
组合结构特征的自由手写体数字识别算法研究
2013-07-11 09:36陈军胜
计算机工程与应用 2013年5期
陈军胜
宁夏大学 机械工程学院,银川 750021
组合结构特征的自由手写体数字识别算法研究
陈军胜
宁夏大学 机械工程学院,银川 750021
在过去的几十年,随着数字化、信息化在社会生活方方面面的推广及普及,手写体的识别成为模式识别的研究热点。数字手写体因其在邮政编码、统计报表、财务报表、银行票据等方面的广泛使用,它的自动识别更是受到了人们的广泛关注。但是很多方法只是停留在理论研究之中,实际生活中手写体数字因个人书写风格的不同而存在字符变形多样的问题,造成现有算法在手写体识别中识别率底、稳定性差、鲁棒性不足等多方面的问题。研究高性能的手写体数字识别算法仍然是一个具有相当挑战性的课题。
手写体数字的识别建立在特征提取及比较的基础之上。按照提取字符特征的不同,现有的数字手写体识别算法大体上可以分为两类:一类是基于结构特征的手写体数字识别算法[1-3]。它们通过识别字符图像内部包含的凹陷区特征、轮廓特征结构突变点特征等基元,采用模板匹配的方式实现手写体数字的自动识别。这类方法能够直观地描述字符的结构,但是存在着对字符形变及噪声缺乏鲁棒的问题;另外一类是基于统计特征的手写体数字识别算法[4-8]。这类算法基于对大量样本的表征、变换和学习,通过估计不同样本类别的特征空间分布训练相应的分类器,并利用这些分类器对未知模式进行分类。当训练样本选取得足够充分时,这类方法能够具有很好的识别能力;然而,充足样本的构造却成为限制这类方法发展的主要瓶颈。
综合分析手写体数字识别的应用需求及现有的手写体数字识别算法,会发现手写体数字识别具有以下特点:(1)手写体数字书写自由,个人书写风格千差万别,造成手写体数字形式变形多样的特点。这就决定了在手写体数字识别中不存在一种简单、单一的方案能够达到很高的识别率。(2)手写体数字识别正确率要求高。在实际应用中,手写体数字往往会涉及到财会、金融等领域,因而,其识别准确率要求更高。(3)手写体识别困难度高,不像文字,数字之间往往没有上下文关系,这就造成在数字识别过程中无法通过上下文间的指导信息辅助完成手写体数字的自动识别,而必须完全独立地对各个数字进行识别。
针对手写体识别的特点及要求,分析现有算法存在的问题,本文提出了一种基于组合结构特征的手写体数字识别算法。该算法能够通过扩展的字符结构特征识别算法自动、鲁棒地提取手写体数字中的诸多结构特征,并综合使用端点、分叉点、横线等特征构建决策树,实现了手写体数字的自动识别。实验结果显示,该方法的识别率明显优于其他传统方法。
1 方法概述
