
一种基于分类的平行语料选择方法
2013-10-15 01:52:16涂兆鹏吕雅娟姚建民
中文信息学报 2013年6期
王 星,涂兆鹏,谢 军,吕雅娟,姚建民
(1.苏州大学 计算机科学与技术学院,江苏 苏州215006;2.中国科学院 计算技术研究所 智能信息处理重点实验室,北京100190;3.加州大学 戴维斯分校 计算机科学系,加州95616)
1 引言
平行语料在机器翻译系统中起着重要的作用。大部分机器翻译系统,无论是基于短语的系统[1],还是基于句法的系统[2-4],都是从经过词语对齐的双语语料中抽取翻译规则。Och等人[5]的工作表明词语对齐的平行语料的质量直接决定了翻译性能。一般来说,平行语料规模越大,质量越高,则词语对齐的质量越高。
然而,大规模高质量的平行句对并不容易获取。由于统计机器翻译所需要的平行语料通常都是百万句对级的,人工构建显然是不可能的。随着网络的发展,大量网络双语语料的存在使得构建大规模平行语料成为了可能。但是网络双语语料中存在着大量的噪声,质量较低,直接使用会使噪声引入到翻译系统中,影响系统性能。
如何从包含噪声的双语句对中选择高质量的平行句对受到了越来越多研究者的关注。例如,陈毅东等人[6]曾研究面向处理平行语料库的筛选排序模型。姚树杰等人[7]在组织训练语料时考虑语料覆盖度问题。但是这些方法都经验性较强,需要人工干预,陈毅东等人[6]指出特征权重和语料选择的分数阈值一般都是人工经验给出。
针对该类问题,本文提出一种自动的基于分类的平行语料选择方法。首先,我们使用少数特征对平行语料进行初步打分,选择差异较大的少量句对构建训练集(如最好的m个句对和最差的n个句对)。然后,在该训练集上我们使用更多的特征(包括词汇特征,句法特征等)训练一个分类器,从而对其他平行语料进行分类,以选择高质量的句对(正例句对)。实验表明,过滤后的平行语料规模仅为原始语料的60%,使用过滤后的语料训练翻译系统,在NIST测试数据集合上取得了0.87BLEU点的提高。
后续章节组织如下:第2节介绍相关工作,第3节介绍基于分类的训练语料选择方法,第4节给出实验和结果分析,最后一节给出结论和未来工作。
2 相关工作
陈毅东等人[6]曾研究面向处理平行语料库的筛选排序模型,这个模型利用预先设定的特征将已有的平行语料进行打分排序,之后选取分数靠前的部分组织成为训练语料。姚树杰等人[7]在组织训练语料时考虑语料覆盖度问题。但是特征权重和得分阈值的选择需要人工经验。
吕雅娟等人[8,9]曾提出一种基于信息检索模型的统计机器翻译训练数据选择与优化方法,选择现有训练数据资源中与待翻译文本相似的句子组成训练子集,在不增加计算资源的情况下获得与使用全部数据相当甚至更好的机器翻译结果。此方法需要提前知道测试文本的内容。
Han等人[10]在基于训练语料句对可以分为字面互译和意译的前提下,提出一种基于词典和词性的方法判断句对是否字面互译,调整字面互译和意译句对在词对齐阶训练段时权重,达到翻译性能的提升。此方法是调整权重更好的利用语料,减小意译句对的影响,此处的权值也需要人工经验给出。
Munteanu等人[11,12]给出了大量的平行句对特征,通过利用少量的高质量的平行语料构建出正反例平行句对,训练分类器从大规模的非平行语料选择出平行语料。但是此方法需要用到少量高质量句对作为正例句对资源。
3 基于分类的平行语料选择方法
语料可以划分为完全平行句对、部分平行句对和完全不平行句对(噪声句对)。我们的任务是从大规模训练语料中选择高质量的平行语料,希望获得的是那些完全平行句对,即高质量平行句对。
通过观察发现,高质量平行句对一般会表现出很多共性:比如源语句和目标语句的互译准确、句对中源语句和目标语句都是比较流畅等。基于此,我们提出使用句对特征评价平行句对质量,利用分类器自动判别句对质量的好坏。下面分别介绍分类器的构建和特征的选择。
3.1 分类器的构建
