
蒙古文输入法输入码方案研究
2013-04-23 06:16白双成张劲松呼斯勒
中文信息学报 2013年6期
白双成,张劲松 ,呼斯勒
(1. 北京语言大学 对外汉语研究中心,北京 100190; 2. 内蒙古社会科学院 蒙古语信息处理研究所,内蒙古 呼和浩特 010020; 3. 内蒙古蒙科立软件有限责任公司,内蒙古 呼和浩特 010019)
1 引言
依据蒙古文编码国际/国家标准及用户协定[1-3],在Windows Vista/7/8、iOS等平台上,依托其复杂文本布局引擎(complex text layout engine),开发 OpenType[4-5]或AAT(Apple Advanced Typography)字体,再配合一个简单的键盘映射输入法即可实现蒙古文的录入和名义字符到变形显现字形的转换显示。但是,为了更好地满足用户需求,开发一套简便快捷的智能输入法是非常有必要的。对于一个录入速度和准确度要求较高的智能输入法而言,研究制定科学合理的输入码方案至关重要。
我们将输入一个单词所需的输入码的码元个数称为码长[5-6]。就词级录入来说,蒙古文输入法的录入速度取决于词的平均码长,其中含两层含义,一个是对应一个单词的码长越短越好,另一个是输入这个输入码时用户思考寻找的时间越短越好。输入法的码长越长,输入信息越多,对应重码词就越少。反之,码长越短,所含信息越少,对应重码词就越多。单纯地减少码长未必能提高速度,因为寻找一个键的时间可能变得较长[5,7]。所以缩短平均码长的关键在于兼顾两者,输入码方案确定就是在码长与信息量之间寻找一个平衡点的过程。需要特别说明的是,好的方案能否落到实处,还要看具体工程实现能力和实际条件。
以往,确定输入法输入码方案时更多的是研发人员从感官认识和个人的主观意识去选择一套方案。为此我们想通过本文较为系统的量化比较各类输入码方案,为下一步的研究和工程实现提供理论依据。
2 部分约定
1) 蒙古文输入也可以用字形、字符编码等信息来输入,但这类输入方式毕竟不是普遍做法,本文讨论的输入法,只限于读音输入(类似于汉字拼音输入),也就是按蒙古文读音为基础的输入法。
