
基于多核处理器的SVC高清实时编码
2013-07-20 02:50黄亮
计算机工程与应用 2013年13期
黄亮
浙江大学 数字技术及仪器研究所,杭州 310027
基于多核处理器的SVC高清实时编码
黄亮
浙江大学 数字技术及仪器研究所,杭州 310027
1 引言
随着视频应用的发展,高压缩率的H.264/AVC视频编码标准取得了非常广泛的应用[1-2]。针对不同处理器能力的计算平台、显示设备,不同视频质量需求的终端用户,需要不同特性的视频码流的问题[3],JVC(Joint Video Coding)增加了H.264/AVC视频标准附录[4],命名为SVC。SVC[5](可伸缩视频编码)具有时域、空域、质量3个层次上的分级特性,比H.264/AVC具有更好的网络环境及终端适应性,可广泛用于视频会议、视频网站无缝切换服务等。
虽然SVC的多层结构能很好地解决如上所述问题,但是伴随层数的增加,编码器的复杂度也大幅增加。文献[6]以x264为基础,仅仅实现了时域可伸缩的编码方案,也只能支持最大分辨率QVGA的实时编码,在高清视频方面,SVC的实时应用方案较少。多核技术的飞速发展,为高复杂度的SVC视频编码提供了强有力的平台支撑。TileraGx36处理器集成了36个核心,每个核都是一个通用处理器,可独立搭载一个Linux操作系统,其64位的CPU架构及SIMD处理指令对高运算复杂度的多媒体应用是极大的支持,并且该平台提供多核处理的硬件同步,编程性较好。
目前,SVC相关的实时并行编码方案较少,工程上主要集中在小分辨率及FPGA上的实现。文献[7]从减少层间采样的内存带宽方面对SVC进行优化;文献[8]对SVC在CIF分辨率下3个层间预测工具进行了全面的性能评估;文献[9-10]从并行滤波的角度提高SVC算法运算速度;文献[11]实现了Intel处理器上的并行编码,但仅限于质量和时间的可伸缩性。本文在分析SVC视频编码算法的基础上,结合JSVM9.18模型,以x264为基础添加SVC的相关功能,充分利用Tilera多核处理器的平台特性,对SVC核心模块进行了SIMD汇编优化,指令cache优化,内存优化等,并结合SVC算法及平台的灵活性,提出了一种多层次的并行编码方式,包括时间层对齐的空间层级并行编码,动态Slice大小编码,多核并行滤波,动态核数分配编码。

图1 SVC编码结构图
2 SVC算法结构
SVC编码算法具有时域、空域、质量3个层次上的可伸缩性质。空域可伸缩(Spatial Scalability,D层)指将原始图像通过下采样生成两幅或多幅空间分辨率不同的图像,然后将各个图像压缩成一个空间分辨率较低的基本层和数个空间分辨率较高的增强层。在相同分辨率下,可以包含多种不同质量的码流即质量可伸缩(Quality scalability,Q层),它通过选用不同的量化等级或者将编码后的残差系数分配到不同的片中(MGS Vector),使码流中能包括不同质量等级的码流。时域可伸缩(Temporal Scalability,T层)指将不同帧率的图像压缩成一个帧率最低的基本层和多个帧率较高的增强层,可通过丢弃码流中的某些帧达到改变帧率的目的。图1所示为SVC空域可伸缩编码框架。