传统的监督式学习需要标记样本数据来训练分类器,然而在现实中很少有标注好的平行语料库。在此我们需要构建足够的正反例句对供分类器学习。如何构造训练分类器的正反例句对是语料选择中关键一步。
文献[7]给出一种简单有效的排序模型对平行语料库句对进行排序。在设定权重后,句对得分成为衡量句对质量的一个重要参考指标。句对得分越大,句对被判定为平行句对的可能性越大。虽然对单个句对来看,无法依据其得分判定句对质量好坏,但实验证明分数高的句对集合比分数低的句对集合质量更好。我们关心的是什么样的句对更有可能成为高质量平行句对?设想如果一个句对在各个特征都比另一个句对表现优异,是否说明该句对成为高质量平行句对有着更大的可能性?答案是肯定的,因为一个句对的综合表现是由其各个特征所决定。我们可以寻找在各个特征上表现好或者表现不好的句对,使用这些句对构造分类器训练的正负例句对。
文献[11]指出句对长度比例特征和基于双语词典的翻译质量特征可以简单高效地评价句对的质量。实验证明翻译模型概率也是十分有效的区分特征。同时,部分特征(比如语言模型得分特征)对高质量句对的区分度不强。所以我们使用上述几个特征作为训练集正负例句对的特征。在这几个特征上全部得分较优的句对选为正例句对,全部得分较差的句对选为负例句对。这样,分类器训练所需要的正负例句对被构造出来。
本实验采用ZhangLe的最大熵模型工具包MaxEnt** http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html,该分类器实现了包含高斯平滑的最大熵算法,采用LBFGS参数估计方法。
3.2 句对质量评价特征
基于双语词典的翻译质量(式1)
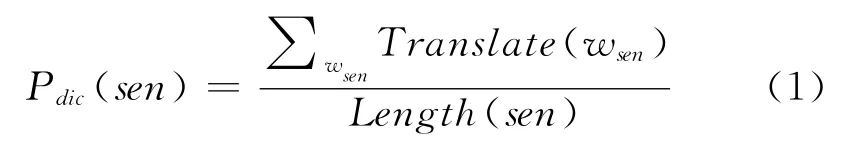
Length(sen)表示句子sen的长度,即句子sen含有词的个数。表示通过查阅双语词典,语句sen中所有在对应另一端句子中能找到译文的词的总数。对于Translate(w),如果单词w在对应的另一端句子中存在翻译项则为1,否则为0。
文献[7,10-11]都指出基于双语词典的翻译质量的特征是一种简单有效的评价特征。直观上看,P值大,表明句子中的很多词能够翻译到对应的另一端句子上,说明句对成为平行句对的可能性更大。所以,我们分别选取源端句子和目标端句子的基于双语词典的翻译质量作为句对特征。
翻译模型概率
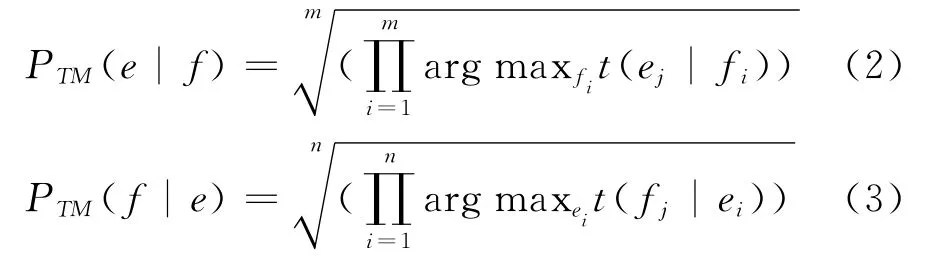
对齐得分被证明[12]是一个简单有效并具有辨别力的特征。在此我们用此公式表示源端句子f与目标端句子e相互的翻译概率。其中,arg maxfit(ej|fi)表示寻找单词fi与另一端句子中单词ej的最大翻译概率。在此我们选取源端到目标端翻译概率、目标端到源端的翻译概率作为句对特征。
语言模型
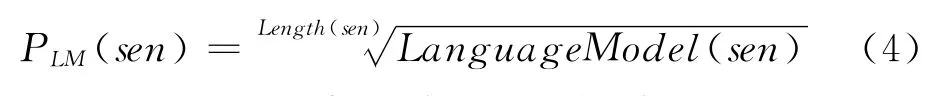
Length(sen)表示句子的长度。Language-Model(sen)表示句子sen的语言模型得分。
语言模型得分能够衡量句子是否流畅。但是根据语言模型公式,我们知道一个句子长度对句子模型得分有影响。为了减缓这种影响,利于不同句子间的得分比较,我们对语言模型得分按句子长度进行归一化处理。
语言模型参数在大规模单语语料上训练得到。实验中我们分别计算语料中的汉英句子的四元语言模型得分。
句子长度
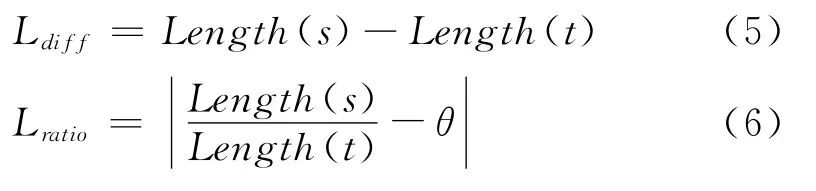
Length(s)表示源端句子的长度,即源端句子含有词的个数。Length(t)表示目标端句子的长度,即目标端句子含有词的个数。Ldiff值表示源端句子长度和目标端句子长度差值,Lratio值表示源端句子长度和目标端句子长度归一化后的商值。
文献[7,11]都指出,句子长度是一个非常重要的特征。文献[7]指出给定的语言对里的互译句对长度应符合一定的比例。并且给出汉英平行句对长度比的经验范围0.5-1.2。通过对我们语料库中语料的统计(图1),发现语料库中大部分汉英平行句对的长度比在该经验范围内。实验中我们取经验值θ=0.85对汉英长度比进行归一化处理。
