
龙腾Stream流处理器验证
2013-07-19 08:14:42白龙飞樊晓桠孙立超
计算机工程与应用 2013年15期
白龙飞,樊晓桠,张 萌,孙立超
西北工业大学 计算机学院,西安 710129
龙腾Stream流处理器验证
白龙飞,樊晓桠,张 萌,孙立超
西北工业大学 计算机学院,西安 710129
1 引言
VLSI技术的巨大进步使得在单个芯片上集成超过数百万个晶体管以搭建大规模的SoC(System on Chip,片上系统)成为可能,验证工作已成为芯片设计流程中最为关键的瓶颈,大约有70%~80%的设计时间都花费在了功能验证中[1]。巨大的验证工作量使得现在很多的新工具和方法学都把验证作为研究目标,并通过并行化、更高层次的抽象和自动化来缩短验证需要的时间[2]。通过验证语言、硬件描述语言或C等高级语言搭建验证平台是功能验证中最为重要的验证手段。验证平台需要提供各种自动化机制以提高测试案例的功能覆盖率和减少创建测试案例的时间,从而保证验证过程更快地达到收敛。System Verilog[3]是业界新兴的一种硬件描述和验证语言(HDVL),支持受约束随机激励的产生和覆盖率统计分析,其面向对象的编程结构有助于采用事务级的验证和提供验证的可重用性[4]。System Verilog面向对象的编程模型这一特性能够极大地增强验证平台组件的重用能力,利用验证组件组合成的强大验证环境能够满足被验证设计(DUV)的各种必要的测试案例。
SoC设计通常集成了CPU、存储器及其他功能模块,并在硬件上运行相应的嵌入式软件,因此SoC设计的验证工作除了验证硬件设计的实现功能,还需要验证软件与硬件协同工作的兼容性和性能[5-6]。传统的基于RΤL(Register Τransfer Level,寄存器传输级)的软件验证平台由于仿真速度的限制[7],存在着时间开销大、仿真效率低的问题。此外,由于RΤL级仿真忽略了大量的电路实际延迟,其性能分析的评估数据过于乐观。而基于FPGA原型的软硬件协同验证可以快速完成验证并保持周期精确,同时降低了开发风险,避免了由于仿真模型的缺陷而引起大量的芯片故障,极大地提高了SoC设计的验证效率[7-8]。
西北工业大学航空微电子中心对面向流计算的主动适应体系结构进行深入研究,成功设计出了龙腾Stream流处理器。本文通过开发基于System Verilog的覆盖率驱动的自动化验证平台,对流处理器的指令集进行了全面的功能验证,并搭建FPGA原型系统对流处理器的实现功能和性能进行了深入评测。根据在原型系统上的性能评测结果,分析了影响流处理器性能的关键因素,并提出了优化流处理器加速性能的方法。
