
基于短语串实例的汉藏辅助翻译
2013-04-23 10:10刘汇丹张立强
中文信息学报 2013年3期
熊 维,吴 健,刘汇丹,张立强
(1. 中国科学院 软件研究所,北京 100190; 2. 中国科学院大学,北京 100049)
1 引言
藏语作为藏文化的最主要和最基本的载体,它在广大的藏区发挥着无可估量的作用[1]。藏语是藏族地区主要的交流语言,汉藏翻译在藏族地区信息传播中起着重要作用。据统计,西藏目前有100多个藏语文翻译单位,近1 000人专门从事各类翻译和藏文工作,每年汉藏翻译工作量约5 000多万汉字[2]。面对如此巨大的翻译需求,传统的纯人工的翻译方式无法满足汉藏翻译的需要。因此,需要借鉴一些成熟的机器翻译技术,加快汉藏翻译的研究,提高汉藏翻译人员的工作效率。
由于藏语自身的原因以及研究投入的不够,国内针对汉藏机器翻译的研究进展相对缓慢。藏语的基础资源库以及相应信息处理工具相对匮乏。在此,本文提出一种基于短语串实例的汉藏辅助翻译方法,主要利用现有的词语对齐技术,充分地挖掘汉藏平行语料中任意长度的翻译实例串,进而为辅助翻译人员提供最优的候选译文。
本文接下来将从以下几个方面进行介绍,第2节主要对机器翻译研究背景和现状进行介绍。第3节对汉藏辅助翻译系统框架进行介绍。第4节主要介绍汉藏平行语料的整理和预处理等相关技术。第5节主要介绍汉藏辅助翻译系统中的句子级别的相似度计算和实例匹配以及短语串级别的实例匹配和译文组合方法。第6节提出辅助翻译实验的评价策略,以及翻译实验结果和分析。文章最后将对本文的相关工作进行总结。
2 研究现状
机器翻译的研究主要包括: 基于规则的翻译、基于实例的翻译和基于统计的机器翻译等。目前研究热点主要集中在基于统计的机器翻译方法上。基于统计的方法通常需要构建较大的平行语料库,如汉英机器翻译实验通常有几十万到百万级的平行语料。而少数民族语言资源相对匮乏,主要的研究还是基于规则的方法上[3-6],基于统计语料库的方法[7-10]还处于研究的初级阶段。
2.1 辅助翻译发展现状
目前,针对少数民族语言机器翻译的研究还主要集中在基于规则的方法上,如侯宏旭等[11]提出了一种基于规则的汉蒙机器翻译方法,即对获取的翻译实例句子,利用翻译规则进行后续译文处理。姜柄圭等[12]提出了一种基于汉语语块抽取的机器翻译方法,即利用翻译规则模版进行辅助翻译。
基于规则的翻译方法通常需要维护一个较大的翻译规则库。构建大规模的语言规则库需要大量的人工资源和语言知识,这个对于汉藏辅助翻译项目的工作量太大。基于句子实例的翻译方法则不需要较多的人工操作和语言知识,优点在于能够利用不断增加的翻译句子实例。但是如果不能在实例库中找到相似度较高的翻译实例,翻译的效果就会变得很差,句子实例利用率较低。基于统计机器翻译方法依赖于大规模的平行语料,短语翻译对有长度限制,如Moses[13]默认设置为7。随着短语长度的增大,需要更多的空间来存储这些翻译对,数据稀疏问题也随之凸现。
国际上比较有影响的辅助翻译系统有Trados*Trades http://www.trados.com/en/、DéjVu X*Déj Vu X http://www.atril.com/等。辅助翻译开源的软件有OmegaT*OmegaT http://www.omegat.org。我国的目前影响较大的辅助翻译产品包括雅信CAT系统*雅信CAT http://www.yxcat.com/Html/index.asp,华建集团的智能辅助翻译系统IAT*华健IAT http://www.hjtek.com/Products/等。上述辅助翻译产品以及开源软件采用的技术主要包括翻译记忆、术语管理、人机交互等,翻译方法主要采用的是基于句子实例的翻译,它并不能很好解决汉藏语料资源相对匮乏条件下的辅助翻译。