在基本的H264混合编码结构之上,为了充分消除层间冗余信息,SVC提供三种层间预测方式:层间帧内预测;层间运动预测;层间残差预测。当基本层参考宏块采用帧内预测编码时,增强层对应宏块可采用层间帧内预测,以基本层宏块的重建数据作为增强层当前宏块的预测数据。采用层间运动预测方式,可利用基本层参考宏块的分割形式、参考索引、运动矢量来预测增强层的宏块运动信息。层间残差预测方式利用了层间纹理及运动信息高度相关的特点,增强层可利用基本层重建残差数据在DCT之前减去基本层重建残差,并允许在频域进一步减小残差。三种层间预测方式在分辨率不同的层之间,均需要进行必要的上采样操作。
本设计采用4层时间层,2层空间层,2层质量层的结构,可提供16种不同的码率。D0层为640×352,D1层为1 280×720,Q0层QP为34,Q1层QP为28。为减小编码延迟,采取零延迟的分级P帧[12]的时间分层方式,结构如图2所示。
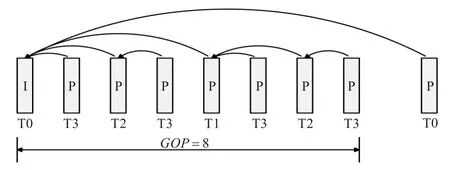
图2 分级P帧时间分层结构图
3 多核并行编码算法
3.1 时间层对齐的空间层级并行
在本文的SVC算法结构中,由于D1Q0层(1 280×720分辨率的质量基本层)需要对D0Q1(640×352分辨率的质量增强层)进行层间上采样的工作,且模式选择上需要综合考虑本层运动搜索和层间预测的结果,运算量非常大,使其成为整个并行算法的瓶颈。按照本文的算法,Q1层的模式选择部分直接取自Q0,运算量较小,因此采用基于空间层的层间并行算法,即D0Q0+D0Q1与D1Q0+D1Q1并行编码,以达到取长补短的效果。
由于同一时间点上的D1层在空间上直接依赖D0层,D0和D1的并行化可通过错帧方式实现,通常的做法是D0层的第1帧首先编码,随后D0的第2帧与D1层的第1帧并行编码,以此类推。考虑到SVC的时间可伸缩结构,各个时间层的参考帧与编码帧的时间相关性各不相同,导致编码效率也不尽相同,总体来说,编码效率上满足T3>T2>T1>T0,加之T3层的帧不作为参考帧,并不需要去方块滤波,这种差异更加明显。但若采用GOP级的并行[13]方案,势必增加延时,不利于实时应用。综合考虑,为了减小两空间层中不同时间层编码性能不均衡性,如图3所示,采取在T3时间层上对齐的方式进行并行编码,有效地均衡两个空间层编码时间,获得了较高的并行效率。
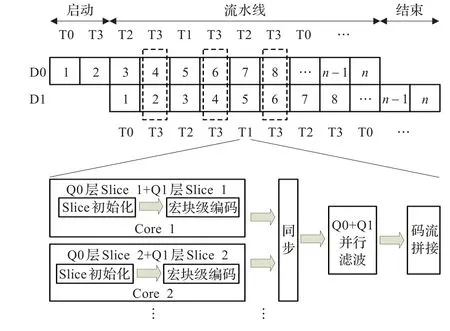
图3 时间层对齐的空间层级并行方案
图3中的数字代表帧序号,启动阶段D0层独自编码两帧,流水线阶段D0层的第3帧与D1层的第1帧同时编码,以此类推,图3以D1层为例阐述了编码过程:
(1)Slice初始化。包括Q0及Q1层的参考帧管理,Slice头部初始化,码流缓冲区初始化,cabac初始化等。