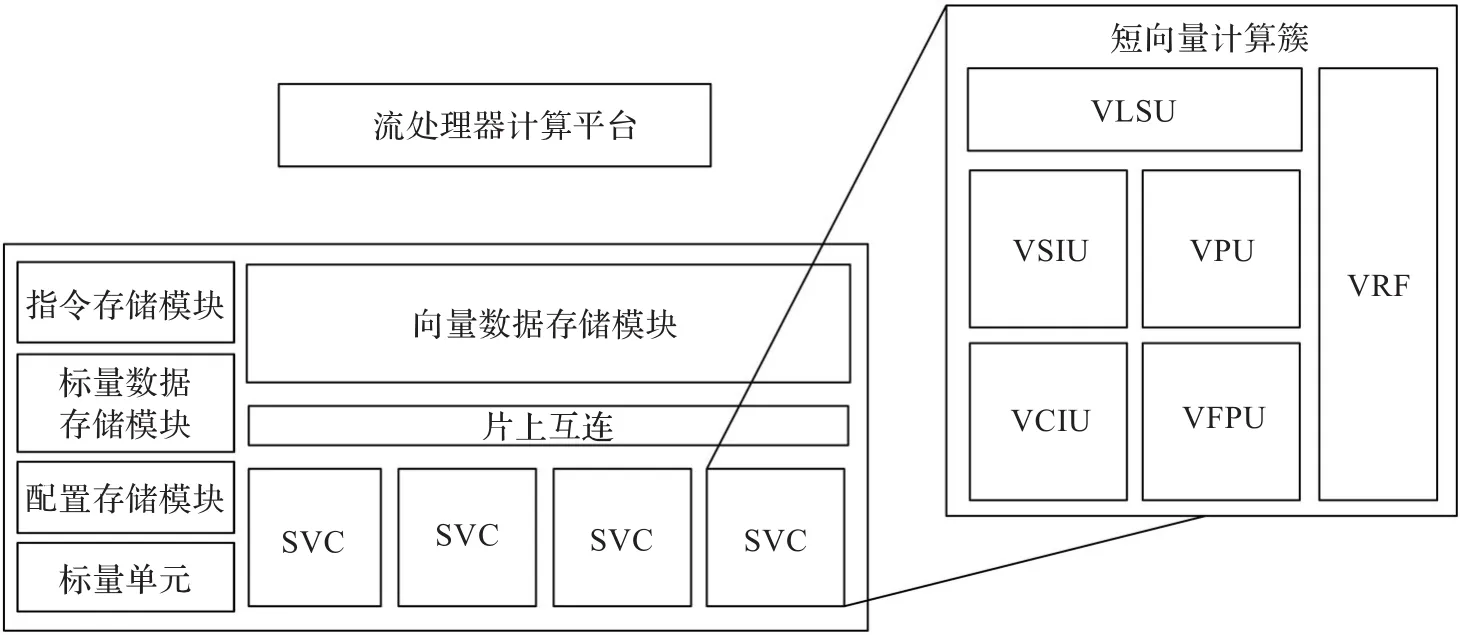
图1 龙腾Stream流处理器计算平台
2 龙腾Stream流处理器
龙腾Stream流处理器[9]是针对具有大量数据并行性、计算密集型的应用而设计的面向于短向量的适应性流体系结构,以多套单指令多数据模式的短向量簇实现程序的并行加速。
流处理器以层次化的片上流存储体系捕获数据局部性的,其存储结构分为三级:片外存储器、片上局部存储器和寄存器文件。主控核组织数据流并通过总线传到片上局部存储器中,向量指令集中的Load/Store指令将片上局部存储器中的数据搬移到寄存器组中,计算部件直接从寄存器组中取数据。
流处理器计算平台包含短向量计算簇、标量单元以及局部存储模块,如图1所示。
2.1 短向量计算簇
短向量计算簇(Short Vector Cluster,SVC)是实现计算平台的主要计算部件,主要包括向量Load/Store单元(VLSU),向量简单定点计算单元(VSIU),向量复杂定点计算单元(VCIU),向量置换单元(VPU),向量浮点计算单元(VFPU),向量寄存器文件(VRF)。计算平台集成4套短向量计算簇,每套短向量计算簇拥有各自独立对应的向量寄存器文件,以SIMD方式执行操作。
2.2 标量单元
标量单元(Scalar Unit)包含32个标量寄存器,1个条件寄存器和ALU单元。其主要功能是少量的标量运算以及独立的标量访存,辅助短向量计算簇实现循环操作,同时为计算簇的访存单元计算有效地址提供支持。
2.3 局部存储模块
局部存储模块(Local Memory)为计算平台提供指令和数据的存储空间,共有四种不同的存储模块,分别为指令存储模块(Instruction Memory)、标量数据存储模块(Scalar Data Memory)、配置存储模块(Configuration Memory)和向量数据存储模块(Stream Memory)。指令存储模块存储主控核传递过来的指令;标量数据存储模块存储标量数据并供标量单元使用;配置存储模块存储用户写入的控制数据,主要功能是写入程序的起始地址和结束地址,控制计算单元的执行与结束;向量数据存储模块主要存储提供给SVC计算部件的向量数据。
