
维哈柯及蒙语多文种语言相似性考查研究
2013-04-23 06:16:27达瓦伊德木草1吾守尔斯拉木1
中文信息学报 2013年6期
王 玲, 达瓦·伊德木草1,,吾守尔·斯拉木1,
(1. 新疆大学 信息与工程学院,新疆 乌鲁木齐 830046; 2. 新疆大学 新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
1 引言
多语言信息处理,尤其是少数民族语言信息处理正从文字信息处理阶段跨越到较复杂的自然语言及语音处理阶段,机器翻译MT(Machine Translation), 大词汇连续语音识别LVCSR(Large Vocabulary Continuous Speech Recognition )等新技术在少数民族语言信息处理中逐步得到预期测试效果[1-3]。
语言信息的自动处理往往需要丰富的语言信息知识,大规模语言资源的收集、整理、建设,需要耗费大量人力、物力、财力,并且对于小语种语言(即少数民族语言)其现有语言资源缺乏,严重阻碍了少数民族语言信息处理的深入发展。本文研究同语系多种黏着语言间的相似性,以期实现语言资源间的共享。 自然界存在许多较相似的语言,如同语系语言,而同一语系下同语族语言间相似性更高,这些语言不仅在文字字模、构词方法、语序、句法、语法等结构上较接近,而且在发音风格上有更多相似特征[4]。接下来将以阿勒泰语系下土耳其语族TLB(Turkish Language Branch)和蒙古语族MLB(Mongolian Language Branch)的文本信息为例进行说明。图1显示了维(Uyghur)哈(Kazakh)柯(Kyrgyz)三种语言的文本句对,及其相应的Unicode编码,三条语句都表达“你什么时候来我们家?”,它们同属土耳其语族。仔细观察发现,每条语句由若干个阿拉伯字母按至右向左顺序书写而成,字符串间用空格分隔。虽然有Uyghur, Kazakh, Kyrgyz不同语言之分,但其字模,字符串构成方式,语序以及句法和语法规则大体相通。另外,三种语言对应字符串的Unicode编码不仅内容上大体相同,而且在表现形式上 (斜体字部分) 也较接近,即使某些略有差别,但切分词干与后缀功能词后,词干部分几乎相同。如图1各条语句的第一个字符串(从右)编码中,词干 /biz/ 都相同,仅后缀功能词不同。黏着语言中这些功能词数量有限,这充分说明同语族语言在书写表现形式上有公共信息。

图1 维哈柯语文本句对及其Unicode编码
这种公共信息结构也同现于蒙古语族,图2显示了三种蒙古语(TM,TODO,NM)文本句对样式,它们同属MLB,目前在不同国家或不同地区被使用。观察它们的Unicode编码,发现TODO与NM(New Monglian蒙古国语言文字系统) 语言词对齐公共部分出现较多。图3进一步说明TODO与NM词与词之间直接转写的可能性较大。

