
可见/近红外光谱结合变量选择方法检测牛肉挥发性盐基氮
2013-08-22 02:04马世榜彭彦昆汤修映田潇瑜
江苏大学学报(自然科学版) 2013年1期
马世榜,彭彦昆,徐 杨,汤修映,田潇瑜
(1.中国农业大学工学院,北京 100083;2.南阳理工学院,河南 南阳 473004)
牛肉是营养价值较高的肉品,需求量越来越大,其新鲜度等品质安全也越来越受消费者重视.挥发性盐基氮(TVB-N)与肉品的新鲜度有很好的对应关系,是国家标准中评价肉品新鲜度的重要指标之一,其值越低,肉品越新鲜.目前,GB/T5009.44—2003中测定肉品挥发性盐基氮的方法主要是半微量定氮法或微量扩散法,检测过程繁琐,效率低、人为影响因素大,检测结果缺乏客观性和一致性,且需要对样品进行破坏处理,不能满足当今肉检过程的快速、无损、自动化的要求.
可见/近红外光谱(visible and near infrared spectroscopy,VIS/NIR)分析技术因具有分析速度快、样品无需预处理、非破坏性、操作简便、测试重现性好、便于实现在线分析等特点,已经广泛应用于农作物[1-2]和肉品品质检测[3-4]的研究.侯瑞峰等[5]初步研究了用近红外漫反射光谱定性区分和定量检测猪肉的新鲜度的可行性;Cai Jianrong等[6]用近红外光谱采用联合区间偏最小二乘方法选择光谱变量建模,预测猪肉TVB-N值,预测相关系数为0.8084.但近红外光谱全波长范围内的光谱信息重叠严重,信息量庞大,影响建模速度、效率和模型预测能力.Liu Fei和Xu Huirong等[7-8]采用变量选择方法提高了光谱预测葡萄汁、梨农产品成分含量的模型精度.用可见近红外光谱结合变量选择方法检测牛肉整个4℃储存期内TVB-N含量,提高建模速度和精度还少有相关报道.本研究拟搭建可见/近红外光谱检测系统平台,结合无信息变量消除(uninformative variable elimination,UVE)算法和连续投影(successive projections algorithm,SPA)算法2种变量选择方法,建立生牛肉整个储存期内TVB-N的最小二乘支持向量机(LS-SVM)光谱预测模型,为进一步开发实用检测设备提供参考.
1 材料与方法
1.1 试验材料
取不同产地和不同品种的2批次牛肉样品.第1批样品取自北京市某大型超市刚上市的内蒙古小黄牛统脊部位34块,尺寸约为8.0 cm×5.0 cm×2.5 cm,用保鲜袋包装放置于4~6℃低温保鲜箱,运至中国农业大学工学院农畜产品无损检测实验室,无挤压地保存在4℃冰箱中,模拟市场上待售生鲜牛肉的放置环境.试验周期为17 d,每隔12 h检测一块样品.第2批样品取自北京市御香苑畜牧有限公司宰后经48 h解僵、排酸后的东北改良牛的统脊部位56块,尺寸也约为8 cm×5 cm×2.5 cm,采取与第1批同样运输保存方式和试验周期,前6 d每隔12 h检测一块样品,后11 d每隔12 h检测2块样品.2次试验时样品均是随机从冰箱中取出,共获得90个样本试验数据.
试验用搭建的可见/近红外光谱检测系统(见图1)采集样品光谱信息.系统主要由封闭舱1、载物台2、光源3、光谱仪4、计算机5等组成.光谱仪波长测量范围是200~1750 nm,最小采样间隔为0.5 nm.封闭舱的作用主要是屏蔽外界光线对检测结果的影响.此外还包括KDY-9820凯氏定氮仪、肉搅拌机、电子天平等试验仪器.