文献[11]进一步指出句子长度的差值也是一个衡量平行句对质量好坏的重要标志。所以我们分别选取源端句子长度和目标端句子长度、两者的差值以及两者的归一化后的商作为句对特征。
未对齐词数量

文献[11]指出,在经过词语对齐后平行句对间产生对齐链。一般来讲,对齐链越多,说明句对间互译的单词越多,句对成为平行句对的概率也就越大。所以未对齐词的数量也能够说明平行句对质量的好坏。在此,我们把源端和目标端的未对齐词数量和未对齐词所占百分比作为句对特征。

图1 语料库中汉英句对不同长度比所含句对数量分布
最长对齐一致性片段和最长连续未对齐片段的长度
文献[11]指出最长对齐一致性片段的长度和最长连续未对齐片段的长度对句对是否平行有着很强的提示信息。这也和我们的直观感觉相符合。所以本文中也将这两者选择作为句对特征。
4 实验
实验训练汉英双语语料含有150万句对,由实验室内部语料100万句对和实验室网络挖掘语料50万句对混合构成。汉语句子平均句长为15,英语句子平均句长为17。对于训练语料,我们使用GIZA++[13]工具包进行双向对齐,然后采用“growdiag-final-and”策略获得多到多的词语对齐。使用搜狗新闻语料训练汉语语言模型,使用Gigaword语料中新华部分训练英语语言模型,使用SRILM工具[14]训练的四元语言模型,模型使用KN方法进行平滑。双语词典使用LDC汉英双语词典,含有汉语英文互译词汇54 170对。
4.1 语料筛选实验
语料筛选流程:
1.对所有的句对计算所有(共18个)特征得分。
2.按基于双语词典的翻译质量得分(双向)由高到低,翻译模型得分(双向)由高到低,句子长度商值归一化得分(单向)由低到高分别对句对进行排序,总共得到五个排序结果。
3.根据五个排序,分别取排序的前m%和后n%判别为伪正例句对与伪负例句对。如果句对在五个排序中都被判别为伪正例句对,我们取其为正例句对。类似的,如果句对在五个排序中都被判别为伪负例句对,我们取其为负例句对。其他句对作为待分类句对。(实验中取m=30n=30,关于m,n的讨论见后文)
4.所有正例句对和负例句对组成训练集,使用所有的特征,训练最大熵分类器。
5.使用训练好的最大熵分类器对待分类句对进行分类。得到分类结果。
在本实验中,我们在步骤3取得473 249句对作为训练集,其中包括193 445个正例句对,279 804个反例句对。在该训练集上训练分类器,使用该分类器对1 026 751个待分类句对进行分类,判别待分类句对中682 145个句对为正例句对。最后,我们使用所有的875 590个正例句对作为我们选出的新训练集进行翻译实验。分类过程中训练句对和待分类句对中正负例句对的数量如表1所示。

表1 分类过程中训练句对和待分类句对中正负例句对的数量
4.2 机器翻译实验
4.2.1 实验设置
实验评测语料使用NIST2002年的评测语料(NIST02)作为开发集。NIST2005,2008年的评测语料(NIST05,NIST08)作为测试集。语言模型使用语料筛选试验中的英语4元语言模型。实验使用开源的基于短语的统计机器翻译moses系统[15],短语抽取限制长度为7,采用 msd-bidirectional-fe调序模型。机器翻译实验中使用最小错误训练方法[16]优化线性模型的参数,采用大小写不敏感的IBM BLEU-4[17]作为评测指标。为了更合理的评测我们的方法,本文设置如下7个翻译系统:
All:使用所有训练句对训练翻译系统。
Pos:使用所有正例句对训练翻译系统。
Neg:使用所有负例句对训练翻译系统。
Rand1:从所有训练句对中随机选取与正例句对数量相等的句对组成句对集合,训练翻译系统。
Rand2:从所有训练句对中随机选取与负例句对数量相等的句对组成句对集合,训练翻译系统。
