
基于统计学习模型的句法分析方法综述
2013-04-23 10:15吴伟成周俊生曲维光
中文信息学报 2013年3期
吴伟成,周俊生,曲维光,2
(1.南京师范大学 计算机科学与技术学院,江苏 南京 210023;2. 南京大学 计算机软件新技术国家重点实验室,江苏 南京 210023)
1 引言
句法分析是自然语言处理的核心技术,是对语言进行深层理解的基石。句法分析的任务是识别出句子所包含的句法成分以及这些成分之间的关系,一般以句法树来表示句法分析的结果。从20世纪50年代初机器翻译课题被提出算起,自然语言处理研究已经有60年历史,句法分析一直是阻碍自然语言处理前进的巨大障碍。句法分析主要有以下两大难点:
第一为歧义。自然语言区别于人工语言的一个重要的特点就是它存在大量的歧义现象。人类自身可以依靠大量的先验知识有效地消除各种歧义,而机器由于在知识表示和获取方面还存在严重不足,很难像人类那样进行句法分析消歧。
第二为搜索空间。句法分析是一个极为复杂的任务,候选树个数随句子长度呈指数级增长,搜索空间巨大。因此,必须设计出合适的解码器,以确保能够在可以容忍的时间内搜索到模型定义的最优解或者近似解。
句法分析方法可以简单地分为基于规则的方法和基于统计的方法两大类。基于规则的方法在处理大规模真实文本时,会存在语法规则覆盖度有限、系统可迁移性差等缺陷。随着大规模标注树库的建立,基于统计学习模型的句法分析方法开始兴起,句法分析器的性能不断提高,最典型的就是风靡于20世纪70年代的PCFG(Probabilistic Context Free Grammar,简称PCFG),它在句法分析领域得到了极大应用。统计句法分析模型本质上是一套面向候选树的评价方法,给正确的句法树赋予一个较高的分值,而给不合理的句法树赋予一个较低的分值,这样就可以借用候选句法树的分值进行消歧。
近些年来,基于统计学习模型的句法分析方法受到了研究者们的广泛关注而迅速成为研究热点,多种模型与算法先后被提出。本文依据采用的学习模型和算法类型,将各种统计句法分析模型归为以下五类,试图建立起基于统计学习模型的句法分析方法研究的发展概貌。
(1) 基于PCFG的生成式句法分析模型。基于PCFG的生成式句法分析模型是利用PCFG规则所提供的概率信息来得到生成式模型所定义的最优树,解码方式一般采用线图算法。按照PCFG规则形式,基于PCFG的生成式句法分析模型主要有三类方法: 基于单纯PCFG的句法分析方法、基于词汇化PCFG的句法分析方法、基于子类划分PCFG的句法分析方法。
(2) 基于丰富特征的判别式句法分析模型。基于丰富特征的判别式句法分析模型是将机器学习领域内性能良好的判别式结构化预测方法应用于句法分析领域,目前主要有基于大间隔(max-margin)分析方法和基于CRF的句法分析方法。
(3) 基于移进—归约(shift-reduce)决策的句法分析模型。基于移进—归约决策句法分析模型是从计算机高级语言的编译原理中推广而来,利用分类器对移进和归约决策进行判定,句法分析过程一般采用自底向上、从左到右的方式。
(4) 面向数据的句法分析模型(Data Oriented Parsing,简称DOP)。DOP模型是建立在子树树库的基础上,通过组合树库中子树来完成句法分析。目前主要有两类方法: 基于STSG-DOP (Stochastic Tree Substitution Grammar,简称STSG)方法和基于PCFG-DOP方法。
(5) 多句法分析器的组合。多句法分析器组合是针对单一模型的局限性所作出的改进,对多个高精度的句法分析器输出的结果进行合成。目前的合成方式主要有子树重组合和候选树重排序。
本文首先概要介绍关于句法分析的数据集与评测方法; 然后重点阐述以上五种句法分析模型,着重对各类模型和算法思想进行分析和对比;接下来,对中文句法分析的研究现状进行综述;最后,对句法分析下一步的研究方向与趋势进行展望,特别针对中文句法分析,给出我们的一些想法。
2 句法分析的数据集与评测方法
2.1 句法分析的数据集
目前研究者使用最多的树库来自于美国宾夕法尼亚大学加工的英文宾州树库(Penn TreeBank,简称PTB)[1]。PTB前身为ATIS(Air Travel Information System,简称ATIS)和WSJ(Wall Street Journal,简称WSJ)树库,具有较高的一致性和标注准确性,是目前研究英文句法分析所公认的标注语料库。
中文树库建设较晚,比较著名的有中文宾州树库(Chinese TreeBank,简称CTB)[2]、清华树库(Tsinghua Chinese TreeBank,简称TCT)[3]、中国台湾“中研院”树库(Sinica TreeBank)[4]。CTB是宾夕法尼亚大学标注的汉语句法树库,目前绝大多数的中文句法分析研究均以CTB为基准语料库。TCT是清华大学计算机系智能技术与系统国家重点实验室人员从汉语平衡语料库中提取出100万汉字规模的语料文本,经过自动句法分析和人工校对,形成高质量的标注有完整句法结构的中文句法树库语料。Sinica TreeBank是中国台湾“中研院”词库小组从中研院平衡语料库(Sinica Corpus)中抽取句子,经由电脑自动分析成句法树,并加以人工修改、检验后所得的成果。
2.2 句法分析的评测方法
目前比较主流的句法分析评测方法是PARSEVAL评测体系[5],它是一种粒度比较适中、较为理想的评价方法,主要指标有准确率(precision)、召回率(recall)、交叉括号数(crossing brackets)。
准确率表示分析正确的短语个数在句法分析的结果中所占的比例,即分析结果中与标准句法树中的短语相匹配的个数占分析结果中所有短语个数的比例。
