
一种用于文本分类的特征项权值计算方法的研究
2013-08-19 08:06:40胡平霞李春媚
惠州学院学报 2013年6期
龚 静,胡平霞,李春媚
(湖南环境生物职业技术学院信息技术系,湖南 衡阳 421005)
1 引言
文本分类是指通过分析文本的内容自动将文本分配到预先定义的类别中,其目标是将语义相近的文本组织到同一个类别中,以便对文本集进行组织和管理[1]。文本分类被广泛应用在网页文本归类、垃圾邮件过滤等领域。文本分类的步骤为:①文本的分词;②文本的表示;③特征项权值计算;④特征选择;⑤文本分类[2]。
在文本分类中,人们较多地研究特征选择算法与文本分类算法,而对特征项权值计算方法的研究非常少,特征项的权值是衡量某个特征项在文本表示中的重要程度或区分能力的强弱[3],即这个特征项在多大程度上能够代表这个文本,可知,选择不同的特征项权值计算方法将会对文本分类的结果产生非常大的影响。因此,文章在既考虑特征项的频率因素,又考虑特征项的语义因素的基础上提出了一种新的特征项权值计算方法,采用支持向量机(Support Vector Machine,VSM)分类算法进行了分类实验,实验结果表明此方法能有效提高文本分类的正确率。
2 特征项的概念及其权值计算
中文文本的内容是用自然语言来描述的,具有有限的结构甚至没有结构,其语义计算机是不能直接理解的,所以需要对中文文本进行相应的处理[4],即预处理,从中抽取标志文本内容的元数据,即特征项。特征项可以是字、词、短语或语义单元,一般来讲,词是具有独立语义特性的最小单位,因此,在中文文本中以词为单位来抽取特征项,最后用结构化的形式表示这些特征项。目前,在中文文本信息处理中,效果较好且应用较广的表示方法为向量空间模型。在VSM 中,一个文本用向量空间中的一个点来描述[5],其形式为:其中为特征项,为特征项的权重,简写为。可知,向量空间模型中每一维的值表示特征项在该文本中的权重,用来刻画该特征项对表示文本内容的重要程度。特征项权值的计算原则就是最大限度地区别不同的文本。一般使用的特征项权值计算方法是词语频率与,但是,这两种方法还存在一些不足,影响文本分类的效果,因此文章从频率与语义两个方面来计算特征项的权重。
2.1 特征项频率信息
2.1.1 特征项频率
特征项频率是指特征项在文档中出现的次数,在不同类别的文档中特征项出现的频率存在很大的差异,因此,特征项频率是文本分类的重要参考因素之一,在最初的文本分类中权值的计算就是采用。
2.1.2 逆文档频率
文档频率是指在整个文本集中出现该特征项的文本数[6]。逆文档频率是指特征项出现在较多的文本中,它的重要性就低,相反,如果集中出现在少数文本中,它的重要性就越高。
综合考虑特征项频率与逆文档频率,得到了特征项频率的计算公式,也就是通常的公式[7],见公式(1):
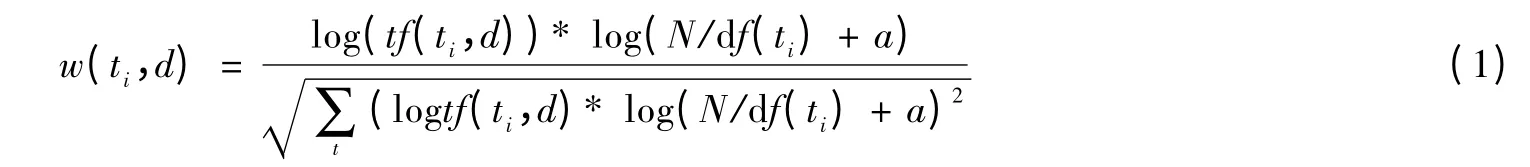
其中,是指特征项在文本中出现的频率,是文本集中文本的个数,是指特征项在文本数据集中出现的文本个数,是逆文本频数。
这样通过频率计算得到,接着考虑特征项的语义信息,然后通过逐步修改权值的方式来真正体现特征项在文本中的重要程度。
2.2 特征项语义信息
特征项的语义分析是从中文文本的语义角度出发,用相应的权重来反映特征项的语义信息,在此主要从特征项的同现、位置、长度等方面来考虑。
2.2.1 词同现频率