2.2 汉藏辅助翻译研究现状
国内针对汉藏翻译的研究主要集中在基于规则方法上。如才藏太等[4]构建的班智达汉藏公文规则翻译系统,提出了一种词条和语法规则模版相结合的方法。德盖才郎等[3]构建了一种基于规则知识库的汉藏机器翻译系统。扎洛等[5]提出的汉藏翻译中复句的翻译规则,是从汉藏句子特点出发研究翻译规则的。看卓才旦等[6]提出的汉藏翻译中动词处理的方法,是从藏语特性出发研究汉藏句子中动词的翻译规则。
汉藏机器翻译在基于统计语料库方向的研究如才让加[7]提出的藏语语料库加工方案。赵维纳等[8]提出的藏文句子边界识别方法。Yu Xin等[14]提出的基于词典的汉藏句子对齐的方法。诺明花等[9-10]提出的基于序列相交的汉藏短语抽取方法。这些语料库的建设、句子边界识别、句子对齐、短语抽取等技术的研究都是汉藏机器翻译在基于统计语料库的方法上的基础性研究。
汉藏机器翻译在语言层面上主要存在以下问题: 一是语序上的不同。汉语的主语(Subject)、谓语(Verb)、宾语(Object)三者之间的语序都是SVO形式的。但是藏语不同,藏语的谓语部分通常位于句子的末尾,它的语序是SOV形式的。与汉英翻译不同,汉藏翻译中存在动词的长距离调序问题。二是词语形态上的区别。汉语是没有形态变化的,而藏语有丰富的形态变化。在统计机器翻译中存在翻译词形错误的问题。
本文研究的主要工作在于将基于统计的机器翻译技术应用到汉藏辅助翻译系统中。在汉藏平行语料资源相对较少的情况下,利用现有的词语对齐技术充分地挖掘汉藏平行语料信息,检索出平行语料中任意长度的短语串翻译实例,从而提高汉藏辅助翻译系统在短语串级别的召回率,改善汉藏辅助翻译质量。
3 汉藏辅助翻译系统框架
汉藏辅助翻译系统主要提供三个层面的机器翻
译结果: 句子级别的匹配翻译、短语串级别的匹配翻译和词语级别的翻译。首先对于一个待翻译句子,先在翻译实例库中利用编辑距离的方法查找最相似的翻译实例。如没有,则进行基于短语串的匹配翻译,并对各个短语串的译文进行组合提供最终翻译。最后对于那些未翻译出来的词语利用词典提供候选藏文翻译。
汉藏辅助翻译系统的翻译流程图如图1所示。
其中,翻译记忆库(TMX格式),主要是为了整个翻译记忆库的可扩展性。汉藏翻译对齐平行语料库,主要用于基于短语串的匹配翻译。

图1 汉藏辅助翻译系统框架图
4 汉藏平行语料的整理和预处理
汉藏辅助翻译实验中共收集到613篇句子对齐文档,主要分为三类: 法律法规54篇、工作报告253篇、领导人文选306篇。最终整理收集到约7万条平行句对。整个语料预处理部分主要包括两个部分: 分词处理、词语对齐等。
4.1 分词处理
在汉藏辅助翻译实验中,汉语分词采用Stanford开发的Chinese-Segmenter分词系统[15],该中文分词系统采用的是基于条件随机场的方法。藏语分词采用了藏文分系统SegTibetan[16]。该系统采用格助词分块并识别临界词,然后采用最大匹配方法分词,并进行紧缩词识别。
