
发音相似的朝鲜语和汉语单元音辨识方法
2013-04-14 07:51:28芦世丹崔荣一
中文信息学报 2013年2期
芦世丹,崔荣一
(延边大学计算机科学与技术学科智能信息处理研究室,吉林延吉133002)
1 引言
语种识别技术是智能信息处理领域的研究热点之一。在人类经济和文化活动日益国际化的趋势下,使用不同语言的人们互相之间的交流日益频繁,语种识别已成了一种不可或缺的技术[1]。语种识别即计算机通过分析处理一段语音信号以判别其属于何语种的过程[2],其学术特点在于它横跨信息处理、声学、语音学、模式识别理论和机器学习等多种学科;同时,语种识别在信息检索、多语种信息服务、国家安全、机器翻译与语音识别等系统的前端处理以及对说话人身份和国籍进行判别或监听等实际应用中扮演着不可替代的角色。
中国是一个多民族国家,据统计现有5 000多万少数民族人口在使用本民族的语言和文字,其中朝鲜族就是一个拥有自己民族语言和文字的少数民族之一。如今,对我国的朝鲜族人民来说,在日常文化生活等各个领域,常常混合使用朝鲜语和汉语。但是目前我国对朝鲜语的语音信息分析和处理技术的研究仍处于起步阶段[3],因此研究辨识汉语和朝鲜语等语种识别技术势在必行。随着智能信息处理技术的发展,汉语以及各种少数民族语言语音处理技术的研究已经取得了研究成果,如文献[4]建立了声韵调体系的区别特征系统;文献[5]对上海普通话与普通话元音系统的声学特征对比研究;文献[6]对蒙古语的元音进行了定量和定性分析;文献[7]和[8]对维吾尔语的声频特性分析和识别等。
朝鲜语的发音由元音和辅音构成,朝鲜语音节通过元音和辅音组合形成了四种构成方式:(1)元音,如“、、、”;(2)元音+辅音,如“、、、”;(3)辅音+元音,如“、、、”;(4)辅音+元音+辅音,如“、、、”。由此可以看出,朝鲜语的每个音节必须有一个元音,没有元音就不能构成音节,在语流中元音的数量和音节的数量是一致的[9],因此在朝鲜语的音节构成中,元音具有举足轻重的地位。同时,元音之间的跨语言比较要比辅音之间的比较相对容易,因此本文研究了具有相似发音的朝鲜语和汉语单元音的辨识方法。
本文主要以共振峰或其组合作为分类特征,用信息增益的方法确定分类阈值并对朝汉语单元音对进行了分类。实验结果表明,朝鲜语单元音和具有相似发音的汉语单元音之间存在可区分性,所采用的方法计算过程简单,并具有良好的分类效果。
2 声频分析及共振峰频率估计
2.1 朝鲜语单元音发音方法分析
(1) [a]:中元音,低元音,不圆唇元音
发音时口自然张开,下颚向下伸,舌尖也随之向下,嘴唇自然放松。发音时比汉语的“a”舌位稍微靠后。
(2) [ə]:中元音,半高元音,不圆唇元音
发音时口比“”张得小一些,舌面后部稍微抬起。发音时比汉语的“e”舌面后部要低一些,嘴张得稍微大一些。
(3) [o]:后元音,半高元音,圆唇元音
发音时口半开,但比发“”时嘴张得小一些,舌向后缩,舌面后部抬起,比发“”时抬高一些,双唇向前收敛成圆形。
(4) [u]:后元音,高元音,圆唇元音
发音时口开得很小,舌向后缩,舌面后部抬起,靠近软腭,双唇向前收敛成圆形,比发""更圆。发音时嘴唇不像发汉语"u"音时那样尖圆突出。
(5) [i-]:中元音,高元音,不圆唇元音
发音时口开得很小,舌稍向后缩,舌面中部向上抬起,接近上腭,嘴唇不圆,向两旁展开,成扁平形。
(6)[i]:前元音,高元音,不圆唇元音
发音时口微开,舌尖抵住下齿背,舌面抬起贴近上腭,双唇向左右自然拉开。发音时舌面前部要比汉语的“i”低一些。
(7) [ε]:前元音,半低元音,不圆唇元音