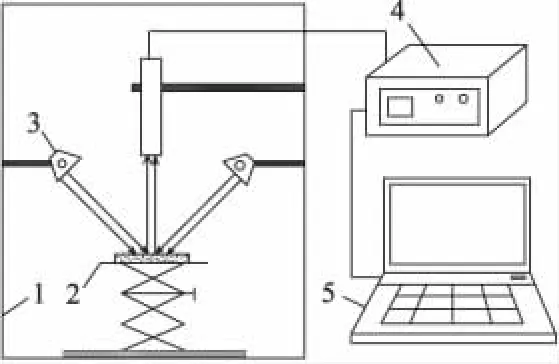
图1 可见/近红外光谱检测系统构架
1.2 试验方法
用上述系统采集样品400~1700 nm波长范围的光谱反射强度信息.样品采集光谱前,把样品从冰箱中取出,去除保鲜袋,在空气中暴露20 min,使样品表面水分自然挥发;调节载物台高度使样品表面距离光纤探头高度为12 cm,每个样品采集6个不同点的光谱信息,把6个点的光谱数据平均值作为该样品的最终光谱反射强度值.
挥发性盐基氮测量按照GB/T5009.44—2003中的半微量定氮法,用KDY-9820凯氏定氮仪测量.每次测量前,做3个样品空白试验,取平均值作为样品空白试验值,每个样品做3个样液试验,取平均值作为该样品样液测量值.样品绞碎时去除脂肪、筋腱等组织.
样本选择及样本集划分.利用主成分分析(principal component analysis,PCA)和统计分析,剔除2个异常光谱曲线样本和3个异常理化值样本后剩余有效样本85个,其原始可见/近红外反射光谱如图2所示.按3∶1的原则用SPXY算法[9]把85个样本划分为校正集和验证集,63个样本作为校正集建立预测模型,22个样本作为验证集验证模型的精度和稳定性,其统计分布结果如表1所示.
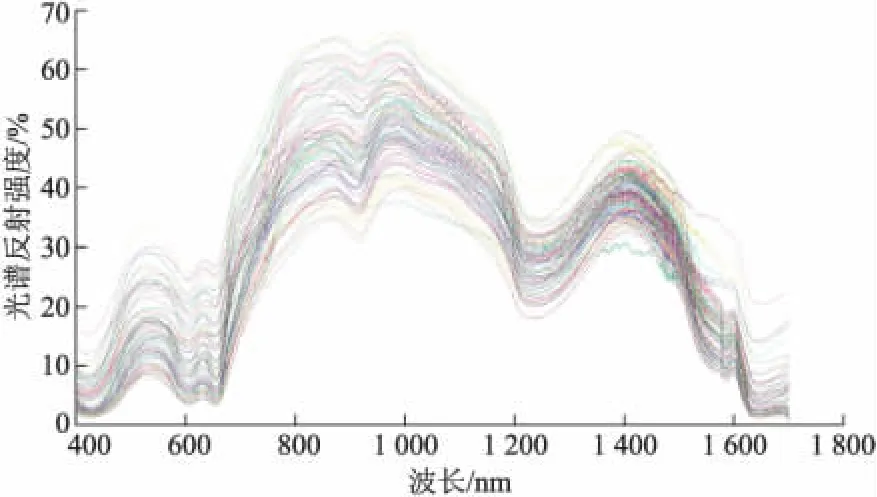
图2 样品的可见/近红外反射原始光谱
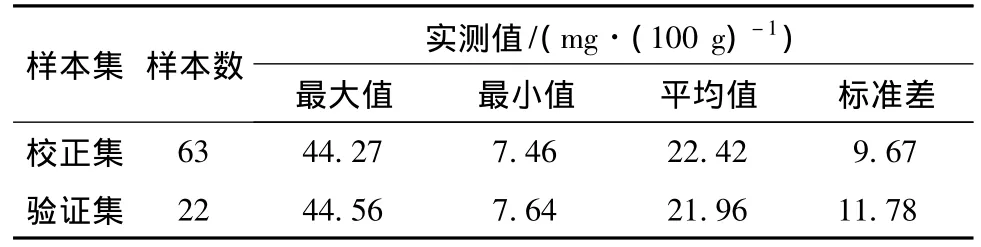
表1 牛肉样本挥发性盐基氮实测值
1.3 数据处理及建模方法
1)数据预处理.为消除高频噪声干扰、图谱偏移或漂移现象和光谱的多重共线性,采用Savitzky-Golay(SG)平滑、多元散射校正(multiplication scatter correction,MSC)和一阶导数(first derivative,FD)方法对光谱数据进行预处理.具体处理是采用Matlab7.6.0软件编写相应程序进行处理和分析,下文其他算法实现及分析也均是用该软件编写的相应程序.