召回率表示分析得到正确的短语个数在标准分析树全部短语个数所占的比例。
交叉括号表示分析得到的某一个短语的覆盖范围与标准句法分析结果的某个短语的覆盖范围存在重叠又不存在包含关系,即构成了一个交叉括号。
除以上定义指标外,F1值也经常被用来衡量句法分析器性能。
3 基于PCFG的生成式句法分析模型
基于PCFG的生成式句法分析模型是目前研究最为充分、形式最为简单的统计句法分析模型,最优树Tbest一般采用概率生成式模型计算,如式(1)所示:
联合概率P(T,S)一般是候选句法树T中所用规则LHS→RHS的概率乘积,如式(2)所示:
本文按照PCFG规则形式,将基于PCFG的生成式句法分析模型分为三类方法: 基于单纯PCFG的句法分析方法[6]、基于词汇化PCFG的句法分析方法[6-11]、基于子类划分PCFG的句法分析方法[12-15]。基于单纯PCFG的句法分析方法在计算树的概率时引入三个基本假设: 位置不变性(place invariance) 假设、上下文无关性(context-free) 假设、祖先节点无关性 (ancestor-free) 假设,它的规则形式最为简单。基于词汇化PCFG的句法分析方法和基于子类划分PCFG的句法分析方法,是对单纯PCFG方法的改进,主要表现在对单纯PCFG所做的三个独立性假设进行突破。基于词汇化PCFG的句法分析方法将短语标记与其某个单词(一般为它的中心词)相关联,引入词汇信息进行消歧。基于子类划分PCFG的句法分析方法引入上下文信息对短语标记进行细分,具体做法有利用语言学知识自定义规则来细分短语标记[12-13]和利用机器学习算法自动对短语标记进行划分[14-15]。若无特殊说明,以下报告的结果均来自于如下实验设置: 训练集WSJ 02-21;测试集WSJ 23。
3.1 基于单纯PCFG的句法分析方法
文献[6]实现了一种基于单纯PCFG的句法分析方法,实验结果为: 召回率70.6%,准确率74.8%。结果并不理想的主要原因在于它所引入的三个基本假设并不符合实际语言情况,难以解决需要上下文信息才可以消除的句法歧义。为了突破PCFG所做的独立性假设,出现了词汇化PCFG方法和子类划分PCFG方法。
3.2 基于词汇化PCFG的句法分析方法
针对单纯PCFG性能低下问题,文献[6]将每个短语标记引入词汇信息,词汇化PCFG的实验结果为: 召回率86.7%,准确率86.6%。同单纯PCFG方法相比,召回率和准确率分别提高了16.1%和11.8%。
为了解决词汇化PCFG后所带来的数据稀疏问题,目前比较成功的方法有用类似最大熵方式来计算规则概率[7]和利用马尔可夫过程对规则进行分解[8]。最大熵优点在于可以考虑更多的特征,而且可以采用删除插值(deleted interpolation)平滑方法来解决数据稀疏问题。受最大熵启发,可以用类似最大熵的方式来计算规则概率,但该方法计算出来的概率不再严格归一,只能看作是评价句法树可能性的分值。该方法的实验结果为:召回率89.6%,准确率89.5%。中心词驱动模型(head-driven model)将每一条规则看作一个马尔可夫过程,即首先由父节点生成中心子节点,然后自右向左依次生成中心子节点左边节点,最后自左向右依次生成中心子节点右部节点。利用马尔可夫过程对规则进行分解后,极大缓解了数据稀疏问题,该方法的实验结果为:召回率88.1%,准确率88.3%。
为了进一步提高词汇化PCFG句法分析器的性能,可以将重排序(reranking)方法引入到句法分析中,但该方法需要一个高精度的基准句法分析器(baseline parser),比较典型的是Collins(1999)[8]中的模型2和Charniak(2000)[7]。Collins(1999)中的模型2采用基于Boosting方法[9]重排序后的结果为:召回率89.6%,准确率89.9%,采用树核方法重排序后的结果为:召回率88.6%,准确率88.9%,虽然结果略低于前者,但算法效率得到了提高[10]。Charniak(2000)采用最大熵方法[11]重排序后的F1值为91.0%。
3.3 基于子类划分PCFG的句法分析方法
与单纯PCFG方法相比,词汇化PCFG方法取得了一定的成功,但同时也产生了非常严重的三大问题: 规则数量急剧上升、数据稀疏问题严重、解析算法复杂度增加。于是,人们不禁要问: 研究者有没有高估词汇信息在句法分析的作用,非词汇化PCFG方法是否还有提高的潜能?文献[12]研究了句法树表示方法与PCFG性能之间的关系,在理论和实践上说明了基于PCFG的句法分析器的性能会随着句法树表示方法的不同而急剧变化。通过为句法树中的每个结点引入其父节点短语标记,句法分析的F1值就可以提高8个百分点。该实验结果表明: 树库中的短语标记粒度过粗,区分度不够,缺少用于消歧的上下文信息。
根据短语在句法树中的上下文信息,可以自定义规则对短语标记进行细分,所利用的上下文信息一般包括父节点和兄弟节点短语标记等。文献[13]在整个实验中,除词性标注外,未使用任何词汇信息,实验结果为: 召回率85.1%,准确率86.3%。虽然性能劣于词汇化PCFG方法,但该方法非常简单、容易理解、易于实现。因此,文献[13]获得了2003年ACL大会的最佳论文奖。
利用EM算法可以自动对短语标记进行划分[14-15]。它首先为原始规则A→BC中短语标记分别标注一个整数类别x、y、z,然后在E步,计算标注规则的期望次数,如式(3)所示:
其中,Pout和PIn分别为内部概率和外部概率;r、s和t为规则的跨度(span);
在M步,通过以上得到的期望次数去更新规则概率,如式(4)所示:
可以每次将短语标记划分为两个子类,然后合并区分不大的划分。该方法实验中使用子类划分后的树库语料,实验结果为: 召回率89.9%,准确率90.2%。
4 基于丰富特征的判别式句法分析模型
随着机器学习领域的蓬勃发展,多种结构化学习模型先后被提出。判别式的结构化学习模型具有可以融合大量有效特征,且能避免在生成式学习模型中需引入的独立性假设等优点,在实际应用中一般比生成式方法性能要好。基于丰富特征的判别式句法分析模型是将机器学习领域内的判别式结构化学习模型应用于句法分析领域,并借用丰富特征来消解句法分析过程中所产生的歧义。目前主要有基于大间隔的句法分析方法[16]和基于CRF的句法分析方法[17]。
4.1 基于大间隔的句法分析方法
大间隔马尔可夫网络(Max-Margin Markov Networks,简称M3N)融合了SVM的大间隔理论与概率图模型处理结构关系的能力[18],可以解决复杂的结构化预测问题,因此可以将它应用到句法分析上[16]。
判别函数采用如下形式:
其中,Φ(x,y)代表与x相对应的句法树y的特征向量;w代表特征权重;
间隔定义为样本
然后最小化权重w:

(7)
其中Li,y为损失函数,ξi为松弛变量。
以上优化问题的对偶形式为:

(8)
其中Ii,y=I(xi,yi,y),指示y与yi是否相同;
主问题的解w*就是正确和错误句法树特征向量的线性组合,如式(9)所示:
其中α*是对偶问题的解。
由于主公式和对偶公式中的变量个数随句子长度呈指数级增长,因此该文对模型进行了分解,将参数数目降为多项式级,最终用类似SMO的方式进行参数学习。该模型在WSJ15(长度小于等于15的句子)上的实验结果为: 召回率89.1%,准确率89.1%。
针对M3N模型训练速度问题,可以采用多个独立而且可以并行训练的二元分类器来代替它,每个二元分类器用于识别一个短语标记,句法分析任务就是通过组合这些分类器来完成,因此分类器的训练速度可以得到很大提高[19-20]。该方法在WSJ15上的实验结果为: 召回率89.2%,准确率89.6%。
4.2 基于CRF的句法分析方法
与基于PCFG的生成式模型相比,采用CRF模型进行句法分析,主要不同点在于产生式的概率计算方法和概率归一化的方式[17]。该模型最大化句法树的条件概率值而不是联合概率值,并且对概率进行全局归一化。
候选句法树的概率估算形式如式(10):
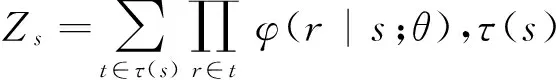
互联网的出现,改变了我们的生活方式与学习方式,也对教育行业提出了新的挑战,近年来,网络教学已经受到越来越多国内外高校的重视网络,网络与教育相结合的呼声日益高涨。《Java程序设计》课程是计算机专业的主修设计课程之一,是一门概念抽象且注重实践性的专业课程。对于该课程来说,传统的教学模式比较单一,课程讲解起来不易理解,如何将泛雅平台应用于《Java程序设计》课程的教学成了各大高校的重中之重。
团势函数(clique potentials) 采用的是指数形式:
训练数据的log似然值为:
以上log似然值对θi求偏导数就是特征的经验期望与模型期望之间的差值:
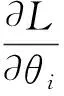
该模型在WSJ15实验结果为: 召回率90.4%;准确率为91.4%,在整个测试集上实验结果为: 召回率87.8%,准确率88.2%。
5 基于移进—归约决策的句法分析模型
基于移进—归约决策句法分析模型是用一个寄存符号的先进后出的栈S,把存在队列Q里面的输入符号一个一个地移进到栈里,当栈顶形成某个规则的一个候选式时,就把栈顶的这一部分归约为该规则的左部符号。决策判定,即执行移进还是归约动作,是由分类器根据当前句法分析状态(S和Q的内容)给出。由此可见,移进—归约决策句法分析采用了自底向上、从左到右的分析过程。该方法的句法分析时间复杂度为O(n),其中n是句子长度[21]。
早期移进—归约决策的句法分析器中采用right、left、up、unary、 root五类决策类别[22-23]。right up left分别表示新节点的起始节点、中间节点、末节点,即right up left 表示可以归为一个新的短语,unary表示要进行一元归约,root表示句法分析任务结束。早期主要有采用决策树和最大熵对以上类别进行分类。决策树所用到的特征包括了词的类别,这些类别需要用聚类方法得到,花费的计算代价很高,解码过程分两阶段完成,虽然引入剪枝策略,与蛮力法相比,相对高效地得到了模型定义的最优解,但是对于某些句子,解码器的搜索空间仍然巨大[22]。最大熵分类器只用到了词本身信息,与决策树相比,模型训练的代价较小,解码方式采用了BeamSearch方法,虽然有可能得不到模型所定义的最优解,但算法的执行效率得到了提高。决策树的实验结果为: 召回率84.0%,准确率84.3%。最大熵的实验结果为: 召回率86.3%,准确率87.5%。
最近比较流行的移进—归约句法分析器将决策类别分为四大类[24]: SHIFT、REDUCE-unary-X、REDUCE-binary-{L/R}-X、TERMINATE。SHIFT表示从队列Q中移出一个词语到栈S中;REDUCE-unary-X表示将要进行一元归约,新生成节点X;REDUCE-binary{L/R}-X表示进行二元归约,新生成节点X,L和R表示X的中心词来自于左孩子节点还是右孩子节点。TERMINATE表示句法分析任务结束。要训练得到基于以上四类决策的句法分析器,需要对树库进行二元转换(binarization transform),X表示二元转换过后的短语标记。虽然决策类别很多,但是分类器的分类性能很高(我们再现了文献[43]中的结果,决策类别达到76个,但是分类精度高达94.7%)。目前主要基于SVM和感知器的移进—归约句法分析器,SVM句法分析结果为: 召回率87.6%,准确率87.5%,虽然结果略低于词汇化PCFG模型,但句法分析速度得到了很大的提高[21]。感知器方法从全局角度对决策进行了考量,在CTB上取得了非常好的结果[24]。
