
词频研究新成果——《当代美语频率词典:词汇素描、搭配和主题词表》评介*
2013-06-01 08:03:38朱玉彬
辞书研究 2013年4期
朱玉彬
章宜华、雍和明(2007:406)指出:“从语言内容处理上讲,当代词典学需要有认知学、社会学、语言学包括词汇学、语义学、句法学、语用学以及翻译学等学科的理论支持;从语言处理的技术上讲,需要计算机科学、信息学、统计学以及语料库的支持。”运用计算机技术进行词典编纂,是当代词典学的一个重要特征,而词频词典的编纂更离不开计算机技术的支持。作为劳特里奇(Routledge)系列频率词典的一种,美国杨百翰大学(Brigham Young University)语言学和英语语言系Mark Davies教授、Dee Gardner副教授编纂的《当代美语频率词典:词汇素描、搭配和主题词表》(A Frequency Dictionary of Contemporary American English:Word Sketches,Collocates,and Thematic Lists;以下简称《当代美语频率词典》)于2010年2月出版[1]。这是一部利用语料库和自然语言处理技术编纂的,可供美语学习者、英语教师及语言研究者参考的实用工具书。该书展现的5000常用词的频率、搭配等语言信息基本反映了当代美语使用的真实情况。
一、主要内容
本词典的核心部分是词目索引,即在当代美国英语中最为常用的5000个词按照不同的分类标准分成三种类型的索引。其中主索引是优化后按照由高到低的频次顺序排列的
5000个词目词(词汇原型,即lemma[2]),每个词目词包含信息如下:
词目序号(1,2,3,…5000) 词目词 词性
搭配词(按照词性归类,每类搭配词又按照频率由多到少的顺序排列)
原始频次 |散布指数(0.00—1.00)(语域标记:S—口语,F—小说,M—杂志,N—报纸,A—学术期刊)
例如第2203号词目:
2203 enable v
noun.student,system.,technology.,program.,teacher,.user,information,.researcher,skill.,software.,.individual,process.,development,.scientist,tool.miscwill.,.us,develop,design.,thus.
15117|0.91 A
在enable这一词条中,noun表示可在中心词enable前后各四词的范围内,构成搭配同现结构的名词,其中最常见的搭配同现词是student;misc表示其他一些词性的搭配同现词。这里所有的搭配同现词也都是词汇原型,并按照由高到低的出现频次排列。一些搭配同现词前后的“.”表示中心词所在位置,如“.scientist”表示enable scientists。词条末尾的语域标记(本例为A,即学术期刊语域)不是每一个词条都有,只有当某一词汇原型在某一个语域中出现的频率至少是其在整个语料库中出现频率的一半时,才使用相应的一个或几个语域符号标示出该词汇原型出现频率最高的语域。因此,像the,break等通用词是没有语域标记的。关于修正词汇原型原始频次的散布系数(本例为0.91)将在下一节介绍。
第二个索引是字母顺序索引,即按照英文字母表的顺序排列这5008个词目,每个词目的格式如下:
中心词 词性 词目序号(与主索引的词目序号一致)
其后的第三个索引是词性索引,即按照英语的基本词性(如动词、名词、形容词等)将上述词目分类,每个词类中的词目按照主索引的词目序号升序排列,即最常见的词目(词目序号最小)排在最前面。每个条目的格式如下:
词目序号(与主索引的词目序号一致) 中心词
这三个索引通过词目序号连成一体,其中主索引所占的页数将近另外两个索引总页数的四倍。
笔者根据该词典前面的缩略符号(p.ix)将词典词目分成三大类,分别统计如下:
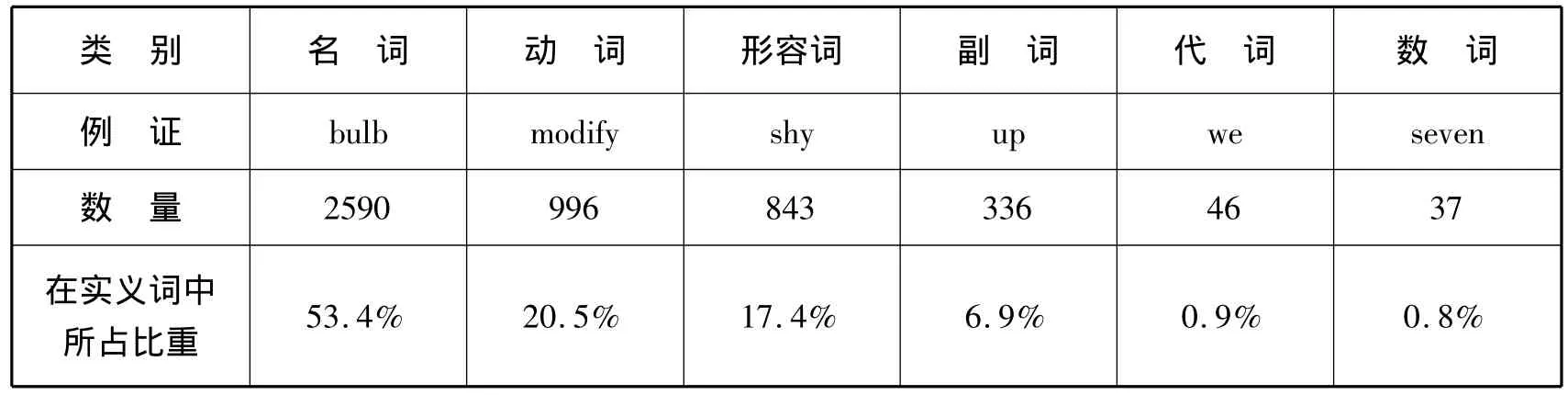
实义词统计表*
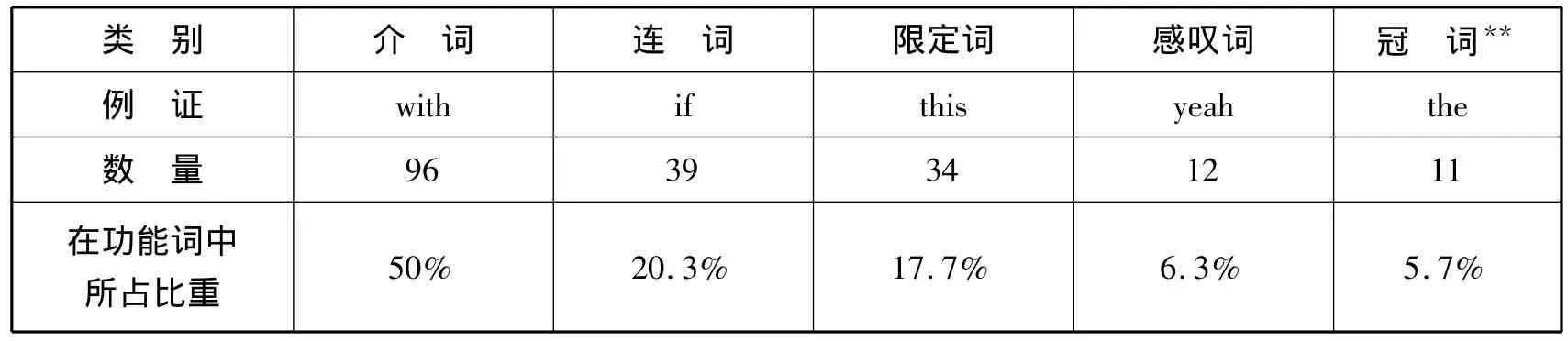
功能词统计表*
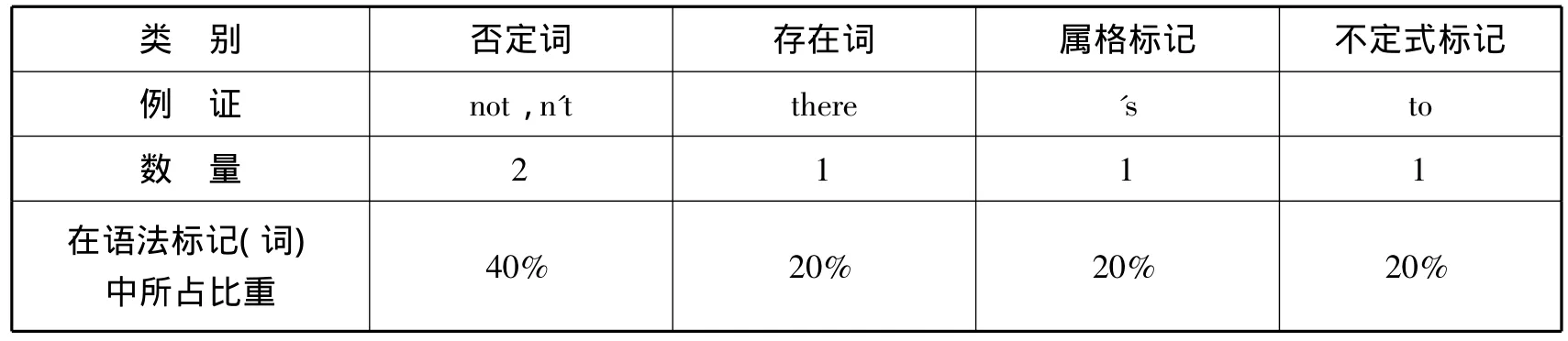
语法标记(词)统计表*

三大类词汇各自所占比重
此外,《当代美语频率词典》前后共收录了31个主题词表。其中有关于动物、身体部位、服饰、颜色、情感等的主题词表15个,每个主题词表中的词目按照出现频次降序排列。如“动物”主题词表列举了前80个词,并在每个词的右下角给出了该词在整个语料库中的原始频次,前面五个依次为:dogn49897,fishn41277,birdn35610,horsen30042,chickenn23955(p.15)。由于一些表示动物的词有比喻义,或是一些体育运动队的吉祥物,它们实际的使用频次可能会增加,编纂者细心地为这些词语加了圆括号,如排于该主题词表中第20位的pig8048等(p.15)。接着是口语、小说、流行杂志、报纸、学术期刊这五种语域的主题词表5张,然后是11张关于英语语言知识的主题词表,包括美语新词、美式英语和英式英语、不规则名词复数、短语动词、单词长度(Zipf定律)等主题词表,每个词表基本都按照原始频次来排列词目。这些主题词表是极具价值的英语教学材料。
二、编纂特色
1.语料来源权威
词频词典的质量取决于供计算机抽取词频的语料库的质量。对于一个平衡语料库来说,容量问题和代表性问题最为关键。《当代美语频率词典》的语言信息抽取自当代美语语料库(Corpus of Contemporary American English,COCA)。该语料库从1990年开始每年收录2000万词的最新资料,包含超过15万个文本文件,迄今为止已达4亿词,堪称全球英语语料库中的“巨无霸”(参见http:∥www.americancorpus.org)。它比1990年开始筹建的1亿词的美国国家语料库(American National Corpus,ANC)还要大三倍,且美国国家语料库目前也只完成了2200万词的收录及详细标注工作(参见http:∥www.americannationalcorpus.org)。鉴于当代美语语料库按照年份每年收录2000万词,完全可以将其作为当代美语的监控语料库。
就语料库的代表性而言,该词频词典编纂时,当代美语语料库一共涵盖了由五个语域构成的五个子库(pp.3—4):(1)口语子库包括从150个电视与广播节目的无脚本对话转写的文本,覆盖全美主要的电视及广播媒体,共7900万词;(2)小说子库涵盖从文学杂志、儿童杂志以及流行杂志搜集到的小说及戏剧文本,1990年至今出版的小说的第一版第一章和电影脚本,共7600万词;(3)杂志子库覆盖全美100多种杂志,按照年份和杂志类别共搜集8100万词;(4)报纸子库包括全美10种主要报纸,按照不同版面分类搜集了7600万词;(5)学术期刊语域包括近100本同行评审的学术期刊,覆盖了美国国会图书馆分类标准的全部代码,每年抽取一定词量形成本子库的文本文件,共7600万词。因此,在这样一个容量巨大(3.88亿词)、抽样均衡的大型平衡语料库的基础上抽取的词频信息,是可以充分反映当代美语词汇的使用情况的。