RandPos:从正例句对集合随机选取与负例句对数量相等的正例句对组成句对集合,训练翻译系统。
Pos+recallNeg:在Pos系统的已有正例句对语料基础上,对每个负例句对进行检测,若该负例句对源端含有Pos系统训练集未覆盖到的新词,则将该句对加入到训练集中,否则跳过。使用最终得到的训练集合训练翻译系统。
4.2.2 实验结果及分析
通过表2的实验结果我们可以观察到各个系统在开发集和测试集上的译测结果。Pos系统对比All系统在两个测试集合上均取得更好的BLEU值(NIST05:+0.74NIST08:+0.87),测试集平均BLEU值提高了0.80个百分点。Pos系统不仅在BLEU值的取得提高,还减小了训练语料的规模——训练句对的数量减少近40%,缩减短语表规模,加快翻译速度。但是在删掉部分语料后,语料的覆盖度降低,测试集翻译结果中未翻译词的数量对比All系统增加了23%。
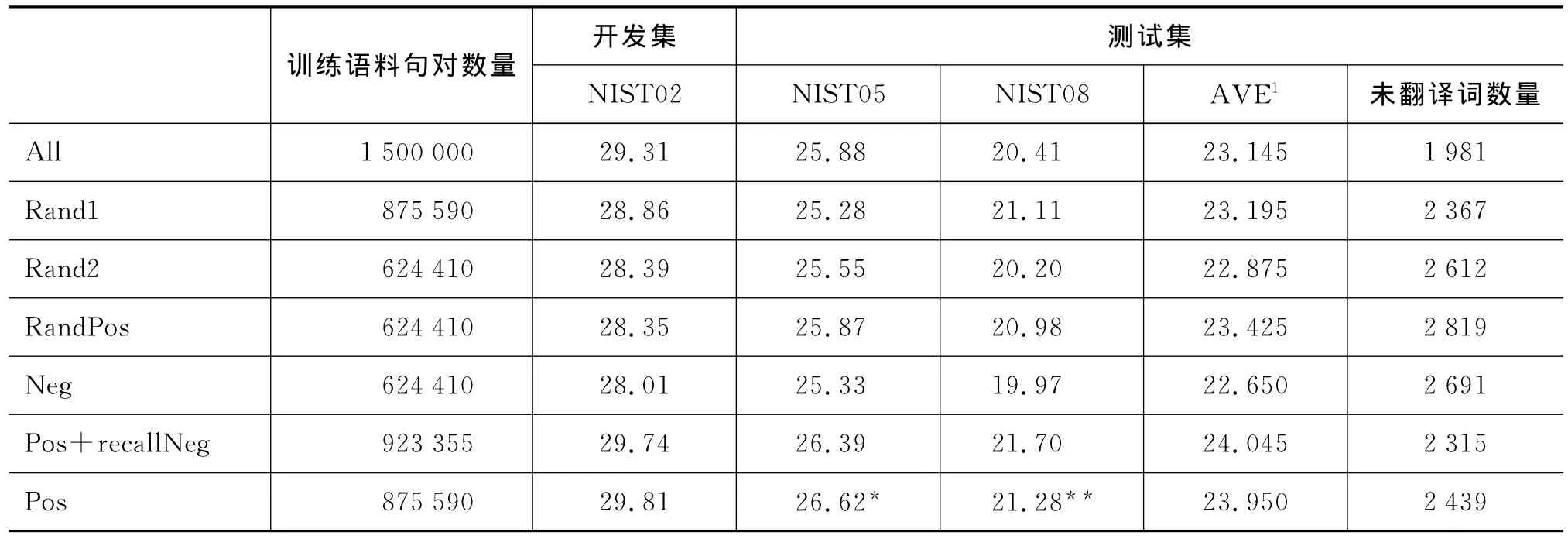
表2 各个系统在开发集测试集的结果。*和**分别表示显著性测试中ρ<0.05和ρ<0.01
对比Pos系统与Rand1系统的结果,在训练句对数量相等的情况下,两个测试集都取得更好的结果。这也说明我们选择的正例句对有着更高的质量。现在的疑问是,未被选择的句对即Pos系统中未使用的负例句对质量如何?我们可以观察Rand2系统、RandPos系统、Neg系统的结果,我们可以看出在训练语料句对数量相等,未翻译词数量相当的情况下,RandPos系统BLEU 值、Rand2系统BLEU值、Neg系统的BLEU值在两个测试集上依次递减。这也和我们的预期所相符。RandPos系统与Neg系统结果的差异也表明正负例句对质量的差异较大。
Rand2系统、Rand1系统、All系统的训练语料的句对数依次增加,但两个测试集合的BLEU值并非依次上涨。这与语料的选择有关,因为我们是随机选择的部分语料,新加入的语料中可能参杂着非平行句对,导致测试结果的BLEU值没有增长。
为了提高语料覆盖度,针对未翻译词处理,我们加入了Pos+recallNeg系统对训练语料进行如下处理:检查每个负例句对,如果负例句对的源端含有正例句对源端单词集合未出现的单词,我们就将此负例句对加入训练集合。在略微增大训练集规模的情况下,减少了未翻译词的数量,进一步提高译文BLEU值。对比Pos系统,Pos+recallNeg系统增加了47 765个句对。其翻译结果中的未翻译词对比Pos系统有所减少,但是仍比All系统多,这与我们预估有所不同。考虑未翻译词出现的原因,一是测试集中存在未登录词。二是测试集中存在的某个词,但是包含该词翻译的译文没有被选为最优译文而被抛弃。对比All系统与Pos+recallNeg系统的未翻译词,发现All系统未翻译词并非Pos+recall-Neg系统的未翻译的子集,证明是第二点原因导致Pos+recallNeg系统的未翻译词数量很多。在测试集BLEU值方面,对比Pos系统,虽然在NIST08测试集提升0.42,但是另外一个测试集NIST05上却降低(NIST05:-0.23)。其原因是添加负例句对,虽然在语料覆盖度问题上有所改善,但是负例句对的增加导致训练语料的整体质量降低,翻译性能无法取得提升。这也说明在选取语料不仅要保证语料覆盖度,同时要保证语料质量。
5 结论和未来工作
本文提出一种自动的基于分类的平行语料选择方法。利用少数特征选取差异较大的少量句对构建训练集,在该训练集上我们使用更多的特征训练一个分类器,从而对余下平行语料进行分类,以选择高质量的句对。实验表明,使用过滤后的平行语料在规模仅为原始语料的60%的情况下翻译BLEU值能有所提高。