2) 限定在PC普通键盘上,不涉及数字键盘或其他类。组成输入码的字符集(通常称为码元)默认为英文字母{abcdefghijklmnopqrstuvwxyz},也可以是普通键盘内的其他所有字母,如蒙科立整词输入法[8]中“NG”用“;”输入。码元越多,重码可能性越小,输入就会更快捷,但会加大用户记忆压力。本文虽不涉及数字键盘,依然对其有一定的借鉴意义。


5) 以词组为单位统计的单词的信息熵保证比以单词为单位的信息熵小,也就是说,以词组为单位进行输入码编码的话,其输入码长度会小很多。如果进一步考虑单词及词组之间的上下文相关性,建立统计语言模型的话信息熵会更小。但本文暂不涉及这些内容。因为我们通过n元模型试验得知,只要单词输入码方案选定合理,直接应用于词组及语言模型,即可获得较好的效果。因篇幅所限,暂不细述。
6) 如果加入单词频率因素,量化比较会更合理些。但碍于目前所能获得的熟语料量严重不足,生语料利用中的部分技术问题还未完成,所以本文暂时无法考虑词频因素。
7) 输入码方案中优先考虑输入的简短快捷和易学,但本文提出的模糊输入特性恰恰是标准音教学和推广中所不能容忍的。我们认为可通过输入法选项来限定,就此不做额外说明。
3 输入方案简介
按输入码方案的特点,将其分为三类,即方案1为全拼方案,方案2和方案3为整词方案,其余为模糊输入方案。各方案介绍如下:
方案1: 全拼方案
该方案是目前多数读音输入法(或称其为音码输入法)采用的输入码方案。其核心思想是依据拼音(音素)文字特点,为每一个音素安排一个输入键(实际应用中可能会用n+g来输入(),用lh输入(l)等策略), 通过上下文的分析,尽力解决一字多形,多字同形(同形异音)问题。例如,音素(a)的输入键为a,则不管其词内位置如何,都用这个a键输入,如的输入码为agana。为区分同一音素在相同上下文中的多个变体,引入变体选择方案(用词典或规则方式特殊处理除外,此处特指此类特殊问题),如蒙科立音码输入法2002版中用1、2、3选择不同变形(如输入为banana1),用-a、-e选择词尾a、e变形(harahar-a)。后续版中引入穷举候选项和大写输入码(也就是shift+键值)输入非常用变体字形方式。基于OpenType技术实现的键盘映射可归为此类。
方案2: 整词输入法方案

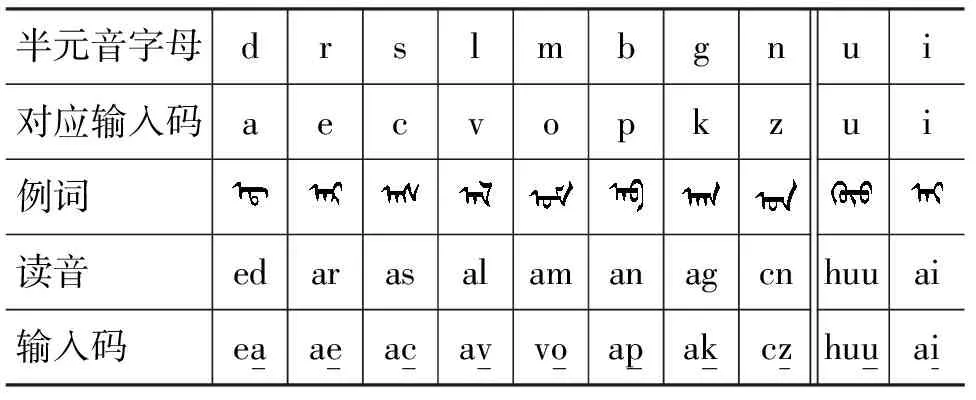
表1 整词输入法半音字母映射关系表

