
基于集成学习的半监督情感分类方法研究
2013-04-23 10:10王中卿李寿山
中文信息学报 2013年3期
高 伟,王中卿,李寿山
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
1 引言
随着互联网的迅猛发展,人们越来越习惯于在网络上表达自己的观点,从而使网络上涌现出大量带情感的文本。作为自动处理和分析这些文本一项基本任务,情感分类渐渐受到重视,并逐渐发展为自然语言处理中一项越来越受关注的研究课题[1-3]。情感分类是指对用户发出的主观性文本进行分析和挖掘,判断其表达的情感色彩是褒义(Positive)或贬义(Negative)。目前,关于情感分类的研究,主要集中在监督学习方面。尽管监督学习方法在情感分类中已经取得了非常好的效果[4-5],但是由于监督学习需要大量人工标注的训练样本,从而使得监督学习的分类系统需要一定的人工标注和时间代价。一种解决方案是采取无需标注样本的分类方法,即非监督学习方法。然而,非监督学习方法的分类效果与实际要求相比还存在一定差距[6-7]。另外一种解决方案是采取综合利用少量已标注样本和大量的未标注样本来提高学习性能的半监督情感分类方法[8-10]。本文主要围绕半监督情感分类方法进行展开。
在半监督情感分类方法中,存在多种不同类型的分类方法。其中一类方法是通过少量标注样本在大量未标注样本中进行学习,从而自动获得未标注样本的标签,然后用这些自动标注样本去更新训练模型。例如,这类方法中常用的协同训练(Co-training)方法和标签传播(Label Propagation)方法。然而,情感分类中的半监督学习是一件比较困难的事情,在使用这类方法对未标注样本进行标注的过程中,会产生很多的误标注样本。误标注样本的产生通常会对最终的分类结果造成不良影响。
本文提出了一种基于集成学习的半监督情感分类方法,通过不同的半监督学习方法针对未标注样本进行标注,最终选取各个半监督学习方法标注一致的样本加入标注样本中更新训练模型。这种方法的优势在于其舍弃那些标签不一致的样本,从而减少误标注的非标注样本对分类性能产生的不良影响。具体实现过程中,我们选取改进的协同训练算法[11]以及标签传播算法[12]作为基本的半监督学习算法,并在上述两种算法生成的分类器针对未标注样本进行标注之后,选取两者标注一致的样本加入标注样本中集中训练分类模型。理论和实验分析都表明,本文提出的基于集成学习的半监督情感分类方法能够有效降低对未标注样本的误标注率。实验结果表明,本文方法的分类性能明显优于各个单独的半监督学习方法。
本文其他部分安排如下:第2节详细介绍情感分类的相关工作;第3节提出基于集成学习的半监督情感分类方法;第4节给出实验结果及分析;第5节给出相关结论,并对下一步工作进行展望。
2 相关工作
早期的情感分类研究主要集中在无监督学习方法。无监督学习一般是通过两个词之间的关系以及一些资源比如WordNet/HowNet或者未标注数据来判断文本的情感倾向[13]。这类基于词典的无监督学习方法的分类效果往往较差,并不能很好地满足实际应用的需求。
基于监督学习的情感分类方法是当前的主流方法,最早由文献[5]将多种分类方法引入情感分类任务中并取得了很好的分类效果。后续的大量研究工作都致力于通过各种途径来改善基于监督学习情感分类的性能。已有学者将集成学习引入到监督学习中,并成功提高了分类器的性能[14]。