4.2 汉藏词语对齐
词语对齐,采用的是开源的词语对齐工具GIZA++[17]。利用Moses自带的训练脚本,只做Moses基于短语训练的前三个步骤,其中所有的参数采用Moses训练时的默认参数设置。最后,提取出GIZA++训练出来的词语对齐文件。
4.3 倒排索引
为了方便对待翻译句子进行实例检索和匹配,需要对已经获取的翻译记忆库和词语对齐的汉藏平行语料库进行倒排索引。倒排索引具体结构如图2所示。

图2 倒排索引结构图
在此,将上面获取的词语对齐的汉藏平行语料进行了三维的倒排索引,包括词语序列、出现该词语句子序号序列、该词语在句子中的位置序列。
三维的倒排索引主要是为了实现短语串级别的实例检索和匹配。利用它和词语对齐信息能抽取实例库中任意长度的短语串实例对应的译文翻译。
4.4 汉藏对照词典
实验中使用的双语对照词典主要包括《藏汉大辞典》[18]、《汉藏对照词典》[19]等。双语对照词典主要是为基于句子的实例匹配和基于短语串的实例匹配中未能成功翻译的词语提供候选藏文翻译的。
5 实例匹配与译文生成
实例匹配主要包括句子级别的实例匹配和短语串级别的实例匹配。
5.1 句子级别的实例匹配
句子级别的实例匹配中相似度计算主要采用编辑距离的方法。考虑到实际效率的要求,首先将待翻译句子进行停用词过滤,然后利用词语的倒排索引进行预处理,得到那些包含待翻译句子中词语的实例句子集合,计算这些实例句子与待翻译句子的编辑距离的公式如式(1)。

(1)
其中Dis见下面式(2)。
根据上述编辑距离的公式,定义如下的句子相似度计算公式(3):
如果上述句子实例匹配句子相似度大于阈值,则返回该实例翻译。否则进行下面的基于短语串级别的实例匹配。
5.2 短语串级别的实例匹配和译文生成
在传统的基于短语的统计机器翻译实验中,抽取的短语翻译对通常有一定的长度限制。基于短语串实例方法的优势在于短语串的长度是不受限的,不需要为由短语串长度带来的存储与计算问题耗费资源。只需要存储汉藏平行语料中的词语对齐信息。
基于短语串的实例匹配与译文生成包括两个关键步骤: 一、查找待翻译句子的所有子串并依据词语对齐信息获取所有子串对应的藏文翻译。二、寻找一条最优翻译路径,并将这条翻译路径上的所有子串对应的藏文翻译组合成译文。
(1) 子串候选译文的查找
这里的待翻译句子的子串是指经过分词处理后的待翻译句子,中文分词器采用前文所述的Stanford开发的Chinese-Segmenter分词系统。子串的最小单位即为分词后的单个词语。
待翻译句子的子串译文查找算法如图3。
Input: 待翻译汉语句子的子串fifi+1…fj
1. 利用上文所述的倒排索引,查找子串中的每一个词语,获取包含子串fifi+1…fj所有词语的的句子集合VS1{S1、S2、…Sn};
2. 如果句子集合VS1不为空,则转3,否则转6;
3. 对于集合VS1{S1、S2、…Sn}中的每一个句子Si,判断词语fi、fi+1、…、fj是否在句子Si中连续。如果连续则保留该句子,将该句子加入句子集合VS2,同时将词语fi、fi+1、…、fj是在句子Si中的对应的位置信息保存;
4. 如果集合VS2不为空,则转5,否则转6;
5. 对于集合VS2{S1、S2、…Sm}中的每一个句子Si,依据词语fi、fi+1、…、fj是在句子Si中的位置信息和预处理中的词语对齐信息,抽取出该子串对应的所有可能的藏文翻译。依据投票原则*这里的投票原则分为两种情况,1. 相同的藏文翻译次数超过一定阈值; 2. 藏文长度大于汉语子串长度。确定该子串对应的藏文翻译,并return;