2.词目排序科学
本词典的词目排序不是简单地按照词目的原始频次降序排列,而是运用了自然语言处理技术中的“散布系数(dispersion index)”来优化原始的词汇频次,这就形成了最终排序时采用的数值,其计算公式为“频次值=原始频次×散布系数”。因为一些词目(特别是一些科技术语,如计算机术语cache)可能会较多出现在某一个或几个语域中,若按照未经修正的原始频次排序,并不能充分反映语言使用的真实情况,而根据优化后的词目频次重新排序,则可以大大减少误差。
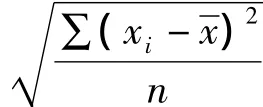
3.搭配信息丰富
自然语言处理领域中,运用信息论中的互信息(Mutual Information,MI)数值来测算两词或表达之间的同现关系是从20世纪90年代初开始的。Church&Hanks于1990年提出用“点互信息(Pointwise Mutual Information)”的方法计量单词或表达式的同现情况。具体而言就是,设定一个语料库中的两个单词w1和w2,P(w1,w2)和freq(w1,w2)表示两词同现的概率和频次,P(w1)和freq(w1)是w1在整个语料库中单独出现的概率和频次,P(w2)和freq(w2)是w2单独出现的概率和频次,N是语料库的总词数,则单词w1和w2共现的互信息其实就是两个词语共现概率除以两词单独出现概率乘积的对数,公式演算过程如下:
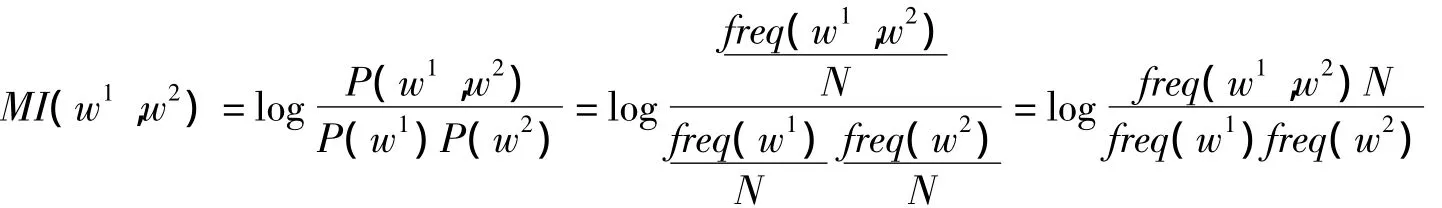
在自然语言处理领域,研究者发现互信息在稀疏数据集上会出现很大问题,即对于那些出现频次较低的单词而言,不能达到预期的测试效果(Manning&Schütze 1999/2003:182)。有研究者建议将词频的最小值设定为3,即只关注出现频次在3次以上的两个词语之间的互信息,但是这也不能完全解决互信息的一些问题(Manning&Schütze 1999/2003:182)。因为互信息在本质上是“测量两词语间互不相关性的一种好方法”(Manning&Schütze 1999/2003:182)。尽管互信息在测量两个词语的同现情况方面不是十分理想,但使用互信息的一个显著优势是可以提供更多的搭配同现信息。因为“互信息的数值越接近0,则说明两词越是独立出现”(Manning&Schütze 1999/2003:182),即两词之间共现的可能性越小;反之,数值越大,则说明这两个词语越会在一起出现。具体到实际操作中,《当代美语频率词典》的编纂者编写出一个程序去检索整个语料库,然后统计出包括节点词(node word)及其前后四个词在内的序列(共计9个词的检索行)的总频次,然后邀请至少四名本族语为美语的使用者进行人工鉴别(p.6)。之后为了获得更多有效的搭配信息,两位编者通过初步的抽样试点计算之后将互信息临界值设定为2.5(p.6),这样可以包括更多的同现词,最后确定录入本词典中每个词目的搭配词。
4.电子资源配套
特别值得一提的是,本词典还配备供不同使用者使用的电子版本。电子版在收词数目、搭配同现词的数量等方面均与纸质版有所不同。电子介质的词典又有三种版本:PDF版本、txt文本文件版本和Excel表格版本,且区分了商用和学术研究用的购买价格。该词典的电子版本最多收录了2万个词目,每个词目带有200~300个搭配词,提供了非常丰富的搭配信息。(参见 http:∥www.wordfrequency.info/purchase.asp)
