
基于分类排名的网站可信度分析
2013-07-25 05:58:04黄晞俞建家
福州大学学报(自然科学版) 2013年1期
黄晞,俞建家
(福州大学数学与计算机科学学院,福建福州 350116)
0 引言
因特网的普及和发展使之成为人们最主要的信息来源之一.而从网上获取信息最常用的方式是通过搜索引擎搜索或者通过门户网站的导航链接推荐,但是正如文[1-2]中提到的,那些基于经典排名算法的搜索引擎所提供的信息却未必总是正确可信的.
为此,近年来有很多学者提出关于网站可信度分析的算法,这一系列算法一般统称为fact finder.其中文[2-4]采用无监督学习,主要通过对网站的可信度、网站所提供的事实、可信度的迭代计算,对网站的可信度进行分析.这些fact finder算法所针对的问题都是文[2]中提出的经典的Truth Discovery问题.文[2]的Truth Finder是最早提出解决这个问题的算法,也是目前相关论文中都用到的一个基准算法.文[3]通过判断源(网站)之间的拷贝关系,将源划分为独立更新的源和抄袭者,给予独立的源以更高的可信度.文[4]中通过将事实划分成难易程度不同的问题,根据难易程度来计算其得分,回答的问题越难,那么得分就越高.文[5]的改进是在判断一个事实正确与否时,通过事先加入一些预知识来判断,使得不会因为某些虚假事实的泛滥而将其误认为真.文[6]提出采用半监督学习的方法,通过加入一些ground truth来提升可信度分析的结果和准确性.
文[1]采用聚类方法,但是对于聚类结果,很难说每次得到的都是有意义的,在文[1]的实验部分也提到这一点;而且传统的fact finder算法基本上都是无监督学习,初始值的设置(如设置初始可信度为0.9或者0.5),显得并不是很合理.本研究中,主要参考文[1]中的方法,将传统的可信度分析问题扩展,增加对每个对象类别的考虑,对文[2]中的算法加以改进,并且通过引入训练集,将传统的分类算法结果与可信度分析算法进行结合.
1 问题描述
问题的描述与文[2]中提出传统的Truth Discovery问题有所不同,文[2]中的算法主要为了从不同网站提供的不同事实中找出可信的事实,并给出网站可信度分析结果.
例如,在不同的网站上搜索ISBN:0852-967675的书,然后找出它的作者.结果如表1所示,即使是同一本书,不同的网站对于它的作者描述也不尽相同.将一个网站定义为一个源,它所提供的作者定义为事实,ISBN为0852967675的书定义为对象.文[2]中的Truth Finder算法,就是根据源的可信度和同一个对象的不同事实之间的关系来找出最可靠的事实,但是文[2]中的问题并没有考虑分类信息,因为同一个对象在不同网站上的分类结果往往并不相同.

表1 不同的事实示例Tab.1 Examples of different facts on the same object
因此,本研究考虑的问题就是在进行网站可信度分析时,如何加入对象的类别信息;再者,传统的无监督算法采用人工设置初始值的方法并不合理,如何通过引入训练集来获得比较合理的初始值也是本研究探讨的问题之一.
算法的输入(Input):事实集F={f1,f2,…,fn};源(网站)集S={s1,s2,…,sm};对象(Object)集O={o1,o2,…,ok};初始的关系矩阵M={mij},1≤i,j≤n,mij表示事实fi和fj之间的关系;一个类别集C={c1,c2,…,ct}.
算法的输出(Output):每个站点总的可信度,每个类中各个站点的可信度和每个对象不同事实的可信度.
2 改进的TruthFinder算法
2.1 变量的定义
2.1.1 源的可信度定义

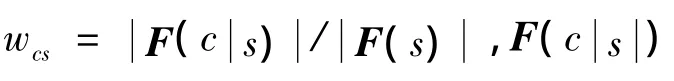
2.1.2 类别的可信度的定义

其中:Fc表示c类的事实集合,T(f)表示事实f的可信度.

其中:T(c|s)表示在源s下类c的可信度.
2.1.3 事实的可信度定义
根据文[2]的定义

其中:T(s)表示源s的可信度.与文[2]不同的是,本研究还考虑到同类事实之间的影响和指向相同对象但是属于不同类别的事实之间的影响,将文[2]中的公式进行改写,就有
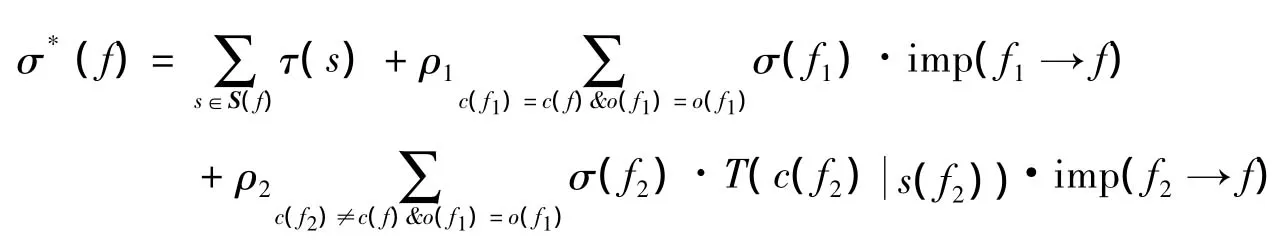
其中:σ(f)=-ln(1-T(f)),0≤ρ1,ρ2≤1是2个参数.最后,再用和文[2]一样的计量方法:

最终使用公式(4)来表示源s的可信度,用公式(5)来表示事实f的可信度,其中e为数学常数,γ表示一个取值为0~1之间的参数.
2.2 算法的实现
ITF实现的具体步骤如下:
Step 1:初始化,主要包括数据预处理,如利用传统的分类算法来对训练数据进行训练,并且预测测试集中各个对象的类别,计算关系矩阵,固定权重wcs和初始可信度;
Step 2:对于每个事实,按公式(5)计算它们的可信度;
Step 3:对于每个分类,根据更新后的事实可信度,按公式(2)和(3)重新计算每个分类的全局可信度以及各个源下各类的可信度;
Step 4:对于每个网站,根据更新后的事实和类别可信度,按公式(1)和(4)重新计算它们的可信度;Step 5:重复Step 2至Step 4,直到达到指定的收敛条件或者超过指定的循环次数.
2.3 预定的收敛条件
定义:
第三,中国气温变化。我国的温度变化跟全球基本上趋势一致,但略高于全球平均水平。我国过去百年约上升0.8℃,最近50年的升率约为0.22℃/10a,高于世界平均值。四季均呈升温趋势,其中,冬季节升温显著,春夏季节存在局地降温情势。
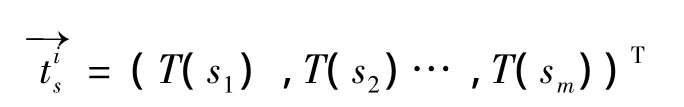
其中:i表示迭代的轮数.
定义收敛条件:
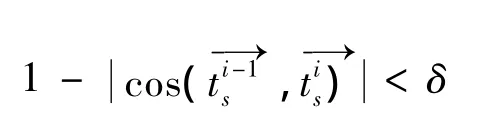
其中:δ为阈值,与文[2]中一样取0.000 000 1.
3 实验结果与分析
3.1 实验数据集
实验数据集来自互联网上的实际数据,来源与文[2]中相同.首先在abebook.com分别以database和data mining作为关键字进行搜索,从中选出200本书,然后使用书的ISBN在不同的网上书店进行搜索,选他们的作者和分类标准作为实验数据.为了评估实验结果的准确性,通过人工将这200本书封面上的作者作为基准事实输入数据集中.
本数据集的信息主要包括网上书店名,作者集,分类标签,书名.采用书店作为源集,某本书在某个书店的作者描述作为事实,书作为对象,利用传统分类算法按分类标签信息对书进行分类,用得到的分类结果作为类别.本实验数据集里总共有9个网上书店,200本书,1 562条事实,2个类别.公式里的参数设为0.5.去除找不到封面的书本集后,用剩余数据集中50%的数据集作为训练数据集,其余的作为测试数据集.
3.2 数据预处理
使用训练数据集,根据事实与基准事实的比较,计算出事实的可信度.
为了获得分类信息,采用向量空间模型,将每本书用其分类标签表示为向量,目标类别为data base类和data mining类.因为不同的源上,分类标签往往不同(如:在本数据集中,Ebay上的维度是53,Amazon上的维度为168),所以对训练数据集分别在不同的源上使用传统的分类算法(包括J48决策树,K-nn(n=1),Naive Bayes)进行训练,并对测试数据集进行预测.在本实验中,采用分类准确度最高(平均80%)的Naive Bayes算法结果,作为数据集中分类信息.
两个事实之间的影响因子imp(f1→f2)与文[2,4]中相同.
3.3 实验结果与分析
3.3.1 准确率比较
准确率定义:
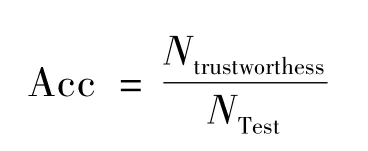
其中:Ntest表示测试集中的对象数,Ntrustworthess表示在测试集中所有的对象里,最可信的事实fbest与基准事实fstandard相同的对象个数.
实验结果如表2所示,ITF算法准确率明显优于其他传统的 Fact Finder算法.其中,TF0.5表示文[2]中参数取 0.5的 Truth Finder算法,Sums指文[5]中的 Sums算法,A·L表示文[5]中Average Log算法,Inv1.2表示文[5]中参数取 1.2 的 Investment算法.
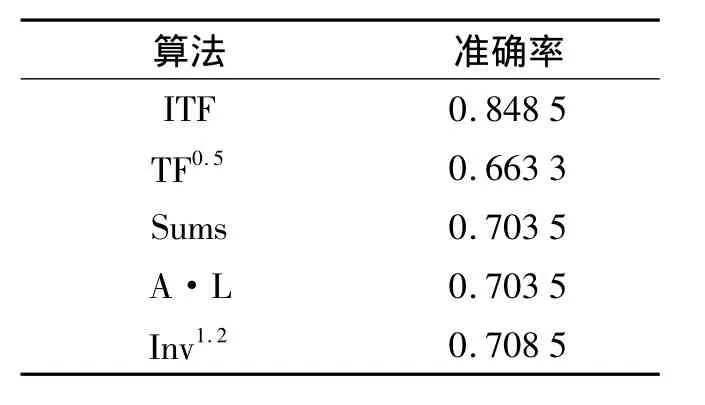
表2 准确率比较Tab.2 Comparison of Accuracy
3.3.2 复杂度分析
假设源(即网站)总数为N,事实的总数为L,对象总数为M,迭代轮数为k,类别数为C,对于每个对象,平均有t个相关的事实,一般而言,有L>>M,L>>N,L>>t.
迭代计算过程中,首先,计算源的可信度需要遍历所有源和所有对象,需要O(MN)时间;其次计算类别可信度,需要遍历所有的事实,只需要O(CL)时间;最后计算事实的可信度,根据σ*(f)的定义,由3个部分组成.第1部分计算需要遍历所有事实,需要O(L)时间;余下部分,主要计算对于同一个对象的不同事实之间关系,平均需要O(t)时间.所以计算所有事实的可信度需要O(L×(L+t)).由于L>>M,L>>N,L>>t,因此总的全局时间复杂度为O(kL2).