本文提出的基于组合结构特征的手写体数字识别算法通过分析字符图像像素间的关系自动提取端点、分叉点等结构特征,从而实现手写体的自动识别。在介绍整体算法之前,首先给出基本概念。
1.1 基本概念
定义1(端点)在二值图像中,端点就是连接点为1的点,即在它的九邻域中只有一个点与它相连。图1所示的8幅图像中位居图像中央的点均为端点。
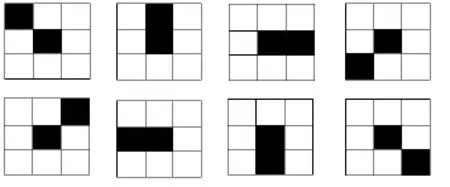
图1 端点的九邻域图
定义2(三交叉点)在二值图像中,三交叉点起连接作用,是负责连接三条不同方向的线且连接数为3的点。在三交叉点的九邻域内有三个像素点与它相连并构成一定角度。图2所示的16幅图像中位居图像中央的点即为三交叉点。
定义3(四交叉点)在二值图像中,四交叉点其连接作用,是负责连接四条不同方向的线且连接数为4的点。在四交叉点的九邻域内有四个点与它相连并构成一定角度。图3所示的两幅图像中位居图像中央的点即为四交叉点。

图2 三交叉点的九邻域图
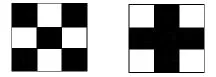
图3 四交叉点的九邻域图
1.2 整体框架
图4所示为基于组合结构特征的手写体数字识别算法的整体框架,主要包括:
(1)手写体数字图像的预处理。
(2)手写体数字图像结构特征的提取,通过本文提出的扩展字符结构特征识别算法鲁棒、准确地识别手写体数字图像中包含的结构特征。
(3)基于决策树的手写体数字自动识别,通过组合本文提取的结构特征构造决策树实现自由手写体数字图像的自动识别。
2 手写体数字图像的预处理
手写数字识别时,首先将纸上的字符,经光电扫描产生模拟电信号,再经模数转换把带灰度值的数字信号输入计算机。纸张厚度、颜色、油墨深浅、印刷或书写质量都要造成字形畸变,产生污点、飞白、断笔、交连等干扰。输入设备的鉴别率、线形度、光学畸变也要产生噪声。所以,在单个字符识别之前,要对带有随机噪声的字符数字信号进行预处理。具体地,预处理包括灰度化、二值化、平滑、细化等步骤。
2.1 灰度化
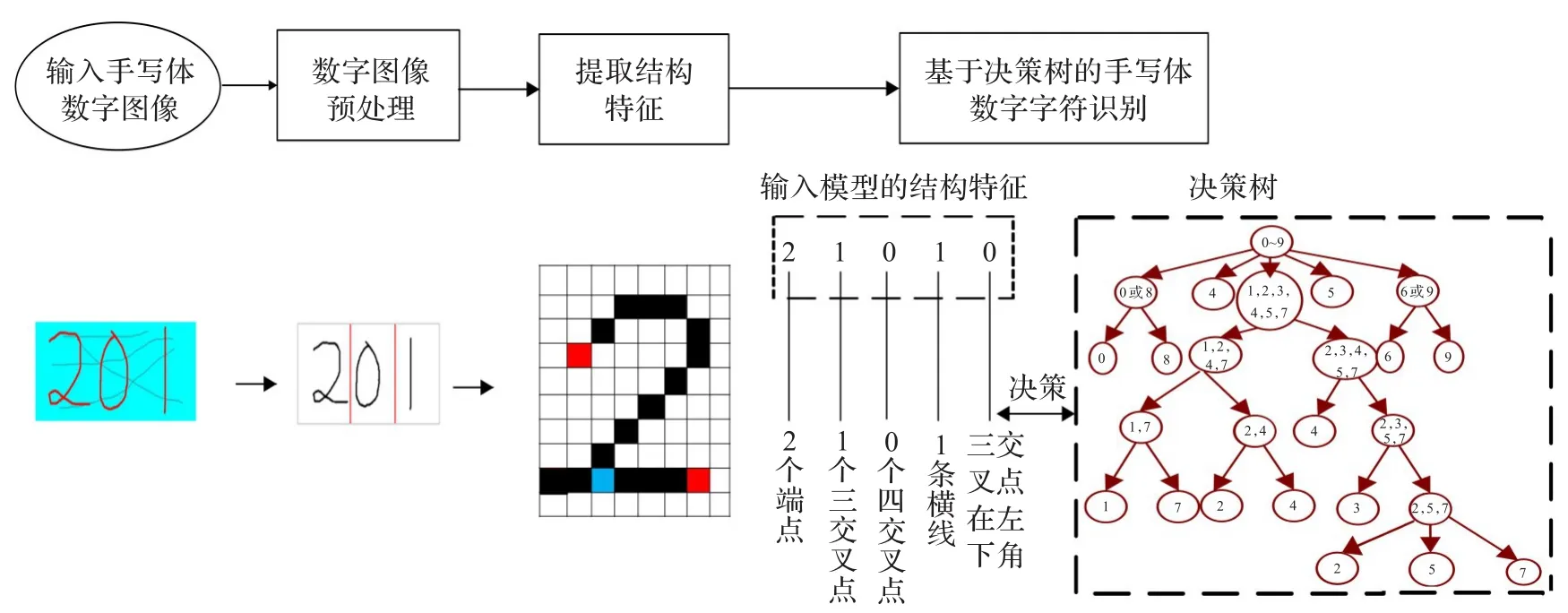
图4 基于组合结构特征的手写体数字字符识别算法整体框架图
手写体数字的颜色并不影响其对应的字符,而彩色图像又占有大量的空间,影响识别效率及效果。因而,在识别之前,首先要对图像进行灰度化处理,以过滤掉与识别信息无关的数据。研究表明:给定一个24位的BMP图像,若其每个像素通过R(红色)、G(绿色)、B(蓝色)三个颜色分量共同表达,则基于人眼对颜色敏感程度分析,可使用:
RGB=B×0.114+G×0.587+R×0.299 (1)的灰度化公式来进行灰度化。灰度化的效果如图5所示。