基于移进—归约决策的句法分析模型应用于中文时对词性非常敏感,文献[24]显示: 基于正确词性标注与基于自动词性标注(标注精度为93.5%)的句法分析实验的F1值相差高达9.4个百分点,主要原因是中文词性标注精度不高和该方法需要考虑大量的词性作为特征。
6 面向数据的句法分析模型
DOP模型是建立在包含大量语言现象的树库基础上,通过组合数库中的子树来实现句法分析任务。与基于PCFG的句法分析模型相比,可以将DOP模型中的子树看作文法,PCFG规则是DOP模型文法特殊形式,即子树的高度为1。
本节首先介绍最优树的定义准则,然后介绍两种主流的利用DOP模型进行句法分析的方法: STSG-DOP方法[25-27]和PCFG-DOP方法[28-31]。STSG-DOP方法将DOP思想归结为子树替换过程,而PCFG-DOP方法将STSG-DOP中的子树文法转化为PCFG形式,减少了文法的数量,提高了句法分析的速度。
6.1 最优树的定义准则
DOP模型一个重要特征就是可能有多个有效推导d对应于同一棵候选树T,这就涉及到模型所定义的最优树Tbest准则问题。就目前DOP模型的研究,主要有以下六种准则:
第一个准则为最有可能推导(the Most Probable Derivation,简称MPD)。MPD是在所有可能的有效推导中,找出概率最大的一个有效推导,如式(14)所示:
第二个准则为最有可能分析(the Most Probable Parse,简称MPP)。在MPP中,句法树T的概率是与T对应的所有可能推导dT的概率累加和,如式(15)所示:
计算MPP是NP-hard问题[32],一般采用近似搜索算法,例如Viterbi-n-best方法[27,29]。
第三个准则为最大成分分析(the Maximum Constituents Parse,简称MCP)。MCP考虑了每一个短语cT正确的可能性,挑出具有最大成分的候选树T,如式(16)所示:
MCP是对MPP的近似,可以采用动态规划算法高效地计算MCP[28]。
第四个准则为最大规则和(the Max Rule Sum,简称 MRS)。MRS是由MCP推广而来,候选树T的概率是T中所有规则rT的后验概率累加和,如式(17)所示:
第五个准则为最大规则积(the Max Rule Production,简称MRP)。MRP与MRS类似,将MRS中的累加符号改为累乘符号,如式(18)所示:
MRP的性能一般要优于MRS[15]。
第六个准则为最短推导(Shortest Derivation,简称SD)。以上五种准则是基于概率,而SD是基于推导的长度,选取具有最短长度的推导,如式(19)所示:
从子树的大小来说,SD是比较倾向于大子树。最短推导可能有多个,一般要对最短推导进行排序处理[33]。
6.2 基于STSG-DOP方法
STSG-DOP[25,34]通过组合树库中的子树来完成句法分析。其中,最基本的操作是替换(substitution),句法树概率是通过计算子树的频度得到。
STSG-DOP方法在ATIS树库上取得了成功,但是为了计算MPP,采用Monte Carlo采样算法[26],由于该算法的随机性和缺少应用该算法的进一步细节,有些研究者并不承认该方法在ATIS树库上的结果[28]。但随着各种近似搜索算法和最优树准则的出现,Bod等人摒弃了Monte Carlo算法,出现了结果可再现的高性能句法分析器[27,29-31],使得越来越多的研究者开始关注DOP模型。
由于STSG子树的数量非常大,而且极其冗余,从理论和计算的角度,都需要对数库中的子树进行限制。这自然会产生一个想法: 是否可以减少子树数量同时又可以提高句法分析器的性能?文献[27]针对该问题在WSJ树库上进行了研究,分别考察了子树大小、词汇化上下文、结构上下文、非中心词依赖,在WSJ40(长度小于等于40的句子)上的实验表明: 对子树进行限制确实能够提高句法分析的性能。该文最后将WSJ40取得最好性能的子树选取方法应用在标准测试集上,实验结果为: 召回率89.7%,准确率89.7%,结果略高于之前词汇化模型Charniak(2000)[7],与当时的Collins(2000)[9]的结果相当。
6.3 基于PCFG-DOP方法
PCFG-DOP方法[28]将子树中的每一个外部节点(exterior non-terminal)对应于8种PCFG规则,使得文法数量随树库大小呈线性增长,与STSG-DOP相比,文法数量急剧下降。
PCFG-DOP方法在文献[27]子树选取的基础上的实验结果为: 召回率89.5%,准确率89.7%,虽然召回率略低于文献[27] (相差0.2%),但句法分析的速度提高了60倍[29]。结合SD和MPP准则可以形成两种DOP模型[29]: LS-DOP和SL-DOP,SL-DOP是从N种概率值最高的候选树中,选出推导长度最短的句法树,LS-DOP是从N种推导最短的候选句法树中,选出概率值最高的句法树。SL-DOP实验结果为: 召回率90.7%,准确率90.8%,LS-DOP实验结果为: 召回率89.4%,准确率89.7%。
为了能够高效地利用DOP模型进行句法分析,可以对子树树库规模和文法形式进行改进: 规定树库中的子树数量必须大于等于2(可以利用树核算法高效地抽取所有满足条件的子树[31]),将子树的根节点和叶节点分别映射为PCFG规则的左部和右部,文献[31]的Tbest准则采用MRS,实验的F1值为89.1%。