2)无信息变量消除算法和连续投影算法.UVE[10]是基于分析偏最小二乘法(PLS)回归系数b的算法,用于消除不提供信息的变量,减少建模变量数,提高建模速度,降低模型的复杂性.SPA[11]是一种利用向量的投影分析,从光谱信息中寻找含有最低限度冗余信息、共线性最小的变量组,大大减少建模所用变量个数.UVE算法和SPA算法相结合,能够进一步减少建模变量个数,提高建模效率和建模精度.
3)建模及评价方法.最小二乘支持向量机(least square-support vector machine,LS-SVM)是在经典SVM的基础上改进的新型建模方法,能够很好的解决高维数、非线性、小样本、局部极小等传统建模方法的难题,降低计算的复杂性,是光谱数据建模分析的有效工具之一[12].模型的性能用校正相关系数Rc、验证相关系数Rv和校正标准差Sc、验证标准差 Sv评判.Rc,Rv越大,Sc,Sv越小,模型越好.
2 结果与讨论
2.1 全波段光谱预处理分析及建模
对原始反射光谱400~1700 nm范围全波段数据共1571个变量进行MSC,FD和SG预处理,采用LS-SVM方法建模预测牛肉TVB-N.选用径向基核函数(radial basic function,RBF)进行LS-SVM进行建模,用网格搜索结合留一交叉验证法进行优化确定影响模型精度的径向基核函数参数σ2和惩罚系数γ.表2显示了不同预处理方法建立LS-SVM模型的预测结果.结果显示SG平滑法(阶次1,窗口11)预处理方法建立的预测模型预测结果最好,校正集和验证集的预测相关系数分别为0.915,0.924,校正集和验证集预测标准差分别为3.956 mg·(100 g)-1和4.638 mg·(100 g)-1,因此下文光谱数据均采用SG平滑预处理方法处理后进行分析.
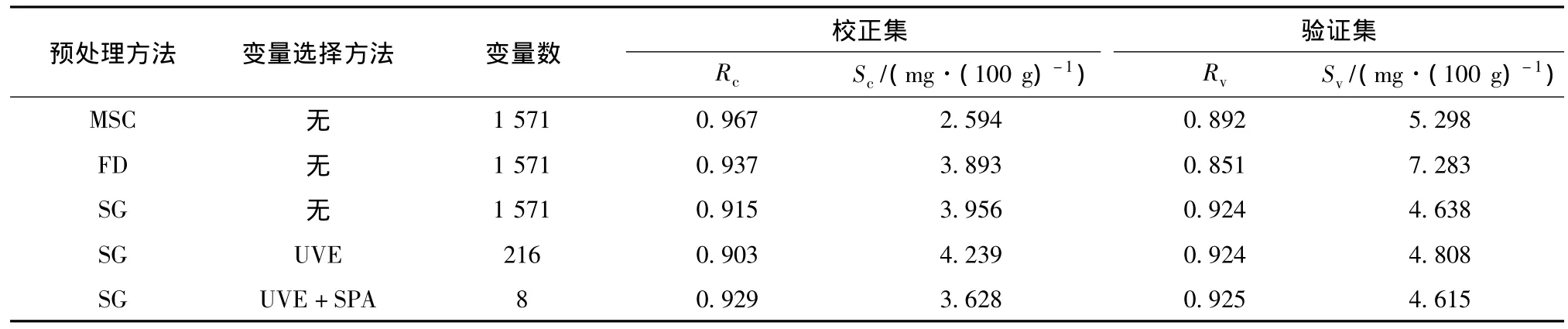
表2 不同预处理和不同变量选择方法得到的光谱变量建立的LS-SVM模型和预测结果
2.2 用UVE提取有效波长