值得注意的是,我们所构造的分类器训练正负例句对是通过取交集的方式构建得到,我们根据 对每个特征排序取前m%和后n%构造伪正负例句对,然后取交集得到分类器训练正负例句对。这里选取的正负例句对并不是真实的。在本文中为减少实验复杂度,我们取m=30,n=30进行试验。但我们可以引入已有信息对语料质量进行判断,从而帮助我们更加合理地设置m,n的取值。换言之,m,n取值可以依赖于我们自身对语料质量的评估。比如,对从网络的获取的语料,通过设置m取值小于n,构造出数量少的训练正例句对。对人工构造的平行语料,我们可以调整m大于n从而获得较多的训练正例句对。引入更多信息,能够帮助我们更好进行语料选择。
未来工作从以下方面展开。如何构造训练分类器的训练句对是语料选择关键的一步。我们在将来会进一步探索其他句对特征,构造更具区分性的分类器训练句对。
致谢
该研究工作是第一作者在中国科学院计算技术研究所自然语言处理研究组客座实习期间完成的。涂兆鹏的工作是其在计算技术研究所自然语言处理研究组读博期间完成。感谢苏州大学姚建民教授和中国科学院计算所自然语言处理组吕雅娟研究员对本研究的支持,感谢谢军博士和涂兆鹏师兄对本文工作的悉心指导。
[1]Koehn P,Och F J,Marcu D.Statistical phrase-based translation[C]//Proceedings of the 2003Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1.Association for Computational Linguistics,2003:48-54.
[2]Chiang D.A hierarchical phrase-based model for statistical machine translation[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2005:263-270.
[3]Yang Liu,Qun Liu,Shouxun Lin.Tree-to-string alignment template for statistical machine translation[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics.2006:609-616
[4]Jun Xie,Haitao Mi,Qun Liu.A novel dependency-tostring model for statistical machine translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.2011:216-226.
[5]Och F J,Ney H.The alignment template approach to statistical machine translation[J].Computational linguistics,2004,30(4):417-449.
[6]陈毅东,史晓东,周昌乐.平行语料库处理初探:一种排序模型[J].中文信息学报增刊,2006:66-70.
[7]姚树杰,肖桐,朱靖波.基于句对质量和覆盖度的统计机器翻译训练语料选取[J].中文信息学报,2011,25(002):72-77.
[8]黄瑾,吕雅娟,刘群.基于信息检索方法的统计翻译系统训练数据选择与优化[J].中文信息学报,2008,22(2):40-46.
[9]LüY,Huang J,Liu Q.Improving statistical machine translation performance by training data selection and optimization[C]//Proceedings of the 2007Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning(EMNLP-CoNLL).2007:343-350.