3 流处理器的指令集验证
龙腾Stream流处理器的指令集采用RISC设计原则,指令长度为32位,指令格式规整,实现了152条向量指令和10条标量指令。向量指令完成简单和复杂的定点运算、浮点乘加和其他一些向量数据处理功能。标量指令主要用于循环控制、标量访存以及向量LSU指令中的标量操作。流处理器的指令格式如图2和图3所示。
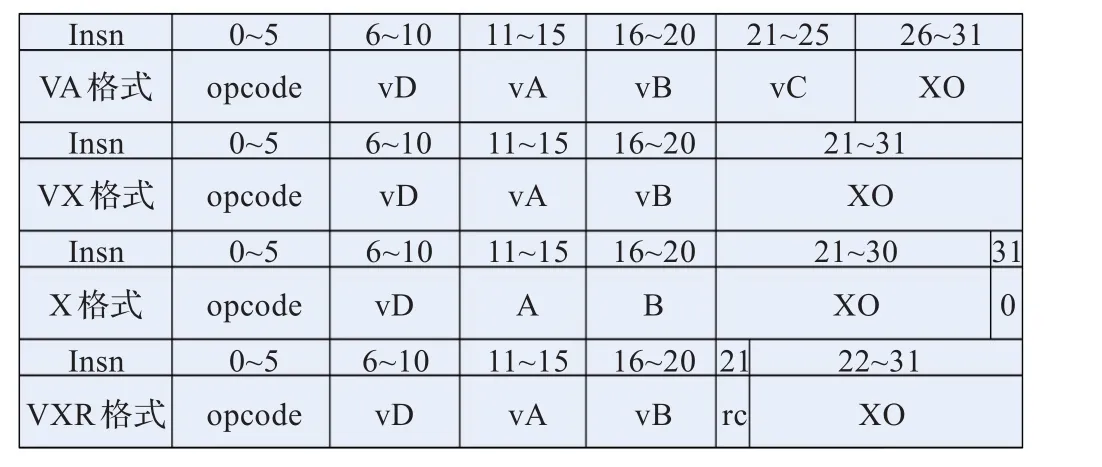
图2 向量指令格式
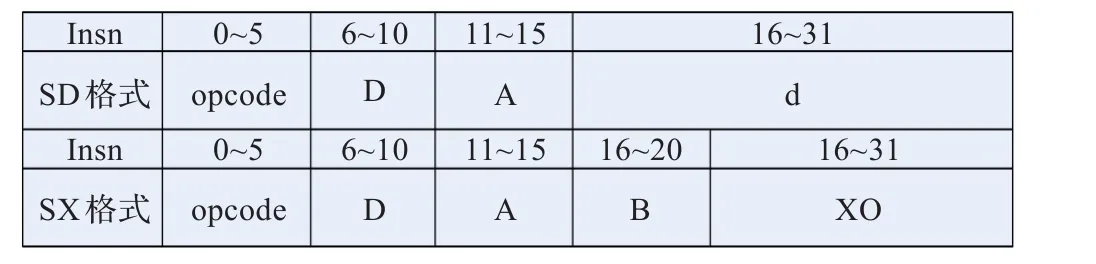
图3 标量指令格式
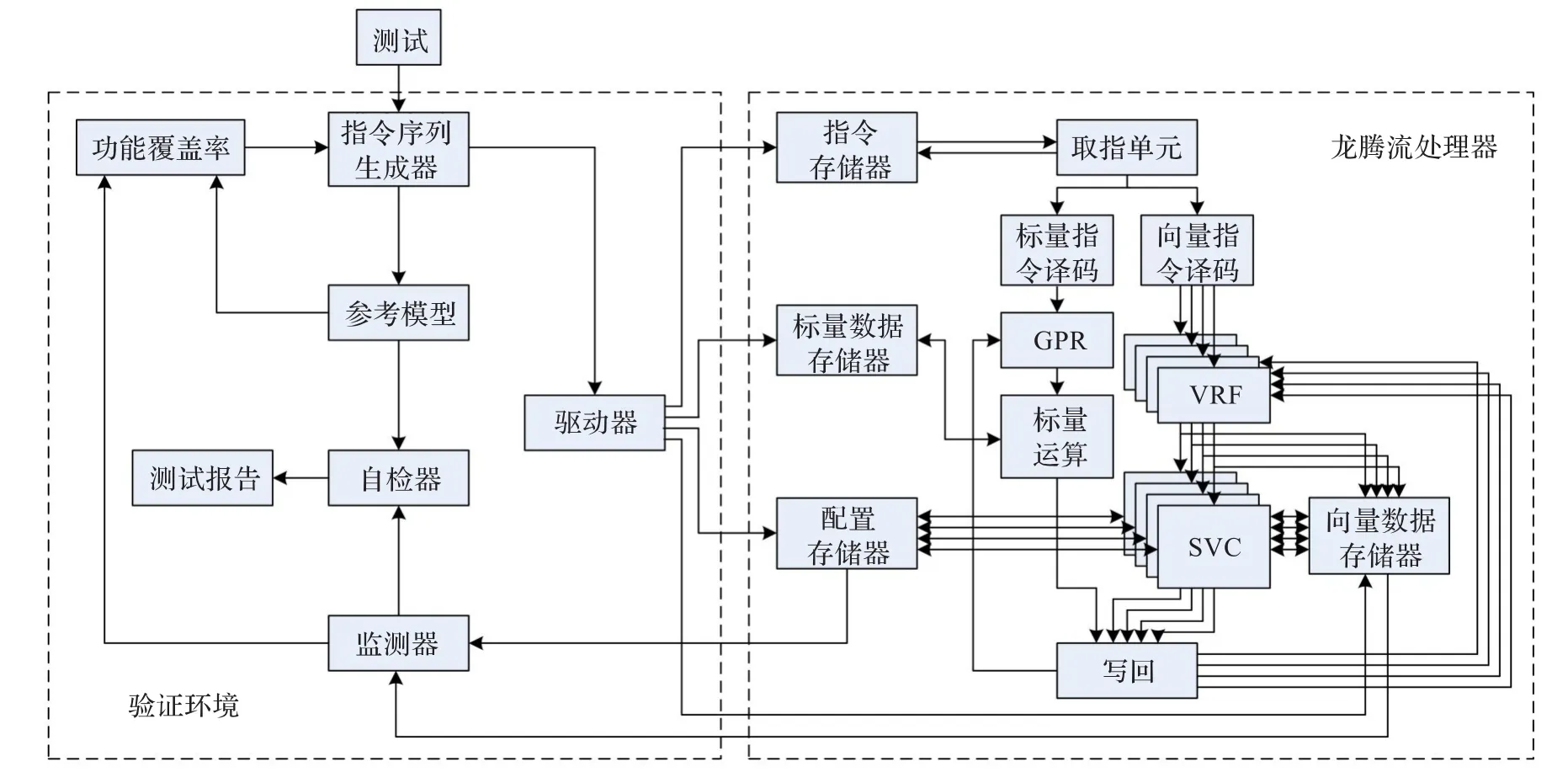
图4 流处理器验证平台结构
本验证采用基于System Verilog的高级验证方法学[10]搭建覆盖率驱动的自动化验证平台,完成流处理器指令集的功能验证。流处理器验证平台的结构设计如图4所示。验证平台为分层次结构,每个层次给其上层或测试案例提供服务,并通过抽象隐藏低层次细节[10-12]。
验证平台主要包括指令序列生成器、驱动器、监测器、参考模型、自检器以及功能覆盖率分析等组件。发生器使用蓝图模式[11]产生一条受约束的随机指令,将其发送给参考模型得到期望响应并回调给自检器,同时通过Mailbox发送到驱动器。驱动器将指令激励发送给DUV,监测器检测到流处理器运行结束后将接收到的实际响应回调给自检器,并通知发生器生成下一条指令激励。自检器对期望响应和实际响应进行比较后输出测试报告。
3.1 发生器
该验证平台要完成流处理器实现的152条向量指令和10条标量指令的验证。考虑到指令集中指令的操作码并不完备,且指令格式也不一致,完全随机的生成方式需要排除掉大量非法指令,受约束的随机生成方式则要求编写大量的约束条件。因此考虑将操作码和操作数分开随机生成,再根据指令类型封装成完整的指令激励。本文将待测指令的操作码存入指令数组,通过约束边界随机生成数组索引得到指令操作码。指令中的操作数及对应寄存器内容的边界较为规整,因此采用受约束的随机方式生成。
所有约束使用带有范围变量的inside运算符和权重变量的dist操作符来参数化约束条件,不需要手动修改约束验证平台便可改变指令发生器的激励产生行为。指令类中inside和dist约束的操作码索引的生成按若干段均匀分布,操作数对应寄存器内容的生成分布按待验证的指令功能点划分,比如加减法指令溢出、浮点指令非法操作等异常情况。
