
FrameNet中有定的零形式识别
2013-04-23 10:10雷章章王智强
中文信息学报 2013年3期
雷章章, 王 宁, 李 茹 2, 王智强
(1. 山西大学 计算机与信息技术学院,山西 太原 030006; 2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
1 引言
在FrameNet语料库中,有些核心框架元素既不是谓词的依存成分,也不能通过槽填充得以发现,这种框架元素称为零形式框架元素(Null Instantiation,简记为NI),也称为零形式[1]。其中,有定的零形式框架元素(Definite Null Instantiation,简记为DNI)即有定的零形式在篇章理解中扮演着重要的角色,零形式识别的任务就是在框架语义角色标注的语料上识别出其中的DNI。
目前语义角色标注(Semantic Role Labeling,简记SRL)是浅层语义分析的一种重要实现方法,但是它只能为显现表达的语义论元分配角色,并且只是作为句子内部的任务而没有上升到篇章级,这使得SRL在许多与文本理解相关的自然语言处理问题(如信息抽取、文本摘要或自动问答等)的应用中受到了限制, 因而获取未显现表达的语义论元并将其与上下文语境中的共指项进行链接,对实现自然语言处理领域中的篇章理解及其应用具有十分重要的意义。
国际计算语言学会议ACL在2010年举行了关于“连接语篇中的事件及其参与者”的语义评测[2], 即SemEval-2010 Task 10,任务组给出了Full Task和NIs only(也称为NI Task)两种任务模式。Full Task包括SRL和NI Task两个部分,NI Task要求参与者在金标准语义角色标注的语料上识别出有定的零形式并在上下文中找到其先行语,本文专注于其中的DNI识别部分。评测任务分别提供了FrameNet和Probank两种标注语料,只有两支队伍提交了NI Task。 Desai Chen等[3]采用了扩展的SEMAFOR 1.0[4]框架语义分析器,该系统将零形式识别看作论元识别问题,采用线性对数模型,将系统之前用于论元识别任务中的特征集稍做改动作为新的特征集,该团队的零形式识别召回率和分类准确率分别为63.4%和54.7%。Sara Tonelli等[5]采用了一个曾用于RTE的语义评测系统VENSES++,将零形式检测任务按动词和名词两种不同的情况分别处理,在随后的零形式分类阶段以是否找到缺失论元的先行语作为分类的依据,若找到,则标记为DNI,否则就标记为INI,该团队零形式识别的召回率为8.0%,在此基础上分类的准确率为62.4%。
本文采用规则过滤与机器学习相结合的方法实现有定的零形式的识别任务,其中主要工作包括零形式检测规则的构建与基于最大熵分类器的零形式分类模型的实现。
2 相关概念介绍
2.1 FrameNet
FrameNet[6]是一个基于语料库的、以框架为基础的计算机词典编纂项目,该项目以框架语义学理论为基础,其分析单元不再是一个个的词而是框架。框架是信仰、实践、制度、想象等概念结构或概念模式的图解表征[7]。激起框架的词元称为目标词,在目标词激起一个框架的同时也激起了一个以框架名命名的场景,场景中的事件及参与者被称为框架元素,框架元素表示与特定的词相关的语义角色或者语义功能,这些词或者出现在特定的句子中或者出现在特定的一组句子中。框架元素又有核心与非核心之分,相比于非核心框架元素,核心框架元素与框架之间具有更为特定的语义联系。
2.2 零形式及其类型
零形式是由核心框架元素缺失引起的[8-9]。核心框架元素缺失的现象可分为两类情况,即允许缺失的语义实体类型和对所缺失论元的解释类型。前者是由特定的词项或句法结构缺失引起的零形式。如例句2.1中缺失的施事者是由被动结构引起的:
例2.1. No doubt, mistakes were made 0Protagonist.
这种缺失是结构的缺失,它适用于任何有着合适的能用于被动语态语义信息的谓词。例2.2展示了另外一种情况,这里的缺失是由特定词项造成的: 动词arrived允许它的Goal角色缺省,但是和它属于同一个Arriving框架下的动词词元reach却不允许。
例2.2. We arrived 0Goalat 8pm.
