
基于词义类簇的文本聚类
2013-04-23 10:15唐国瑜夏云庆
中文信息学报 2013年3期
唐国瑜,夏云庆,张 民,郑 方
(1. 清华信息科学技术国家实验室技术创新和开发部语音和语言技术中心, 清华大学信息技术研究院语音和语言技术中心, 清华大学计算机科学与技术系,北京 100084;2. 资讯通信研究院,新加坡 138632)
1 引言
文档聚类是自然语言处理中的重要任务,而文档表示是文档聚类中的关键部分。现有的很多方法都是基于词袋(Bag of Word)的思想。向量空间模型(Vector Space Model, VSM)[1]是最常用的经典文档表示模型,它将词看作特征,将文档表示成词的向量。但是VSM忽略了两个重要的语言学现象: 同义词和多义词现象。
同义词现象指不同的词含有相同的或者相似度的词义。例如: “计算机”和“电脑”表达了相同的意思。
多义词现象则指一个词可以同时含有两个或者多个词义。例如“苹果”可以指一种水果,也可以指一个电脑公司。
为了同时解决这两个问题,以前的研究试图将文档表示在语义空间上[2-5]。 一些研究试图利用WordNet[2]或者维基百科[3]构造一个显式语义空间,然后采用简单的词义归纳技术区分词义。但是这些通用的语义资源通常欠缺完备性。另外一些研究如潜狄利克雷分布(Latent Dirichlet Allocation, LDA)[4]将文本表示在一个潜语义空间上。这类方法不需要外部资源,因此它能在一定程度上克服显式语义方法的不足。但是Lu et al.[6]的研究表明,潜语义表示模型在需要细粒度区分信息的文本挖掘任务上的性能并不突出。
本文提出了词义类簇模型(SCM),在词义类簇空间上表示文本。SCM首先构造词义类簇空间,然后在这个空间上表示文本。词义类簇空间的构造有两部分组成。首先利用LDA模型[7]从开发集中归纳词义;然后通过聚类方法合并相同或相似的词义生成词义类簇。这是由于词义归纳任务专注于词的消歧,忽略了词之间的关系。因此在本文中局部的词义需要结合成全局的词义类簇。词义类簇空间构造后,本文首先进行词义消歧,然后将文档表示在词义空间上。
本文提出的SCM模型旨在同时处理同义词和多义词现象。1) 词义聚类可以将相同或者相近的词义聚为一类。同义词或者近义词将被识别成相同的词义类簇,这样文档相似度将计算得更加准确。2) 文档中的每个词都根据它的上下文赋予一个特定的词义类簇,这样多义词会是被识别成不同的词义类簇,因此可以得到更加准确的文档相似度。
与之前提到的显式语义方法相比,本文的词义是由开发集归纳出来的,比较容易获得,还可以扩展到不同的语言中。与LDA相比,SCM利用LDA获得词义,可以获得较好的细粒度区分信息。
实验表明,SCM在标准测试集上的性能优于基线系统以及经典话题模型LDA。
本文组织如下: 第2节介绍了相关工作,第3节介绍了SCM模型,第4节介绍了相关实验,最后一节进行了总结。
2 相关工作
2.1 文档表示模型
传统的VSM模型中,词和词之间都是相互独立的,忽略了他们之间的语义关系。一些研究试图利用概念或者词类簇[8-9]作为特征,另外一些研究则利用词与词之间的相似度[10-11]。但是这些模型只解决了同义词现象,忽略了多义词现象。
为了同时解决这两个问题,一些文档表示模型采用了WordNet或者维基百科等语义资源,将文档表示在概念空间上[2,3,12]。但是这些语义资源很难构建并且缺乏完备性。
还有一些研究利用潜语义空间。潜语义分析(LSA)[5]以及潜狄利克雷分布(LDA)[4]是其中两个代表性的模型。LSA[5]试图利用奇异值分解压缩矩阵,它的特征是所有词的线性组合。LSA不能处理多义词现象。LDA[4]曾经成功地用于话题发现任务,但是Lu et al.[6]的研究表明,直接将LDA用于需要细粒度区分信息的文本挖掘任务(如文档聚类)中性能较差。
本文利用开发集归纳词义并且利用词义类簇表示文档,使SCM模型可以同时处理同义词现象和多义词现象。同时该模型可以很容易地拓展到其他语言和其他领域。
2.2 词义归纳和词义消歧