图2 不同蒙古语文本句对样式及其Unicode

图3 MLB语言间词对齐关系
据以上分析,同语族各语言间存在较多公共信息,能否有效利用这些公共部分实现各语言之间的文本语音信息的转换处理,从而降低少数民族语言与不同语序、不同语法语言(如汉语)之间的翻译处理难度,是极其有意义的讨论课题。因此本文设计以下技术路线,如图4所示,先采用MT(Machine Translation) 高代价复杂技术解决汉语与维语的转换问题,再讨论用TT(Text Transformation)技术解决同语族语言文本转换问题,进而实现汉语与不同少数民族语言的机器翻译。该方法或许比各少数民族语言单独使用MT技术更方便有效。为此,探讨语言之间共享性或者相通性很有必要。
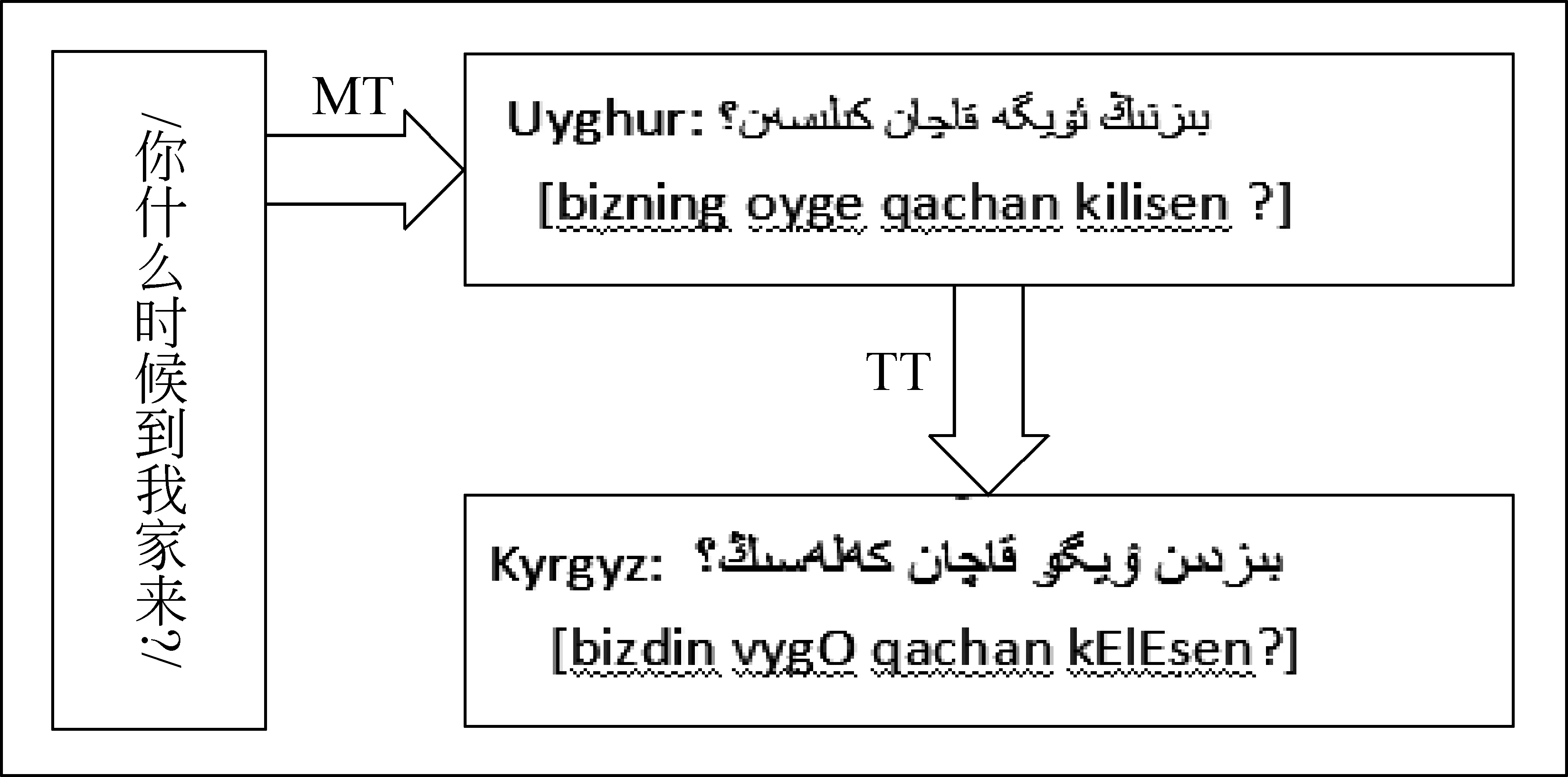
图4 汉语与少数民族语言(同语族语言)机器翻译技术路线
本文组织结构如下: 第2节简介相关研究现状,第3节讨论Cosine相似尺度理论,第4节基于对齐文本及语音音律参数,利用Cosine相似度算法,通过具体实验考察各语言间相似性,分析实验结果,第5节为结论与展望。
2 相关研究现状
近年来,关于跨语言信息处理研究,主要侧重于跨语言检索以及相似语音参数横向移植等方面。文献[5]运用德、英、法等15种欧洲语言语音声学参数横向移植,实现目标语的语音识别。文献[6]借助机器翻译实现中文与英文文本跨语言信息检索。文献[7-8]阐述了在同一语言文本中,通过计算句子相似度,获取语义接近的句子,提高机器翻译质量的方法。然而,关于相似语种的文本及语音信息的横向转换处理研究,还很稀少。本研究前期工作基于语料库以及语言学规则实现蒙古语多文种横向转写,取得较好成果[9-10]。
3 cosine相似尺度
设有两个n维向量A和B,如式(1)所示,这两个向量的相似性由式(2)给出。当cosineθ=1,(θ=0°)时,两个向量A和B相同,即A和B完全相似;当cosineθ=0,(θ=90°)时,两个向量A和B完全不相同,即A和B无相关性;用cosineθ在[0,1]之间的取值,度量两个向量A和B的相关程度[11-12]。
4 相似度考察实验
4.1 文本相似度考察实验
4.1.1 实验数据
本实验的数据来源于多语言平行文本语料,该语料由科研项目NSFC61163030*国家自然科学基金支持建造,有关该语料的数据统计信息见表1。

表1 多语言平行文本语料数据统计信息
4.1.2 实验方法
首先对语料中各种语言的文本句对进行量化处理,获取量化向量归正参数; 再利用式(2)分别计算句对级以及词对级相似度。
4.1.3 实验结果及分析
图5显示了各语言句对级相似度计算结果,从图中观察到,在文本级实验中, 同语族语言之间相似度较高,MLB语言之间相似度达到0.8,TLB语言之间相似度高达0.9;不同语族的语言之间相似度明显下降,如TLB-TODO,TLB-TM;并且TLB-TODO语言(同地区不同语族语言)的相似性略高于TLB-TM(不同地区不同语族语言)。