方案3: 在方案2的基础上要求补充所有半音字母。提出这一方案的目的仅仅是想在数据上比较一下方案2以外的半音字母对重码过滤的贡献度。实际应用中录入复杂度已接近方案1,还要记忆半音字母对应关系,无实际应用价值。
方案4: 只取各音节的首字母,忽略所有其他字母。此方案将在词组输入和基于统计语言模型输入中具有重要作用。
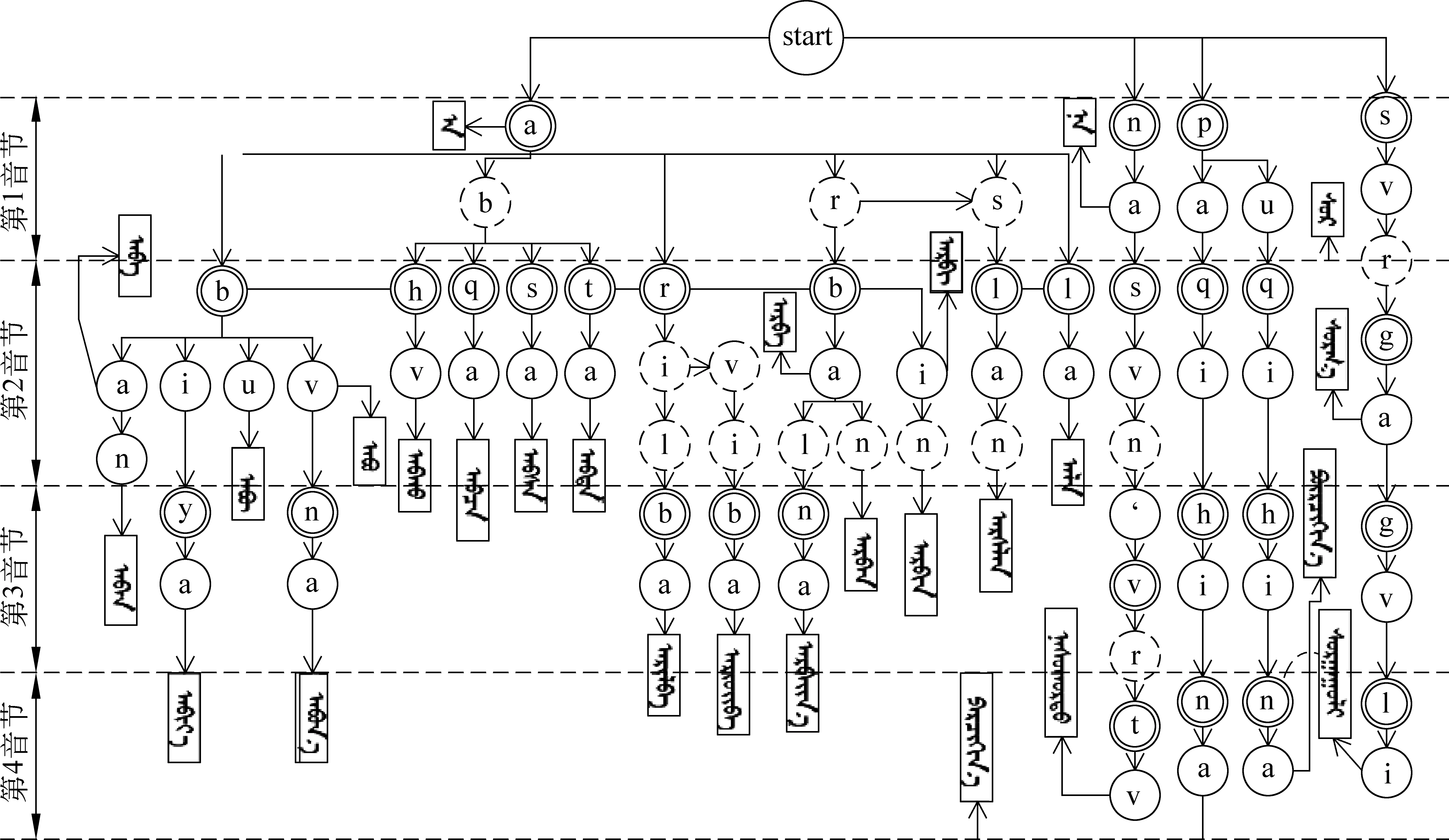
图1 模糊输入方案示意图
方案5: 取各音节首字母,再取首音节元音。此方案主要观察首音节元音贡献度。
方案6: 取各音节首字母,再取词尾半音字母。此方案主要观察词尾半音字母贡献度。

4 量化比较
试验中使用的是1 215 799条词。
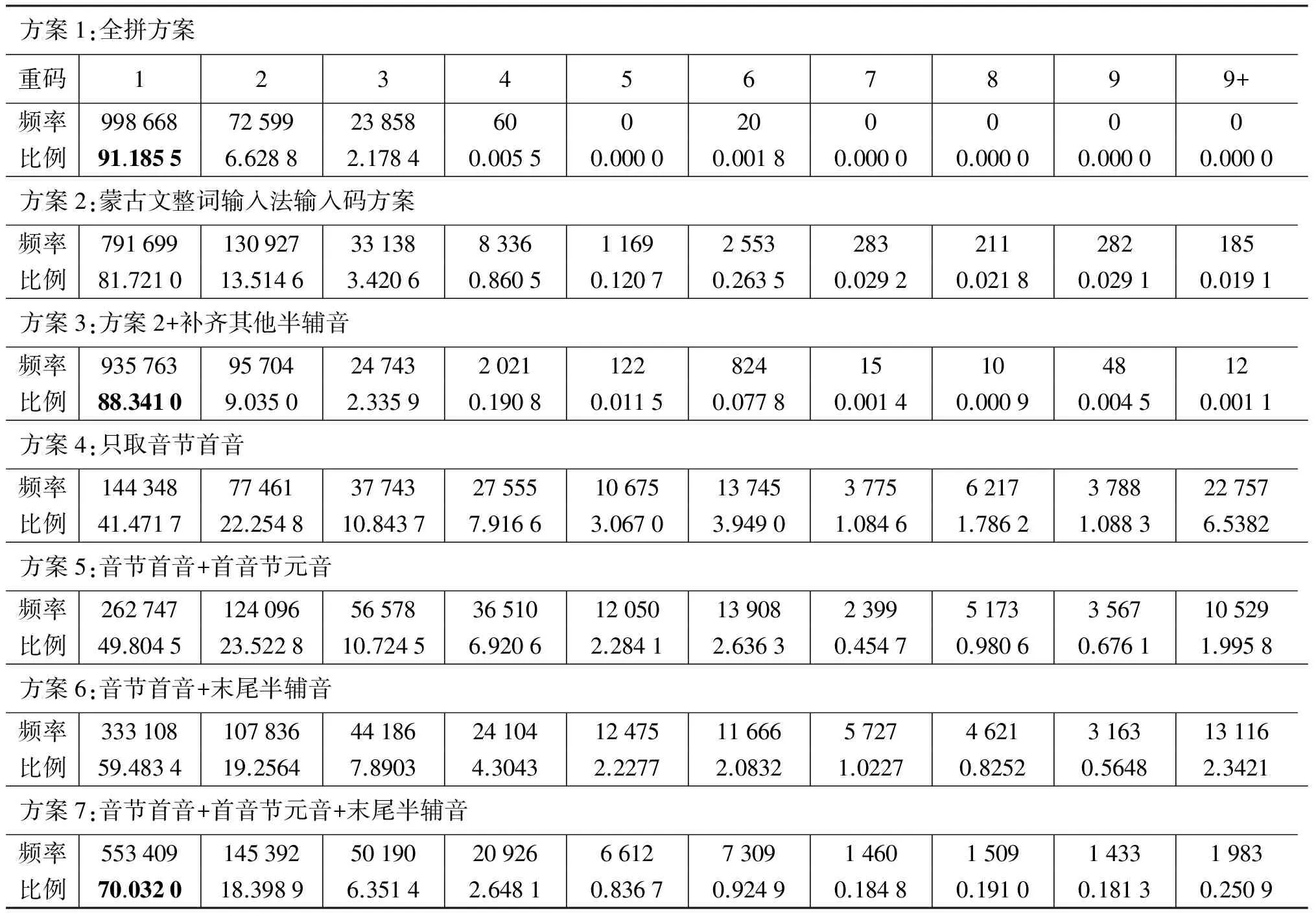
表2 各方案重码分布表
从表中分析可知
全拼方案类—方案1:
1) 只需了解键盘布局即可会拼写,易学性突出;
2) 拼写所有可能组合,没有拼不出来的字,是其他方案的必要补充;
3) 高达91.185 5%的无重码率,重码集中前3项,便于盲打;
4) 音节切分没有歧义;
5) 只需规则推导,不用词表也可以;
(三)预防用药 一些疾病,如仔猪黄、白痢,只要事先在饲料中加入药物,完全是可以做到事半功倍的预防作用。为了预防常见病,一般养殖场都定期或不定期在饲料中加入土霉素粉、黄芪多糖粉、氟哌酸粉、环丙沙星粉等,做到防患于未然。
6) 输入码长,效率低;
7) 没有词库支持错误率较高;
整词方案类—方案2至方案3
1) 平均码长比方案1短很多,但无重码率还是高达81.721 0,重码分布与方案1接近;
2) 音节切分基本没有歧义;
3) 需记忆对应关系,按人类学理论,易中断录入者的思维过程,不符合人的自然行为;
4) 录入未登录词时,需要在方案1与方案2之间进行切换;
模糊方案类—方案4至方案7
1) 平均码长接近方案2,但与其相比,输入更自然流畅,符合自然行为;
2) 补充信息越多重码率越低,输入灵活,便于读音不确定词的录入;
3) 与方案1结合录入未登录词更为自然,无需切换;
4) 利于用更为简短输入码用于基于统计模型的连续输入;
5) 失去音节结构,重码率升高;
6) 输入灵活,但同时输入随意性增大,盲打难度提高;