对全波段光谱进行SG平滑后建TVB-N的LSSVM预测模型,得到了较好的预测结果,但全波段中可能包含有对建模无用的冗余信息,全部作为建模输入变量,影响建模速度和精度.用UVE算法进行变量选择,剔除全波段中的无用信息,提取有效波长信息.首先用PLS结合全交叉验证确定最佳主成分为10,在全光谱变量矩阵中加入与其个数相同的随机变量1571个,利用确定的最佳主成分数建立各个变量的PLS回归模型,求得回归系数,计算每个变量的稳定性C.根据设定的稳定性C的阈值,进行变量选择.UVE变量选择过程如图3所示,中间竖直线左侧是全波段光谱实际1571个变量稳定性C的分布,右侧是相同变量个数的1571个随机变量稳定性C的分布.两条水平虚线代表稳定性C的阈值的上下限,两线范围之外的变量为有用信息用来建模.随机变量的稳定性C的最大值设定为阈值.用UVE变量选择后,从1571个变量中选择出了216个有效变量,变量个数减少了86%,变量覆盖可见和近红外光谱区域.选择出来的变量作为输入变量建立LS-SVM模型,预测结果如表2中所示,校正集和验证集的预测相关系数分别为0.903,0.924,预测标准差分别为4.239 mg·(100 g)-1和4.808 mg·(100 g)-1,与用全光谱变量建立的模型预测结果相比,变量个数大幅减少,但预测精度并没有显著下降.所以UVE算法能够有效剔除全波段光谱数据中无用信息,提取用于建模的有效变量信息.
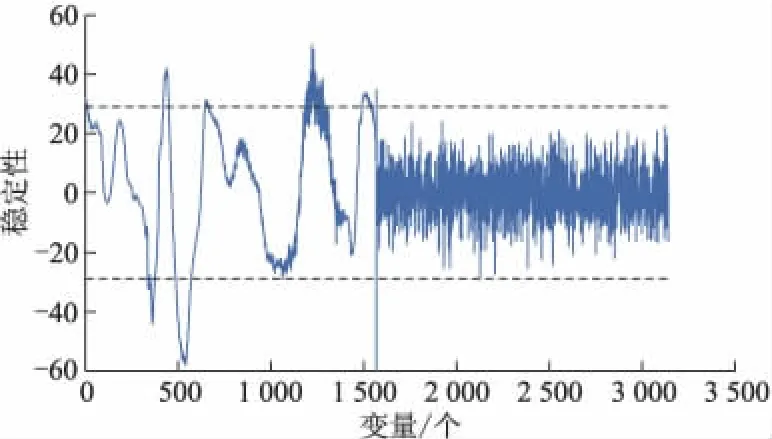
图3 UVE稳定性分布曲线
2.3 用UVE-SPA提取有效波长
用UVE算法消除了原始全波段光谱中存在的大量的无用信息,提取出来了有效的变量信息,但为进一步减少变量个数,并消除变量之间的共线性,用SPA算法对UVE提取后的光谱信息进行处理,提取共线性最小的有效波长变量.波长变量选择数设定为1~21,由校正集内部交叉验证均方根误差(RMSECV)值确定最佳有效光谱变量个数.从UVE处理后的216个光谱变量中,提取出8个有效变量,如图4,5所示.变量个数在UVE处理后的基础上减少了96%,与原始全光谱变量个数相比减少了99.5%.提取的有效变量作为输入变量建立LS-SVM预测模型对验证集进行预测,预测结果如表2中所示,预测相关系数和标准差分别为0.925,4.615 mg·(100 g)-1,具有较好的预测结果,预测精度高于UVE-LSSVM.预测结果的散布图如图6所示,验证集样本的预测值能够较好地分布在回归直线的两侧,说明UVE算法联合SPA算法能够很好地从大量的光谱信息中提取出最有效的波长变量,结合LS-SVM建立的预测模型,能够很好地预测牛肉挥发性盐基氮的值.