关于空间复杂度,主要需要保存源,事实,对象的信息需要O(L+M+N)空间.在迭代计算过程中,并不需要额外的空间花费.所以总空间复杂度为O(L+M+N).
3.3.3 实验结果分析
由表2可见,ITF算法的准确率在本实验数据集上的准确率明显高于传统Fact Finder系列算法,而且不论在时间复杂度还是空间复杂度上,和文[2]的TF算法相比,并没有大幅增加.最终实验结果表明,ITF算法的结果优于传统的Fact Finder系列算法.
4 结语
提出一种改进的基于分类排名的网站可信度算法.ITF算法利用训练集来获得算法的初始输入,比起传统的无监督Fact Finder算法中将初始可信度都设置成0.9或者0.5更科学合理.实验结果表明,ITF算法的准确率明显高于传统的Fact Finder算法,在时间开销上,除了预处理中的时间开销外,迭代计算中的时间开销与传统的Fact Finder算法并没有大幅增加,而且在空间开销上并没有额外的增加.虽然ITF算法在可信度标准的确认上仍然是和其他文献[2,4-5]一样,根据实验数据来主观确定,但在以后的工作中,会通过引入半监督学习的方法来对算法中的可信度标准判定和计算进行改进.
[1]Gupta M,Sun Yi-zhou,Han Jia-wei.Trust analysis with clustering[C]//Proc of 2011 Int World Wide Web Conf(WWW'11).Hyderabad:[s.n.],2011:53 -54.
[2]Yin Xiao-xin,Han Jia-wei,Yu P S.Truth discovery with multiple conflicting information providers on the web[J].Transactions on Knowledge and Data Engineering,2008,20(6):796-808.
[3]Dong Xin Luna,Berti- Equille L,Hu Yi- fan,et al.Global detection of complex copying relationships between sources[C]//International Conference on Very Large Data Bases(VLDB).Singapore:[s.n.],2010(3):1 358 -1 369.
[4]Alban G,Abiteboul S,Marian A,et al.Corroborating information from disagreeing views[C]//Proceedings of the Third ACM International Conference on Web Search and Data Mining.New York:[s.n.],2010:131 -140.
[5]Pasternack J,Roth D.Knowing what to believe(when you already know something)[C]//Proceedings of the 23rd International Conference on Computational Linguistics.Beijing:[s.n.],2010:877 -885.
[6]Yin Xiao-xin,Tao Wen-zhao.Semi-supervised truth discovery[C]//The 20th International Conference on World Wide Web.New York:[s.n.],2011:217 -226.
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
意林(2018年3期)2018-03-02 15:17:24
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
山东青年(2016年1期)2016-02-28 14:25:25
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
当代修辞学(2014年3期)2014-01-21 02:30:44
食品科学(2013年8期)2013-03-11 18:21:31