发音时口腔半开,舌尖抵住下齿背,舌面前部向硬腭抬起,升到半低程度,嘴唇不圆。
(8) [e]:前元音,半高元音,不圆唇元音
发音时口微开,舌尖抵住下齿背,舌面前部向硬腭抬起,升到半高程度,嘴唇不圆。
“”和“”的区别在于开口度和舌面前部的高度。“”比“”开口度大,舌面前部的高度低。
发音时开口度和舌位与发“”基本相同,但嘴唇要收敛成圆形。
发音时开口度和舌位与发“”基本相同,但嘴唇必须要收敛成圆形。
在朝鲜语的10个单元音中,与汉语单元音发音相似的有6个(如表1所示),朝鲜语单元音“”和汉语单元音“e”的波形图如图1所示。

表1 6对发音相似的单元音
2.2 共振峰提取
声道可以看成是一根具有非均匀截面的声管,在发音时起共鸣器的作用。当准周期脉冲激励进入声道时会引起共振,产生一组共振频率,称为共振峰频率或简称共振峰,它是区别不同元音的重要参数。不同的元音对应于一组不同的共振峰参数,为了精确地描述语音应尽可能使用多个共振峰,但在实际应用中只用前3个共振峰就够了,它们分别被称为F1、F2和F3[10]。

图1 朝鲜语单元音和汉语单元音e的波形图
提取共振峰特性最简便的手段是使用语谱仪,而采用数字信号处理的方法分析共振峰参数,也可获得与语谱仪相同的信息。常用的提取共振峰的方法有带通滤波器组法、倒谱法和LPC法。从线性预测导出的声道滤波器是频谱包络估计器的最新形式,线性预测提供了一个优良的声道模型。
从语音产生的数学模型可知,在大多数情况下,声道模型可以用一个全极点模型表示:

其中,m为线性预测阶数,ai(i=1,2,…,m)为m阶线性预测系数。使用Durbin递推算法可以求出声道模型H(z)的线性预测系数,然后令A(z)=0即可求出此多项式的m/2对共轭复数根(zi,zi*)(i=1,…,m),从而得到相应的共振峰频率和带宽。
2.3 平滑处理
在共振峰提取的过程中,无论采用哪种方法提取的共振峰频率轨迹与真实的共振峰轨迹都不可能完全吻合。实际情况是大部分段落吻合,而在一些局部段落和区域中会有共振峰估计值偏离,甚至远离正常轨迹,称这种偏离点为共振峰的“野点”。为了去除这些“野点”,对所求得的共振峰轨迹进行平滑处理是非常必要的。常用的平滑技术主要有:中值滤波平滑处理、线性平滑以及动态规划平滑处理[11]。
3 特征参数提取及阈值确定
3.1 共振峰的峰峰比
本文采用LPC法提取每帧语音信号的一组共振峰,并根据不同的分类对象选择不同的共振峰特征参数或共振峰组合,并对组合的共振峰对的所有帧参数比值累加求和,最后求其平均值而得到平均每帧语音信号的共振峰与共振峰的比值(本文称其为峰峰比),作为区分汉语和朝鲜语单元音的特征,其公式如下:

其中N表示音频文件划分的帧数,Fi和Fj表示第i和j个共振峰(i≠j)。朝鲜语单元音“”和汉语单元音“e”的共振峰特征如图2所示。
3.2 分类阈值的确定
根据前述特征值的分布,本文采用信息增益方法确定分类阈值。为了精确地定义信息增益,采用信息熵(entropy)刻画任意样例集的纯度。给定关于某个目标概念的样例集S,目标具有c个不同的值,那么目标概念的熵为:

其中pi是S中属于类别i的样本比例。
信息增益(information gain)可以作为属性分类训练数据的能力的度量标准。一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵的减少量。一个属性A相对样例集合S的信息增益G(S,A)定义为:
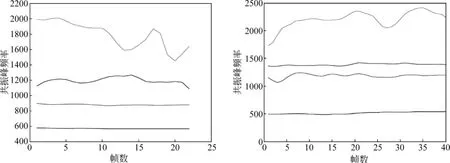