很多研究都致力于解决词义消歧任务[13]。自然语言处理任务(比如信息检索[14])使用词义来代替词可以带来性能的提高。但是这些研究需要人工编辑的语义资源,同时如何选取词义的粒度也是研究中的难题。
本文采用词义归纳(Word Sense Induction, WSI)算法从未标注文本中自动发现词义。词义归纳算法有很多[15]。Brody and Lapata[7]提出的贝叶斯模型利用拓展的LDA模型归纳词义。实验结果表明他们的模型要优于SemEval-2007评测[16]中最好的几个系统。词义归纳算法已经在信息检索任务中得到了应用[17-18]。但是以上的这些研究都只考虑了每个词的词义而忽略了词与词之间的关系。
本文采用贝叶斯模型[7]进行词义归纳,同时采用该模型进行词义消歧。
2.3 文档聚类
文档聚类的目的是按照相似程度将文档划分为不同的类簇。一般来说聚类算法可以分为基于区分和基于生成两种。前者试图利用相似度将数据划分为不同的类簇(比如k-Means和层次聚类方法)[19,20],后者则利用特征和数据的分布(如EM算法)[21]进行划分。
本文评测提出的模型是用于文本聚类任务的,同时聚类算法还用来构造词义类簇。
3 词义类簇模型
词义类簇模型主要是利用词义类簇表示文档。3.1节给出了词义以及词义类簇的定义。3.2节给出了文档在词义类簇空间上的表示,3.3节则给出了词义类簇的构造,最后3.4节总结了词义类簇模型的流程。
3.1 词义和词义类簇
定义1词义: 特定词w的词义sw可以统计地表示为一组上下文的词的概率分布。如式(1)所示。
其中ti表示上下文中的词,p(ti|sw)表示ti对于词义sw的概率,即给定词义sw, 词ti出现在上下文中的概率。
本文利用上下文中的词代替语义资源表示词义,这是由于语义资源通常构造困难且欠缺完备性,而上下文中词的分布可以通过WSI算法(见3.2节)从开发集中获得。
两个词义的例子如下:
例#1: 词“作业”的词义“作业#1”
作业: 0.159
功课: 0.069
学生: 0.019
例#2: 词“作业”的词义“作业#2”
作业: 0.116
工作: 0.039
车间: 0.026
从例子可以看出,词“作业”含有两个词义,每个词义都有不同的上下文词的概率。
一个词可以含有不同的词义,因此多义词可以很容易的用词义进行区分,但是由于词义是由WSI算法归纳出来的,而现有的WSI算法只关注于局部词义即同一个词的不同词义。因此本文引入词义类簇来获得不同词之间的相同词义。本文假设每个词义只能属于一个词义类簇。
定义2词义类簇: 词义类簇指一组由词义聚类算法得到的词义,它可以表示为式(2):

两个词义类簇的示例如下:
例#3: 词义类簇 c#1
{作业#1, 功课#1}
作业#1={作业: 0.159, 功课: 0.069, 学生: 0.019}
功课#1={功课: 0.179, 作业: 0.059, 学生: 0.029}
例#4: 词义类簇 c#2
{作业#2, 工作#1}
作业#2={作业: 0.116, 工作: 0.039, 车间: 0.026}
工作#1={工作: 0.12, 作业: 0.04, 车间: 0.016}
类簇c#1中,由于“作业#1”与“功课#1”的上下文概率分布比较相似,因此“作业#1”与“功课#1”被聚为一类。同理,“作业#2”和“工作#1”被聚为一类。从上面的两个类簇可以看出,类簇之间反映了词的多义性而类簇内部则反映了词的同义性。
3.2 词义类簇模型
为了在词义类簇空间上表示文档,我们需要获得每篇文档对于每个词义类簇的概率。而每篇文档的词义类簇的概率可以通过它含有的词获得。因此,词义类簇c出现在文档d中的概率如式(3)所示。
其中p(wk|d)表示文档的词概率,可以用nwk,d/Nd进行估算,其中nwk,d表示词频,Nd表示文档长度。p(c|w,d)表示文档d中的词w含有词义类簇c的概率。
这样,我们需要计算每篇文档中每个词的词义类簇概率,它是由词义类簇中的词义概率获得,可以通过式(4)计算。
对于文档中的词w,它的每个词义在文档中出现的概率可以通过式(5)计算。