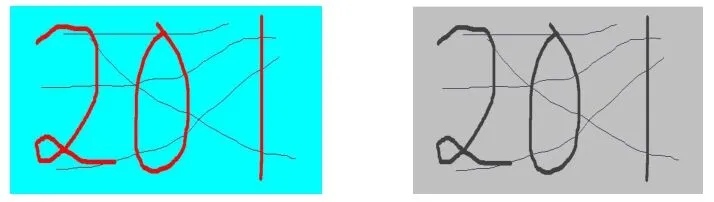
图5 彩色手写体数字位图的灰度化
2.2 二值化
为进一步减少图像的数据量,使其更加便于图像的识别操作,在得到数字字符的灰度化图像后,需对灰度图像进行二值化操作。二值化的一般方法是确定一个灰度值,即阈值x,将灰度值小于x的像素设为白色,将灰度值大于等于x的像素设为黑色。因为手写体字符图像的前景色和背景色为图像中存在最多的两种灰度颜色,因而图像的灰度直方图中会各形成一个波峰,将两波峰之间的波谷作为阈值,即可有效实现图像的二值化操作。为此,本文中,为保证阈值确定的合理性,利用灰度直方图确定阈值并实现二值化。图6给出了图5所示灰度图像的二值化结果。
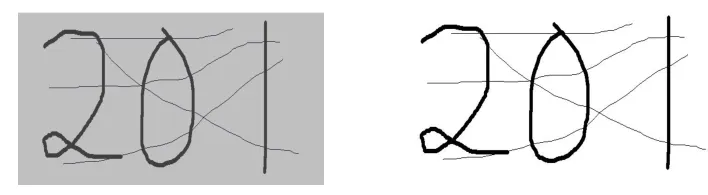
图6 灰度图像的二值化
2.3 平滑处理
为消除手写体图像中的噪声,需进一步对手写体图像进行平滑去噪处理。均值滤波、中值滤波、空间与低通滤波是图像平滑处理中较为常用的滤波方法。鉴于在一定条件下,中值滤波可以克服线性滤波器所带来的细节模糊问题,而且对滤除脉冲干扰及图像扫描噪声非常有效。本文选用7×7的滑动窗口对二值化图像进行中值滤波。图7给出了利用中值滤波光滑去噪后的字符图像。
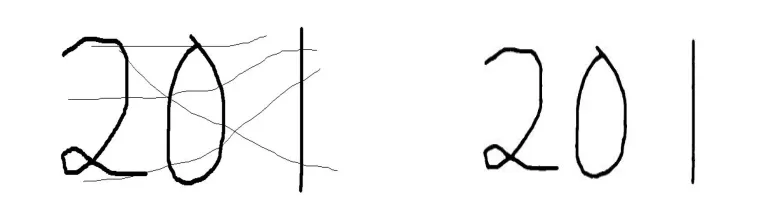
图7 利用低通滤波对二值图像进行光滑去噪

图8 单行字符图像在X、Y方向上的投影
2.4 字符分割
字符识别的基本对象是单个字符,在进行字符识别之前,需对光滑去噪后的图像进行分割操作,以从多行或多字符图像中获得单个字符。本文中,将通过投影分割的方式来获取单个字符。首先,利用水平投影法获得单行字符图像,此后再以单行字符图像为输入,利用垂直投影法获得单个字符图像。公式(2)(3)分别给出了水平投影及垂直投影的计算公式。

其中,h,w分别是图像的高度和宽度,f(i,j)为图像第i行第j列元素的灰度值,对二值图像为1或0。以图7中平滑去噪后的图像为例,图8给出了利用公式(2)、(3)中sum(i) 和sum(j)随i、j的变化趋势图。由图可见,给定一行字符后,由于字符间独立成块,水平方向之间并无交集,因而,可在对单行图像进行垂直投影后利用投影图像中的空白间隙对字符集合进行分割。图9给出了相应的分割结果。
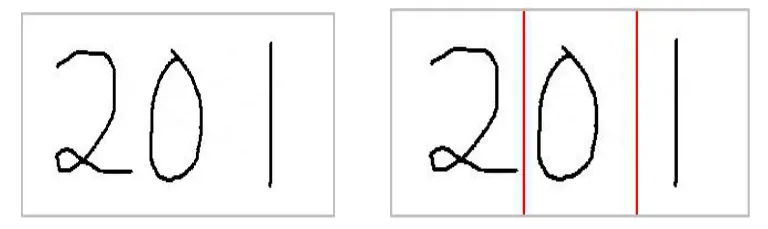
图9 基于垂直投影的图像分割
2.5 字符细化