三、不足之处
《当代美语频率词典》也有一些问题:
(1)词典“缩略符号”一页提供的词目加起来一共有5045个(参见本文第一节的最后一张统计表格),这与词典正文部分收录的5000个最为常用的词目在数目上有些差异。在词典的三个索引中,兼类词按照词性单独列为词典词目,并单独配有相应的词目序号,所以不可能出现不同词性的词同属一个词目而造成词汇数目“缩水”。笔者曾就此发电子邮件咨询过主编Davies教授。Davies教授指出:《当代美语频率词典》的正文是5000条词目,确实比根据词典前面的词类缩略符号一页提供的数据统计出的结果少了1%左右的词目,但这不影响整部词典统计数据的可靠性。笔者推测,这一问题可能是因截取点定在第5000个词目后,没有相应地修改“缩略符号”页上提供的词目数造成的。
(2)关于“冠词”类中词目扩大化的问题,笔者也曾向Davies教授求教。Davies教授指出,在前2万个词目中,属于冠词范畴的词目依次为(括号内的数字是根据当代美语语料库算出的最新词目序号):the(1),a(5),his(25),their(36),her(42),my(44),your(69),its(78),our(79),no(93),every(172),thy(10226),his/her(12456),yer(19414),并进一步指出其理据来源于兰开斯特大学开发的CLAW赋码器的第七版赋码集(C7 Tagset)(参见http:∥ucrel.lancs.ac.uk/claws)对于此类词汇的赋码。笔者查看了C7赋码集,上述这些词汇的赋码为:

这三个词类的确都是以A开头的,AT1作为AT的一个相关词类,包含了a和an这两个传统语法界定的“不定冠词”。但是,将APPGE归入“冠词”的做法毕竟有违一般的语法观念。基于语料库编纂的《朗文英语口语和笔语语法》(Biberet al.1999/2000)用不同术语指称这些词:definite article(the),indefinite article(a,an),possessive determiner(his,your)和quantifier(no)。因此,对“冠词”范畴扩大化的问题还是有必要向读者做出一些说明的,不然很多读者会产生疑惑。比如可以从这几类词的功能上加以说明,他们都能修饰名词,并对被修饰的词加以限制说明。
(3)《当代美语频率词典》的数据基础是词汇形式的出现频率,而不是其语义的出现频率。尽管两位编纂者根据词性对搭配词进行了归类,但是它们最多只能反映出词汇语义的粗颗粒度差异,对于词汇语义的细颗粒度差异,还需要真正基于语义标注的大型平衡语料库助一臂之力。其实这也是大多数基于形式出现频率编纂的词频词典的共同缺陷。值得关注的是,现在国际上已有很多研究者正在积极地进行词汇句法语义标注的理论研究与工程实践,希望将来研究者可以编纂出实用的语义频率词典。
上述问题不过是《当代美语频率词典》这块美玉上的几个瑕疵。能从一个4亿词(最初编制的主索引是从3.8亿词的语料库中抽取,参见Davies 2009)的当代美语语料库中提取如此丰富准确的词频信息,单就这一项艰辛的工作来说已实属不易。黄昌宁和李娟子(2002:172)指出:词频统计信息在“决定词典的收词,编写语言教科书和开发自然语言处理系统的机器词典等诸多方面都有重要的参考价值”。《当代美语频率词典》向语言学习者、语言教师及研究者提供了当代美语词汇使用的实际情况,其应用价值是不言而喻的。希望国内研究者可以充分利用这部词典的研究成果,并结合在英国国家语料库基础上编纂的《英语书面语与口语的词汇频率》(Leechet al.2001)一书,在英语教学、英汉词典编纂与语言研究中取得更多的成果。