近几年来,基于半监督学习的情感分类渐渐受到广大研究者们的重视。Wan将两种不同语言(英语和汉语)作为两个不同的视图,采用协同训练方法进行半监督情感分类[15];Li等则是把评价语句分为个人视图(Personal View)和非个人视图(Impersonal View)并同样采用协同训练方法进行半监督情感分类[16]。Dasgupta和Ng将谱聚类、主动学习、直推学习和集成学习引入到半监督学习中[8],但仍未获得较高的分类准确率(在初始标注样本为100时,Book和DVD领域的准确率只有60%)。苏艳等对协同训练方法进行改进,提出了基于动态随机特征子空间的协同训练算法,并实验验证了当特征子空间数目为4左右的时候,该半监督分类方法能够取得最佳性能[11]。半监督的情感分类方法还存在一种特殊的实现方式:少量标注样本结合情感词典的方法。例如,Sindhwani和Melville提出了基于二部图的半监督学习方法,同时实现了篇章级和词语级的情感分类[17];Li等则基于限制性非负矩阵分解(Constrained Non-negative Tri-factorization)的方法实现了这种方式的半监督学习情感分类任务[18]。
本文提出的方法不同于以上任何一种半监督分类方法,是一种集成方法,即在已有几种半监督分类方法的基础上,利用多种半监督学习方法的融合进一步提高分类性能。据我们所知,本文是首次提出面向情感分类的半监督集成学习方法,即使在传统的主题文本分类中,也没有关于半监督方法的集成学习的相关研究。
3 基于集成学习的半监督情感分类方法
3.1 半监督集成学习的总体框架
半监督集成学习是指融合多种半监督学习方法的一种学习机制。在给定标注样本和未标注样本的情况下,不同的半监督学习方法可以通过各种融合算法,形成一种新的基于集成学习的半监督学习方法。图1为半监督集成学习的一个总体框架。

图1 半监督集成学习总体框架图
通常来讲,差异性是影响集成学习性能的一个重要因素。参与融合的方法差别越大,集成学习的性能提高会越明显。因此,我们选用不同的半监督学习方法进行集成学习。目前存在很多的半监督学习方法,其中由Blum和Mitchell提出的协同训练算法,已有很多研究者对其进行了研究和改进,并取得了进展,使得协同训练成为半监督学习中非常经典的一种方法[19]。此外,标签传播算法(LP)也是一种常用的半监督学习方法。我们将选取这两种半监督学习方法进行集成学习研究,下面简单地介绍这两种算法。
3.2 半监督学习方法简介
3.2.1 基于随机动态特征子空间生成的协同训练算法
Co-training算法需要两个独立视图从而训练两个分类器, 然后采用互助方式迭代地扩充带标记数据集并重新训练。为了获得两个独立视图,苏艳等提出了一种基于随机特征子空间的方法用于产生两个不同的特征子空间[11]。具体实现中,基于动态随机特征子空间生成的协同训练算法,是将每一个特征子空间作为文本的一个表示视图,多个特征子空间对应多个文本表示的不同视图。在这些视图下,应用协同训练算法进行半监督学习。下面详细介绍了基于随机动态特征子空间生成的协同训练算法流程。
输入:
已标注初始样本集合L,包含n+个正类样本和n-个负类样本;
未标注样本集合U;
输出:
更新后的标注样本集合L;
程序:
进行N次迭代,直到U=∅结束循环:
(1)B=∅,B表示每次迭代后从U中挑选出自信度最高的标注样本;
(2) 将L和U的特征空间随机分成m个特征子空间;
(3) 训练m个子空间分类器F1,F2, …,Fm;
(4) 分别使用F1,F2, …,Fm对未标注样本集U进行分类;
(5) 对于每个子空间分类器,从分类结果中选择出自信度最高的一个正类样本和一个负类样本,添加到B中;
(6) 将B添加到标注样本中(L=L∪B),从U中删除B(U=U-B)。
3.2.2 标签传播算法(LP)
在许多关于情感分类的研究中,文档通常用词袋(Bag-of-words)模型化并用向量形式描述。在这些设置中,单词与文档间的关联是不清晰的。为了更好地捕捉单词和文档之间的关系,本文采用基于文档—词的二部图表述文档与单词的关系。文档—词的二部图的连接关系由文档和词的连接矩阵表示,即n×V矩阵X:n为文档数目,V为词的数目。文档—词的二部图仅存在文档到词及词到文档的连接关系。具体来讲,文档到词及词到文档的转移概率计算如下:

输入:
已标注初始样本集合L,包含n+个正类样本和n-个负类样本;
未标注样本集合U;
输出:
更新后的标注样本集合L;
程序:
(1) 初始化:
P:n×r标注矩阵,同时Pij标识文档i(i=0…n)属于类别j(j=1…r)的概率
PL:P0的前m行对应的m个标注实例L
PU:P0的后n-m行对应的n-m个未标注实例U


(2) 循环迭代N次直到收敛;
3.3 基于集成学习的半监督情感分类方法
由于在半监督学习中,只存在少量的标注样本,每个基分类器无法获得较高的准确率,因此对于每个未标注样本所属类别的预测概率并不准确。为了加入正确率更高的非标注样本,我们提出了一种基于一致性标签的样本融合方式,用于融合以上两种不同的半监督情感分类方法。具体来讲,给定标注样本和未标注样本,首先利用两种不同的半监督学习方法对未标注样本进行标注,然后对标注结果进行融合,选取标注一致的未标注样本加入标注样本中。用更新后的标注样本对测试样本进行分类。值得一提的是,我们仅选用两种不同的半监督学习方法进行集成学习,对于多个半监督学习方法来说,我们的方法可以很容易推广,即考虑对其中任意两种方法进行一致性标签融合。直观上,这种方法能够在一定程度上降低半监督学习中对未标注样本的误标注率,从而改进半监督情感分类方法的性能。下面详细介绍了这种基于集成学习的半监督情感分类训练集产生的流程。
输入:
已标注初始样本集合L,包含n+个正类样本和n-个负类样本;
未标注样本集合U;
输出:
更新后的标注样本集合L;
程序:
(1)B=∅,B表示最终选择的标注一致的样本集合;
(2) 用不同的半监督学习算法Fi(i=1, 2) 对U中的每个样本X进行标注,标注结果为
Li(X)(Li(X)=c1, …,cm);
(3) 依次取出U中的每个样本X:
若L1(X)=L2(X)=c
将未标注样本X标注为类别c且将标注后的X添加到B中;
(4) 将B添加到标注样本中(L=L∪B),并从U中移除。
基于一致性标签融合的半监督情感分类方法降低了由于未标注样本被误标注,引入大量噪声数据对半监督学习性能产生的负面影响,对未标注样本的标注准确率高于每一个参与集成学习的半监督学习方法。
下面是关于一致性标签融合方法能够提高未标注样本的分类正确率的理论分析。首先,我们定义两个函数,其中Li(X)为半监督学习算法Fi对未标注样本X的分类结果:
根据上面的算法流程,我们可以得到式(1)。
其中LES(X)为集成学习系统对未标注样本的标注(即选择各个子半监督学习方法一致性的标注),real(X)为样本X的真实标签。
其中E1(X)=1并且LES(X)=c(c为某一类别)
每一个子半监督学习算法Fi对未标注样本的分类准确率,也可以用其对每个未标注样本正确分类的概率表示,即P(Li(X)=real(X)),简单表示为Pi。我们假设每个半监督学习算法对未标注样本的分类过程是相互独立的,则:
P(LES(X)=real(X))=P1×P2
(3)
P(E1(X)=1)=P(L1(X)=L2(X)=real(X))
+P(L1(X)=L2(X)≠real(X))
(4)
由于情感分类的结果只有两种类别,正极性或是负极性,我们又可得到式(5)。
结合式(1)、(3)、(4)、(5)得式(6)。
设Pbest=MAX(P1,P2),为了证明基于集成学习的半监督情感分类方法降低了子半监督学习方法的误标记率,即其加入的样本有更高的标记准确率,我们需要证明式(7)。
我们不妨假设Pbest=P1, 则式(7)又可写成式(8)。
进一步化简得式(9)。
即证P2>0.5,也就是说每个子半监督分类算法的准确率要超过一个随机分类器(每个样本只可能属于两种类别,随机分类器准确率可达0.5),这个条件对一个半监督分类算法是很容易满足的。所以我们认为基于集成学习的半监督情感分类方法可获得比各个子半监督分类方法更低的误标注率,从而控制了噪声数据的负面影响,进一步获得对测试样本更高的分类准确率。
4 实验
4.1 实验设置
本实验数据包括两个数据集:四个领域的产品评论语料,具体包括Books、DVD、Electronics和Kitchen四种不同的产品评论和电影(Movie)领域语料[5]。每个领域包含1 000篇正类和1 000篇负类评论。实验采用MALLET机器学习工具包中的最大熵分类器*http://mallet.cs.umass.edu/,分类算法的所有参数都设置为默认值。分类选取词的一元特征(Unigram)作为特征。数据方面,我们给出两个不同的实验设置: (1)随机选取5%样本作为初始标注样本,85%样本作为未标注样本,剩余10%样本作为测试样本;(2)随机选取10%样本作为初始标注样本,80%样本作为未标注样本,剩下10%样本作为测试样本。其中子半监督学习方法为上文介绍的基于动态随机特征子空间生成的协同训练算法和标签传播算法(LP)。考虑到随机特征子空间生成的随机性问题,每次实验我们取10次实验结果的平均值作为最终结果。
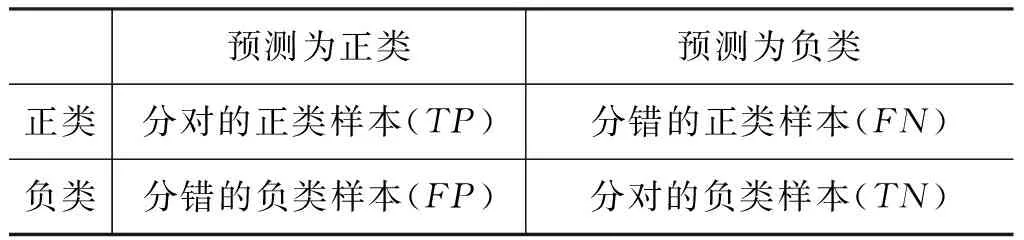
表1 两类问题的混淆矩阵
表1中的数据用来评估分类效果。其中,TP和TN代表了被正确分类的正类样本和负类样本,FP和FN代表了被错误分类的正类样本和负类样本。在情感分类问题中,通常使用准确率(A-ccuracy,Acc.)衡量分类效果。
为了更好地体现我们的方法对噪声数据的控制程度,我们引入误标注率(Mistakenly Labeled Rate,MLR),用来衡量加入到标注样本中的错误标注样本所占的比例。
其中A为所有加入到标注样本中的样本,FA为加入到标注样本中的错误标注样本。
4.2 实验结果与分析
我们实现以下常见的半监督学习方法的比较研究:
(1)Baseline:对未标注样本不做任何处理,直接使用标注样本训练分类模型。