(2)宏块级编码。对Q0及Q1层的宏块轮流进行编码,且所有层间预测均按宏块级进行,如Q0层宏块依次为A,B,C,…,Q1层宏块为a,b,c,…,则编码顺序为A,a,B,b,C,c,…,这样在编码宏块a时可直接利用宏块A的残差或者重建数据,从而避免了整帧残差或重建数据的存储与拷贝。一个宏块的编码过程可分为层间运动上采样,层间帧内上采样,层间残差上采样,标准H.264帧内预测,层间帧内预测,运动搜索,带残差预测的运动搜索,层间运动预测,运动补偿,模式仲裁,DCT,量化,Z扫描及熵编码,反量化,IDCT,残差/帧内重建数据拷贝(以备层间预测使用)和宏块语素修正(如cbp为0时transform_8×8等需要修正)。
(3)去块滤波。依次对Q0、Q1层进行滤波,滤波模块包括标准H.264的LPF以及需要进行层间帧内上采样宏块的LPF。
(4)码流拼接。由于各个Slice并行编码,最后需要将各个Slice的码流拼接在一起。
3.2 基于时间层的动态Slice划分
在同一幅图像上,不同的区域的复杂度也可能各不相同,这种内容上的差异使得各个Slice的编码时间各不相同,也直接导致了整个编码器的均衡程度降低。另一方面,在去方块滤波开始之前,各个核必须完成对应Slice的编码,因此各个Slice必须在并行滤波之前进行同步,同步的时间开销直接取决于各个核对Slice编码的均衡程度。
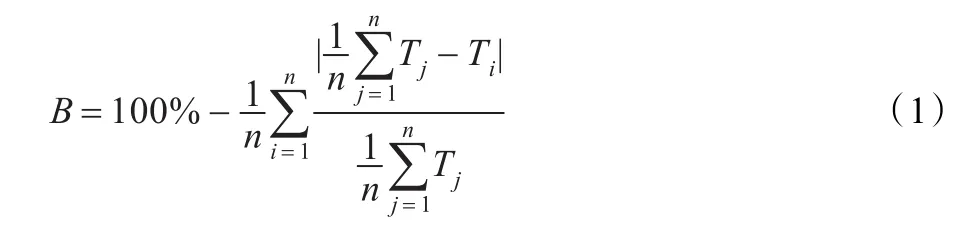
可定义编码均衡度为:公式中,B代表编码均衡度,Ti、Tj分别表示第i个和第j个Slice的编码时间,n表示总Slice数。公式(1)反映了Slice间编码的整体均衡度,各个Slice编码时间相差越明显,B的值越小,而理想情况下,若各Slice编码时间完全相同,则编码均衡度B为100%。动态Slice划分目的就是提高编码均衡度。
根据图1的编码结构,每个Slice的编码过程可以划分为两个阶段:
(1)独立编码(包括层间帧内、运动、残差上采样、模式选择、变换量化、熵编码等);
(2)滤波(包括LPF和INTRA滤波)。
动态Slice划分针对第一个阶段,在层级并行的基础上,动态调整各个Slice的大小。本设计采用了基于PID控制(比例积分微分控制,是控制系统中常用的一种方法)的Slice大小动态划分的策略,即在Slice个数一定的前提下,根据已编码帧的即时统计信息决定当前帧的各个Slice中宏块的个数。考虑到SVC的时间分层结构,为了避免不同时间层之间因参考关系不同造成的编码效率差异,本文算法针对每个时间层单独控制。设每个时间层Slice数为n,整帧总宏块数为frame_mb_count,首先设定一个控制目标值target,控制流程如下所示。
(1)首先初始化各Slice中宏块个数:
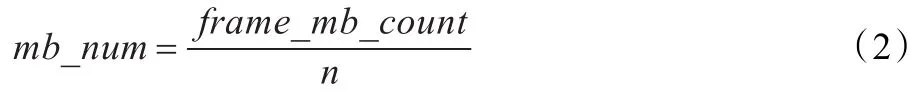
(2)对各个Slice并行编码,统计执行时间Ti;