3.2 驱动器
流处理器的指令集按操作数数目可分为四类,如表1所示。驱动器根据指令类别分情况配置流处理器的四个存储模块,实现指令激励的驱动。

表1 流处理器指令分类表
向量指令驱动的处理步骤为:(1)通过对标量数据存储模块进行写操作,设定待测指令四个操作数的存放地址;(2)将源操作数写入向量数据存储模块;(3)组织指令,在待测指令前安排Load指令将源操作数装入向量寄存器,其后安排Store指令将向量寄存器中的执行结果存储到向量数据模块;(4)将组织好的指令序列写入指令存储模块;(5)写配置存储模块设定流处理器执行的指令序列的起始与结束地址;(6)写配置存储模块启动流处理器进入工作状态。
驱动Load/Store指令时需额外考虑目的操作数/源操作数的存放地址,以避免和源操作数/目的操作数的地址发生冲突。
3.3 监测器
由于不同类型指令的执行结果存放位置不同,因此监测器需要根据指令类型设定读取地址。
监测器首先从与发生器相连的Mailbox中读取指令激励,根据指令索引判断指令类型并设定读取指令执行结果的地址。通过监视配置存储模块的处理器状态寄存器,在流处理器执行结束后读取指令执行结果并回调给自检器,同时通知发生器该指令执行完毕。
3.4 自检查结构
本验证平台的自检查结构采用基于参考模型的黑盒验证手段。如图5所示,激励同时施加给DUV和参考模型,参考模型动态预测期望响应,比较函数将期望响应与实际响应进行比较。
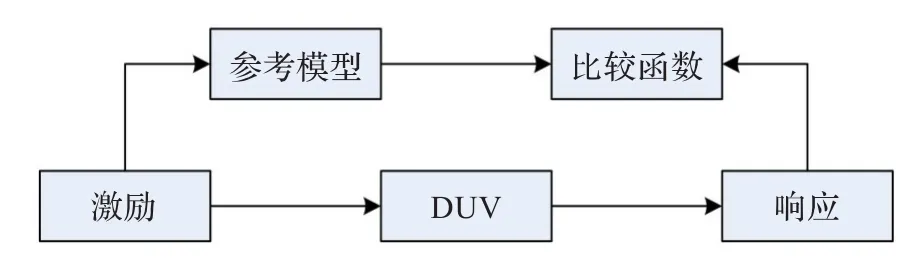
图5 验证平台的自检查结构
本验证平台的参考模型用C语言实现,通过直接编程接口(DPI)[3]将其集成到System Verilog验证环境中。参考模型根据指令激励的索引调用相应的执行函数得到期望响应。参考模型的期望响应输出与DUV的实际响应输出之间的延迟不一,需要自检器对其周期匹配后再进行比较。本文先将参考模型输出的期望响应保存,在监视器得到实际响应后调用比较函数进行比较,并输出测试报告。
3.5 功能覆盖率
由于本验证平台是对流处理器的指令集进行功能验证,因此功能覆盖率的分析主要关注指令类型及其功能点的覆盖,即指令集中的所有指令及其异常情况是否全部生成并验证。