6. 将汉语句子子串对应的藏文翻译置空,并return;
Output: 汉语句子子串对应的藏文翻译emem+1…en
图3 子串译文查找算法
子串的枚举主要采用从左至右,从短到长的方式。对于给定待翻译句子S:f1f2f3…fn(其中fi表示句子S中的第i个词语)。子串的查找顺序如下:f1、f1f2、f1f2f3、…、f1f2f3…fn、f2、f2f3、f2f3…fn、… 、fn。这样查找主要是为了减少查找的次数,例如,如果对于子串fifi+1…fj在实例库中没有查找到与之相匹配的实例句子,那么以子串fifi+1…fj为前缀的其他子串也就没有必要继续查找了,可以直接跳跃到查找子串fi+1开始后续查找。
经过上述对待翻译句子的所有子串的翻译的查找,可以获得如下一个待翻译的候选项如图4。

图4 子串翻译候选项以及译文
(2) 查找最优翻译路径并进行译文组合
在第一步获取的翻译选项表后,如何查找一条最优的从头到尾的翻译路径。在此我们共提出并实验三种解决方法。分别是正向最大子串匹配的翻译方法、反向最大子串匹配的翻译方法以及路径概率最大的翻译方法。
以图4的待翻译句子为例,对于每个子串都只提供了一个候选翻译选项,即概率最大的翻译候选项。正向最大子串匹配的翻译方法的翻译路径为{(加强 民族 地区)(的 干部 队伍 建设 )(。)}。反向最大子串匹配的翻译方法的翻译路径为{(加强)(民族 地区 的) (干部 队伍 建设 。)}。以上这两种翻译翻译路径的选择主要基于最长子串来考虑的,这样就可以充分地利用语料库中的与待翻译句子具有最大相同子串的翻译实例。
同时,也进行了基于路径概率最大的翻译方法的实验。这个方法不同于基于短语的统计机器翻译在获取了所有候选翻译表后进行的基于堆栈的柱搜索方法,传统的基于短语的方法翻译路径的代价包括语言模型、翻译模型、调序模型等因素。在此,我们只考虑了语言模型、翻译模型两个因素。
对于汉语子串对应的候选译文的评分主要采用以下五个特征:
• 语言模型概率pLM(ei|e1…ei-1)
• 长度惩罚
对于一个待翻译句子f,找到一个目标语言的翻译句子e,使得该句子p(e|f)的概率最大,在此我们使用如下的对数线性模型公式(4)。

(4)
其中λφ、λLM参数采用默认值1。以图4为例,系统依照基于路径概率最大方法获得的翻译路径为{(加强) (民族 地区 的)(干部 队伍 建设 )(。)}。
6 翻译实验、评价策略和实验结果分析
翻译实验使用Moses基于短语的翻译作为对比系统,总共5个实验系统,分别是基于正向最大匹配的翻译系统、基于反向最大匹配的翻译系统、基于路径概率最大的翻译系统、基于句子实例的翻译系统和Moses基于短语的翻译系统。
汉藏辅助翻译实验中,共搜集整理69 756句对的汉藏平行语料库,对于汉语句子相同的已做删除处理。数据分布如表1。
随机从各个不同领域的文档中按比例共抽取429句对用作测试语料,测试语料只有一个翻译候选译文,余下67 327句对用作训练语料。其中测试语料汉语部分共8 547个词汇,平均约20词语/句子。评测工具使用的NIST评测脚本mteval-v11b.pl 评测实验结果如表2。

表1 数据分布表

表2 各系统评测得分以及总耗时