上面的两个例子也展示了第二类缺失情况下的差异。作为对比,例句2.1中犯错误的施事者“Protagonist”能够被理解,没有必要为之找回或者建立一个特定的篇章所指(INI的例子),而例句2.2中缺失的角色Goal是一个谈话人双方必须从语篇或者上下文中才可以理解的实体(DNI的例子)。
图1给出的是FrameNet中Arrest框架下的词元arrest.v的标注情况,各个框架元素用不同颜色区分,其中核心框架元素在Core Type中用Core标出。标注框架下的两条语句是FrameNet中由arrest.v激起的零形式句子标注实例,其中CNI是指结构的零形式。
3 基于规则的零形式检测
零形式是由核心框架元素缺失引起的,但是缺失的核心框架元素并不一定就是零形式,因为核心框架元素之间还具有三种关系,只有充分考虑了这些关系才能够判断缺失的这个核心框架元素是否为零形式。
3.1 核心框架元素间的关系
在FrameNet的框架中,核心框架元素之间可能会有着某种特定的关系,使得它们并不完全独立,这三种关系分别是:
• CoreSet: 这个关系表明,其中的核心框架元素可以一个或者多个需要显示表达。有这种关系的情况比较复杂,可能在某种情况下,其中的一个核心框架元素缺失时不认为是论元缺失从而不用标记为零形式,而对于另外一个则必须进行标记;也可能有的情况下进行标记,有时又不需要标记,这因框架不同而不相同。

图1 动词arrest.v在FrameNet中的标注
例如,在Arrest框架中:
Core: {Authorities, Charges, Offense, Suspect}
FE CoreSet: {Charges, Offense}
两个角色Charges和Offense具有CoreSet关系,在FrameNet给出的标注语料中,若二者中仅缺失Charges,需要标记为零形式;而若仅缺失的是Offense,则不必标记。
• Excludes: 这是个互斥的关系,拥有这种关系的两个核心框架元素不可以同时出现,这样当其中的一个出现的时候,与其互斥的论元没有出现时也不认为是论元缺失,从而不用标记为零形式。
• Requires;这是个有序的关系,若核心框架元素A和B具有这种关系,且A在前面,则要求A出现时B一定要出现否则即认为是论元缺失,但是B出现的时候不一定要求A也必须出现或被标记为NI。
例如,在Similarity框架中:
Core: { Differertiating_fact, Entity_1, Entity_2, Dimension};
Excludes: {
Requires: {
例3.1. [Entity_1The configuration of hard drives] is no differentTarget[Dimensioninthis respect].[Entity_2DNI]
例3.1中,由目标词different激起的Similarity框架中, Entity_1和Entity_2都与Entities互斥,这样在句中出现了 Entity_1时,就不会出现Entities,也不用将其标为NI;又由于Entity_1和Entity_2有Requires关系,在只出现了Entity_1的前提下,有必要将Entity_2标记为NI。从这个例子我们也可以看出,核心框架元素Differertiating_fact缺失,而且它也不在这三种关系中,却没有将其标记为NI,这种情况是很少见的。
3.2 零形式检测的规则构建
根据核心框架元素之间三种关系,即: CoreSet,Excludes和Requires,本文构造了三个零形式的检测规则:
规则1. 缺失的核心框架元素若与某个显示表达的核心框架元素有Excludes关系,则没有出现零形式,否则参考其他两个规则;
规则2. 缺失的核心框架元素若属于某个显示表达核心框架元素的Requires关系,则出现了零形式,并将该缺失的核心框架元素标记为零形式;
规则3. 缺失的核心框架元素与某些显示表达的核心框架元素在同一个CoreSet集合中,而没有其他两种关系,则根据该CoreSet中各角色的标注规律进行标注,在我们的实验处理中,如果有一个显现的表达了,就默认为其他的都不是零形式。
