
Toeplitz含噪语音端点鲁棒检测
2013-08-30 10:00:18王景芳宁矿凤
计算机工程与应用 2013年18期
王景芳,宁矿凤
WANG Jingfang1,NING Kuangfeng2
1.湖南涉外经济学院 电气工程系,长沙 410205
2.湖南涉外经济学院 计算机科学系,长沙 410205
1.Electric Engineering Department,Hunan International Economics University,Changsha 410205,China
2.Computer Science Department,Hunan International Economics University,Changsha 410205,China
1 引言
语音作为语言的声学表现,是听觉器官对外界声音传播介质机械振动的感知,是人类信息传递和情感交流的重要载体。目前,语音处理技术要求语音输入在安静的环境下进行,当周围环境有噪声(如工厂、机场等)时,系统性能会急剧下降。然而,语音通信过程不可避免地受到来自周围环境、传播介质等噪声的影响。语音端点检测是数字语音处理的重要环节[1-5],其目的是从采样得到的数字信号中检测出语音信号段和噪声信号段。将采集的语音信号分为纯噪声段和带噪语音段,判断各语音片段的起止点,是语音增强算法和语音编码的重要组成部分之一。在语音识别过程中,正确确定语音段的起止端点,可减少计算量和语音识别误判率。
短时能量是语音端点检测算法中最常用的特征[6],它在高信噪比环境中可以有效地分出语音和噪声,但是大量的实验结果显示,基于短时能量的方法在低信噪比和非平稳噪声环境中,其性能明显下降。当然,部分算法在低信噪比环境中可以保持稳定的性能[7]。其缺点是计算复杂度太大,不适合实时语音识别系统的应用。Shen[8]最早提出将信息熵用于语音/噪声分类,人的发音和噪声的差异可以从它们的频谱熵表现出来。基于语音频谱熵的算法在低信噪比环境下胜过基于能量的方法。在白噪声效果较好,但在有色噪声还是难以奏效。