在中文文本中,句义的表达是由词与词的关系及组成句的词义表达的,出现在同一句中的词两两之间的同现关系表现句子的意义。如果两个词同时出现在同一句子中,说明这两个词具有最直接的相关性[8]。增加词共现概念的向量空间模型比单纯的基于词频的向量空间模型更能反映文本的内容和语义。
设词在文本中出现的总次数为,即词频,词在文本中出现的总的次数为,即词频,词与词同现频率记为(句内不重复计数),可知=,因此,文章定义词与的同现概率计算方法为公式(2)。
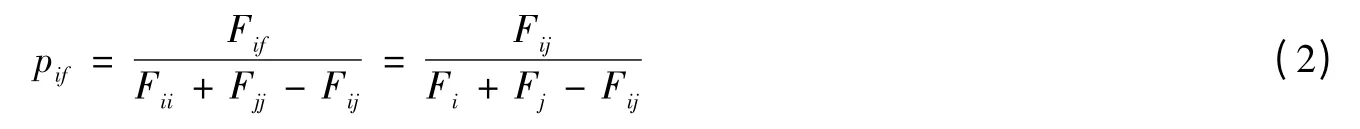
其中,为词与词的同现概率,可知=,≡1。
最终,就得到了一个关于文本的词与词之间的一个同现概率矩阵,它是一个行列的对称矩阵,表示该文本特征项的数量。

文章利用该矩阵对的权值进行修正,特征项的权值修正为公式(4):
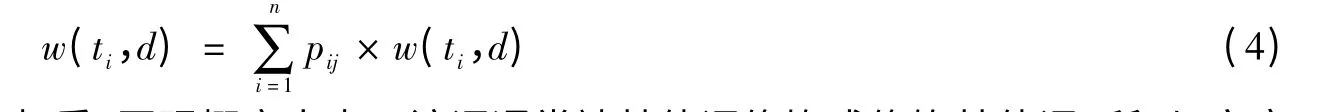
可见,加强了同现概率大的特征项的权重,同现概率大表示该词通常被其他词修饰或修饰其他词,所以,文章就认为该词是一个比较重要的词,是能够体现文本的主题思想,它的权重应该得到相应的加强,并且也加强了与之关联比较大的词语权重,新得到的文本特征描述蕴涵了词的同现特点,突出了该文本的语义信息,符合人们的思维习惯。
2.2.2 特征长度权重
一般说来,长词的频率较低,是面向内容的,而短词的频率较高、含义多,是面向功能的[9]。适当提高长词的权重,有利于分割词汇,以便更加准确地体现出特征项在文本中的重要程度。因此,长词应该具备较高的权重,因此,文章将权值修正为公式(5):

其中,表示词的长度,如“数字电子计算机”中
2.2.3 位置权重
国外学者进行过统计,体现文本主题的句子,10% 出现在段尾,80% 出现在段首[10]。同样,国内研究者通过统计得出中文新闻的标题与主题的符合率为94%,而中文期刊自然科学论文的标题与主题的符合率为97%。这些数据说明特征项的位置不一样,对文本的作用也不一样,尽管有些特征项的频率不高,但是它却能够很好地反映文本的内容。所以,针对性不同位置的特征项进行了加权,设位置权重计算方法如公式(6)所示。
设特征项的位置权重为,其值为:

设为特征项在相应位置出现的次数,进行了位置加权的特征项权值计算方法在此定义如公式(7)所示:
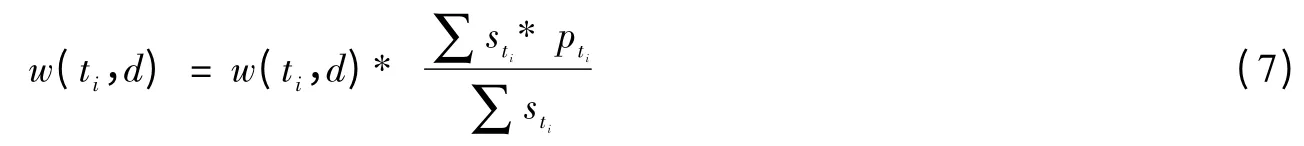
2.3 一种新的特征项权值计算算法()
设待分类的文本集合为,文本集合的个数为,特征项集合为,特征项权值计算方法描述如下:
对于每个特征项,其中;每个文本,其中
Step 1 首先统计特征项在文本中出现的次数及它与同时出现在同一个句子内的次数,特征在文本集中出现的文本频率,特征项的位置信息以及的词长。
Step 2 将Step1 得到的与利用公式(1)计算基于特征项频率特性的权值();
Step 3 利用step1 中得到的建立同现概率矩阵,然后利用公式(4)修正特征项权值();
Step 4 利用Step1 计入的词长,然后利用公式(5)修正特征项权值();
Step 5 利用Step1 中给出的位置信息,然后利用公式(7)修正特征项权值();
Step 6 得到特征项最终权值为(),程序结束。
3 实验与结果