3.3 零形式检测的步骤
依照零形式框架元素的特点及上面的检测方法,设计检测步骤如下:
Step 1. 数据预处理: 第一,抽取FN中每个框架的核心框架元素及框架下的CoreSet、Excludes和Requires关系并记录到数据库中;第二,提取语料中所有句子的目标词、所属框架、框架核心元素标记等信息并记录到数据库中;
Step 2. 全部改为. 对于测试语料,根据上步中提取的信息对比以判断核心框架元素是否缺失,若没有,就不做标记,否则转向Step 3;
Step 3. 使用规则1判断缺失的框架元素是否在某个Excludes关系中,若是,不做标记,否则转向Step 4;
Step 4. 使用规则2判断缺失的框架元素是否在某个Requires关系中,若是,转向Step 6,否则转向Step 5;
Step 5. 使用规则3判断缺失的框架元素是否在某个CoreSet中,若有,转向Step 6;
Step 6. 将缺失的句子信息记录到文件中,以便后续试验的进行。
4 基于最大熵的零形式分类
找到有定的零形式在上下文中的共指项有助于篇章理解的提高,因而对于检测出来的零形式,我们还想进一步知道其解释类型。参与评测的两支团队都是将零形式的分类和消解捆绑在一起进行的,即能够消解的被认为是有定的零形式,否则被判为无定的零形式。本文尝试选用最大熵分类器,通过训练语料的训练,直接用来对测试语料中的零形式解释类型进行分类预测。我们的做法是基于零形式的这样一个规律: 框架不同,目标词不同,缺失的核心框架元素不同都可能导致对零形式的解释类型不同[10]。
最大熵模型在自然语言处理中获得了广泛的应用,它是由最大熵原理推导而来,最大熵原理认为在学习概率模型时,在所有可能的模型中,熵最大的模型是最好的。最大熵模型的学习过程就是求解最大熵模型的过程。最大熵模型的一般表示见式(1)。
其中
这里,Rn为n维欧式空间,x∈Rn为输入,y∈{1, 2…,K}为输出(K个类别),w∈Rn为权值向量,fi(x,y),i=1, 2…,n为任意实值特征函数。
本文采用最大熵模型实现零形式分类问题,将有零形式的出现的框架作为输入样本x,把两种零形式类型DNI和INI作为分类输出,即y∈{DNI, INI},选择的特征集列表如表1所示。

表1 特征选取
5 实验及结果分析
5.1 实验语料
实验语料来源于SemEval-2010 Task10,其中训练语料是在SemEval-2007 Task 19的基础上加入了Arthur Conan Doyle的小说《名侦探福尔摩斯》中的部分节选语料的全文标注,测试语料是该小说中故事《巴克斯维尔的猎犬》的第13章(Chapter 13)和第14章(Chapter 14)节选部分的全文标注,详情参看表2,其中frame inst.是标注的框架实例数(annotated frame instances)。
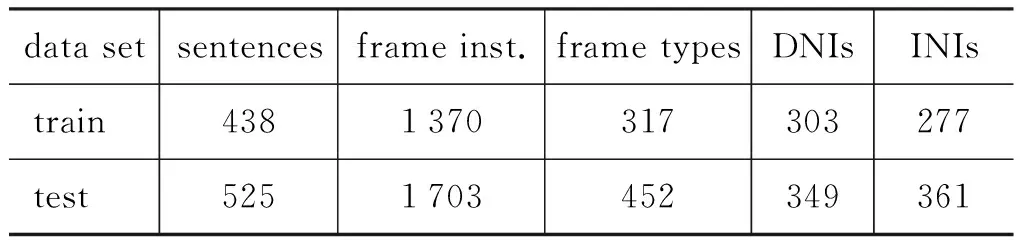
表2 评测语料的数据详情
5.2 零形式检测的实验结果及分析
按照基于规则方法,在测试语料上完成的零形式检测的结果如表3所示,括号中的数据为实验正确检测出来的数据。
根据表3的实验结果,我们给出了零形式检测实验相应的准确率、召回率和F值作为评定,如表4所示。

表3 零形式检测的实验数据统计

表4 零形式检测的实验结果评定
作为对比,我们给出了参与评测的两支队伍相应的零形式检测数据,如表5所示,其中710是金标准标注的零形式数目(NIs)。

表5 参与评测的系统零形式检测结果
由上述几个表的数据对比,我们认为使用规则的方法识别零形式是可行的,SEMAFOR系统的本身的召回率是不高的,这个数据是由评测系统给出的,具体在5.3节中详述。对实验结果分析中,我们发现识别错误主要由以下三种情况造成: (1)选用的FrameNet版本不同,在评测任务中,标注语料的框架库来自于FrameNet1.4,而本实验所采用的版本是FrameNet1.5,两个版本中某些框架名和框架元素标名不同造成了部分的识别错误;比如在FrameNet1.4中的“observable_bodyparts”,在FrameNet1.5中改为“observable_body_parts”这使得我们在按照规则发现零形式的时候丢失了该框架的信息,而这个框架在Chapter 13中出现了28次,其中核心框架元素“Possessor”缺失引起了零形式共有5次(3次DNI,2次INI)。例5.1给出的就是Chapter 13中S72里面的一个由“Possessor”缺失引起的DNI实例,它没有被我们的实验检测出来。