细化是减少图像信息量并保留图像主要特征的又一预处理操作。为有效提高字符识别的效果和质量,将选用两步腐蚀的方法对字符图像进行细化[9-10]。具体地:第一步,对字符图形进行预腐蚀,将所有腐蚀可去除的像素点标明但不立即去除;第二步,以第一步标注的可去除像素点为基础,选择消除那些消除后不会破坏字符连通性的点,并保留其他点,以确保字符图像的拓扑结构。图10为按照本文算法细化得到的效果图。

图10 字符细化
3 手写体数字结构特征的提取
至此,得到了高质量的字符图像,本章将考虑字符图像的特征提取。由于手写体字符不像印刷体字符那么规范,使用诸如模板匹配的方法需要建立大量的模板库,效率低且识别效果差。而字符结构的某些特征并不因为书写人的不同而发生改变,如数字字符1无论写成怎样,它都会存在两个端点,内部也不会有别的交叉点;数字2无论写成怎样,一般都会有一个交叉点和两个端点的。因而,可以认为无论数字写得如何随意,只要不是非常夸张,特征点信息都是相对稳定的。本文将以预处理后的字符图像为输入提取其字符结构特征,并依据字符结构特征识别数字字符。
3.1 结构特征的提取
不同的数字具有不同的结构特征,如有些数字有两个端点,有些数字没有端点,有些数字有三交叉点,有些数字有四交叉点,而且不同数字特征点的位置也不一样,所以端点和交叉点特征就可以成为判别数字的一个主要特征。本文将利用击中击不中变换来识别数字字符的形状特征。具体地:在击中击不中变换中将结构元素分解成两类,一类定义为前景结构元素E,另一类定义为背景结构元素F,定义如下:B=(E,F),其中E和F的交集为空集。对图像A进行击中击不中变换的定义就是:
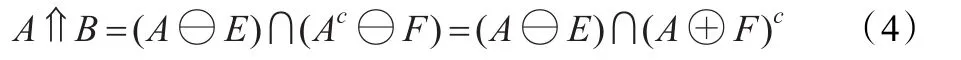
由于E与F的交集为空,构造一个新的结构T,将E中为1的元素定义为1,将F中为1的元素定义为-1,将其他元素定义为0,就可完整地表征出击中击不中的结构元素E 和F。将T定义为发现结构特征的探针,下面将根据不同的待识别结构特征设置相应的探针T。
(1)端点特征。对于有些数字,比如1、7,是存在两个端点的,而0、8则是不存在端点的。所以端点特征是一个简单且重要的判别特征。为有效识别端点信息,以图1给出的8种不同形态的端点为依据,设计了8种不同的探针,如图11所示。以这8个探针对原始图像进行击中击不中操作,很容易识别出字符图像的端点信息,图12给出了一个实验结果。
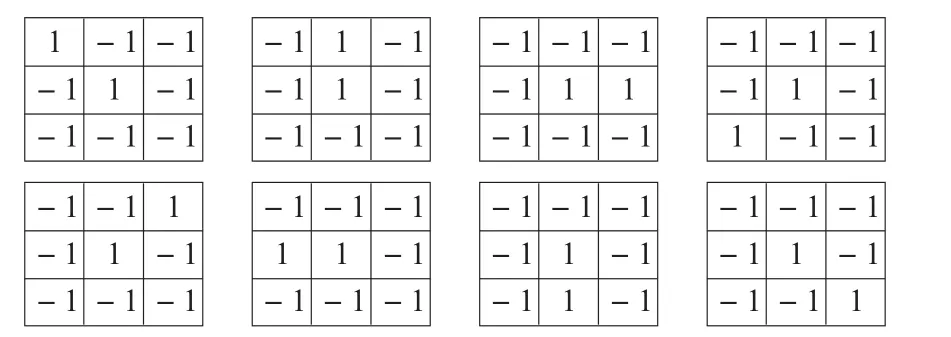
图11 识别端点结构的8种探针

图12 数字字符中端点结构的提取
(2)三交叉点特征。对于有些数字,比如2、3,是存在三交叉点的,而0、1则不存在三交叉点。所以三交叉点特征也是一个比较重要的判别特征。为有效识别三交叉点信息,以图2给出的16种不同形态的三交叉点为依据,设计了16种不同的探针,如图13所示。以这16个探针对原始图像进行击中击不中操作可有效识别出字符图像中包含的三交叉点信息,图14给出了一个实验结果。