5 平均码长
为进一步用一个单值直观比较输入码方案的特性,在此借用平均码长概念。长度为len的输入码有n个重码时,我们还需要用一个空格或数字键选择,所以每个词需击键len+1次。我们认为按空格选择第一候选项和按数字键选择其他候选项具有决然不同的消耗,以至于放大其影响而忽略空格输入时,平均击键数可公式化为(len*n+n-1)/n=len+1-1/n。例如同样是码长为2的输入码,如果重码为2,则平均码长为2+1-1/2=2.5,如果重码为3时平均码长为2+1-1/3=2.66。所以总平均码长公式为:
其中len(i)是第i个输入码长度,C(i)为输入码i的重码词个数。
需要说明的是当n大于阈值时,还需要翻页。但我们比较的几种输入码方案中10以上重码量较少,为简化公式,没有对其进行细化。

表3 平均码长对照表输入码方案
从表中可以看到,我们方案6和方案7之间可以找到一个近似方案2的平均码长。
需要说明的是,表3所示数据中,没有考虑单词实际出现频率,加上计算单词中涵盖大量蒙古文形态变化派生的单词,所以平均码长要比现实文字录入的平均码长长很多。
6 总结
基于本文试验,我们在新输入法中采用了融合方案4至方案7的改进型混合输入码方案,即,用户必须输入各音节首字母,其余字母都可以随意忽略。通过本试验我们明确了所采取输入码方案的优缺点。为进一步研究与工程实现奠定了基础。
除上述量化比较中凸显的优点外,此方案还有如下优点值得阐述:
1) 输入中可避开读音易混淆字母

2) 有助于输入外来词和特殊词拼写

值得说明的是,输入码中的各成分的权值不一样,更为合理的方式是测定各信息的熵[9-10]或互信息,通过熵或互信息来确定单词的最短输入码更为合理,但这种方式推导出来的输入码仅仅是满足最小化输入码的需求,会增加人们输入码记忆难度,实际意义需要研究。如果与上述分析类似,将输入码分为音节首字母、元音、半音字母等,通过熵或互信息,自底向上推导出一个合理的词级编码方法将是我们近期另一项研究内容。
更进一步,以上所有分析源于一个思想,认为蒙古文读音输入法的编码方案的不同,实质上是从音素、音节、单词、词组等不同层次进行编码的结果。从音素层次,对每个音素进行编码,就是全拼方案。而其余都是从音节层次(更准确说是抽象音节结构角度考虑,而不是穷举所有音节结构)进行编码。基于单词及以上单位的编码方式目前不太适合蒙古文。这个需要合适的语言模型及语料库的支持。
