。
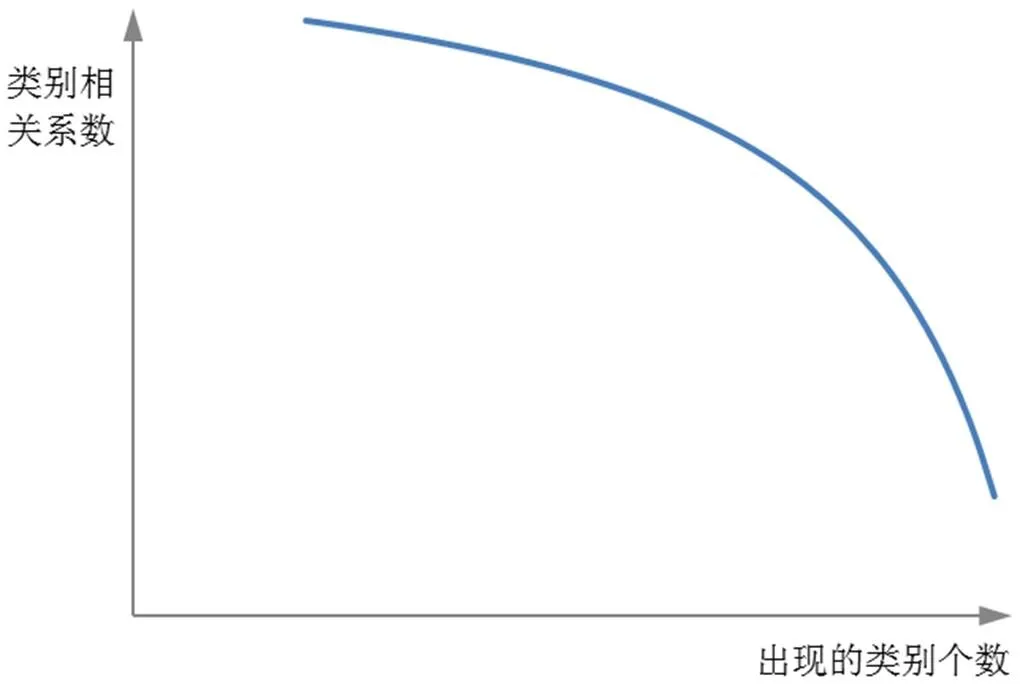
图1 类别相关系数与类别个数的关系图
3 实验设计及结果
3.1 实验设计
本实验的设计思路:首先对训练文本进行预处理并建立特征空间,其中技术环节包括文本分词和词汇过滤。然后,利用MI或者MIFC算法计算各个特征项的权重,从高到低排序,取前面N个形成特征空间。接着,基于特征空间和KNN算法实现分类器。最后,将预处理过后的测试文本导入分类器分类,得到实验结果。实验的流程如图2所示。
本实验的训练文本、测试文本均采用复旦大学提供的语料库,从计算机、环境、经济、体育和政治5个类别中分别选取100篇文本,总共500篇,构成实验的训练文本集。此外,再从这5个类别中分别挑选另外的100篇文本,总共500篇,构成实验的测试文本集。
本实验的分词系统采用中科院的ICTCLAS 4j系统[10]。ICTCLAS系统功能强大,不仅有较高的分词准确性,还能对词汇进行词性标注,方便用户进行词性统计。在ICTCLAS系统的基础上,可以通过程序实现特征选择。
本实验分别使用MI和MIFC两种特征选择算法提取100维的特征空间,并通过KNN算法实现分类器,比较两个特征空间的分类能力。通过不断调试参数,发现K=40时,分类的准确率最高。
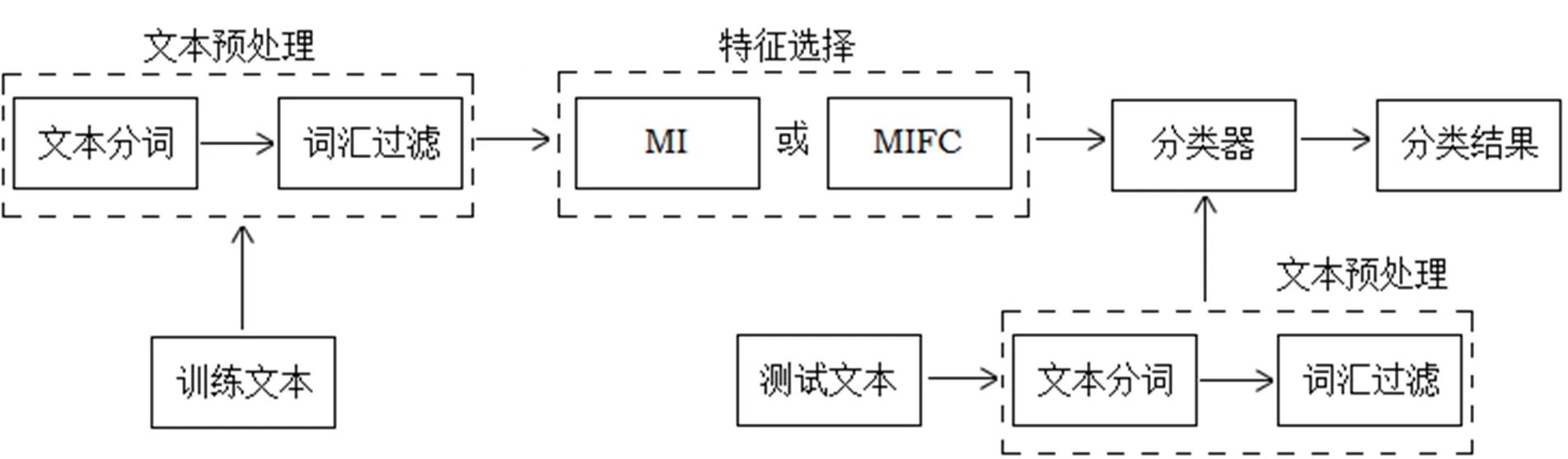