(3)计算实际值与目标值的误差error及累积误差error_sum:

(4)根据同一时间层中前一帧的误差、当前的误差,以及累积误差计算新的Slice宏块数:
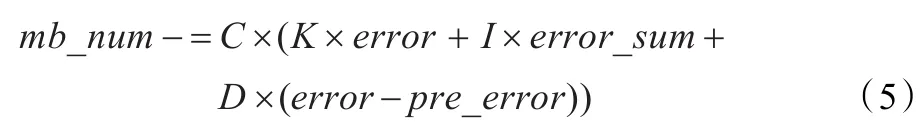
以上式中,target代表理想情况下每个Slice的编码时间占整帧编码时间的比例,target=1/n;Ti为第i个Slice的编码时间;error为目标值target与实际值的误差,例如当某一Slice编码时间超过平均值,error的值为负,将起到减小mb_num的作用;error_sum为累积误差;pre_error为前一次的误差;K、I、D分别为比例、积分、微分调节系数;K×error即时成比例地反应控制系统的偏差error,偏差一旦产生,调节器立即产生控制作用;I×error_sum主要用于消除系统静态误差;D×(error-pre_error)能反应偏差信号的变化速率,并能在偏差信号的值变得太大之前,在系统中引入一个有效的早期修正信号,从而加快系统的响应速度,减小调节时间;常量C,用以调节宏块增加或减少的程度。实验中K=0.7,I=0.2,D=0.1,C=256。
3.3 去方块滤波的并行化
去方块滤波是SVC算法中关键的一个模块,它能有效地降低重建图像的块效应。但是宏块在滤波顺序[14]上存在严格的依赖关系,即当前宏块的去方块滤波必须在其上边宏块、右上宏块以及左边宏块去方块滤波之后进行。由于这种限制,如果各个Slice编码完成之后由一个核串行地对整帧图像执行滤波操作,而其他核处于空闲状态,整个滤波过程会非常漫长,核的利用率也比较低。本文采用一种多核并行滤波方案,将整帧的滤波工作分配成多个核进行,每个核负责一个“竖条”的滤波工作。图4显示了640×352分辨率图像的滤波过程。
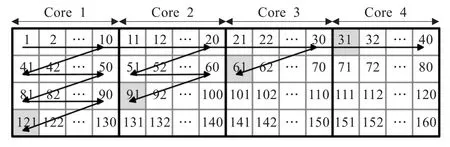
图4 并行滤波方案
图4中,数字序号代表宏块序号。按照这种方式滤波,Core 1首先依次对10个宏块滤波,然后Core 1继续对下一行10个宏块滤波,同时Core 2开始对第一行10个宏块滤波,依此类推,“竖条”边缘的宏块滤波前需要同步,如宏块60,需要判断宏块21是否已经滤波完成,宏块61需要判断宏块60是否完成滤波。各个核滤波的列数可按如下公式迭代算出:
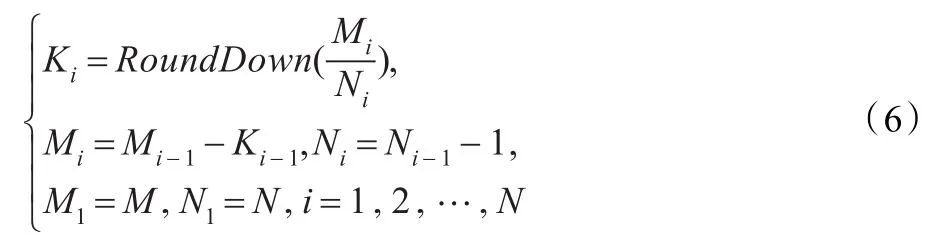
其中,RoundDown()为向下取整函数,M为一帧的宏块列数,N为所使用的核数,Ki为第i个核需要滤波的列数。i从1开始,按照公式迭代计算出K1,K2,…,KN,这样可以保证M不是N的整数倍时仍能将所有列分配到各个核上。
3.4 动态核数分配方案
视频序列内容丰富多变,实际应用中,视频序列的纹理复杂度随时间波动,导致编码器性能不稳定。表1为采用固定核数对各个序列进行编码的性能统计。
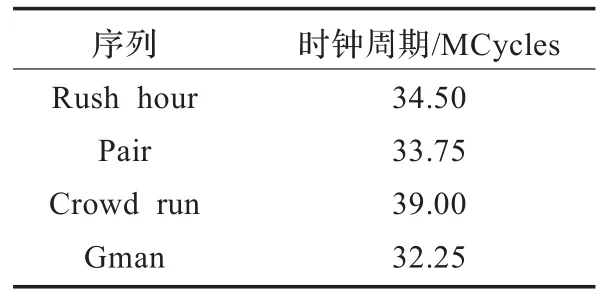
表1 固定核数编码性能统计