覆盖组使用cross结构记录操作码索引和操作数对应寄存器内容覆盖点的组合值。验证环境的总体覆盖率计算由所有简单覆盖点和交叉覆盖点的命中情况决定,而本验证平台的覆盖率目标仅由交叉覆盖率反映,因此将各个覆盖点的覆盖率权重置为零,以防止总体覆盖率被错误地提高。操作码索引覆盖点的每个值对应一个仓,寄存器内容覆盖点则按待验证指令的功能点创建仓,并使用ignore_bins结构清除掉不需要关注的操作码索引和寄存器内容组合对应的交叉仓。
覆盖率分析器通过对参考模型输出和监测器接收到的响应数据进行采样,实时统计覆盖组的功能覆盖率及各功能点的命中情况,并根据分析结果动态调整指令生成器中约束条件的范围和权重。通过从功能覆盖率到生成器的反馈使验证过程自动集中在覆盖率空间中未被覆盖的区域,最终达到指令类型及其功能点全覆盖的目标。
通过分析覆盖率报告修改随机约束或人工编写定向测试激励可以提高验证的覆盖率,但需要测试人员的实时干预。改变随机种子并添加到回归测试包的方法在不同版本仿真器和约束解释器中重用验证平台时会出现问题,使用相同的种子可能生成不同的激励,覆盖率漏洞会因为激励的不同而不同。本文实现的覆盖率自动反馈机制不仅减少了人工的干预和工作量,而且使得验证平台在移植到不同仿真软件上时具有良好的通用性。
实验分别使用VCS和Questasim仿真软件运行验证平台,均获得了100%的功能覆盖率,表明验证平台具有良好的可移植性。验证平台共检测出23个bug(浮点指令:14个,置换指令:8个,简单定点指令:1个)。同原有的功能仿真验证平台相比,本验证平台大大提高了验证效率和覆盖率,如表2所示。
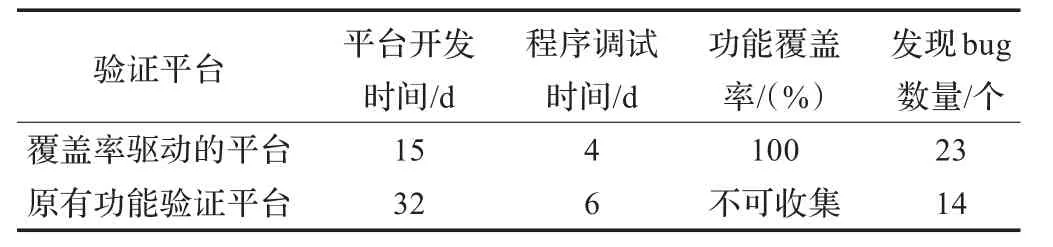
表2 覆盖率驱动的验证平台同原有功能验证平台比较
4 流处理器的性能验证
龙腾Stream流处理器的FPGA原型验证系统[13]的结构如图6所示。流处理器通过Avalon Slave总线连接到基于Nios II处理器的硬件系统中,其运行受到主处理器的控制。标量主处理器Nios II承担流处理过程中的控制和数据的组织传递,包括启动计算平台,控制传入到计算平台的输入数据,对计算平台的运行结束信号进行检测,执行流级程序。流处理器原型作为协处理器实现流应用的运算加速。
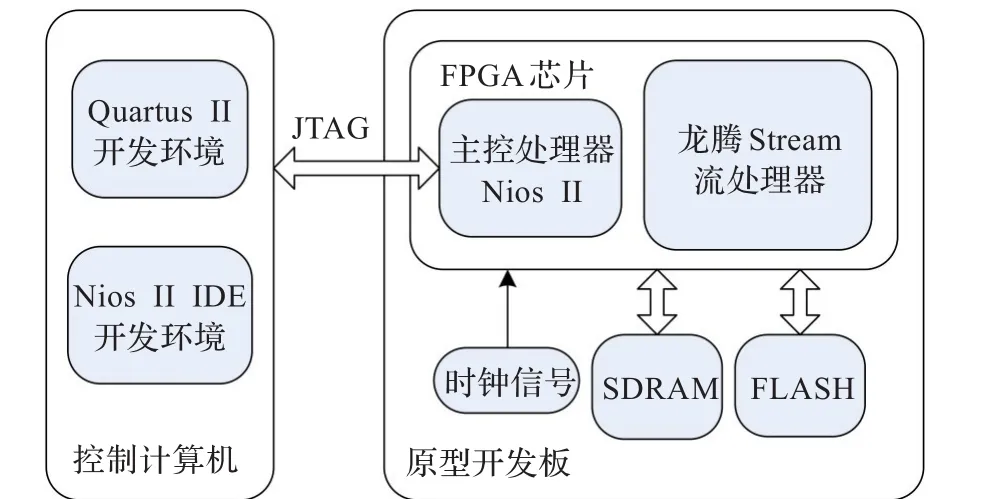
图6 流处理器FPGA验证平台