例5.1
(2)未登录框架名造成一些零形式未被发现。在测试语料中存在一些框架是参与评测时FrameNet框架库中还没有的,和第一个原因相同,对这部分框架中的零形式我们也没有能够检测出来,而SEMAFOR系统在框架识别阶段充分考虑了这个因素。(3)本文认为影响实验结果的最重要的因素是核心框架元素之间存在的CoreSet关系,这里以例5.2来说明。
例5.2
在“Hospitality”框架中:
Core: { Behavior, Expressor, Guest, Host, Topic, Judge }
FE Core set(s): {Behavior, Expressor, Host}、{Guest, Topic }
例5.2列举的是Chapter 13中S112里面框架“Hospitality”的金标准语料标注情况,其中只有一个核心框架元素“Host”是显现表达的,按照我们前面的检测规则,由于“Behavior”、“Expressor”和“Host”属于同一个CoreSet,这里即使前面两个缺失了也不标记为NI;在另外一个CoreSet中“Guest”和“Topic”都缺失了,我们只将第一个缺失的核心框架元素即“Guest”标记为NI而不再关注“Topic”,而实际的金标准语料将所有缺失的核心框架元素(一共5个)都标记为NI,这也影响了本文后续实验中对NI的分类。为了了解这个现象对零形式检测及分类结果的影响,我们对两篇测试语料中包含的CoreSet关系进行了统计。
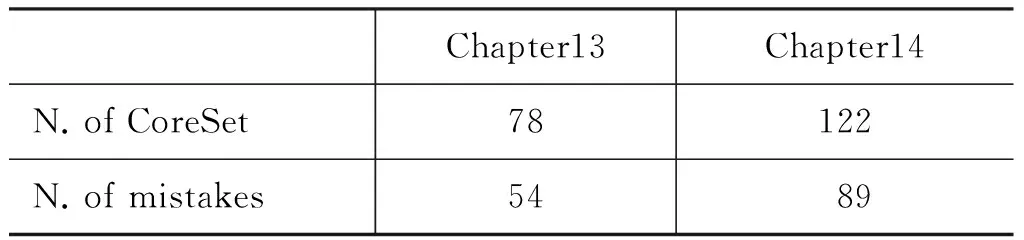
表6 测试语料中CoreSet关系统计
如表6所示,其中N.of mistakes 是由于CoreSet造成的零形式发现错误个数,这也解释了表3中Chapter 14的实验结果不如Chapter 13得到的结果,且其召回率要远低于准确率的原因。
5.3 零形式分类的实验结果及分析
在零形式发现的基础上,使用最大熵分类器对零形式分类做出了预测,实验使用的是张乐博士的最大熵工具包[10],表7给出的实验结果(Predicted),括号中的数据是预测正确的数目,同时也给出了VENSES++系统的预测结果,表8进一步给出了预测结果相应的准确率、召回率和F值。

表7 零形式分类的实验数据
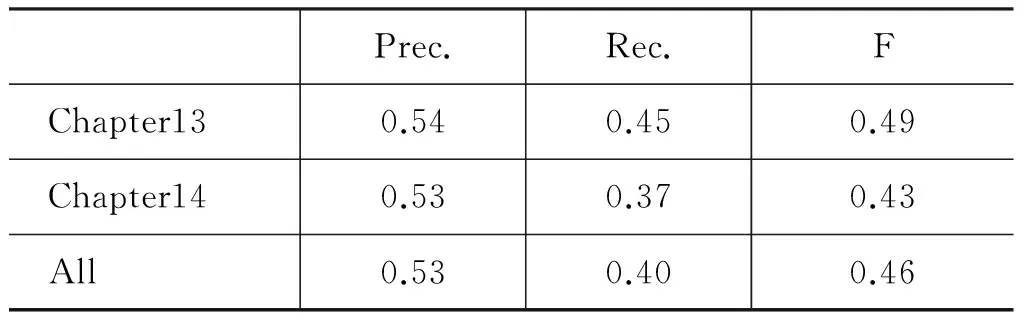
表8 本文零形式分类的结果评定
SEMAFOR系统在检测到的450个零形式中[2],有246个得到了正确的分类(DNI/INI),准确率为54.7%(246/450),在该团队评测任务提交的论文[3]给出的分类结果中,识别出来的DNI只有21个,这与评测系统对他们结果的评分策略有关;而VENSES++系统的分类准确率高达64.2%(35/57),不过该系统之前发现的零形式数目很少。本文
识别正确的有定的零形式数目(284)较两支参与评测的队伍都要多,这说明我们提出的零形式分类方法是可行的。
对零形式分类的评定的指标(准确率、召回率和F值)都不是很高,主要有两个原因: (1)受限于之前零形式检测的结果;(2)零形式分布的多样性,框架、词元或缺失的核心框架元素不同,对零形式的解释类型都可能不同,很难构建一个合适的统一分类模型。
6 总结
在FrameNet中,有定的零形式是包含了缺位填充的核心依存图的重要组成部分,在篇章理解中扮演着重要角色。本文采用规则过滤与机器学习相结合的方法分两步实现了有定的零形式的识别,在测试语料上取得了不错的结果,说明了本文的方法是可行的。
零形式存在的多样性给有定的零形式的识别带了很大的困难。在核心框架元素之间的三种关系中,由于CoreSet关系表现的零形式情况非常复杂,使得与之相关的零形式很难用本文的规则发现,这也影响了后续的分类效果,零形式的多样性同样也给零形式分类建模带来了挑战,这些都是本文以后工作的重点。