附 注
[1]本文直接引证《当代美语频率词典:词汇素描、搭配和主题词表》的有关内容时,只标出页码(如:p.6)。
[2]有研究者将lemma译为“削尾词”,这里我们称为“词汇原型”。
1.黄昌宁,李娟子.语料库语言学.北京:商务印书馆,2002.
2.章宜华,雍和明.当代词典学.北京:商务印书馆,2007.
3.Biber D.et al.Longman Grammar of Spoken and Written English.Beijing:Foreign Language Teaching and Research Press,1999/2000.
4.Church K W,Hanks P.Word Association Norms,Mutual Information,and Lexicography.Computational Linguistics,1990(1):22—29.
5.Davies M.The 385+Million Word Corpus of Contemporary American English(1990—2008+):Design,Architecture,and Linguistic Insights.International Journal of Corpus Linguistics,2009(2):159—190.
6.Davies M,Gardner D.A Frequency Dictionary of Contemporary American English:Word Sketches,Collocates,and Thematic Lists.London/New York:Routledge,2010.
7.Leech G.et al.Word Frequencies in Written and Spoken English Based on the British National Corpus.London:Longman,2001.
8.Manning C D,Schütze H.Foundations of Statistical Natural Language Processing.Cambridge:The MIT Press,1999/2003.
9.Oakes M P.Statistics for Corpus Linguistics.Edinburgh:Edinburgh University Press,1998.
猜你喜欢
西藏研究(2021年1期)2021-06-09 08:09:52
疯狂英语(双语世界)(2016年3期)2016-02-27 10:12:00
——基于《广辞苑》从有无对应动词形角度
山西青年(2016年19期)2016-02-04 15:17:09
首都外语论坛(2014年1期)2014-03-20 15:21:23
湖北社会科学(2014年12期)2014-02-27 09:46:51
科技视界(2013年23期)2013-08-15 00:54:11
成都理工大学学报(社会科学版)(2012年2期)2012-01-04 05:24:54
职业教育研究(2011年6期)2011-03-25 10:36:23
当代修辞学(2010年6期)2010-01-21 02:28:02
中学生英语高效课堂探究(2008年9期)2008-11-17 08:02:22