由于PCFG-DOP方法的文法数量相对较少,可以利用树库中的所有子树进行句法分析,文献[30]的Tbest准则采用MRP,实验的F1值为88.1%,虽然结果低于子树选取后的结果,但是并没有付出昂贵的代价进行子树选取也没有引入词汇信息。
7 多句法分析器的组合
以上介绍的几种句法分析模型有个共同的缺点: 最佳句法树Tbest都是基于单一模型定义的,得到的最优解并不一定最接近实际情况。近些年来,针对单一模型的局限性,另一个研究重点放在多个句法分析器组合上。这种方法是利用多个高精度的基准句法分析器(baseline parser)输出多个高概率值结果,并结合丰富句法结构特征对它们进行合成处理。目前合成方式主要有子树重组合[35-36]和候选树重排序[37]。子树重组合是对候选树中的子树进行重组,形成一个新的最优的句法树。候选树重排序是对候选树分值进行重新估算,选出分值最高的候选树作为最后的分析结果。
子树重组合主要有投票方法和权重相加法。投票法就是首先统计各子树在候选树上的频度,然后选择频度最多的子树来组合成一棵新的句法树,该方法得到的结果偏向于准确率[35]。权重相加法就是利用CKY算法将跨度相同短语标记间的成分权值相加,最后得到能够覆盖整个句子的概率值最大的句法树,该方法得到的实验结果偏向于召回率,为了调和准确率和召回率,一般要引入阈值对候选子树进行剪枝[36]。文献[35]采用投票方法,在实验中采用三个高精度的基准句法分析器,最优性能为: 召回率88.5%,准确率88.7%,进行子树重组合后,实验结果为: 召回率89.2%,准确率92.1%。文献[36]采用权重相加法,在实验中采用五个高精度的句法分析器,最优性能为: 召回率90.6%,准确率91.3%,子树重组合后实验结果为: 召回率91.0%,准确率93.2%。
子树重组合的优点在于利用到了多个高精度的基准句法分析器,但存在两个不足点: 第一,每一个句法分析器只输出一个结果;第二,没有利用到候选句法树的起始概率值,虽然不同句法分析器输出的候选树的概率值不可比较。候选树重排序方法继承了子树重组合的优点,并针对其缺点进行了改进,即让每个基准句法分析器都输出多个最优结果,并且将句法树的起始概率值作为主要特征。文献[37]进行了候选树重排序,基准句法分析器采用Charniak(2000)[7]和Petrov(2007)[15],并且让这两个句法分析器分别输出最优的50个结果,实验的F1值为92.6%。
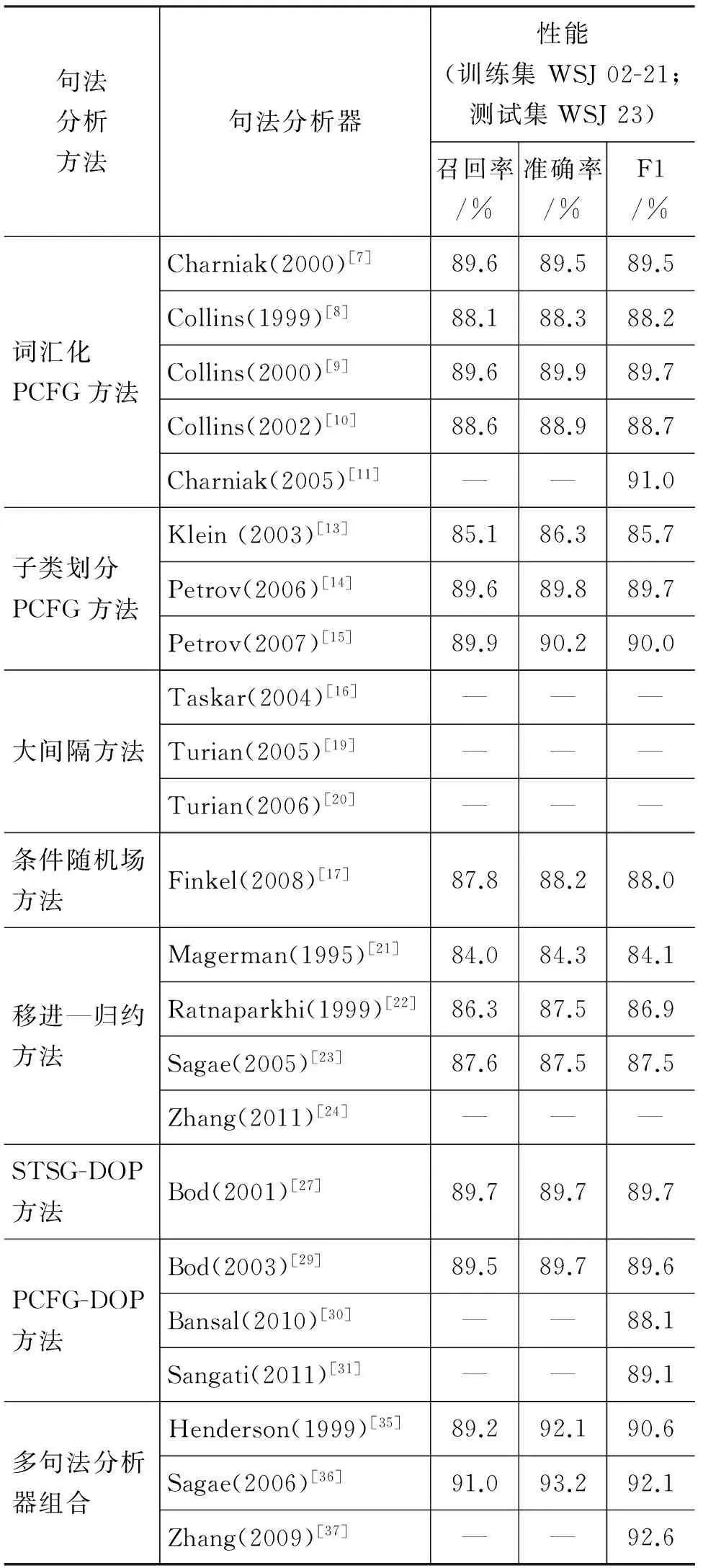
为了便于比较分析,表1列出了各种句法分析方法在英文宾州树库上的句法分析性能。

表1 句法分析器性能比较
续表
8 中文句法分析的研究现状
与英文句法分析相比,中文句法分析的研究相对较晚。按照上文的分类方法,以下将简单综述中文句法分析的研究现状。若无特殊说明,以下报告的结果均来自于如下实验设置: 训练集CTB 001-270;测试集CTB 271-300(基于正确分词且句子长度小于等于40)。
在单纯PCFG方法方面,文献[38]利用内向—外向算法,从已有小规模中文宾州树库中提取规则,利用大规模已做好分词标注的语料库对规则进行训练,并针对汉语的特点(特别是汉语虚词的特点),引入句法结构共现的概念来减弱PCFG的独立性假设。实验结果表明,引入句法结构共现概率能够提高句法分析器的准确率和召回率。
在词汇化PCFG方面,文献[39]将Collins的中心词驱动模型应用于中文,实验结果为: 召回率78.0%,准确率81.2%。文献[40]在中心词驱动模型的基础上,提出了基于语义的模型,并且对基本名词做了特殊处理,实验结果为: 召回率78.7%,准确率80.1%(训练集: CTB 026-270)。文献[41]提出了一个两级的中文句法分析方法,基本短语和复杂短语分别被词汇化的马尔可夫模型和中心驱动模型所识别,实验语料采用哈尔滨工业大学树库,单一模型(中心驱动模型)实验结果为: 召回率86.4%,准确率86.3%;两级的句法分析模型实验结果为: 召回率88.0%,准确率87.5%。
在子类划分PCFG方面,文献[42]自定义规则对短语标记进行划分,引入短语标记的上下文信息,提出了结构上下文相关的概率句法分析模型。实验结果表明,引入结构的上下文信息确实能够提高句法分析的性能。文献[15]将自动划分短语标记的方法应用于中文,实验结果为: 召回率85.7%,准确率86.9%(训练集: CTB 001-270,400-1151)。
在移进—归约决策句法分析方面,文献[43]将移进—归约决策句法分析模型应用于中文,实现了一个高速、准确的确定性中文句法分析器,采用SVM分类器的实验结果为: 召回率78.1%,准确率81.1%。文献[24]利用全局线性模型对决策类别进行了预测,实验结果为: 召回率80.2%,准确率80.5%;文献[44]对移进—归约决策方法进行了扩展,实现了层次式句法分析模型。该方法将句法树的构建转换为层次标注问题,分类器采用最大熵,实验结果为: 召回率76.5%,准确率80.0%。文献[45]又将层次式句法分析模型与语义角色标注进行了联合学习,缓解了语义分析对句法分析结果的依赖,同时又提高了两者的性能。
在多句法分析器组合方面,文献[37] 以Charniak(2000)[7]和Petrov(2007)[15]句法分析器各产生的50-best候选树作为输入,系统合成后,在整个测试集上实验的F1值为85.5%(训练集: CTB 001-270,400-1151)。
9 总结与展望
近十几年来,英文句法分析有了长足的发展,而且已日趋成熟。它的研究趋势主要基于以下两点:
第一点就是基于树库的文法受到了研究者的青睐。与早期的方法相比,现在的句法分析方法更强调从真实的树库中获取文法知识,例如词汇化PCFG方法、面向数据的句法分析方法,使得训练出来的模型更加符合实际情况,因而促进了句法分析性能的提高。
第二点就是统计学习理论在句法分析领域扮演越来越重要的作用。随着各种统计学习算法的提出,研究者开始将各种可以集成丰富上下文特征的判别式学习模型引入到句法分析领域,例如: 应用结构化学习模型CRF和大间隔方法实现句法分析,针对传统生成式模型的不足实现了理论上的改进。
同时也可以看出,这两个因素也引发了一些问题。词汇化PCFG方法带来了非常严重的三大问题,造成训练和测试时需要巨大的时空开销。STSG-DOP方法子树数量巨大,虽然出现了PCFG-DOP方法,减少了文法数量,但是仍然非常冗余,因此,子树的选取也是DOP模型非常值得研究的课题。与传统的生成式模型相比,大间隔方法和CRF方法等判别式学习模型的消歧能力更强,但模型的复杂度也更高,例如M3N模型在WSJ15上训练就需要几个月时间[17]。因此,在应用一些有效的判别式学习模型实现句法分析任务时,如何利用句法树结构的特性设计和实现更有效地学习和训练算法也将会是下一步研究的热点。
值得一提的是,子类划分PCFG方法和移进—归约方法另辟蹊径,取得了比较好的性能。子类划分PCFG方法较好地克服了词汇化PCFG的固有缺点,而且是当今精度最高的单一句法分析模型之一。另外,基于移进—归约决策的句法分析模型将传统的利用线图算法进行句法分析的过程转化为一系列基于分类器的移进和归约决策分类过程,而决策分类可以采用决策树、最大熵、SVM等性能良好的分类器。该句法分析模型具有很强的灵活性和可扩充性。而且该模型应用于中文时取得了较好的性能,且具有句法分析速度快等优点。
中文句法分析相对于英文句法分析还有很长的路要走,但可以借鉴英文句法分析,譬如将大间隔和CRF等判别式学习模型,以及DOP方法应用于中文,相信可以取得性能的提高。基于上述分析,我们提出一些关于改善中文句法分析的几点思路。
(1) 近些年,依存句法分析成为研究热点,依存树反应了词汇间的依存关系,属于语义范畴,提供了比单纯词汇更为丰富的信息,因此更加有利于消歧。文献[46]利用依存结构来辅助句法分析,采用单纯PCFG实验结果就与词汇化PCFG性能相当,充分说明了语义信息对句法分析的作用。受该文启发,可以利用依存结构来辅助其他句法分析模型,也可以将句法分析与后续语义分析任务进行联合学习,以缓解句法分析对语义信息的严重依赖。
(2) 文献[43]在句法分析过程中孤立地在每个步骤应用分类器进行移进和归约决策,而没有考虑每个移进—归约决策的全局效果。文献[24]虽然对文献[43]的方法进行一些改进,但使用的解码算法只是一个近似搜索算法,并不能在迭代过程中搜索出全局最优的移进和归约决策序列,且感知器并不是一个具有良好泛化性能的学习器,因而,该方法在理论上并没有很强的、自然的保证。近来,文献[47] 提出了一种新的基于搜索的结构化预测学习算法SEARN,将复杂的结构化预测问题转换为简单的代价敏感分类问题,且在理论上对该算法的有效性进行了分析和证明。因此,可以考虑将SEARN算法应用到基于移进—归约决策的句法分析模型上,相信能够实现一个性能良好的中文句法分析器。
(3) 由于汉语缺乏形态变化,目前主流的中文句法分析所用的词类标记和短语标记并不能反映其语法功能,而且相同条件下中英文句法分析的结果相差较大[48],因此,有必要进一步研究适合中文自身特点的句法分析器。陈小荷教授提出了彻底按照词的语法功能来划分汉语词类[49]以及基于语法功能匹配句法分析的设想。文献[50]通过实践验证了通过语法功能来处理词语分类以及在句法中进行语法功能匹配是可行的。基于语法功能匹配的句法分析思想目前还处于探索阶段,因此,这种将中文语法特点与一些句法分析模型相结合的研究,也将会是今后一个有意义的研究方向。
致谢感谢英国剑桥大学Zhang Yue博士,与他的讨论使我们受益匪浅。
[1] Mitchell P Marcus, Mary Ann Marcinkiewicz, Beatrice Santorini. Building a Large Annotated Corpus of English:The Penn TreeBank [J]. Computational linguistics, 1993,19(2):313-330.
[2] Naiwen Xue, Fei Xia, Fu-Dong Chiou, et al. The Penn Chinese Treebank:Phrase Structure Annotation of a Large Corpus [J]. Natural Language Engineering, 2005,11(2):207 -238.
[3] 周强.汉语句法树库标注体系[J].中文信息学报, 2004, 18(4):1-8.
[4] Huang Chu-Ren, Keh-Jiann Chen, Feng-Yi Chen, et al. Sinica Treebank:Design Criteria,Annotation Guidelines, and On-line Interface[C]//Proceedings of the Chinese Language Processing Worshop. Stroudsburg: Association for Computational Linguistics, 2000:29-37.