图2 实验流程图
3.2 实验结果及分析
利用MI与MIFC提取的两个不同的特征空间,分别对测试文本集中的500篇文本进行分类,并与文本原来所属的类别进行比较,统计两种算法下各个类别分类的准确率。统计结果如图3所示。
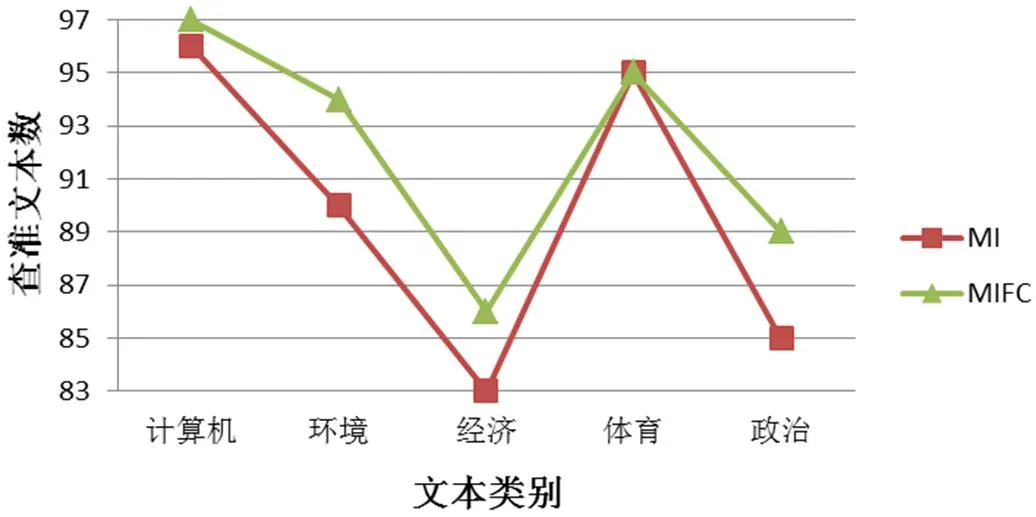
图3 当K=40时,MI与MIFC分类的准确率比较
对于计算机、环境、经济、体育、政治5个类别,每个类别各100篇文本的测试集,使用MIFC算法查准的文本数分别为97、94、86、95、89篇,使用MI算法查准的文本数分别为96、90、83、95、85篇。
从实验结果可以看出,除了体育类文本(两者准确率相同),MIFC算法的分类准确率都要高于MI算法。因此,以MIFC作为特征选择算法得到的分类结果较MI算法具有更高的准确性,同时也验证了使用MIFC算法提取的特征空间比MI算法提取的特征空间具有更强的文本分类能力。
4 结论
本文重点研究了在中文文本分类中的互信息特征选择算法,针对互信息算法可能赋予低频特征词过高权重的问题,引入了特征词频数和文本类别权重对互信息算法做了进一步的改进。实验结果表明,改进的MIFC算法确实提高了特征选择的精确度和文本分类的准确率。
[1] 范小丽, 刘晓霞. 文本分类中互信息特征选择方法的研究[J]. 计算机工程与应用, 2010, 46(34): 123-125.