FPGA原型验证系统通过运行测试程序集完成流处理器实现功能及性能的评测工作。测试程序集选用典型的流应用实例,包含了传统的图像处理应用、常用的数字信号处理应用以及通用计算与科学计算。根据流处理器原型系统设计测试程序的软件架构,对应用实现并行化流编程。在测试程序中加入串行的参考程序,以验证FPGA原型系统的正确性。原型系统的性能评测环境如表3所示。

表3 性能评测环境
性能评测以通用计算架构作为对比,分别对流应用程序进行测试,精确统计程序执行的周期数。通过比对运行结果,并行程序和参考的串行程序完全一致,从而验证了流处理器实现功能和FPGA原型系统的正确性和可靠性。图7列出了流处理器原型系统相对于MPC8270的加速比,大部分流应用均在流处理器原型系统上取得了可观的加速效果,平均加速比可达15.9。

图7 流处理器原型系统相对于MPC8270的加速比
造成各流应用加速效果差异的主要原因是核级程序的并行处理宽度不同,向量点积、FIR、Laplace变换、均匀量化、DCΤ和FFΤ的并行宽度均为16,矩阵乘法的并行宽度为32,而中值滤波的并行宽度为64,所以中值滤波和矩阵乘法均取得了不错的加速效果。
流应用的核级执行时间所占比例也是影响加速效果的一个重要因素。测试程序的核级执行时间所占比例如图8所示。核级执行时间比例较大的应用容易获得较好的加速效果,比如DCΤ、矩阵乘法和中值滤波。
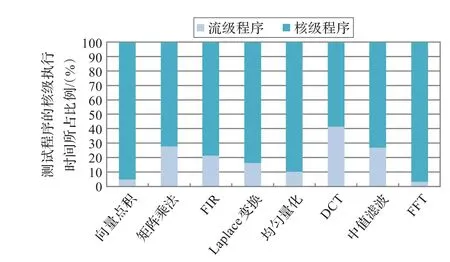
图8 测试程序的核级程序执行时间所占比例
实验结果发现,FFΤ算法的加速性能并不理想。该算法每一级的蝶形运算在核级程序中通过短向量簇并行加速完成,但由于流体系只适合处理规则的流数据,每一级运算的数据置换操作则需要标量主处理器来承担。尽管核级程序具有极大的并行数据宽度,但流存储器对总线的带宽仅有32位,这使得大量的程序执行时间耗费在了数据来回迁移的过程中,大幅降低了核级程序执行时间所占的比例,从而制约了加速性能的发挥。
主协处理器异构核间相差巨大的数据带宽已成为制约流处理器系统性能的瓶颈,开发具有更高带宽的片上数据总线或数据传输方式是提升流处理器计算性能的关键。因此,对流处理器结构的优化可以从两个方面考虑,一是通过支持组间交叉存储和数据流索引访问,为随机访存提供强大的数据带宽;二是在片上局部存储器和片外存储器中间加入DMA模块,提高数据在主控处理器和流处理器之间传输的速度。
5 结束语