表1中,视频会议录像Gman序列耗时最短,马拉松比赛人群奔跑场景的Crowd run耗时最长,两者相差接近7 Mcycles,变化幅度达到21%。可见,不同场景的视频对编码器性能的要求不同,如果仅用满足最低要求的核数来编码,在遇到复杂场景时会达不到实时的帧率;反之,若按照最复杂场景来分配核数,在遇到低复杂度视频时会浪费核数,整个系统能耗比降低;再者,视频场景的变化是必然的,也很难预估恰好合适的核数。因此,本文采用动态核数分配方案,使整个系统始终保持较高的能耗比。其基本做法是以前一秒已编码帧的统计信息为依据,预估下一秒应分配的核数。核数调整公式为:

其中,t为初始设定的一个目标帧率,c为当前阶段的实际帧率,m为当前所使用的核数,n为下一秒需要的核数,RoundDown()为向下取整函数。当实际编码帧率高于目标帧率即c>t时,n的值相应减小,由于一个核负责两个Slice(Q0+Q1)的编码,所以对应的Slice个数相应减小,反之亦然。当核数发生变化时,Slice大小重新平均分配。核数调节之后,空闲的核可用做系统其他用途或者进入睡眠等待。
4 实验结果与分析
在TILERA公司的TileraGx36平台上(1GHz主频,36核处理器),对上述方案进行了测试,选取的序列为Rush hour、Pair、Crowd run、Gman,结果如下:
(1)动态Slice大小划分方案实验结果
图5、图6是对CrowdRun序列D0层4组Slice的编码时间统计。测试序列特点是图像上半部分是天空,下半部分是人群奔跑的场景,如图5,整体编码性能在34 Mcycles上下摆动,各Slice编码时间差异明显,按照公式(1),整体均衡度只有56.47%。由图6可见,采用动态Slice大小划分方式后,从第2帧开始,各个Slice编码时间逐渐达到均衡,最终稳定在32 Mcycles上下,相比固定Slice划分,平均执行时间降低了5.89%,整体性能得到了提高,编码均衡度达到97.33%,比固定Slice划分提高了40.86%。
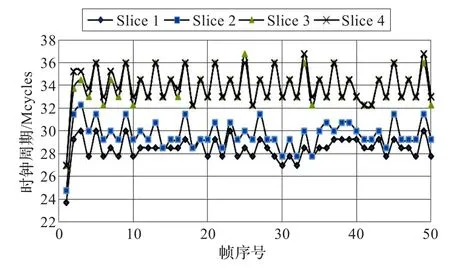
图5 固定Slice大小划分编码时间
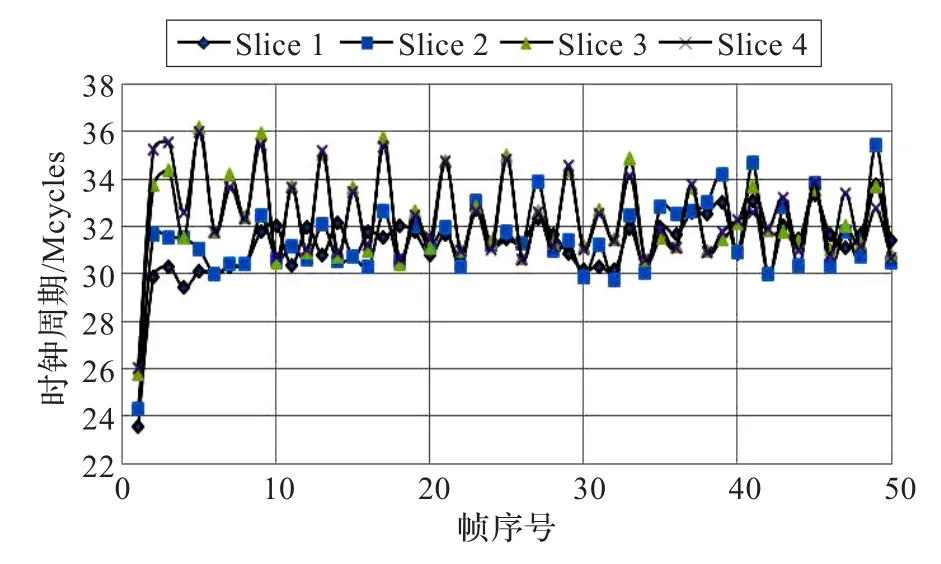
图6 动态Slice大小划分编码时间
(2)去方块滤波的并行化方案实验结果
图7所示为4核滤波结果,相比串行滤波,并行滤波的执行时间减少了56.44%,加速比平均达到了2.3。

图7 串行与并行滤波性能比较(D0Q0层)
(3)动态核数分配方案实验结果
为显著起见,将4个序列按照复杂度从低到高拼接起来,依次为Gman、Pair、Rush hour、Crowd run,如图8所示,随着视频复杂度的增加,所用核数动态跟随性较好,能较快地使编码性能稳定在所设定的目标值附近。相比表1固定核数的编码方式,动态核数分配方式将编码器性能波动控制在2.4%之内,使SVC编码器自适应地响应不同复杂度的场景。