图5 各语言句对级相似度计算结果
上述同语族语言之间以及不同语族语言之间的文本相似度差别,同现于各语言词对级相似度计算结果中,并且表现得更加明显,如图6所示。图中显示MLB词相似度接近0.9,TLB词相似度超过0.9,然而不同语族语言之间词相似度极低。实验结果揭示,对于不同的少数民族语言,如果它们属于同一语族,则实现不同形式语言文本转换处理,在词级单元平行进行是可能实现的。

图6 各语言词对级相似度计算结果
4.2 语言的发音相似度考察实验
4.2.1 实验数据
本实验以维哈柯语言为主,利用平行语料录制语音,分别选用各语言10个发话人,每人朗读相同内容的50个句子,进行录制。录制数据用16KHz,16bit,单声道WAVE格式保存。最后,对录制的每句语音流,人工严格地标注出音素,再分别抽出音素单元的声学特征参数以及句子发话段的基频参数F0,如图7所示,本实验将分别考察各语言声学特征及音律特征的相关性,进而探讨相似语言语音信息横向处理的可行性,这将有利于相似语言连续语音识别,语音合成等跨语言信息处理的深入发展。
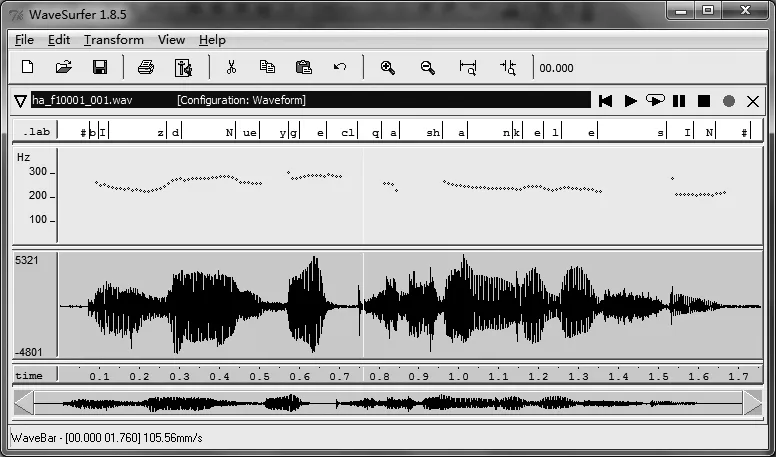
图7 声频分析
4.2.2 共振峰分析
共振峰是指说话者声道脉冲响应,如果将声道视为一个谐振腔,共振峰就是这个腔体的谐振频率。表示浊音信号,最主要的是前三个共振峰F1,F2和F3(图8)。本实验利用LPC(频域线性预测算法),提取元音前两个共振峰F1和F2,分别比较TLB语言和MLB语言的声频特性。TLB语言和MLB语言基本元音的F1和F2共振峰分析结果分别见图9(a,b,c) 和图10(a,b),为比较黏着语言常用标准,图9(d)中给出日本语5个元音共振峰标准分布图[13]。分析以下各图,得出结论: 1) 同语族语言TLB中各元音F1共振峰取值大致相同(350Hz~950Hz),F2共振峰有明显差别,哈语和柯语取值范围明显高于维语,维语为500Hz~4 000Hz,而哈语为900Hz~5 000Hz,柯语为1 000Hz~7 000Hz。
2) 比较图9和文献[14]的研究结果图10,不同语族(TLB和MLB)语言的基本元音共振峰分布特性差别较大,并且从图10(新疆和内蒙地区蒙语口语发音)观察到不同地区的蒙古语发音有明显差距。

图8 元音共振峰提取方法


4.2.3 音律特性—基频(F0)分析
人类的语音信息主要体现在韵律的变化上,在韵律特征中,基频结构最能反映说话人的语言信息特征。语音中只有浊音和元音有周期性脉冲串,其频率就是基音频率,简称基频F0。实验利用语音信号时域算法工具Wavesurfer提取不同语言发话段的基频F0曲线,分析比较各语言基频之间的相似性。表2和表3以及图11(a)和图11(b)分别给出不同语言话者说相同内容话语/bizningvygEqachankilisen/时基频实验结果。
从表2和表3以及图-11(a)和图-11(b)观察到,维哈柯各语言发音风格几乎接近,在不同民族的男女发话中,h-k(哈柯)说话人音律最相似,其次是u-k(维柯),接下来是u-h(维哈)。特别是,维语男声(u-m)有明显的音调特征。