在语音增强方面利用过信号子空间[9-12];本文针对在低信噪比、非平稳噪声条件下难以实现语音端点检测,提出了一种基于Toeplitz最大特征值的去噪语音端点检测方法。该方法用相语带频谱自相关序列构造一个对称Toeplitz矩阵,利用该矩阵最大特征值的信息量对语音信号进行双门限端点检测。该算法大大提高了算法的检测精度与有效性,能在多种噪声环境和低信噪比条件中都能保持较好的检测性能。
2 构造Toeplitz信息矩阵
语音信号从整体来看其特性及表征其本质特征的参数均是随时间而变化的,是一个典型的非平稳过程,但在一个短时间段内(10~30 ms),其特性相对保持稳定,因而可以看做是一个准平稳过程,即语音信号的短时平稳性。目前绝大多数的语音信号处理技术均是在“短时”的基础上,将语音信号分为许多段来逐段分析其特征参数,其中每一段称为一“帧”,分段的过程称为“分帧”处理,通过对语音信号加窗函数来实现,帧长一般取10~30 ms。分帧可以连续分段,但一般是通过一个滑动窗口进行交叠式分段,这样使帧与帧之间平滑过渡,保持了信号的连续性。在窗函数的选取上,为了能够得到高的频率分辨率并克服Gibbs现象,选取汉宁(Hanning)窗交叠式分段。
对带噪语音信号x(n)进行分帧,帧长FrameLen,帧移StepLen(StepLen<FrameLen),总帧数Num,若第k帧的信号经过快速傅里叶变换(FFT)得到它在谱上的NFFT个点YF(i,k)(0≤i≤NFFT),因语音频谱范围(200 Hz~4 kHz),找其对应的点区间 [Nd,Ng]点 (0≤Nd<Ng≤NFFT),记 L=Ng-Nd+1,LM=L/2为Toeplitz矩阵大小;Xk(i)=YF(i+Ng-1,k)(1≤i≤L)。
第k帧语带频谱自相关序列R(m):
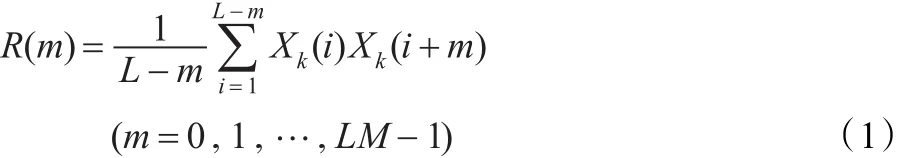
构造LM维实对称Toeplitz矩阵A:
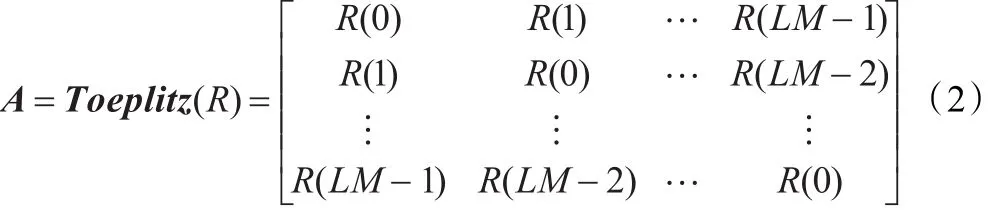
这样Toeplitz矩阵阶数不高,求特征值速度快。
3 语音端点检测实现过程
3.1 求最大特征值迭代法原理分析