[5] E Black, S Abney, D Flickenger, et al. A Procedure for Quantitatively Comparing the Syntactic Coverage of English Grammars[C]//Proceedings of the DARPA Speech and Natural Language Workshop. Stroudsburg: Association for Computational Linguistics, 1991:306-311.
[6] Eugene Charniak. Statistical parsing with a context-free grammar and word statistics[C]//Proceedings of the 14th National Conference on Artificial Intelligence. MenloPark: AAAI Press/MIT Press, 1997: 598-603.
[7] Eugene Charniak. A maximum-entropy inspired parser[C]//Proceedings of NAACL 2000. San Francisco: Morgan Kaufmann Publishers, 2000:132-139.
[8] Michael Collins. Head-Driven Statistical Models for Natural Language Parsing [D]. Philadelphia: University of Pennsylvania, 1999.
[9] Michael Collins. Discriminative reranking for natural language parsing[C]//Proceedings of ICML 2000: 175-182.
[10] Michael Collins, Nigel Duffy. New ranking algorithms for parsing and tagging: kernels over discrete structures, and the voted perceptron[C]//Proceedings of the ACL 2002. Stroudsburg: Association for Computational Linguistics, 2002:263-270.
[11] Eugene Charniak, Mark Johnson. Coarse-to-fine n-best parsing and maxent discriminative reranking[C]//Proceedings of ACL 2005. Stroudsburg: Association for Computational Linguiscs, 2005:173-180.
[12] Johnson Mark. PCFG models of linguistic tree representations [J]. Computations Linguistics, 1998,24(4):613-632.
[13] Dan Klein, Christopher D Manning. Accurate Unlexicalized Parsing[C]//Proceedings of ACL 2003. Stroudsburg: Association for Computational Linguistics, 2003:423-430.
[14] Slav Petrov, Leon Barrett, Romain Thibaux, et al. Learning accurate, compact, and interpretable tree annotation[C]//Proceedings of COLING-ACL 2006. Stroudsburg: Association for Computational Linguistics, 2006:443-440.
[15] Slav Petrov, Dan Klein. Improved inference for unlexicalized parsing[C]//Proceedings of HLT-NAACL 2007. Rochester, 2007:404-411.
[16] Taskar B, Klein D, Collins M, et al. Max-margin parsing[C]//Proceedings of EMNLP 2004. Barcelona, 2004.
[17] Jenny Rose Finkel, Alex Kleeman, Christopher D Manning. Efficient, feature-based, conditional random field parsing[C]//Proceedings of ACL-HLT 2008. 959-967.
[18] B Taskar, C Guestrin, D Koller. Max margin Markov networks[C]//Proceedings of NIPS 2003. Vancouver, 2003.
[19] Turian J, Melamed ID. Constituent parsing by classification[C]//Proceedings of IWPT 2005. Stroudsburg: Association for Computational Linguistics, 2005.