[1] The Unicode Consortium[EB]. http://www.Unicode.org.
[2] 确精扎布. 蒙古文编码[M] . 呼和浩特: 内蒙古大学出版社, 2000.
[3] 国家质量监督检验检疫总局,国家标准化管理委员会.GB 25914-2010.信息技术传统蒙古文名义字符、变形显现字符和控制字符使用规则[S]. 北京.中国标准出版社,2011.11.
[4] OpenType specification[EB]. http://www.microsoft.com/typography/otspec/ .
[5] 姚延栋, 吴健, 孙玉芳,呼斯勒. 传统蒙古文变形显示机制研究与实现[J].中文信息学报,2005, 18(5): 84-89.
[6] 朱巧明、李培锋等.中文信息处理技术教程[M].北京.清华大学出版社,2005.9.
[7] 吴军.数学之美[M].北京.人民邮电出版社.2012.6: 185-196.
[8] S·苏雅拉图.蒙古文整词计算机生成理论研究[J].中文信息学报,2001,15(4): 59-65.
[9] 那日松,淑琴.蒙古文信息熵和拉丁转写研究[A]. 中国计算技术与语言问题研究——第七届中文信息处理国际会议论文集[C], 2007: 782-785.
[10] Thomas M.Cover, Joy A. Elements of information theory[M]. New York. Wiley.1991.
猜你喜欢
音乐生活(2022年9期)2022-10-21
蒙古学问题与争论(2021年0期)2022-01-19
北京教育·普教版(2020年9期)2020-10-09
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
天津音乐学院学报(2019年4期)2019-06-11
蒙古学问题与争论(2019年0期)2019-03-29
速读·中旬(2018年8期)2018-10-23
上海戏剧(2017年10期)2017-10-24
中国信息化周报(2017年30期)2017-08-31