为了检验此种权值计算方法的有效性,采用与通用的词频与方法进行了对比实验。实验用VC++实现,在Celeron(R)2.6G,4GB 内存的计算机上进行。用中国科学院计算技术研究所的ICTCLAS 分词系统进行分词,采用的分类算法为支持向量机算法,SVM 是基于统计学习的机器学习方法,能够较好地处理小样本情况下的学习问题,能够利用核函数思想把非线性问题转化为线性问题来解决,能够大大降低算法的复杂度,因此被广泛应用在文本分类领域。实验文本数据来源于复旦大学国际数据库,训练语料是由人工标注类别的,6个类别共641 篇文本,测试语料626个文本,训练语料与测试语料基本上是1:1 的比例。分类结果评价指标采用F-measure,其计算如公式(8)所示,得到的实验结果如表1 所示。
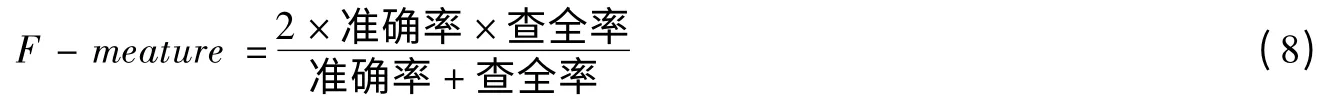

表1 比较实验结果
通过对实验结果比较分析,文章中提出的权值计算方法的F- meature 平均值比以词频为权重的计算方法平均高出了14.11%,比方法平均高出6.78%。可知,此方法更能突出特征项对文本内容的贡献程度,实验结果证明此方法更有效。
4 结束语
无论对于文本分类还是文本聚类,特征项权值计算都是其中的一个基础环节,选不同的权值计算方法对文本分类的准确率有很大的影响,文章提出的权值计算方法在实际的分类系统中取得了比较好的效果。但是,实验中是采用支持向量机SVM 分类器来进行分类的,以后将尝试将此权值计算方法与其他文本分类算法相结合,以期提高文本分类的整体性能,与此同时也将尝试将此算法思想运用到文本聚类、自动文摘中去。
[1]路永和,李焰锋.改进TF-IDF 算法的文本特征项权值计算方法[J].图书情报工作,2013(2):91-95.
[2]张爱华,靖红芳.文本分类中特征权重因子的作用研究[J].中文信息学报,2010(5):97-101.
[3]龚静,李安民.一种改进的k-means 中文文本聚类算法[J].湖南工业大学学报,2008.3:52-55.
[4]杨杰明.文本分类中文本表示模型和特征选择算法研究[D].吉林大学,2013.6.
[5]谭金波.文本层次分类中特征项权重算法的比较研究[J].情报杂志,2007(9):87-91.
[6]NAVEENKMAR N,BATRI.K.An Empirica l Study on Term Weights for Text Categorization[J].International Journal of Advanced Information Science and Technology 2012(11):43-46.
[7]龚静,曾莉.用于文本分类的特征选择方法[J].湖南环境生物职业技术学院学报,2008(9):24-26.
[8]寇莎莎,魏振军.自动文本分类中权值公式的改进[J].计算机工程与设计,2005(6):1616-1618.
[9]侯艳钗.基于词语权重的中文文本分类算法的研究[D].石家庄:河北工业大学,2010.
[10]李凯齐,刁兴春,曹建军.基于信息增益的文本特征权重改进算法[J].计算机工程,2011(1):16-18.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
开放教育研究(2020年2期)2020-03-31 01:54:14
自动化学报(2017年7期)2017-04-18 13:41:02
现代语文(2016年21期)2016-05-25 13:13:44
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
大连民族大学学报(2015年2期)2015-02-27 08:28:11
导航定位与授时(2014年2期)2014-04-27 13:41:09