(2)Co-training:基于随机动态特征子空间生成的协同训练算法,已有文章证明,将m设置为4,即将特征空间分成四个特征子空间,能够获得的分类效果已经优于Li et al.(2010)提出的Personal/Impersonal视图的co-training算法[10],可以认为是目前情感分类半监督学习中最好的方法之一。具体算法流程参见3.2.1节。
(3)LabelPropagation:标签传播算法,具体算法流程参见3.2.2节。
(4)我们的方法:对每个子半监督学习算法进行一致性标签融合,选择标注一致的未标注样本更新初始标注样本,即本文重点提出的方法,实验中两个子半监督学习方法分别为Co-training和Label Propagation。
图2显示当初始标注样本5%时,各种半监督学习方法的分类性能比较。从图中结果可以看出,我们的方法获得的分类效果明显优于其他方法,分类准确率比单独使用Co-training和LP算法分别平均提高了3.1%和5.2%。图3显示当初始标注样本10%时,各种半监督学习方法的分类性能比较。从图中结果可以看出,我们的方法同样获得最佳的分类效果,分类准确率比单独使用Co-training和LP算法分别平均提高了2.1%和3.8%。
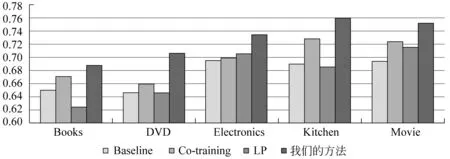
图2 初始标注样本5%时不同半监督分类方法情感分类性能比较
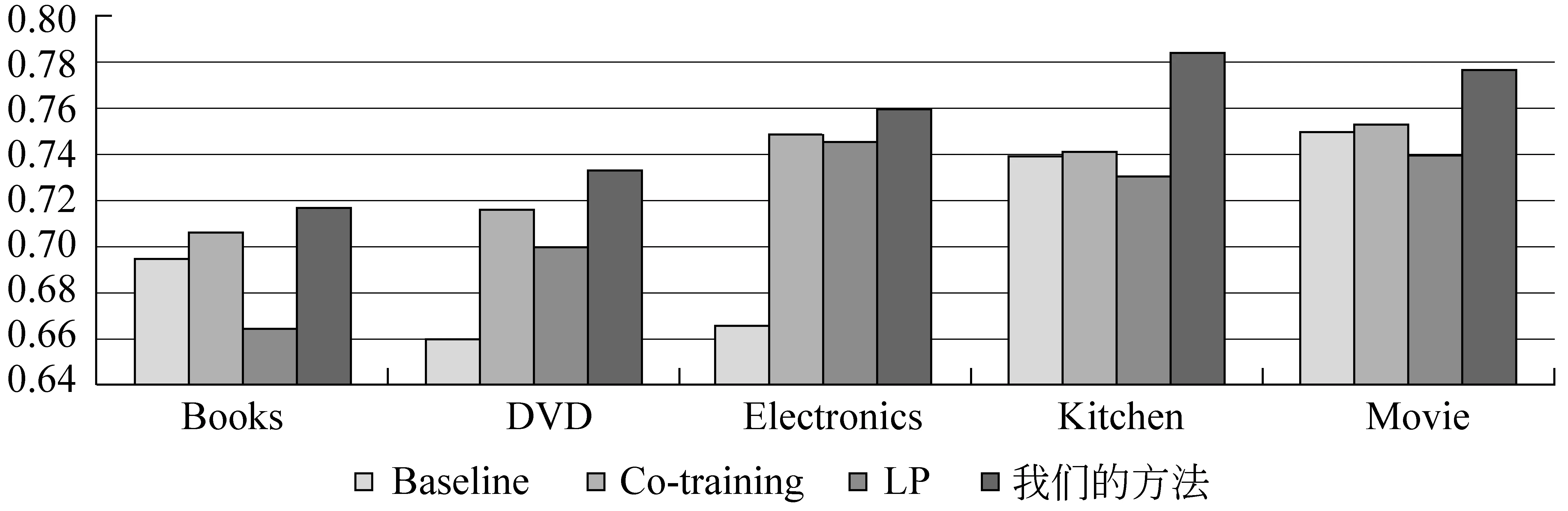
图3 初始标注样本10%时不同半监督分类方法情感分类性能比较
表2初始标注样本5%时各种半监督学习算法误标注率比较
表2和表3分别显示当初始标注样本为总样本的5%和10%的时候,各种半监督学习方法误标注率结果。从表中可以看出,融合后的算法对未标注样本的误标注率有明显下降。Co-training方法的样本误标注率平均超过25%,LP的误标注率平均超过35%,而我们的方法的平均误标注率仅在13%左右。
表3初始标注样本10%时各种半监督学习算法误标注率比较

领域Co-trainingLP我们的方法Book0.250.410.12DVD0.260.390.11Electronic0.230.360.10Kitchen0.230.350.10Movie0.220.320.08
5 结论和下一步工作
本文研究基于集成学习的半监督情感分类问题,提出了一种基于一致性标签融合的半监督集成学习方法用于情感分类任务。该方法能够降低半监督学习算法对未标注样本的误标注率,具有一定的噪声过滤功能。实验结果表明,我们的方法能够进一步提高半监督情感分类的分类准确率,性能明显优于各个单独的半监督情感分类方法。
本文实验中,所使用的特征是词的一元特征(Unigram)。我们计划在下一步工作将尝试把词的二元特征(Bigram)应用到半监督情感分类中,进一步提高分类性能。此外,本文实验中只用了两个子分类器进行标签一致性融合,直觉上,多个分类器进行标签一致性融合势必导致参与融合的样本数目减少,分类器性能与子分类器数目并非成正比关系,在下一步工作中,我们将探索多分类器融合问题,我们也将尝试将其他的半监督学习方法参与集成,进一步对集成学习方式进行探索。
[1] 黄萱菁, 赵军. 中文文本情感分析[J]. 中国计算机学会通讯, 2008, 4(2).