图2 朝鲜语单元音和汉语单元音e的共振峰特征
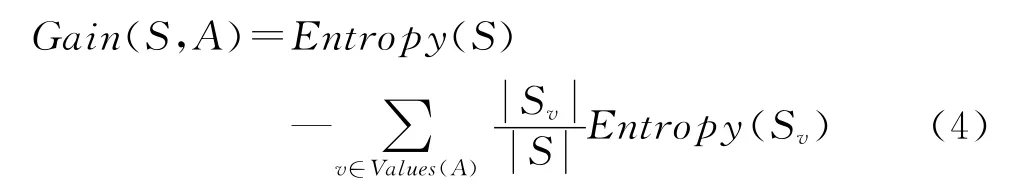
其中Values(A)是属性A所有可能值的集合,Sv是S中属性A的值为v的子集,即Sv={s∈S|A(s)=v}。
确定阈值的算法步骤如下:
Step1:对连续值属性A进行升序排序;
Step2:把连续值属性的值域分割为离散值的区间集合,按以下规则动态地创建一个新的Boolean属性Ac,具体规则如下:
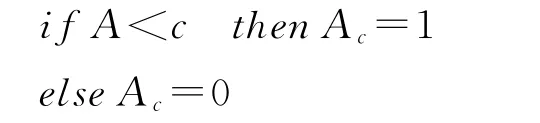
Step3:若相邻离散属性值不同,则计算该离散属性值对应的连续属性值的算术平均值作为候选阈值,直到找出所有候选阈值;
Step4:依次计算当每个候选阈值作为训练样例的特征分类的阈值时产生的信息增益,直到Step3中所有候选阈值对应产生的信息增益都被计算;
Step5:选择候选阈值中产生最大信息增益的阈值c作为最终的特征分类阈值。
4 实验结果及分析
本文的音频样本是采用SONY PCM-D50线性PCM录音棒在相对安静的实验室环境下录制的,采样频率8kHz,用16位进行量化,保存为WAV格式的文件。
实验一 朝鲜语单元音识别
采用24个滤波器,提取12维MFCC特征参数,并利用DTW算法识别朝鲜语的10个单元音,识别结果如表2所示。实验结果表明,10个朝鲜语单元音具有可区分性,其中“”和“”易混淆,“”和“”不容易区分。

表2 10个单元音采用MFCC特征和DTW的识别结果
实验二 单元音对辨识
根据朝鲜语单元音和对应的发音相似的汉语单元音的共振峰分布差异,选择能有效区分单元音对的共振峰作为特征。
(1)朝鲜语单元音“”比汉语单元音“a”舌位稍微靠后,根据这个发音差异,可以利用第二共振峰特征F2来分类,如果单元音共振峰频率小于分类阈值时被分类为朝鲜语单元音“”,当大于阈值时被分类为汉语单元音“a”;
(2)朝鲜语单元音“”比汉语单元音“o”靠前,因此可以选择第二共振峰F2进行分类,当共振峰频率大于分类阈值时被分类为朝鲜语单元音“”,而小于分类阈值时被分类为汉语单元音“o”,且因汉语单元音“o”的第三共振峰与第四共振峰之间的差距较大,可以采用第三共振峰与第四共振峰的峰峰比进行分类;
(3)朝鲜语的“”比汉语的“e”舌面后部要低一些,嘴张的要大一些,因此可以同时选择第一共振峰F1和第二共振峰F2作为分类特征,如果某一单元音的第一共振峰频率大于F1分类阈值且第二共振峰小于F2分类阈值时,则被分类为朝鲜语单元音“”;
(4)朝鲜语单元音“”发音时舌面前部比汉语单元音“i”低,因此可以选择第一共振峰F1作为分类特征,如果某一单元音的F1大于分类阈值,则该单元音被分类为朝鲜语单元音“”,否则被分类为汉语单元音“i”;
(5)朝鲜语单元音“”发音时不像汉语单元音“u”那样尖圆突出,因此选择第二共振峰作为分类特征,当F2大于分类阈值时,被分类为朝鲜语单元音;
实验结果如表3所示。
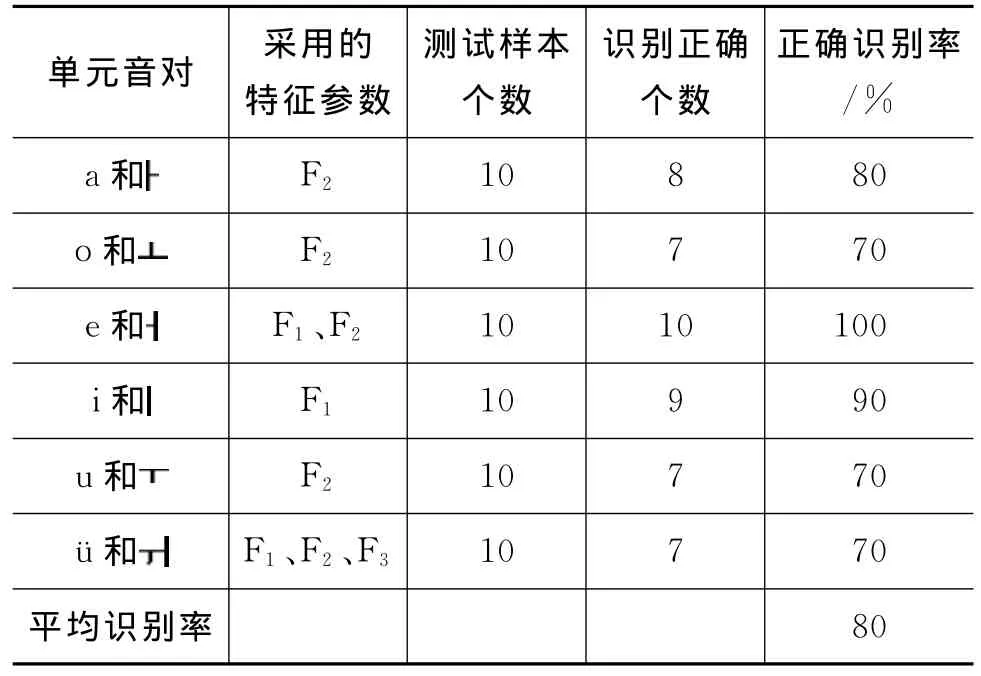
表3 单元音对的识别结果
选择不同的共振峰特征参数或共振峰组合的峰峰比作为分类特征,采用信息增益确定分类阈值进行分类,可以获得较高的分类正确率,这也验证了声学角度的元音特性。每个元音在口腔中所占有的位置与元音的共振峰频率有对应关系。一个元音的第一共振峰越低,这个元音的舌位就越高;一个元音的第一共振峰的频率越高,这个元音的舌位越低。一个元音的第二共振峰频率越低,这个元音的舌位就越靠后;一个元音的第二共振峰频率越高,这个元音的舌位就越靠前。另外,F1和F2与嘴唇的圆展程度也有关系,如圆唇可使F2降低。第三共振峰F3虽然与舌位的关系并不密切,但受舌尖活动的影响,舌尖抬高卷起时,F3就明显下降。不同的人发同一元音时,每个人发音的共振峰的频率不会绝对相同,因此,它们的共振峰频率位置不会完全重叠,而会有所差异,但这些差异是同一个元音的共振峰频率位置范围内的差异[12]。