表2 维哈柯语言男声发话语音基频实验结果
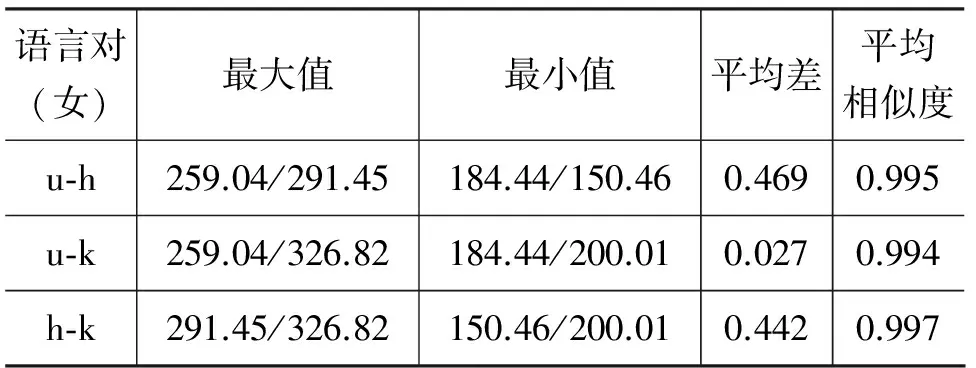
表3 维哈柯语言女声发话语音基频实验结果

5 结论与展望
大数据条件下建立共享云模型实现相似语言横向或者跨语言信息处理,多方位通信,促进少数民族语言的信息化发展是十分重要的研究方向。本文以阿勒泰语系下维哈柯及蒙古语为研究对象,利用平行语料从文本层面和发音层面研讨了同语系下诸多语言间的相似性或者相通性,定量给出这些语言间的相似程度。实验结果显示,在文本层面同族语言间以词为单元的文本转换的可能性较高;在语音层面维哈柯语言完全利用共享语音模型横向实现语音转换的可能性也较高。也就是说,如果在具备维吾尔语语言资源的前提下,通过横向处理方式实现哈语、柯语或者蒙古语多语种之间的机器转换,语音识别及语音合成等技术是完全有可能的,然而对于相似语言横向处理共享模型应该如何建设,还需要进一步研究。
[1] Wushour Slam, et al, Speech Processing Technology of Uyghur Language[C]//Proceedings of Oriental COCOSDA International Conference on Speech Database and Assessments, 2009: 11-16.
[2] 卡哈尔江,等. 一种改进的维吾尔语句子相似度计算方法[J], 中文信息学报,2011, 25(4): 50-53.
[3] 伊·达瓦,等. 语料资源缺乏的连续语音识别方法的研究[J], 自动化学报,2010, 36(4): 550-557.
[4] Shuichi Itahashi, Chiu-yu Tseng. Computer Processing of Oriental Languages[M]. 2010. World Scientific,www.American-sGroup.com.
[5] T Schultz, A Waibel. Fast Bootstrapping of LVCSR System with Multilingual Phoneme Sets[C]//Proceedings of Eurospeech 2001: 371-374.
[6] Lin jun Zhang, et al. Cross-Language information retrival, Journal of Computer Science,2004,31(7), 16-19.
[7] EHARA Terumasa, et al. Mongolian to Japanese machine translation system[C]//Proceedings of second international symposium on information and language processing, 2007: 27-33.
[8] Idomucogiin Dawa, Satoshi Nakamura. A Study on Cross Transformation of Mongolian Family Language[J], Journal of Natural Language Processing, J-STAGE, 2008,15 (5): 3-21.
[9] 达瓦·伊德木草. 基于机器翻译的蒙文多文本转写方法的研究[C]//新疆维吾尔自治区科技厅自然科学基金资助项目(2011211A012).
[10] 伊·达瓦等, 蒙古语语言—文字的自动化处理[J]. 中文信息学报,2006, 20(4): 56-62.
[11] Jun Ye. Cosine similarity measures for intuitionistic fuzzy sets and their applications[J]. Mathmatical and Computer Modeling, 2011, 53: 91-97.
[12] TSchultz, A Waibel. Experiments on Cross Language Acoustic Modeling[C]//Proceedings of Eurospeech, 2001.
[13] 古井 贞熙. 音响·音声工学[M], 东京, 近代科学社,1992.
[14] 伊·达瓦, 大川 茂村,白井 克彦, 蒙古语七个元音声频特性计算机分析[J], 声学学报,1999, 24(1): 94-97.
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
长春师范大学学报(2022年1期)2022-02-14 13:45:52
蒙古学问题与争论(2021年0期)2022-01-19 05:21:02
河北画报(2020年8期)2020-10-27 02:54:20
山东交通科技(2020年2期)2020-08-13 09:24:06
赤峰学院学报(蒙文哲学社会科学版)(2017年4期)2017-12-15 08:22:50
电子制作(2017年20期)2017-04-26 06:57:35
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