图14 数字字符中三交叉点结构的提取
(3)四交叉点特征。对于有些数字,比如4,是存在四交叉点的,而2、7是不存在四交叉点的。四交叉点特征是用以识别数字字符的又一重要判别特征。为有效识别四交叉点信息,以图3给出的2种不同形态的四交叉点为依据,设计了2种不同的探针,如图15所示。以这2个探针对原始图像进行击中击不中操作,很容易识别出字符图像的四交叉点信息,图16给出了相应的实验结果。
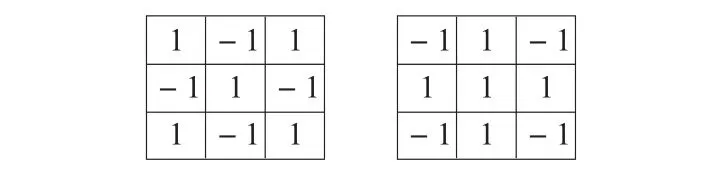
图15 识别四交叉点结构的2种探针
图16 数字字符中四交叉点结构的提取
通过击中击不中操作可有效地识别数字字符中包含的端点、三交叉点、四交叉点等结构点信息。但是,仅仅依赖结构点还难以完成数字字符的有效区别,如数字2,5都包含2个端点和1个三交叉点,且都没有四交叉点。仔细观察会发现,除了这些结构点信息,数字字符中还包含一类结构线信息,横线特征就是一类非常重要的结构线信息。如有些数字,比如2、5、7,是存在横线的,而0、3、8这些数字是不存在横线的;且不同数字中横线的长短和位置也是不一样的,如数字2的横线在下方,而数字5和7的横线都在数字的上方,所以横线特征也是一个比较重要的判别特征,可和特征点结合共同支持字符的识别。为提取横线特征,本文定义了如图17所示的掩膜,通过原始图像同掩膜图像间的卷积标识包含横线特征的点,进而发现横线特征。图18给出了一个相应的实验结果。
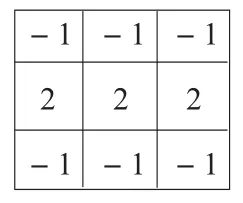
图17 识别横线结构的掩膜
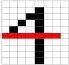
图18 数字字符中横线结构的提取
3.2 伪特征点的去除
理想状况下,提取以上字符特征,并据此进行数字识别就可以了。但是,如表1所示,由于手写体数字字符的随意性,会出现很多标准写法中不该出现的特征,即伪特征点:如标准的数字8中间位置有且仅有一个四交叉点,而这里出现了两个三交叉点;标准的数字3应该包含两个端点,一个三交叉点,而这里多出一个端点,等等。这势必影响以此为基础的字符识别。为此基于字符结构特征的分析,提出了一种伪特征点的去除算法扩展已有的字符结构识别算法以确保特征提取的准确性、鲁棒性。具体地,在一个特定的阈值范围内,如果:
(1)有且仅有2个端点,如表1中的“4”,则去掉2个端点,增加1个三交叉点。
(2)有且仅有2个三交叉点,如表1中的“8”,则去掉2个三交叉点,增加1个四交叉点。