本文通过开发基于System Verilog的覆盖率驱动的自动化验证平台,对龙腾Stream流处理器的指令集进行了功能验证,提高了验证的效率和覆盖率,验证平台具有良好的重用性和可移植性。搭建FPGA原型系统对流处理器的实现功能和系统性能进行了评测,并根据实验结果分析了影响流处理器性能的关键因素,并提出了优化流处理器结构的方法。未来将在可靠数据带宽、多粒度并行和编程模型等方面作深入研究,进一步改进流处理器原型系统。
[1]Mulani P D.SoC level verification using System Verilog[C]// Second International Conference on Emerging Τrends in Engineering and Τechnology,Nagpur,2009.
[2]Bergeron J.Writing testbenches:functional verification of HDL models[M].2nd ed.New York:Springer,2003:3-4.
[3]SystemVerilog Standards Committee.SystemVerilog 3.1a language reference manual[R/OL].(2004-03-04).http://www. eda-stds.org/sv.
[4]钟文枫.System Verilog与功能验证[M].北京:机械工业出版社,2010:22-23.
[5]Huang Xu,Liu Lintao,Li Yujing,et al.FPGA verification methodology for SiSoC based SoC design[C]//International Conference on Electron Devices and Solid-State Circuits,Τianjin,2011.
[6]Chen Wenwei,Zhang Jinyi,Li Jiao,et al.Study on a mixed verification strategy forIP-based SoC design[C]//Seventh IEEE CPMΤ Conference on High Density Microsystem Design and Packaging and Component Failure Analysis,Shanghai,2005.