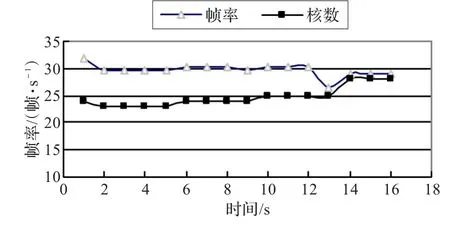
图8 动态核数分配方案性能统计
(4)串行最优与并行方案性能比较
如图9,基于x264的经过优化的串行算法虽然比JSVM9.18开源版本快了不少,在TileraGx36平台上也只能达到1.5帧/s左右,而并行算法的帧率稳定在30帧/s左右,满足了实时应用的要求。各个序列加速比分别为19.87、19.66、21.82、19.16,均在19以上,相比文献[15]中的并行方案提高了10.5。
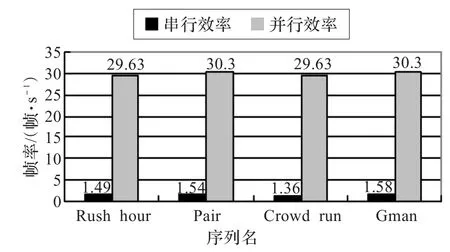
图9 串行与并行总体性能比较
5 结束语
本文在分析SVC编码算法的基础上,以可移植性较好的x264开源代码为基础添加SVC的功能,针对SVC编码算法的特点,提出了时间层对齐的空间层级并行编码方案,采用了直接根据编码时间来动态调整Slice宏块个数的方案,各个核的均衡程度得到了提高。本文还针对任务依赖性比较强的去块滤波模块提出了并行化滤波方案,有效地提高了并行加速比。此外,结合平台特性,对编码核数采取动态调整策略,使有限的资源得到合理的利用。整个编码方案实现了720P高清视频的SVC实时编码,具有较高的工程实用性。
[1]李占林,林其伟.H.264可分级编码技术的研究[J].微计算机信息,2007,23(12):300-302.
[2]任宏.H.264扩展标准-可伸缩视频编码(SVC)及其中精细可伸缩编码的研究[D].成都:成都电子科技大学,2009.
[3]刘娜.可伸缩视频编码算法研究与优化[D].北京:北京邮电大学,2010.
[4]Wiegand T.Draft ITU-T recommendation and final draft international standard of joint video specification,Technical Report JVT-G050[R].2003.
[5]骆政崎,余松煜,宋利,等.H.264可分级扩展技术的介绍和分析[J].中国图象图形学报,2006(11):1578-1583.
[6]孔群娥,曾学文.基于x264实现H.264的时域可伸缩编码[J].微计算机应用,2011,32(3).
[7]Su Y,Tsai S,Chuang T.Mapping scalable video coding decoder on multi-core stream processors[C]//Proceedings of the Picture Coding Symposium,2009.
[8]Li X,Amon P,Hutter A.Performance analysis of inter-layer prediction in scalable video coding extension of H.264/AVC[J]. IEEE Transactions on Brodcasting,2011,57(1).