(3)有1个端点、1个三交叉点,如表1中的“3”,则去掉端点,三交叉点不变。
(4)有1个端点、2个三交叉点,如表1中的“9”,则去掉端点和1个三交叉点,只留1个三交叉点。
(5)有2个端点和1个四交叉点,如表1中的“5”,则去掉这2个端点及这个四交叉点,并新增一个三交叉点。
根据以上判别条件,依次判断手写体字符图像中已识别特征的真伪,有效去除手写体字符中的伪特征点,实现手写体字符特征结构的规范化,可以更好地克服手写体数字的随意性,增加算法的鲁棒性。
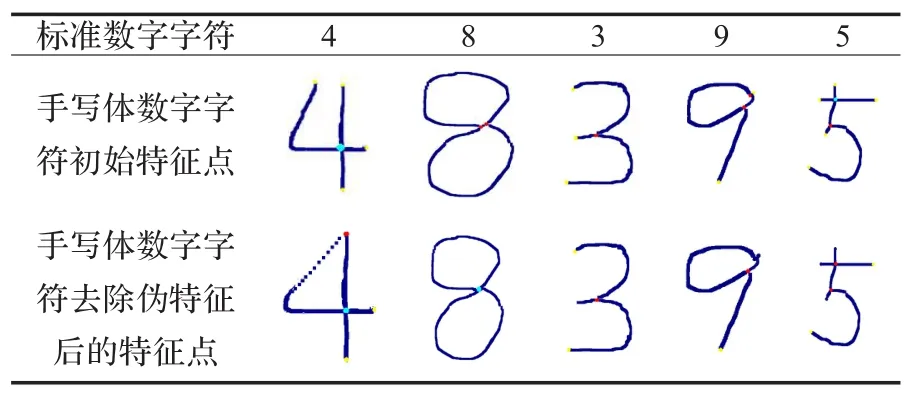
表1 手写体数字字符伪特征说明1)
4 基于决策树的手写体数字自动识别
以上面提取的各类字符结构特征为基础,综合比较它们的区别能力并构造用以识别手写体数字字符的决策树,以实现手写体字符的有效识别。本文中按照端点数为0~4的不同情况将待识别数字字符分为5类,其中:端点数为0的有0、8,端点为1的数字为6、9,端点为2的数字为1,2,3,5,7,端点为3的数字为另一种形态的5,端点为4的是4。进一步,将依次利用三交叉点数、四交叉点数、横线数及其位置细化识别结果。图19给出了本文所构造的决策树。每输入一幅手写体数字字符,依据此决策树,逐条判断,便可实现数字字符的有效识别。
5 系统实现
本文以Matlab为开发平台,设计并实现了基于组合结构特征的自由手写体数字识别系统。系统包括输入模块和图像识别模块两部分。用户可通过输入模块提交手写体数字字符,系统通过图像识别模块依次对图像进行预处理、结构特征提取并依据决策树决策判断得到输出结果。
5.1 测试库的构造
为验证算法的准确性及鲁棒性,选取识别率为评价参数,构建了一个包含1 000份不同输入的测试集。这1 000份输入图像包括数字图片0~9各100份,每份由10人分批次书写,形态各异,轻重不同。表2举例列出了其中的部分手写体字符。
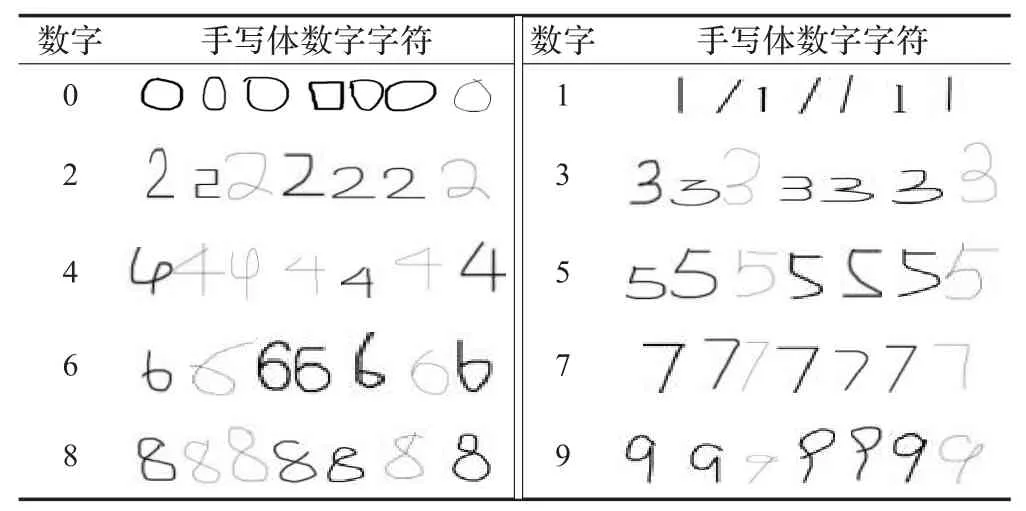
表2 部分手写体数字测试用例
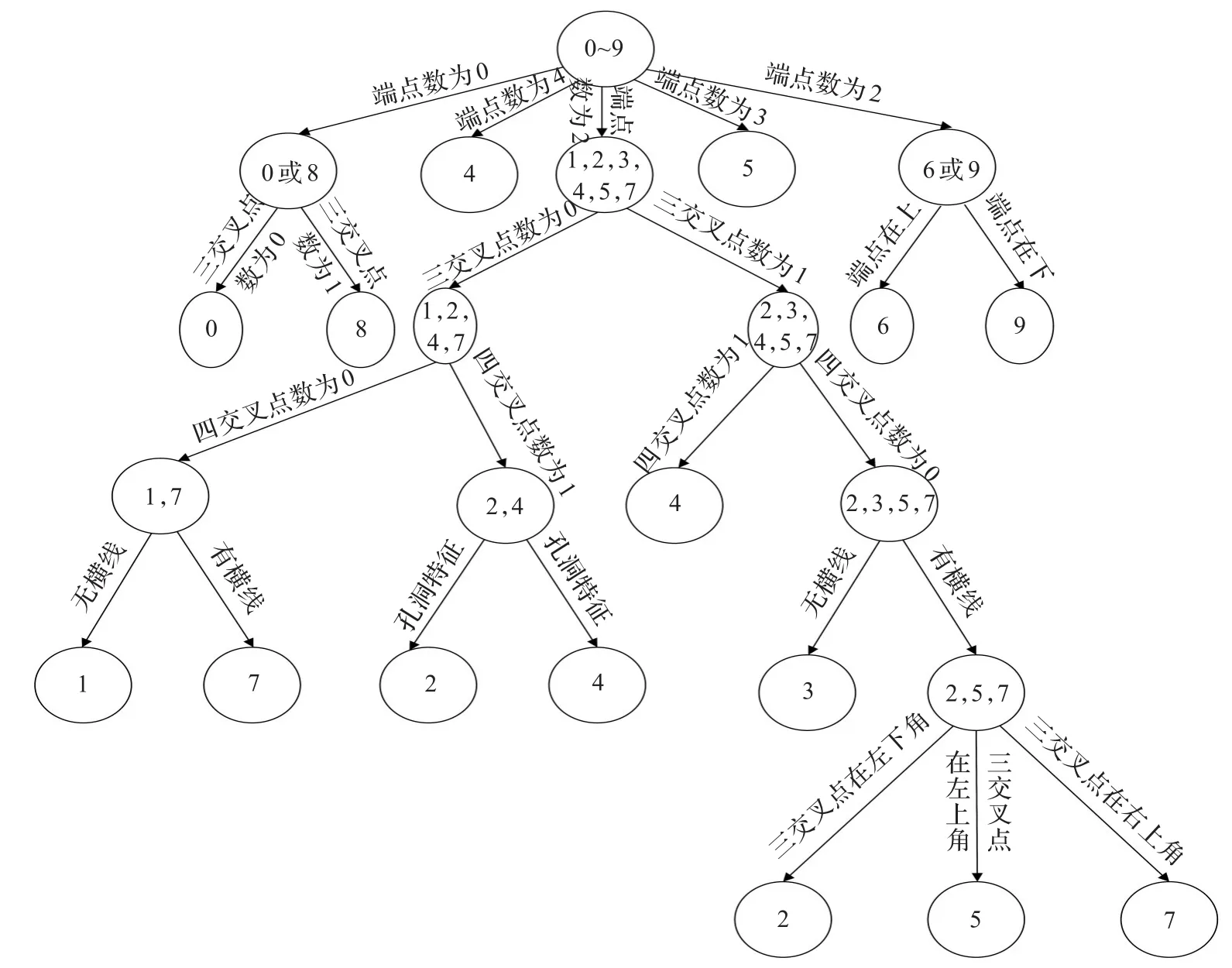
图19 支持手写体数字字符自动识别的决策树
5.2 识别率测试
以本文构造的1 000份手写体输入为测试数据,实现并应用本文算法对0~9的10个数字进行了测试,结果如表3所示。由表3可以看出,针对不同人书写的不同形态的数字,该算法的整体识别率高达97.4%。而针对不同的数字,由于字符形式变化多样性的不同,识别率略有不同。对于数字0和7,该算法的识别率已经达到100%,其他绝大多数数字的识别率也已经达到90%以上。这表明基于组合结构特征的决策树算法具有较高的识别率和较强的鲁棒性。但是不可否认的是,该算法仍存在一些问题,由于算法中综合应用的判别特征还是不够多,造成部分数字,如3、4、5的识别率较低,还有待于改进和完善。