[10]Han X,Li H,Zhao T.Train the machine with what it can learn:corpus selection for SMT[C]//Proceedings of the 2nd Workshop on Building and Using Comparable Corpora:from Parallel to Non-parallel Corpora.Association for Computational Linguistics,2009:27-33.
[11]Munteanu D S,Marcu D.Improving machine translation performance by exploiting non-parallel corpora[J].Computational Linguistics,2005,31(4):477-504.
[12]Munteanu D S,Fraser A,Marcu D.Improved machine translation performance via parallel sentence extraction from comparable corpora[C]//Proceedings of HLT-NAACL 2004:Main Proceedings.2004:265-272.
[13]Franz Josef Och,Hermann Ney.Improved Statistical Alignment Models[C]//Proceedings of the 38th ACL,2000.
[14]Andreas Stolcke. SRILM-an extensible language modeling toolkit[C]//Proceedings of the 7th International Conference on Spoken Language Processing 2002:901-905.
[15]Koehn P,Hoang H,Birch A,et al.Moses:Open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions.Association for Computational Linguistics,2007:177-180.
[16]Och F J.Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1.Association for Computational Linguistics,2003:160-167.
[17]Papineni K,Roukos S,Ward T,et al.BLEU:a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association for computational linguistics.Association for Computational Linguistics,2002:311-318.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
少年博览·初中版(2018年12期)2018-01-18 09:17:58
海外华文教育(2016年1期)2017-01-20 08:21:58
小天使·一年级语数英综合(2016年4期)2016-11-19 10:22:17
小天使·一年级语数英综合(2016年6期)2016-05-14 12:21:05
汽车观察(2016年3期)2016-02-28 13:16:36
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
小天使·一年级语数英综合(2015年10期)2015-10-14 06:30:06