[7]Nakamura Y,Hosokawa K,Kuroda L,et al.A fast hardware/ software co-verification method for system-on-a-chip by using a C/C++simulator and FPGA emulator with shared register communication[C]//41st Design Automation Conference,San Diego,2004.
[8]Lin Yifan,Zeng Xiaoyang,Wu Min,et al.New methods of FPGA co-verification for System on Chip(SoC)[C]//Sixth International Conference on ASIC,Shanghai,2005.
[9]开耀文.多核流处理器原型系统设计[D].西安:西北工业大学,2012.
[10]Bergeron J,Cerny E,Hunter A,et al.Verification methodology manual for SystemVerilog[M].New York:Springer,2005:1-280.
[11]Spear C,Τumbush G.SystemVerilog for verification:a guide to learning the testbench language features[M].3rd ed.New York:Springer,2012:1-22,280-284,323-360.
[12]Bergeron J.Writing testbenches using SystemVerilog[M].New York:Springer,2006:279-331.
[13]张宇轩.流处理器演示系统设计与实现[D].西安:西北工业大学,2012.
[14]S2C dual stratix-4 ΤAI LM hardware reference manual[R]. California:S2C Inc.,2010.
[15]MPC8280 PowerQUICCII family reference manual[R].Τexas:Freescale Semiconductor,Inc.,2005.
BAI Longfei,FAN Xiaoya,ZHANG Meng,SUN Lichao
School of Computer Science,Northwestern Polytechnical University,Xi’an 710129,China
Τhe improvement of chip design complexity urgently needs advanced methodology to cope with the huge workload of verification.Τhis paper presents a method for functional verification of the“Longtium Stream”processor instruction set by constructing an automatic coverage-driven verification platform.Τhe experimental results show that the method improves the efficiency and functional coverage of verification and enhances the reusability and portability of the verification platform.Τhis paper builds a FPGA prototype system to evaluate the functionality and performance of the Stream processor,and proposes optimization methods for accelerating its performance.
Stream processor;instruction set verification;System Verilog;Field Programmable Gate Array(FPGA)prototype verification
芯片设计复杂度的提高迫切地需要先进的方法学以应对巨大的验证工作量。通过开发基于System Verilog的覆盖率驱动的自动化验证平台,对龙腾Stream流处理器的指令集进行了功能验证。实验结果表明,该验证平台提高了验证效率和功能覆盖率,具有良好的重用性和可移植性。搭建FPGA原型验证系统对流处理器的功能和系统性能进行了评测,并提出了优化流处理器加速性能的方法。
流处理器;指令集验证;System Verilog;现场可编程门阵列(FPGA)原型验证
A
ΤP303
10.3778/j.issn.1002-8331.1304-0160
BAI Longfei,FAN Xiaoya,ZHANG Meng,et al.Verification of“Longtium Stream”processor.Computer Engineering and Applications,2013,49(15):65-69.
国家高技术研究发展计划(863)(No.2009AA01Z110);教育部博士点基金(No.20116102120049)。
白龙飞(1988—),男,硕士研究生,主要研究领域为计算机系统结构;樊晓桠(1962—),男,博士,教授,主要研究领域为计算机系统结构;张萌(1978—),男,博士,讲师,主要研究领域为计算机系统结构;孙立超(1989—),男,硕士研究生,主要研究领域为计算机系统结构。E-mail:bailongfei@mail.nwpu.edu.cn
2013-04-11
2013-05-27
1002-8331(2013)15-0065-05
◎网络、通信、安全◎
猜你喜欢
互联网周刊(2023年22期)2023-12-04 16:27:17
今日农业(2022年15期)2022-09-20 06:54:16
今日农业(2021年21期)2021-11-26 05:07:00
Biomedical and Environmental Sciences(2020年1期)2020-02-29 05:46:54
中国电子科学研究院学报(2019年8期)2019-12-23 10:39:50
计算机与现代化(2018年2期)2018-03-13 07:23:35
生态毒理学报(2016年2期)2016-12-12 03:52:27
科技与创新(2016年12期)2016-06-25 12:46:56
西南交通大学学报(2016年6期)2016-05-04 04:13:05
数学物理学报(2014年3期)2014-03-11 18:34:26