实验中,同时也统计了测试集中所有能在实例库中查找到的短语串实例的个数占测试集中所有短语串的个数的比率。具体数据表如图5~6。
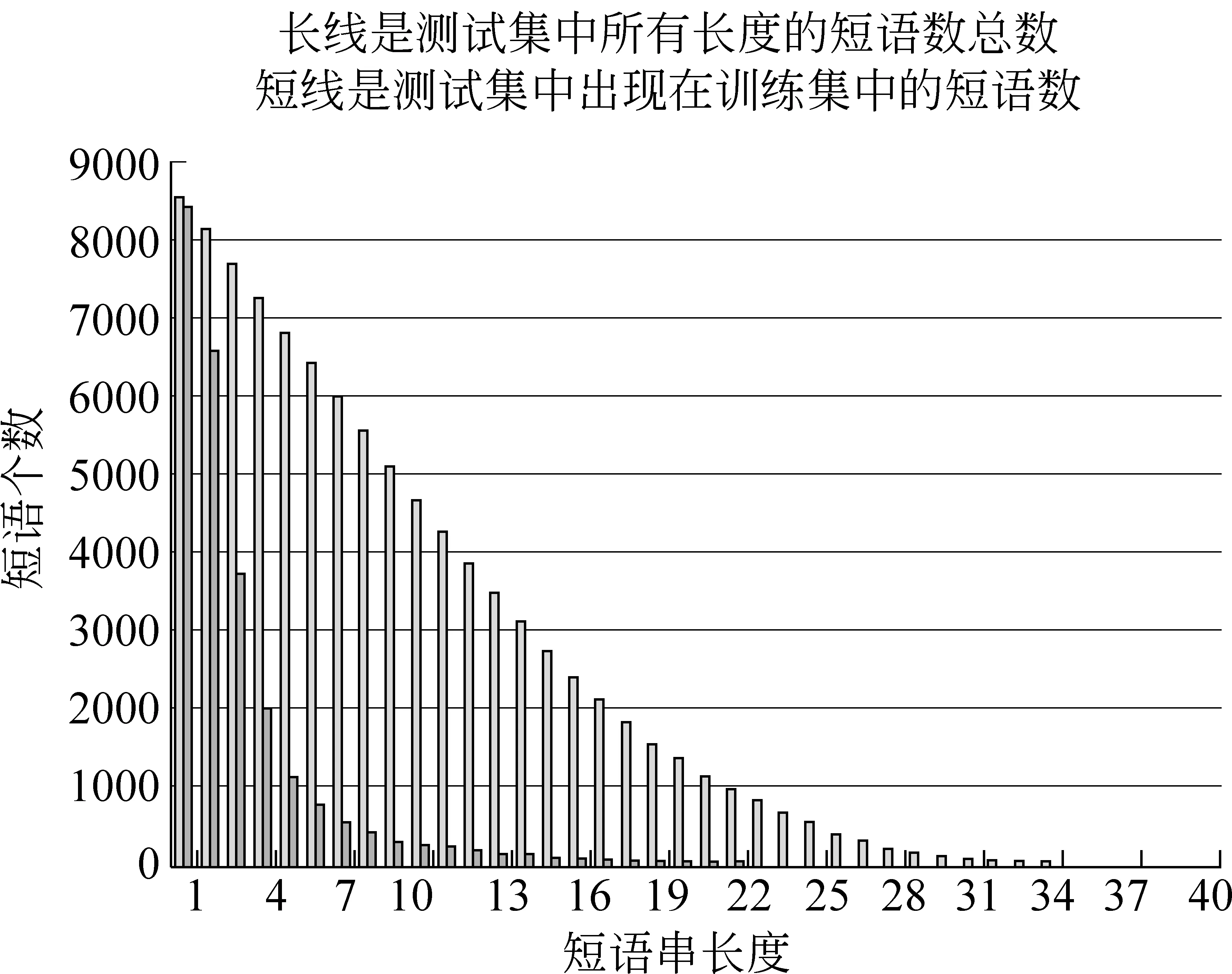
图5 测试短语串分布图
测试语料中所有的短语串共98 706个。其中能在训练语料中查找到的短语实例共25 512个,抽取出长度大于7的短语翻译实例共2 258个,这个较Moses基于短语的方法在短语翻译实例的召回率上提高了约9.71%。
图6中的长度为N的短语实例个数是指测试集中长度为N的短语串出现在训练集中的个数。整个测试集中,找到最长的翻译实例串长度为33个词语。

图6 测试集实例串比率
基于正向和反向的最大子串匹配的方法是纯粹的基于短语串实例的翻译,两者的翻译效果大致相同,主要原因在于两者采用了相同的基于实例串的翻译,只是翻译路径选择顺序略有不同。而基于路径概率最大的方法则采用了简单的翻译模型在翻译效果上比前面两种方法有一定的提高,这个主要原因在于翻译路径的选择存在差异,基于路径概率最大的方法在选择短语实例串时,通常会选择出现频度较大的实例串,比如名词短语串等。这个比单纯的正向最大匹配和反向最大匹配方法的效果要好,本次测试集中BULE值提高了0.02。
以上三个方法相对于基于句子实例的方法都有极大的提高。基于句子实例的翻译方法,第一,测试语料在训练语料库中没有相同的实例。第二,考虑到翻译效率,基于实例的方法只是寻找与待翻译句子相近的汉语句子并返回相近句子对应的译文,并没有做局部调整如近义词替换等。可以看出,在语料库规模较小的情况下,单纯的基于句子实例的方法并不能获得较好的效果,在本次试验中效果BULE值都没有达到0.1,这个结果相对基于统计的机器翻译来说效果很差。
本文提出的基于短语串实例的方法与开源系统Moses基于短语的翻译还有一定差距,在本测试集中BULE值比Moses低0.06。翻译效果基本达到了Moses基于短语翻译方法的80%左右,这个主要原因在于,上述实验的三种翻译方法,前两个只是基于短语串实例的翻译,并没有涉及到翻译模型、语言模型。而基于路径概率最大的方法也只是依照候选译文的概率寻找一条最优的翻译路径,无调序模型(可以看到例子中的动词“加强”对应的翻译只是直译出来,并没有调到藏语句子的末尾)。翻译速度上单句的平均翻译时间约0.175s,这个翻译速度基本达到辅助翻译实时性的要求。
总的来说,在语料规模较小的情况下,基于句子实例的翻译并不能为辅助翻译人员提供较好的译文选择,而基于短语串实例的翻译能够充分的挖掘现有的平行语料资源,可以将任意长度的汉藏翻译实例串和候选译文提供给辅助翻译人员。
7 结束语
本文主要提出了一种简单的基于短语串实例的汉藏辅助翻译方案,翻译效果与传统的基于句子实例的方法相比有极大的提高。在平行语料资源较少的情况下,基于短语串实例的机器翻译方法能利用词语对齐方法充分挖掘现有平行语料资源,能够检索出任意长度的短语串翻译实例,提高了汉藏辅助翻译系统在短语级别的召回率,为辅助翻译人员提供训练语料库中任意长度的翻译实例串。改善了汉藏辅助翻译系统的译文质量。下一步,我们将在基于短语串实例的翻译方法上,对短语调序做进一步的研究。
致谢
本文中使用的语料由益西桑布老师校对,特此感谢。
[1] 陈玉忠,俞士汶.藏文信息处理技术的研究现状与展望[J].中国藏学,2003,(4):97-107.