其中a表示词w在文档d中的上下文。
最后p(sw|a)可以通过词义消歧获得。本文对文档中的每个词都采用贝叶斯模型进行词义消歧。贝叶斯模型[7]在本文中主要用于词义推导和词义消歧。
例如有两句话:
S1: 学生们的作业很多。
S2: 工人正在生产车间作业。
词义消歧后,S1中“作业#1”的概率为0.998 05,而S2中“作业#2”的概率为0.998 05,这样,多义词情况得到了处理。
这样,SCM模型可以用词义类簇代替词,将每篇文档表示在词义类簇空间上。SCM模型的一个实例如图1所示。图1 中,文档d1和d2分别含有四个词。首先,词“作业”和词“功课”属于同一个词义类簇,这意味着SCM可以处理同义词问题。其次,词“作业”在两篇文档中分别属于不同的类簇,这是由于它在两篇文档中具有不同的含义,因此SCM模型可以处理多义词问题。

图1 SCM模型的示例
3.3 词义类簇空间的构造
词义类簇的构造算法包含两步: 词义归纳和词义聚类。
由于贝叶斯模型在词义归纳算法的优越性[7],本文采用这个算法,详细过程请参见文献[7]。本文采用句子作为上下文,直接采用LDA模型进行词义归纳。
给定一个词w,由上文提到的贝叶斯模型可以获得它的词义sw的上下文分布概率即p(t|sw)。但是由于贝叶斯模型是针对特定词的,它只能识别出词的多义性忽略了同义词之间的关系。因此我们将上下文的词作为特征,p(t|sw)作为特征权重,利用聚类算法进行聚类,本文采用Bisecting K-Means[22]算法进行聚类。Bisecting K-Means 是K-Means的拓展方法,研究证明它的性能优于标准的K-Means算法和层次聚类算法[24]。它首先将样本看作是一个类簇,然后迭代找出最大的类簇进行划分。
3.4 词义类簇模型的流程
利用词义类簇模型进行文档表示的流程如图2所示。

图2 SCM模型的流程
利用SCM进行文档表示分为两个阶段: 第一阶段,首先利用开发集归纳出词义(见3.3及定义1),然后利用聚类算法构造词义类簇。第二阶段,首先对文档中的每个词进行词义消歧,然后利用公式(3)计算出文档中的类簇分布概率。
4 评测
我们利用文档聚类任务对SCM模型进行评测,将SCM模型与现有的文档表示模型进行对比。
4.1 实验设置
开发集: 我们从英文Gigaword语料库(LDC2009T13)中抽取了210万英文文档作为英文开发集, 从中文Gigaword语料库(LDC2009T27)中抽取了350万中文文档作为中文开发集。
测试集: 本文采用四个测试集.
1) TDT4 测试集: 我们采用TDT2002(TDT41)和TDT2003(TDT41)作为评测集[23]。
2) CLTC测试集: 我们从CLTC数据集抽取了两个评测集[24]。
四个评测集的信息如表1所示。
聚类方法:
为了评测SCM在文档聚类的性能,我们把文档类簇看做特征,采用TF-IDF公式计算每篇文档中特征的权重。然后采用相似度度量公式计算文档间的相似度。最后用聚类算法进行聚类。由于聚类算法不是文本的重点,我们使用经典的聚类算法: HAC(Hierarchical Agglomerative Clustering)算法[25]。HAC算法先将每个文档看成一个类簇,然后逐步将相似度最高的类簇合并为一个类簇。为了计算类簇之间的相似度,我们采用group-average link算法[25]。当类簇个数达到预定值后,则停止合并过程。

表1 测试集的话题和文档统计信息
评测指标
我们采用了文献[24] 提出的评测指标。首先计算每个类簇最大的F值。假设Ai代表系统生成的类簇ci的文档,Aj代表人工标注的类簇cj的文档。则F值计算如下:
其中pi, j,ri, j和fi, j分别代表准确率、召回率和F值。
参数设置
SCM要设置的参数包括LDA相关的参数(α,β 以及Gibbs sample的迭代次数),每个词的词义个数以及词义类簇的个数。对于LDA相关的参数,我们取α=0.02,β=0.1,迭代次数设置为2 000,因为这些参数在文献[7]的工作中被证明是最优的。由于对每个词选取最优的词义个数是非常繁琐的,我们对每个词都选用相同的词义个数。我们利用CLTC1的数据集作为调试集得出当词义个数设为4的时候性能最优,因此我们的实验都选用4作为词义个数。