幂法是求方阵的最大特征值及对应特征向量的一种迭代法。设 An有n个线性相关的特征向量v1,v2,…,vn,对应的特征值 λ1,λ2,…,λn,满足:

3.1.1 基本思想
因为{v1,v2,…,vn}为 Cn的一组基,所以任给 x(0)≠0 ,
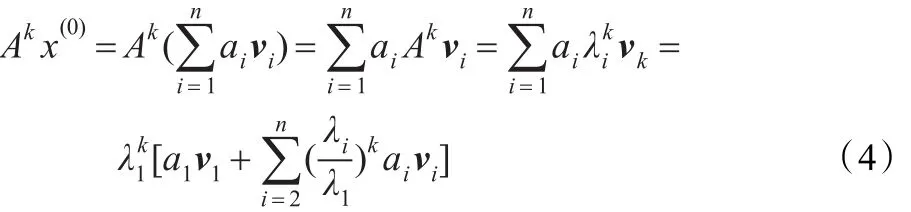
若 a1≠0,则知,当 k充分大时 A(k)x(0)≈λk1a1v1=c v1属λ1的特征向量。
另一方面,记max(x)=xi,其中|xi|=||x||∞,则当 k充分大时:
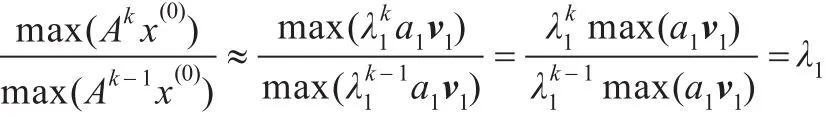
若a1=0,则因舍入误差的影响,会有某次迭代向量在v1方向上的分量不为0,迭代下去可求得λ1及对应特征向量的近似值。
3.1.2 规范化
在 实 际 计 算 中 ,若 |λ1|> 1 则 |λk1a1|→ ∞ ,若 |λ1|< 1 则

注:若A的特征值不满足条件式(3),幂法收敛性的分析较复杂,但若 λ1=λ2= … =λr且 |λ1|>|λr+1|≥ … ≥|λn|则定理结论仍成立。此时不同初始向量的迭代向量序列一般趋向于l1的不同特征向量。
3.2 Toeplitz矩阵A最大特征值求解算法
求解一个最大特征值,在这里用幂法,这样避免求特征值中出现矩阵分解或求逆矩阵计算。其实现步骤:
(1)赋初值:LM维列向量 y=[1,1,…,1]H,H为转置;LM维列向量 y0=[0,0,…,0]H;循环判决条件eps=0.000 1(一个较小数),d=1。
(2)矩阵计算:z=A y。
(3)归一化:

其中 ||z||∞=max{|z(i)|,i=1,2,…,LM}。
(4)计算:d=max{|y(i)-y0(i)|,i=1,2,…,LM},保留上一次的 y,y0=y。
(5)循环判决:如果 d>eps转第(2)步,否则转第(6)步。
(6)计算最大特征值:
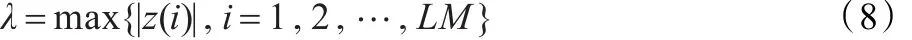
(7)保留第k帧最大特征值信息量:

3.3 双门限语音端点判别
为了防止各帧最大特征值信息量Tzv出现锯齿形波动,将Tzv相邻3帧平均滤波。双门限语音端点判别:
步骤1认定初始的N0帧为噪声帧,对Tzv(l)(0<l≤N0)求均值Avg与标准方差Std。定义双门限语音帧阈值TS和噪声帧阈值TN分别为:

步骤2计算下一帧语音信号最大特征值信息量Tzv(l)。当前一帧为噪声帧,则和阈值TS比较,小于TS则判定为噪声帧,大于TS则为语音帧。当前一帧为语音帧,则和阈值TN比较,小于TN则为噪声帧,大于TN则为语音帧。循环步骤2至信号采样结束。
α、β 可选取在(0,4)之间,不同噪声选取不同值;语音段至少有一定的延续段,比如持续0.2 s;若检测到语音段小于它,则称为“语音碎片”(在非高斯噪声[如:工厂噪声(factory)、嘈杂噪声(babble)]下常见),最后对孤立“语音碎片”剔除或对相邻“语音碎片”整合。
4 实验评估
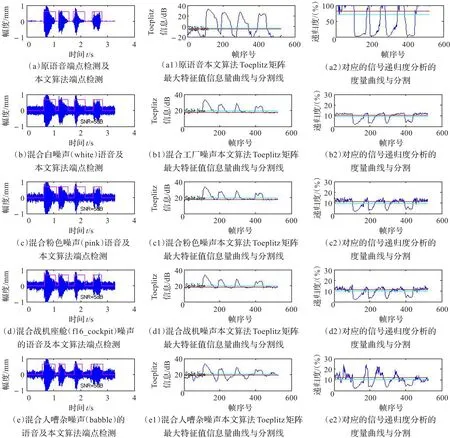
图1 原语音与混合不同噪声(SNR=5 dB)的端点检测对比
背景噪声选自Noisex-92数据库[13],它的采样频率 fs=19.98 kHz。以同样的采样频率 fs,在计算机噪声与室内噪音环境录下“语、音、端、点”音见图1(a),门框折线为本文方法端点检测结果。在语音分帧过程中,每帧取25 ms,即帧长 FrameLen=[0.025 fs]点,帧移[FrameLan/4],确定每帧的快速傅里叶变换(FFT)长度取它等于帧长FrameLen,截取开始噪声帧N0=20。
将原语音、原语音与噪声Noisex-92库中的噪声——白噪声(white)、粉色噪声(pink)、战机噪声(f16_cockpit)、人嘈杂噪声(babble)用本文Toeplitz矩阵最大特征值法进行端点检测,在信噪比SNR=5 dB、0 dB、-5 dB时,用本文算法与信号递归度分析法[14]对比检测结果分别列图1~3。图中左部的横坐标为时间(s)、纵坐标为幅度;中部的横坐标为帧数、纵坐标为Toeplitz矩阵最大特征值信息量(dB);右部的横坐标为帧数、纵坐标为递归度(%)。图1~3的左部为语音、混有不同噪声的语音及它们的端点检测,图中部为本文算法的Toeplitz矩阵最大特征值信息量与端点分割线;本文算法在多种噪声混合情况下,Toeplitz矩阵最大特征值信息量曲线变化不大,语音端点分割准确,自适应性好。