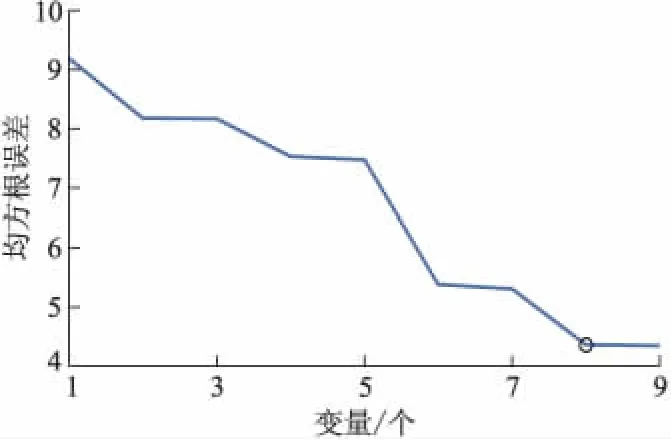
图4 SPA变量选择
图5 UVE-SPA选择的波长
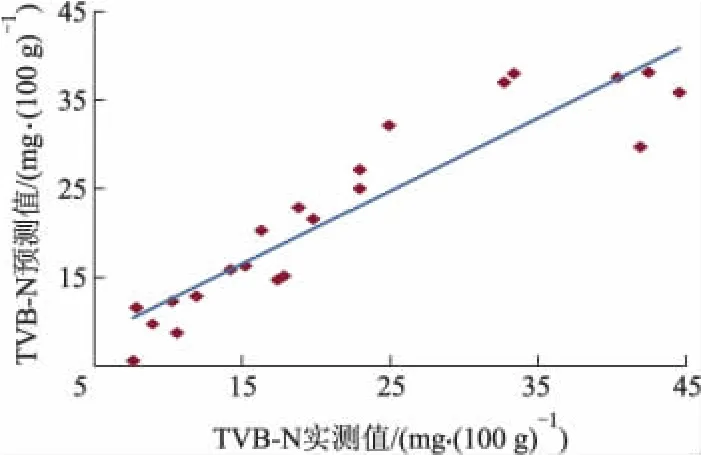
图6 UVE-SPA-LS-SVM模型预测TVB-N结果
3 结论
搭建了可见/近红外光谱检测系统,结合UVE和SPA建立LS-SVM预测模型,实现了牛肉4℃下整个储存期TVB-N的无损快速准确检测.通过优化对比,确定SG平滑为最佳光谱数据预处理方法.选取有效光谱变量8个,与全光谱变量建模相比,变量数减少了99.5%,精度得到提高,建立的LS-SVM预测模型的预测相关系数和标准差分别为0.925和4.615 mg·(100 g)-1,具有较好的预测精度.结果表明:应用可见/近红外光谱技术,结合UVE、SPA变量选择算法和LS-SVM建模方法,能有效减少建模所用变量个数,提高建模速度和模型预测精度,为进一步开发实用的牛肉TVB-N无损快速检测设备,实现牛肉新鲜度无损快速评价、分级提供参考.