实验方法:
本文评测了4个方法。
VSM: 一个采用VSM表示文档的基线系统。
LDA: 经典的话题模型[4],用文档的话题作为特征进行聚类。
SM(Sense Model): 基于词义的文档表示基线系统,即直接用本文的词义归纳算法归纳出的词义直接表示文档。它与SCM的区别是不包含词义聚类步骤。
SCM: 本文提出的词义类簇模型。
4.2 实验结果及讨论
本文分别比较了四个系统在英文和中文的四个测试集上的性能。结果如表2 和表3所示。其中对于SCM,我们在100到2 000的范围逐步增加词义类簇的个数,表2 和表3分别列出了各个测试集的最高的F值。SCM还列出了相关的词义类簇个数。
从表2和表3可以得出如下结论:
1) 在大多数情况下,SM的性能要高于VSM,这意味着在大多数情况下,使用词义表示文档是有效的。这是因为经过词义归纳和消歧后,每个文档中的词都被赋予一个特定的词义,使文档相似度的
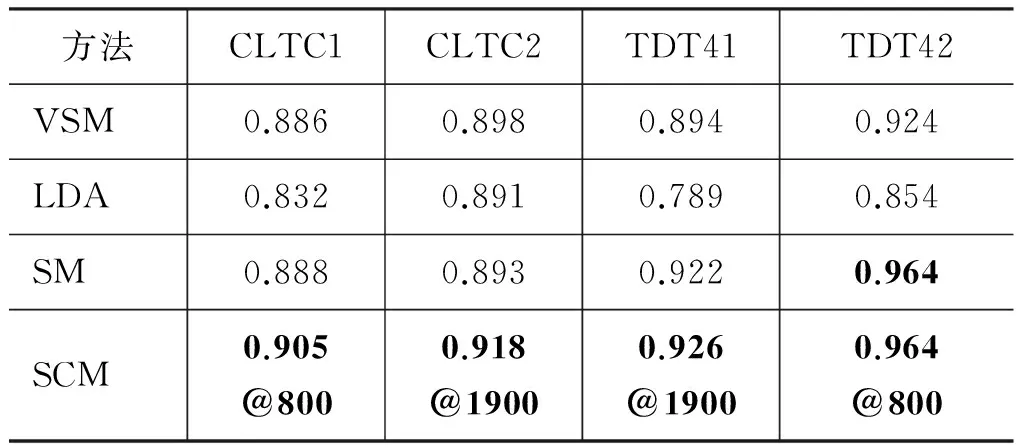
表2 系统在四个英文数据集上的最高F值

表3 系统在四个中文数据集上的最高F值
计算更准确。例如,两个文档分别含有3.3节提到的句子S1和S2。由于词“作业”在两篇文档中分别被识别为不同的词义,因此两篇文档的相似度为0,而在VSM中,由于含有相同的词“作业”,它们的相似度大于0,这意味着词义空间的相似度计算更准确。但是有些情况下,SM的性能要低于VSM,原因是我们对于每个词都是用了相同的词义个数,因此含有相同意义的词有可能被识别为不同的词义,这影响了系统的性能。
2) SCM的性能要高于SM。这是由于使用词义聚类方法将相似或相同的词义聚为一类。例如,{职工#0, 职工#2, 工人#2}是由SCM构造的词义类簇。即使不包含相同的词,含有“职工#0”的文档与含有“工人#2”的文档具有一定的相似度,这更符合实际情况。同时,词义聚类还能从一定程度上弥补每个词的词义都取相同个数的不良影响。比如说,“职工#0”和“职工#2”,一个词义被错误的分成两个,但是它们具有相似的上下文分布,因此可以在词义聚类阶段聚在一起。
3) SCM的性能要高于VSM,这意味由于SCM可以处理多义词和同义词现象,使用词义类簇比使用词更具有优越性。
4) 在大多数情况下,SCM性能优于LDA。LDA是一个经典的话题模型,它将文档表示在一个话题空间上,可以同时处理多义词现象和同义词现象。但是在本实验的大多数情况下,LDA的性能最低,这是由于文档聚类任务需要细粒度区分信息,而直接使用LDA不能很好提供这种信息。SCM利用LDA识别词义类簇,因此SCM不仅能够同时处理同义词和多义词现象,同时还能够提供特征空间的细粒度区分信息。
5) SCM在英文和中文两种语言上都能获得相似的改进。这意味着SCM的改进不仅仅限于一种语言,它可以被拓展到不同的语言。
5 总结和展望
本文在文档表示部分改进了文档聚类, 提出了一个新的文档表示模型SCM,采用词义类簇表示文档。在SCM中,首先利用词义归纳算法和词义聚类技术构造词义类簇,然后将文档表示在词义类簇空间上。本文提出的SCM旨在处理同义词和多义词现象。同义词可以被聚在相同的词义类簇中。同一个词的不同词义被识别为不同的词义类簇。因此文档相似度在SCM上计算的更准确。在两种语言的四个数据上的实验证明,SCM模型比基线系统和LDA的性能更优。
在接下来的工作中,我们将在大规模数据集上继续评测SCM。同时由于SCM将文档表示在词义类簇空间上,我们将考虑采用SCM在短文本聚类中处理稀疏性数据。另外我们可以进一步改进模型自动获取词义的个数进行词义归纳。
[1] G Salton, A Wong, C S Yang. A Vector Space Model for Automatic Indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.