[20] Turian J, Melamed ID. Advances in discriminative parsing[C]//Proceedings of COLING-ACL 2006. Stroudsburg: Association for Computational Linguistics, 2006.
[21] Kenji Sagae, Alon Lavie. A classifier-based parser with linear run-time complexity[C]//Proceedings of IWPT 2005: 125-132.
[22] Magerman David M. Statistical Decision-Tree Models for Parsing[C]//Proceedings of ACL 1995. Stroudsburg: Association for Computational Linguistics, 1995:276-283.
[23] Adwait Ratnaparkhi. A Linear Observed Time Statistical Parser Based on Maximum Entropy Models[C]//Proceedings of EMNLP 1997.
[24] Yue Zhang, Stephen Clark. Syntactic Processing Using the Generalized Perceptron and Beam Search [J]. Computational Linguistics, 2011,37(1): 105-151.
[25] Rens Bod. A computational model of language performance: data oriented parsing[C]//Proceedings of COLING 1992. Stroudsburg: Association for Computational Linguistics, 1992:855-859.
[26] Rens Bod. Using an Annotated Corpus as a Stochastic Grammar[C]//Proceedings of the Sixth Conference of the European Chapter of the ACL. Stroudsburg: Association for Computational Linguistics, 1993:37-44.
[27] Rens Bod. What is the minimal set of fragments that achieves maximal parse accuracy?[C]//Proceedings of ACL 2001. Stroudsburg: Association for Computational Linguistics, 2001.
[28] Joshua Goodman. Efficient algorithms for parsing the DOP model[C]//Proceedings of EMNLP 1996: 143-152.
[29] Rens Bod. An efficient implementation of a new DOP model[C]//Proceedings of EACL. Stroudsburg: Association for Computational Linguistics, 2003:19-26.
[30] Mohit Bansal, Dan Klein. Simple, accurate parsing with an all-fragments grammar[C]//Proceedings of ACL 2010. Stroudsburg: Association for Computational Linguistics, 2010:1098-1107.
[31] Federico Sangati, Willem Zuidema. Accurate Parsing with Compact Tree-Substitution Grammars: Double-DOP[C]//Proceedings of EMNLP 2011: 84-95.
[32] Sima’an K. Computational Complexity of Probabilistic Disambiguation by Means of Tree Grammars[C]//Proceedings of COLING 1996.Stroudsburg: Association for Computational Linguistics, 1996:1175-1180.
[33] Rens Bod. Parsing with the Shortest Derivation[C]//Proceedings of COLING [C]. Stroudsburg: Association for Computational Linguistics, 2000:69-75.
[34] Remko Scha. Taaltheorie en taaltechnologie: competence en performance [C]//R. de Kort and G.L.J. Leerdam (eds.): Computertoepassingen in de Neerlandistiek. Almere: LVVN, 1990:7-22.
[35] John Henderson, Eric Brill. Exploiting diversity in natural language processing: combining parsers[C]//Proceedings of EMNLP 1999: 187-194.
[36] Kenji Sagae, Alon Lavie. Parser combination by reparsing[C]//Proceedings of NAACL 2006. Stroudsburg: Association for Computational Linguistics, 2006:129-132.
[37] Hui Zhang, Min Zhang, Chew Lim Tan, et al. K-Best Combination of Syntactic Parsers[C]//Proceedings of EMNLP 2009. Stroudsburg: Association for Computational Linguistics, 2009:1552-1560.
[38] 林颖,史晓东,郭峰. 一种基于概率上下文无关文法的汉语句法分析[J].中文信息学报, 2006,20(2):1-7.
[39] Daniel M Bikel. On the parameter space of generative lexicalized statistical models [D]. Philadelphia: University of Pennsylvania, 2004.
[40] Deyi Xiong, Shuanglong Li, Qun Liu, et al.Parsing the Penn Chinese Treebank with semantic knowledge[C]//Proceedings of IJCNLP 2005: 70-81.
[41] 曹海龙. 基于词汇化统计模型的汉语句法分析研究[D].哈尔滨:哈尔滨工业大学, 2006.
[42] 张浩, 刘群, 白硕.结构上下文相关的概率句法分析[C]//第一届学生计算语言学研讨会.北京:北京大学,2002.
[43] Mengqiu Wang, Kenji Sagae, Teruko Mitamura. A fast, accurate deterministic parser for Chinese[C]//Proceedings of COLING/ACL. Stroudsburg: Association for Computational Linguistics, 2006:425-432.
[44] Li Junhui, Zhou Guodong, Ng Hwee Tou. Syntactic Parsing with Hierarchical Modeling[C]//Proceedings of AIRS 2008: 561-566.
[45] Li Junhui, Zhou Guodong, Ng Hwee Tou. Joint Syntatic and Semantic Parsing of Chinese[C]//Proceedings of ACL 2010. Stroudsburg: Association for Computational Linguistics, 2010:1108-1117.
[46] Zhiguo Wang, Chengqing Zong. Phrase Structure Parsing with Dependency Structure[C]//Proceedings of COLING 2010. Stroudsburg: Association for Computational Linguistics, 2010:1292-1300.
[47] Hal Daumé III, Langford J, Marcu D. Search-based structured prediction [J]. Machine Learning, 2009,75(3):297-325.
[48] Daniel M. Bikel. Two Statistical Parsing Models Applied to the Chinese Treebank[C]//Proceedings of the Second Chinese Language Processing Workshop. Stroudsburg: Association for Computational Linguistics, 2000:1-6.
[49] 陈小荷. 从自动句法分析角度看汉语词类问题[J]. 语言教学与研究,1999.
[50] 徐艳华. 现代汉语实词语法功能考察及词类体系重构[D].南京:南京师范大学,2006.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
中华胰腺病杂志(2019年4期)2019-08-29
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2016年2期)2016-02-27
中华胰腺病杂志(2012年3期)2012-11-07