[2] 赵军,许洪波,黄萱菁,等. 中文倾向性分析评测技术报告[C]//第一届中文倾向性分析评测会议, 2008.
[3] 刘鸿宇,赵妍妍,秦兵,等. 评价对象抽取及其倾向性分析[J]. 中文信息学报, 2010, 24(1): 84-88.
[4] 唐慧丰, 谭松波, 程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报, 2007, 6(2).
[5] Pang B, L Lee, S Vaithyanathan. Thumbs up? Sentiment Classification using Machine Learning Techniques[C]//Proceedings of EMNLP-02,2002.
[6] Zagibalov T, J Carroll. Automatic Seed Word Selection for Unsupervised Sentiment Classification of Chinese Test[C]//Proceedings of COLING-08,2008.
[7] Yarowsky D. Unsupervised Word Sense Disambiguation Rivaling Supervised Methods[C]//Proceedings of ACL-95:189-196.
[8] Dasgupta S, V Ng. Mine the Easy, Classify the Hard: A Semi-Supervised Approach to Automatic Sentiment Classification[C]//Proceedings of ACL-IJCNLP-09,2009.
[9] Wan X. Co-Training for Cross-Lingual Sentiment Classification[C]//Proceedings of ACL-IJCNLP-09,2009.
[10] Li S., C. Huang, G. Zhou, and S. Lee. 2010. Employing Personal/Impersonal Views in Supervised and Semi-supervised Sentiment Classification[C]//Proceedings of ACL-10.
[11] 苏艳,王中卿,居胜峰,等.基于随机特征子空间的半监督情感分类方法研究[J].中文信息学报,2012,26(4): 85-92.
[12] Zhu X. and Z. Ghahramani. 2002. Learning from Labeled and Unlabeled Data with Label Propagation. CMU CALD Technical Report.CMU-CALD-02-107.
[13] Turney P. Thumbs up or Thumbs down? Semantic Orientation Applied to Unsupervised Classification of reviews[C]//Proceedings of ACL.2002.
[14] 李寿山, 黄居仁.基于 Stacking组合分类方法的中文情感分类研究[J].中文信息学报,2010,24(5): 56-61.
[15] Wan X. Co-Training for Cross-Lingual Sentiment Classification[C]//Proceedings of ACL-IJCNLP-09.
[16] Li S, C Huang, G Zhou, et al. Employing Personal/Impersonal Views in Supervised and Semi-supervised Sentiment Classification[C]//Proceedings of ACL-10,2010.
[17] Sindhwani V, P Melville. Document-Word Co-regularization for Semi-supervised Sentiment Analysis[C]//Proceedings of ICDM-08,2008.
[18] Li T, Y Zhang, V Sindhwani. A Non-negative Matrix Tri-factorization Approach to Sentiment Classification with Lexical Prior Knowledge[C]//Proceedings of ACL-IJCNLP-09,2009.
[19] Blum A, T Mitchell. Combining Labeled and Unlabeled Data with Co-training[C]//Proceedings of COLT-98,1998.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电子技术与软件工程(2019年18期)2019-11-18
中国惯性技术学报(2018年4期)2018-11-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子技术与软件工程(2017年14期)2017-09-08
电脑爱好者(2017年7期)2017-05-06
Coco薇(2015年11期)2015-11-09