[1] 俞士汶,黄居仁. 计算语言学前瞻[M]. 北京: 商务印书馆, 2005: 21-74.
[2] J Ruppenhofer, C Sporleder, R Morante, et al. SemEval-2010 Task 10: Linking Events and Their Participants in Discourse[C]//Proceedings of the 5th International Workshop on Semantic Evaluation.ACL 2010. Uppsala, Sweden: 15-16 July 2010: 45-50.
[3] D Chen, N Schneider, D Das, et al. SEMATOR: Frame Argument Resolution with Log-Linear Models[C]//Proceedings of the 5th International Workshop on Semantic Evaluation.ACL 2010. Uppsala, Sweden: 15-16 July 2010: 264-267.
[4] D Das, N Schneider, D Chen, et al. Probabilistic frame-semantic parsing[C]//Proceedings of the NAACL-HLT. ACL 2010. Los Angeles, California: June 2010: 948-956.
[5] S Tonelli, R Delmonte. VENSES++: Adapting a deep semantic processing system to the identification of null instantiations[C]//Proceedings of the 5th International Workshop on Semantic Evaluation.ACL 2010. Uppsala, Sweden: 15-16 July 2010: 296-299.
[6] J Fillmore, C R Johnson, M R L Petruck. Background to FrameNet[J]. International Journal of Lexi-cography, 2003, 16(3): 235.
[7] J Fillmore, Charles. Linguistics in the Morning Calm[M]. Seoul, Korea: Hanshin Publishing Company, 1982: 111-137.
[8] J Fillmore. Pragmatically controlled zero anaphora[C]//Proceedings of the 12th Annual Meeting of the Berkeley Linguistics Society. Berkeley, CA. 1986: 95-107.
[9] J Ruppenhofer. Regularities in null instantiation.2005.
[10] Zhang Le.Maximum entropy modeling toolkit for python and C++:[OL]http://homepages.inf.ed. ac.uk/s0450736/ maxent toolkit.html.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
通信技术(2021年12期)2022-01-25
小资CHIC!ELEGANCE(2022年1期)2022-01-11
开放教育研究(2020年2期)2020-03-31
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
燕山大学学报(2015年4期)2015-12-25
现代企业(2015年2期)2015-02-28