[2] Battiti R. Using Mutual Information for Selecting Features in Supervised Neural Net Learning[J]. IEEE Transactions on Neural Networks, 1994, 5(4): 537-550.
[3] 卢新国, 林亚平, 陈治平. 一种改进的互信息特征选取预处理算法[J]. 湖南大学学报: 自然科学版, 2005, 32(1): 104-107.
[4] 刘海峰, 陈琦, 张以皓. 一种基于互信息的改进文本特征选择[J]. 计算机工程与应用, 2012, 48(25): 1-4.
[5] 刘依璐. 基于机器学习的中文文本分类方法研究[D].西安: 西安电子科技大学, 2009.
[6] 李英. 基于词性选择的文本预处理方法研究[J]. 情报科学, 2009, 27(5): 717- 719.
[7] Estévez P A., Tesmer M, Perez C A. Normalized Mutual Information Feature Selection[J]. IEEE Transactions on Neural Networks, 2009, 20(2): 189-200.
[8] 刘慧. 基于KNN的中文文本分类算法研究[D].成都: 西南交通大学, 2010.
[9] 陈平, 刘晓霞, 李亚军. 文本分类中改进型互信息特征选择的研究[J]. 微电子学与计算机, 2008, 25(6): 194-196.
[10] 刘群, 张华平, 俞鸿魁, 等. 基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8): 1421-1428.
An Improved Mutual Information Algorithm based on Word Frequency and text Category
*XIE Li,LI Guang-yao,TAN Yun-lan
(1.School of Electronics and Information, Tongji University, Shanghai 201804, China)(2.School of Electronics and Information Engineering, Jinggangshan University, Ji’an, Jiangxi 343009, China)
This paper analyzes the shortages of Mutual Information (MI) algorithm. Aiming at the problem that low frequency features may have higher weights, we take advantage of two indexes of strong informational features–word frequency and concentration ratio and propose an improved MI algorithm based on word frequency and text category (MIFC). The result of the experiment shows that MIFC algorithm has greater accuracy than traditional MI algorithm.
mutual information; feature selection; word frequency; text category; MIFC
TP391
A
10.3969/j.issn.1674-8085.2013.03.010
1674-8085(2013)03-0041-04
2013-03-17;
2013-03-24
上海市科委国际合作基金项目(10510712500)
*谢 力(1989-),男,浙江台州人,硕士生,主要从事数据挖掘、虚拟现实研究 (E-mail: Robert3443@126.com);
李光耀(1965-),男,安徽安庆人,教授,博导,主要从事大规模城市建模与仿真、数据挖掘研究(E-mail:lgy@tongji.edu.cn);
谭云兰(1972-),女,江西新干人,副教授,同济大学博士生,主要从事图像处理,数据挖掘研究(E-mail: tanyunlan@163.com).
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
读者·校园版(2015年7期)2015-05-14 13:11:40
中文信息学报(2015年4期)2015-04-21 08:29:12
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