表3 基于组合结构特征的手写体数字识别结果统计 (%)
5.3 算法比较
为了进一步验证算法的有效性,本文实现了基于主分量分析(Principal Component Analysis,PCA)[11]的传统手写体识别算法,并将该方法和本文提出的基于组合特征的识别方法进行了比较。具体地,在基于PCA的自由手写体识别实验中,选用美国国家邮政局数据库中包含的7 291个训练样本为训练样本集,依次计算0~9这10类字符的协方差矩阵Cx,求解其特征值,按特征值大小排序,得到这10个字符对应特征向量的基向量;并依次选取3,6,16三个不同的特征维数d构建其基向量数组u1~ud,依据式(5)对本文构造的数据进行分类判断。则待识别样本属于第i类模式。

实验共进行了100轮,表4是最后的平均识别结果。由实验结果可见,本文提出自由手写体数字识别算法明显优于传统算法,这是因为:(1)字符结构特征相比较统计方法特征而言是一种更能反映数字手写体本质特征向量,能够更好地捕捉自由手写体中不变的属性;(2)本文提出的扩展特征结构特征识别算法能够鲁棒地提取各类字符结构特征,进一步提高算法的识别率;(3)通过组合各类结构特征,本算法能够更好地识别0~9不同的数字字符,因而具有更高的识别率。
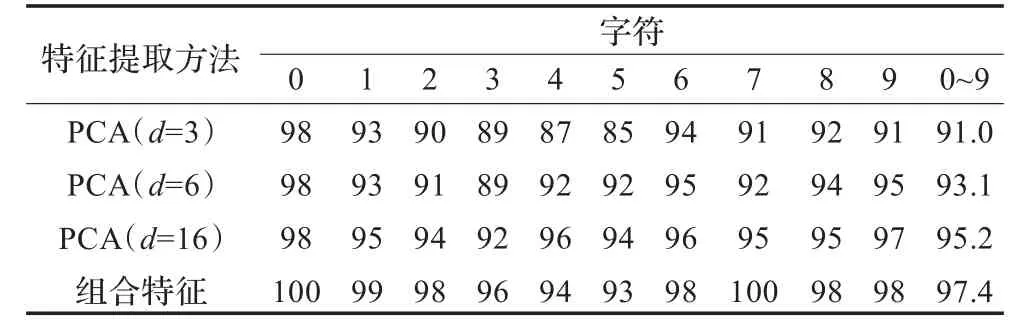
表4 本文算法同PCA算法识别率比较 (%)
6 总结与展望
本文提出一种基于组合特征的自由手写体数字识别算法,给出了自由手写体数字字符图像的预处理方法,设计并实现了手写体数字字符结构特征信息的有效识别算法,并针对性地提出了一种新的伪特征点去除算法扩展本文字符结构特征识别算法,建立了基于组合特征的决策树识别算法,并通过实验验证了该算法的有效性。所提出的字符结构特征构建算法能够准确、稳定地识别自由手写体数字字符的结构特征,为手写体的识别提供底层支持;基于组合特征的决策树自动识别算法能够综合利用多种结构信息完成自由书写体字符的自动识别,保证了算法的准确性及鲁棒性;实验结果表明该算法的识别率高达97.4%,明显优于传统自由手写体识别算法。
为了进一步加强自由手写体数字字符的识别能力及识别效率,下一步将考虑如何扩展并综合应用多种字符结构特征,使其能够有效地改进部分数字,如3,4,5等数字字符的识别率,使得手写体数字字符的整体识别能力都有所提高。
[1]宋曰聪,胡伟.手写体数字识别系统中一种新的特征提取方案[J].计算机科学,2007.