[2] A Hotho, S Staab, G Stumme. WordNet improves text document clustering[C]//Proc.of SIGIR2003 semantic web workshop.ACM, New York, 2003: 541-544.
[3] P Cimiano, A Schultz, S Sizov, et al. Explicit vs. latent concept models for cross-language information retrieval[C]//Proc. of IJCAI’09.
[4] D M Blei, A Y Ng, M I Jordan. Latent dirichlet allocation[J]. J. Machine Learning Research,2003(3): 993-1022.
[5] T K Landauer, S T Domais. A Solution to Plato’s Problem: The Latent Semantic Analysis Theory of Acquisition, Induction and Representation of Knowledge[J]. Psychological Review,1997,104(2): 211-240.
[6] Yue Lu,Qiaozhu Mei,Chengxiang Zhai, Investigating task performance of probabilistic topic models: an empirical study of PLSA and LDA[J]. Information Retrieval, 2011,14(2), 178-203.
[7] S Brody, M Lapata. Bayesian word sense induction[C]//Proc. of EACL’2009: 103-111.
[8] J Pessiot, Y Kim, M Amini, et al. Improving document clustering in a learned concet space[J]. Information Processing and Management, 2010,46: 180-192.
[9] S Dhillon. Co-clustering documents and words using bipartite spectral graph partitioning[C]//Proc. SIGKDD’2001: 269-274.
[10] S K M Wong, W Ziarko, P C N Wong. Generalized vector model in information retrieval[C]//Proc. of the 8th ACM SIGIR,1985: 18-25.
[11] A K Farahat, M S Kamel. Statistical semantic for enhancing document clustering[J]. Knowledge and Information Systems,2010.
[12] H Huang, Y Kuo. Cross-Lingual Document Representation and Semantic Similarity Measure: A Fuzzy Set and Rough Set Based Approach. Fuzzy Systems[J]. IEEE Transactions,2010,18(6): 1098-1111.
[13] R Navigli. Word sense disambiguation: a survey[J]. ACM Comput. Surv. 2009,41(2), Article 10 (February 2009): 69.
[14] C Stokoe, M P Oakes, J Tait. Word sense disambiguation in information retrieval revisited[C]//Proceedings of SIGIR ’2003: 159-166.
[15] M Denkowski, A Survey of Techniques for Unsupervised Word Sense Induction[J]. Technical Report. Language Technologies Institute, Carnegie Mellon University.
[16] E Agirre, A Soroa. Semeval-2007 task02: evaluating word sense induction and discrimination systems[C]. SemEval 2007.
[17] H Schutze, J Pedersen. Information Retrieval based on word senses[C]//Proc. of SDAIR’95: 161-175.
[18] R Navigli, G Crisafulli. Inducing word senses to improve web search result clustering[C]//Proc. of EMNLP ’10: 116-126.
[19] S Dhillon, D S Modha. Concept decompositions for large sparse text data using clustering[J].Mach. Learn., 2001,42(1-2): 143-175.
[20] Y Zhao, G Karypis, U Fayyad. Hierarchical clustering algorithms for document datasets[J]. Data Mining and Knowledge Discovery, 2005,10(2): 141-168.
[21] C Ordonez, E Omiecinski. Frem: fast and robust em clustering for large data sets[C]//CIKM ’02, ACM Press. New York, NY, USA, 2002:590-599.
[22] M Steinbach, G Karypis, V Kumar. A comparison of document clustering techniques[C]//KDD Workshop on Text Mining,2000.
[23] Junbo Kong, David Graff. TDT4 multilingual broadcast news speech corpus[J].2005.
[24] G Tang, Y Xia, M Zhang, et al. 2011 CLGVSM: Adapting Generalized Vector Space Model to Cross-lingual Document Clustering[C]//Proc. of IJCNLP’2010: 580-588.
[25] E M Voorhees. Implementing agglomerative hierarchic clustering algorithms for use in document retrieval[J]. Information Processing and Management. v.22(6): 465-476. 1986.
猜你喜欢
客联(2022年3期)2022-05-31
校园英语·中旬(2022年3期)2022-04-23
汉字汉语研究(2021年3期)2021-11-24
作文大王·低年级(2021年9期)2021-09-10
中国新闻周刊(2021年26期)2021-07-27
西夏研究(2020年1期)2020-04-01
新世纪智能(英语备考)(2019年11期)2020-01-18
心理研究(2019年2期)2019-04-20
新高考(英语进阶)(2018年3期)2018-05-14
电脑爱好者(2017年7期)2017-05-06