[2] 罗爱军,格朗,伍金加参等.西藏汉藏翻译队伍状况调查与分析[J].西藏科技,2010,(5):21-23.
[3] 德盖才郎,李延福,项青朝加,等.实用化汉藏机器翻译系统的设计与实现[C]//863计划智能计算机主题学术会议论文集.2001:405-411.
[4] 才藏太,华关加.班智达汉藏公文翻译系统中基于二分法的句法分析方法研究[J].中文信息学报,2005,19(6):7-12.
[5] 扎洛,索南仁欠.汉藏机器翻译中复句的翻译规则研究[C]//中文信息处理前沿进展——中国中文信息学会二十五周年学术会议.2006:454-460.
[6] 看卓才旦,金为勋,李延福,等.汉藏翻译系统中的动词处理研究[J].术语标准化与信息技术,2006,(3):28-32.
[7] 才让加.藏语语料库加工方法研究[J].计算机工程与应用,2011,47(6):138-139,146.
[8] 赵维纳,刘汇丹,等. 面向汉藏辅助翻译系统的平行语料库建设[C]//第三届全国少数民族青年自然语言信息处理暨第二届全国多语言知识库联合学术研讨会, 2010:43-46.
[9] 诺明花,张立强,刘汇丹,等.汉藏短语抽取[J].中文信息学报,2011,25(2):105-110,121.
[10] 诺明花,吴健,刘汇丹,等.汉藏短语对抽取中短语译文获取方法研究[J].中文信息学报,2011, 25(3):112-117.
[11] 侯宏旭,刘群,那顺乌日图,等.基于实例的汉蒙机器翻译[J].中文信息学报,2007,21(4):65-72.
[12] 姜柄圭,张秦龙,谌贻荣,等.面向机器辅助翻译的汉语语块自动抽取研究[J].中文信息学报, 2007,21(1):9-16.
[13] Koehn P, H Hoang, et al. Moses: open source toolkit for statistical machine translation, Association for Computational Linguistics[C].2007.
[14] Xin Yu, Weina Zhao, Jian Wu. Dictionary-based Chinese-Tibetan sentence alignment[C]//The 2010 IEEE International Conference on Intelligent Computing and Integrated Systems. 2010
[15] Pi-Chuan Chang, Michel Galley and Chris Manning. Optimizing Chinese Word Segmentation for Machine Translation Performance[C]//ACL Third Workshop on Statistical Machine Translation, 2008.
[16] Huidan Liu, Weina Zhao, Minghua Ruo, et al. Tibetan Number Identification Based on Classification of Number Components in Tibetan Word Segmentation[C]//International Conference on Computational Linguistics. 2010.
[17] Franz Josef Och, Hermann Ney. A Systematic Comparison of Various Statistical Alignment Models[J]. Computational Linguistics, 2003,29(1): 19-51.
[18] 张怡荪. 藏汉大辞典[M]. 民族出版社.1993.12.
[19] 民族出版社,汉藏对照词典[M]. 民族出版社. 2002.7
猜你喜欢
湖南工业职业技术学院学报(2022年3期)2022-12-06
通信技术(2021年12期)2022-01-25
原生态民族文化学刊(2017年2期)2018-06-01
敦煌学辑刊(2017年1期)2017-11-10
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中文信息学报(2012年2期)2012-06-29
中国火炬(2010年4期)2010-07-25