References)
[1]朱咏莉,李萍萍,毛罕平,等.基于特征光谱提取的有机基质含水量快速测定方法[J],江苏大学学报:自然科学版,2011,32(2):140-143.Zhu Yongli,Li Pingping,Mao Hanping,et al.Moisture content detection in organic substrates based on characteristic wavelength in near infrared spectroscopy[J].Journal of Jiangsu University:Natural Science Edition,2011,32(2):140-143.(in Chinese)
[2]陈 斌,崔 广,金尚忠,等.近红外光谱在快速检测棉制品中含棉量的应用[J].江苏大学学报:自然科学版,2007,28(3):185-188.Chen Bin,Cui Guang,Jin Shangzhong,et al.Application of near infrared spectra in rapid inspection of cotton contents[J].Journal of Jiangsu University:Natural Science Edition,2007,28(3):185-188.(in Chinese)
[3]徐 霞,成 芳,应义斌.近红外光谱技术在肉品检测中的应用和研究进展[J].光谱学与光谱分析,2009,29(7):1876-1880.Xu Xia,Cheng Fang,Ying Yibin.Application and recent development of research on near-infrared spectroscopy for meat quality evaluation[J].Spectroscopy and Spectral Analysis,2009,29(7):1876-1880.(in Chinese)
[4]Savenije B,Geesink G H,van der Palen J G P,et al.Prediction of pork quality using visible/near-infrared reflectance spectroscopy[J].Meat Science,2006,73:181-184.
[5]侯瑞锋,黄 岚,王忠义,等.用近红外漫反射光谱检测肉品新鲜度的初步研究[J].光谱学与光谱分析,2006,26(12):2193-2196.Hou Ruifeng,Huang Lan,Wang Zhongyi,et al.The preliminary study for testing freshness of meat by using near-infrared reflectance spectroscopy[J].Spectroscopy and Spectral Analysis,2006,26(12):2193-2196.(in Chinese)
[6]Cai Jianrong,Chen Quansheng,Wan Xinmin,et al.Determination of total volatile basic nitrogen(TVB-N)content and Warner-Bratzler shear force(WBSF)in pork using Fourier transform near infrared(FT-NIR)spectroscopy[J].Food Chemistry,2011,126:1354-1360.
[7]Liu Fei,Jiang Yihong,He Yong.Variable selection in visible/near infrared spectra for linear and nonlinear calibrations:a case study to determine soluble solids content of beer[J].Analytica Chimica Acta,2009,635:45-52.
[8]Xu Huirong,Qi Bing,Sun Tong,et al.Variable selection in visible and near-infrared spectra:application to online determination of sugar content in pears[J].Journal of Food Engineering,2012,109:142-147.
[9]展晓日,朱向荣,史新元,等.SPXY样本划分法及蒙特卡罗交叉验证结合近红外光谱用于橘嘻橙皮苷的含量测定[J].光谱学与光谱分析,2009,29(4):964-968.Zhan Xiaori,Zhu Xiangrong,Shi Xinyuan,et al.Determination of hesperidin in tangerine leaf by near-infrared spectroscopy with SPXY algorithm for sample subset partitioning and monte carlo cross validation[J].Spectroscopy and Spectral Analysis,2009,29(4):964-968.(in Chinese)
[10]Wu Di,He Yong,Nie Pengcheng,et al.Hybrid variable selection in visible and near-infrared spectral analysis for non-invasive quality determination of grape juice[J].Analytica Chimica Acta,2010,659:229-237.
[11]Márcio J C P,Roberto K H G,Mário C U A,et al.The successive projections algorithm for spectral variable selection in classification problems[J].Chemometrics and Intelligent Laboratory Systems,2005,78:11-18.
[12]Liu Fei,He Yong.Application of successive projections algorithm for variable selection to determine organic acids of plum vinegar[J].Food Chemistry,2009,115:1430-1436.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
温州大学学报(自然科学版)(2022年2期)2022-05-30
空间科学学报(2021年1期)2021-05-22
潍坊学院学报(2020年2期)2021-01-18
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
制导与引信(2017年3期)2017-11-02
中国光学(2015年5期)2015-12-09
海军航空大学学报(2015年4期)2015-02-27