[9]Cervero T,Otero A,López S.A novel scalable Deblocking Filter architecture for H.264/AVC and SVC video codecs[C]//Proceedings of the IEEE International Conference on Multimedia and Expo,2011.
[10]Yan C,Dai F,Zhang Y.Parallel deblocking filter for H.264/AVC on the TILERA many-core systems[C]//Proceedings of the 17th International Multimedia Modeling Conference(MMM 2011),2011,6523:51-61.
[11]Yao K,Sun J,Liu J.A novel parallel encoding framework for scalable video coding[C]//Proceedings of the IEEE Visual Communications and Image Processing(VCIP 2011),2011.
[12]毕厚杰,王健.新一代视频压缩编码标准——H.264/AVC[M]. 2版.北京:人民邮电出版社,2009-11.
[13]Vander E B,Jaspers E G T,Gelderblom R H.Mapping of H.264decodingonamultiprocessorarchitecture[C]//Proceedings of the SPIE Conf on Image and Video Communications and Processing,2003:707-718.
[14]Reichel J,Schwarz H,Wien M.Scalable video coding:working draft 1[C]//Proceedings of the Joint Video Team(JVT)14th Meeting,Hong Kong,China,17-21 January,2005.
[15]Huang Y,Shen Y,Wu J.Scalable computation for spatially scalable video coding using NVIDIA CUDA and multi-core CPU[C]//Proceedings of the 2009 ACM Multimedia Conference,with Colocated Workshops and Symposiums MM’09,2009:361-370.
HUANG Liang
Institute of Advanced Digital Technology and Instrument,Zhejiang University,Hangzhou 310027,China
Due to the complexity of Scalable Video Coding(SVC)algorithm,a TileraGx36-oriented SVC parallel coding algorithm for HD video is proposed.This algorithm implements temporal layer aligned parallel coding in spatial level.Within a layer, due to the diversity of images,a dynamic Slice partition based on statistics is proposed to achieve dynamic coding balance among Slices,and for the high dependence of LPF module,a parallel loop filter method is proposed.A dynamic core allocation scheme is proposed considering the platform features.Experimental results show that the whole solution speeds up the encoding process by more than 19 times and implements real time encoding for 720P high definition sequences.
Scalable Video Coding(SVC)algorithm;multi-core processor;temporal layer aligned spatial level parallel coding; dynamic Slice partition;parallel loop filter;dynamic core allocation
针对SVC(Scalable Video Coding)视频编码算法的高复杂度,提出了一种面向TileraGx36多核平台的针对高清视频的SVC并行编码算法。在层间,提出基于时间层对齐的空间层级并行编码;在层内,针对图像变化的多样性,为实现Slice间编码性能的动态均衡,提出了直接根据统计时间的Slice级动态分割方法,并针对依赖性较强的去方块滤波模块实现了多核并行滤波方案。结合平台特点,实现了多核处理器核数的动态分配方案。实验结果表明,整个方案并行加速比超过19,实现了最大分辨率720P视频序列的实时编码。
可伸缩视频编码(SVC)算法;多核处理器;时间层对齐的空间层级并行;动态Slice划分;并行滤波;动态核数分配
A
TP391.41
10.3778/j.issn.1002-8331.1211-0174
HUANG Liang.High definition real time SVC encoding based on multi-core processor.Computer Engineering and Applications,2013,49(13):170-174.
国家自然科学基金仪器专项(No.40927001)。
黄亮(1987—),男,硕士研究生,主要研究方向:基于嵌入式平台的多媒体应用。E-mail:huangliangzju@sina.com
2012-11-15
2013-02-28
1002-8331(2013)13-0170-05
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
测控技术(2021年10期)2021-12-21
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
上海公路(2018年3期)2018-03-21
光学精密工程(2016年5期)2016-11-07
电子设计工程(2015年24期)2015-08-26
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
河南科技(2015年8期)2015-03-11
郑州大学学报(理学版)(2013年3期)2013-03-11