5 结论及下一步工作
本文采用共振峰或峰峰比作为特征,对朝鲜语中与汉语发音相似的六对单元音进行了辨识。由于不同人发同一个元音的共振峰频率也会有较大的差异,因此元音的共振峰频率分布并不是一个点,而是一个区域,采用信息增益方法来划分这个区域,可以获得较好的分类效果。但是该方法仍不能从单元音本身的细节特征进行分类,这也体现了该方法的局限性。如何从单元音本身的细节特征来改善分类效果,是下一步工作的重点。
[1] 黄山奇,张连海,屈丹.一种基于人耳听觉感知和子带补偿滤波的鲁棒语言辨识特征参数提取方法[J].模式识别与人工智能,2012,25(1):166-171.
[2] K E Wong,BEng(Hons),BIT.Automatic Spoken Language Identification Utilizing Acoustic and Phonetic Speech Information[D].Queensland University of Technology.2004:9.
[3] 金哲俊.关于朝鲜族男生的朝鲜语单元音共振峰的特征研究[J].东疆学刊.2010,27(1):74-77.
[5] 于珏,李爱军,王霞.上海普通话与普通话元音系统的声学特征对比研究[J].中文信息学报,2004,18(6):66-72.
[6] 呼和.蒙古语元音的声学分析[J].民族语文,1999,(4):58-60.
[7] 祖丽皮亚·阿曼,艾斯卡尔·艾木都拉.维吾尔语双音节词韵律特征声学分析[J].中文信息学报,2009,23(5):104-107.
[8] 王昆仑,张贯红,吐尔洪江·阿布都克力木.维吾尔语元音的声频特性分析和识别[J].中文信息学报,2010,24(2):122-128.
[9] 金永寿,张英美,金海守.基础韩国语[M].哈尔滨:黑龙江朝鲜民族出版社,2009:4-11.
[10] 赵力.语音信号处理(第二版)[M].北京:机械工业出版社,2009:7-8.
[11] 韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004:91.
[12] 董滨,赵庆卫,颜永红.基于共振峰模式的汉语普通话中韵母发音水平客观测试方法的研究[J].声学学报,2007,32(2):122-128.
猜你喜欢
考试与评价·七年级版(2021年1期)2021-08-14 04:25:30
韩国语教学与研究(2021年1期)2021-07-29 08:43:46
考试与评价·七年级版(2020年1期)2020-10-23 09:10:18
知识经济·中国直销(2018年12期)2018-12-29 12:22:12
当代陕西(2018年12期)2018-08-04 05:49:22
纺织科学研究(2017年4期)2017-05-17 03:59:56
韩国语教学与研究(2016年2期)2016-10-19 00:54:36
新闻传播(2016年4期)2016-07-18 10:59:20
中国卫生(2014年9期)2014-11-12 13:02:06
小学生时代·大嘴英语(2014年6期)2014-11-04 00:35:50