在混有噪声的低信噪比情形下测试,测试结果由3个指标衡量[15]:
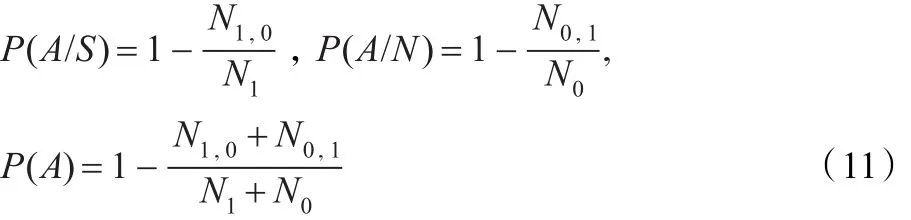
其中,N1和N0分别为测试语音中手工标记语音帧和噪声帧总个数,N1,0为手工标记语音帧而识别为噪声帧的错误个数,N0,1为手工标记噪声帧而识别为语音帧的错误个数。则P(A/S)为语音帧检测正确率,P(A/N)为非语音帧检测正确率,P(A)为总的检测正确率。
表1给出不同噪声不同信噪比环境下的两种方法实验结果的简表。
5 结束语
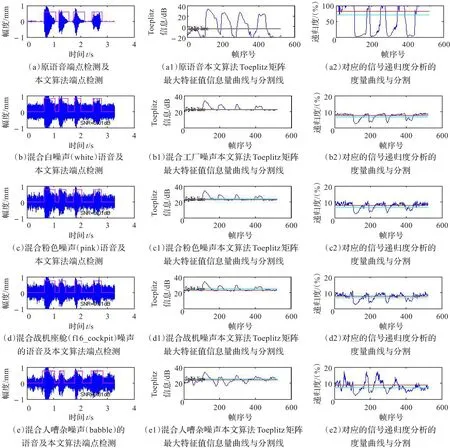
图2 原语音与混合不同噪声(SNR=0 dB)的端点检测对比
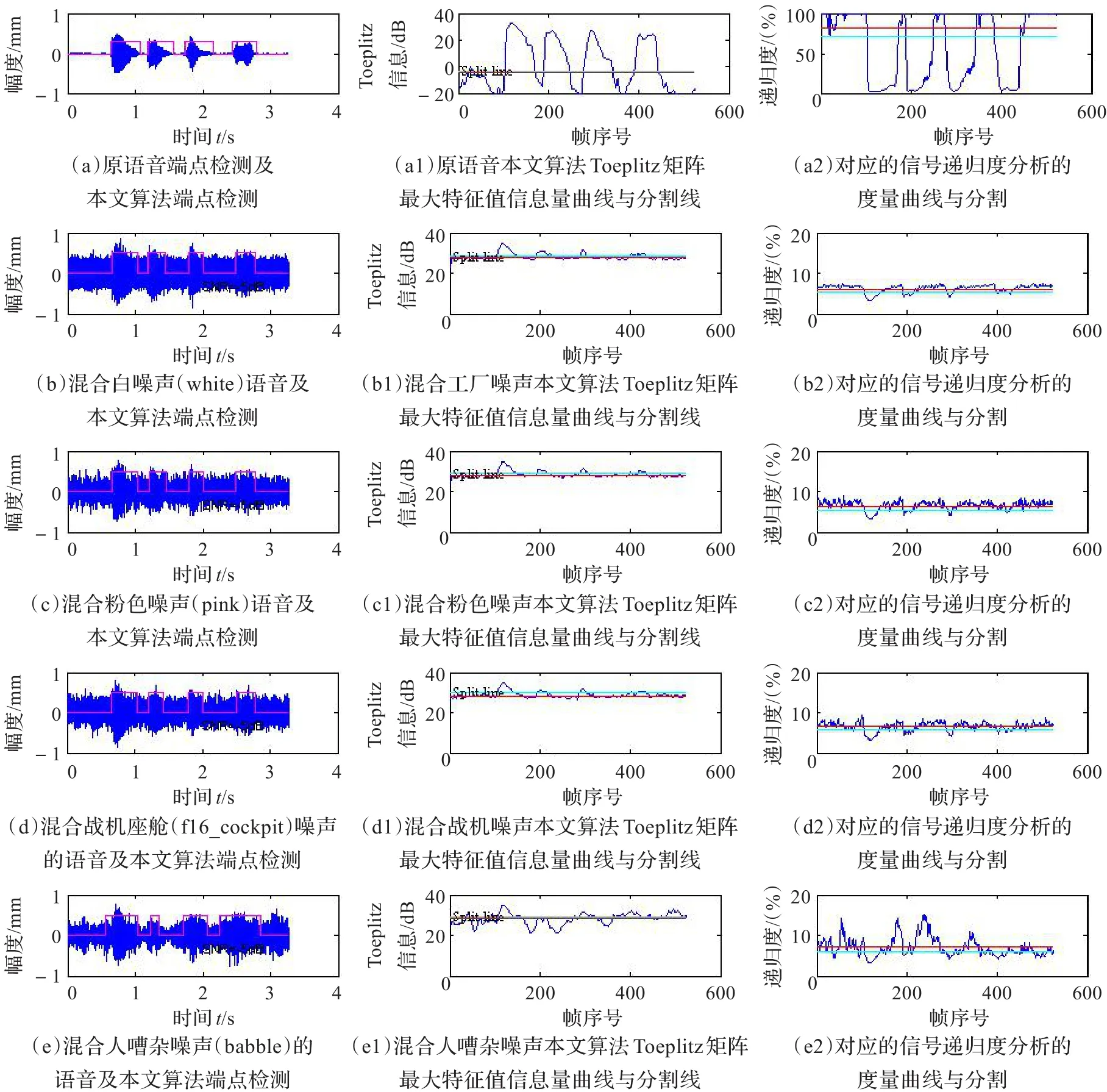
图3 原语音与混合不同噪声(SNR=-5 dB)的端点检测对比
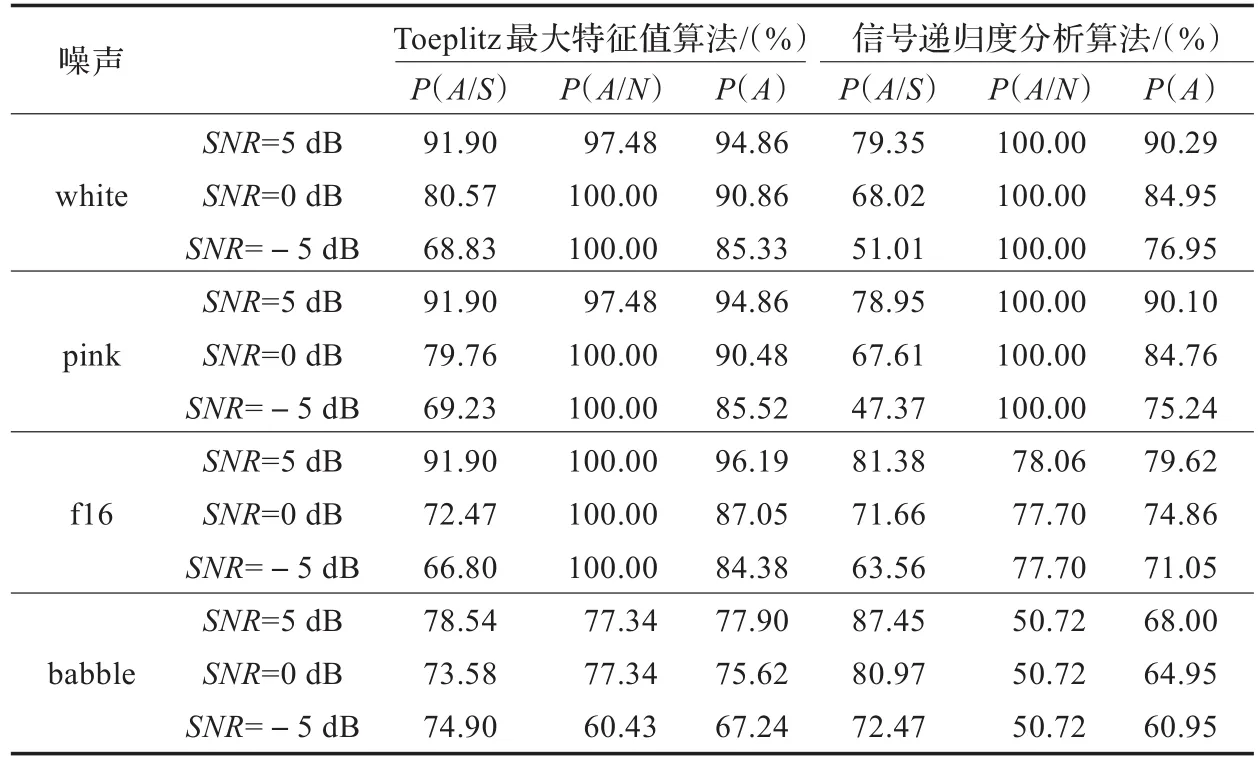
表1 语音端点检测实验结果
文中从新视觉角度提出了一种基于Toeplitz最大特征值的含噪语音端点鲁棒检测的新方法,本方法用语带频谱范围(200 Hz~4 kHz)自相关序列构造一个对称Toeplitz矩阵,利用该矩阵最大特征值的信息量对语音信号进行双门限端点检测。用最大特征值抽提主体信号,更好地抑制了噪声。在信噪比低于5 dB时,一般的语音端点检测方法,如短时谱估计,显得几乎无能为力;该算法仍实用,它具有计算简单,抗噪声能力强的特点,并通过实验表明该方法的正确性,还具有很好的鲁棒性;本文算法通用性好,适应环境宽。特别是噪声混叠在低、高频段的含噪语音检测甚佳,噪声混叠在语音带频段的情形值得进一步改进。
[1]Raj B,Singh R.Classifier-based non-linear projection for adaptive endpointing of continuous speech[J].Computer Speech and Language,2003,17:5-26.