[2]黄涛.模板匹配在图像识别中的应用[J].云南大学学报:自然科学版,2005,27(5A):327-332.
[3]沙腾.基于CCD图像识别通用算法研究[D].杭州:浙江大学,2008.
[4]Li Sanping,Yue Zhenjun.Realization of handwritten numeral recognition system based on PNN with MATLAB[J].Journal of Military Communications Technology,2005,3(26):54-57.
[5]贾厚林.基于人工神经网络的数字识别研究与实现[D].南京:东南大学,2006.
[6]姜文理,王卫,孙正兴.基于决策树的快速在线手写数字识别技术[J].计算机科学,2006.
[7]张伟,王克俭,秦臻.基于神经网络的数字识别的研究[J].微电子学与计算机,2006.
[8]Likforman-Sulem L,Sigelle M.Recognition of degraded handwritten digits using dynamic Bayesian networks[C]//Proceedings of SPIE.San Jose,CA:[s.n.],2007.
[9]张德丰.MATLAB数字图像处理[M].北京:机械工业出版社,2009.
[10]马驷良,马洪波,董险峰.数字图像的一种快速细化方法[J].吉林大学自然科学学报,2001(4):17-19.
[11]芮挺,沈春林,丁健,等.基于主分量分析的手写数字字符识别[J].小型微型计算机系统,2005,26(2):289-293.
CHEN Junsheng
School of Mechanical Engineering,Ningxia University,Yinchuan 750021,China
Because of its large differences in writing style,context-independency and high recognition accuracy requirement, free handwritten digital identification is still a very difficult problem.Analyzing the characteristic of handwritten digits,this paper proposes a new handwritten digital identification method based on combining structural features.Given a handwritten digit,a variety of structural features of the digit including end points,bifurcation points,horizontal lines and so on are identified automatically and robustly by a proposed extended structural features identification algorithm,and a decision tree based on those structural features is constructed to support automatic recognition of the handwritten digit.Experimental result demonstrates that the proposed method is superior to other general methods in recognition rate and robustness.
handwritten digital identification;combining structural feature;decision trees;pattern recognition
自由手写体因其书写风格差异大、上下文无关及识别准确度要求高等原因导致其识别难度大的问题。针对手写体数字识别的特点及要求,提出一种新的基于组合结构特征的自由手写体数字识别算法。通过扩展的字符结构特征识别算法自动、鲁棒地提取手写体数字字符端点、分叉点、横线等多种结构特征,并组合应用这些结构特征构造决策树完成手写体字符的自动识别。实验结果表明基于组合结构特征的自由手写体数字识别算法的鲁棒性和识别率明显优于传统方法。
手写体数字识别;组合结构特征;决策树;模式识别
A
TP391
10.3778/j.issn.1002-8331.1109-0092
CHEN Junsheng.Research on combining structural features based free handwritten digital identification algorithm. Computer Engineering and Applications,2013,49(5):179-184.
陈军胜(1969—),男,副教授,主要从事随机分析研究。E-mail:chenjs@nxu.edu.cn
2011-09-06
2011-11-28
1002-8331(2013)05-0179-06
CNKI出版日期:2012-01-16 http://www.cnki.net/kcms/detail/11.2127.TP.20120116.0928.062.html
猜你喜欢
星星·散文诗(2023年1期)2023-04-15
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
小学生学习指导(中年级)(2019年3期)2019-04-10
电脑知识与技术(2017年3期)2017-03-27
中国塑料(2016年2期)2016-06-15
兽医导刊(2016年12期)2016-05-17
中学生物学(2016年8期)2016-01-18
应用海洋学学报(2015年3期)2015-11-22
中华建设科技(2014年6期)2014-08-27