[2]Tanyer S G,Ozer H.Voice activity detection in nonstationary noise[J].IEEE Transactions on Speech and Audio Processing,2000,8(4):478-482.
[3]Karray L,Martin A.Towards improving speech detection robustness for speech recognition in adverse conditions[J].Speech Communication,2003,40:261-276.
[4]Kuroiwa S,Naito M,Yamamoto S,et al.Robust speech detection method for telephone speech recognition system[J].Speech Communication,1999,27:135-148.
[5]Ramirez J,Segura J C,Benitez C,et al.Efficient voice activity detection algorithms using long-term speech information[J].Speech Communication,2004,42:271-287.
[6]Ramirze J,Segura J C,Benitez C,et al.An efective subband OSF-based VAD with noise reduction for robust speech recognition[J].IEEE Transactions on Speech and Audio Processing,2005,13(6):1119-1129.
[7]Nemer E,Goubran R,Mahmoud S.Robust voice activity detection using higher-order statistics in the LPC residual domain[J].IEEE Transactions on Speech and Audio Processing,2001,9(3):217-231.
[8]Shen J,Hung J,Lee L.Robust entropy-based endpoint detection for speech recognition in noisy environments[C]//Proc of International Conference on Spoken Language Processing,Sydney,Australia,1998:232-238.
[9]Ephraim Y,van Trees H L.A signal subspace approach for speech enhancement[J].IEEE Trans on Speech Audio Processing,1995,3(4):251-266.
[10]Klein M,Kabal P.Signal subspace speech enhancement with perceptual post filtering[C]//IEEE-ICASSP’02,Orlando,Florida,USA,2002:537-540.
[11]Mittal U,Phamdo N.Signal/noise KLT based approach for enhancing speech degraded by colored noise[J].IEEE Trans on Speech Audio Processing,2000,8:159-167.
[12]Yi H,Loizou P C.A generalized subspace approach for enhancing speech corrupted by colored noise[J].IEEE Trans on Speech and Audio Processing,2003,11(4).
[13]Spib noise data[EB/OL].[2011-10-20].http://spib.rice.edu/spib/select_noise.html.
[14]闫润强,朱贻盛.基于信号递归度分析的语音端点检测方法[J].通信学报,2007(1):35-39.
[15]Marzinzik M,Kollmeier B.Speech pause detection for noise spectrum estimation by tracking power envelope dynamics[J].IEEE Trans on Speech and Audio Processing,2002,10:109-118.
[16]李晋,王景芳,高金定.基于经验模态分解和递归图的语音端点检测算法[J].计算机工程与应用,2010,46(34):132-135.
[17]王景芳.实时语音端点鲁棒检测[J].计算机工程与应用,2011,47(20):147-149.
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:34
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
中学生数理化·教与学(2019年8期)2019-09-18 15:08:40
西南交通大学学报(2018年5期)2018-11-08 10:59:16
数学物理学报(2017年1期)2017-06-05 09:12:28
新闻传播(2016年11期)2016-07-10 12:04:01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:52
东北电力大学学报(2015年1期)2015-11-13 05:20:25
计算机工程(2015年4期)2015-07-05 08:29:20
