
基于分段的藏字校对算法研究
2013-04-14 07:49:58安见才让
中文信息学报 2013年2期
安见才让
(青海民族大学计算机学院,青海西宁810007)
1 引言
信息社会的发展,使电子书、网上图书馆以及网页等种类繁多的信息不断出现,供人们使用。这些信息主要是通过键盘录入、扫描等方式输入到计算机的,但是,任何一种方式都无法保证存入的信息准确无误。文本校对技术正是解决准确地输入信息的一种专业性技术。
国外英文文本校对方面取得了一定的成果,部分成果实现了产品化。英文的校对分为两部分,一是针对英语单词内部出现的拼写错误[1],主要采用最小编辑距离技术、相似键技术等六种方法来实现;二是对句子中出现的单词正确但用法错误进行校正,主要采用自然语言处理和统计语言模型技术(SLM)解决。由于汉语和少数民族语言与英语在语言本身及文本的输入方式上均存在较大差异,因而汉语或少数民族语言的文本校对系统所采用的策略和技术与英文的校对系统有一定的差异。现普遍采用的技术有词切分技术[2]、最小编辑距离技术[2]、近似集模糊匹配技术[3-5]、语法分析及语义分析技术等[3,6]。国内在文本校对方面的研究始于20世纪90年代初期,但发展速度较快,其中藏字的主要校对方法采用字典匹配的方法进行。本文通过研究藏字的语法和构字规律,提出了一种新的校对方法。
2 藏字语法
藏字是由元音和辅音通过一定的语法规则组合形成,其语法形式化地描述为:设B、O、Pr、Back、 FurthBack、Up和Lw分别表示辅音集、元音集、前加字集、后加字集、再后加字集、上加字集和上加字集,则,B={{,,,},{,,,,},{,,,},{,,,},{,,,},{,,,,},{,,,},{,}},辅音共有30个字母,共8组;O={,,,},共有4个元音字母;Pr={,,,,},共有5个字母;Back={,,,,,,,,,},共有10个字母;FurthBack={,},共有2个字母;Up={,,},共有3个字母;Lw={,,,},共有4个字母。藏字的构成结构如图1所示。

图1 藏字结构
藏文字母按前加字+上加字+基字+下加字+元音+后加字+再后加字的顺序进行组合,前加字、上加字、基字、下加字、元音、后加字和再后加字可以省缺,但是,藏字不是前加字集合、上加字集合、基字集合、下加字集合、元音集合、后加字集合和再后加字集合中的各一个字母的简单组合,而是需按字母的字性规范进行组合,比较复杂。若以元音位置为中心,可以把藏字分成两个部分:前段pretibet和后段backtibet。前段部分生成规则如表1所示。

表1 藏字前段生成规则

续表
另外,1998年颁布的中国国家标准《信息交换用藏文编码字符集基本集》(GB16959-1997)只包括了41个藏文编码字符(含藏文和梵音藏文),加上其他组合用字符及篇章装饰或标点类符号共计168个[7]。藏字的横向和纵向叠置分别用藏文字母和藏文主字字符组合实现。所以,同一藏文字母有两种字符(机内):藏文字母和藏文主字,如图2所示。

图2 藏文主字和藏文字母
将藏字分为两类:无叠加字和有叠加字,每类又分为两类:有元音和无元音。

3 Unicode编码的藏字结构特征
以Unicode为编码的藏字以有无元音与主字以及主字的个数为对象,对藏字结构进行分析和研究,得到如表2所示结构信息。

表2 藏字结构信息

续表

续表
对表2中藏字结构进行分析,得到合法藏字结构及分段点位置的特征如下:
① 藏字中若有元音,则元音位置为分段点;
②无叠加字符和元音的藏字中:
若字长为1,该字的分段点位置为1;若字长为2,第一个字符是基字,第二个字符是后加字,分段点位置为1;字长为4,第二个字符是基字,分段点位置为2;
若字长等于3,第一、二、三位字符既满足作前加字、基字、后加字的语法条件,又满足作基字、后加字、再后加字的条件,这时要判断第一个和第二个字符是否是同组,若是同组,则该藏字按基字+后加字+再后加字处理,分段点位置为1,否则按前加字+基字+后加字处理,分段点位置为2;
③有叠加字符而无元音的藏字中:
含有2个主字,第一个主字为基字,第二个主字为下加字,基字之前的字符为上加字,分段点的位置为第2个主字的位置;
④ 没有叠加字符的藏字中,若有前加字,其肯定出现在基字之前,若有元音,元音肯定出现在基字后面,后加字肯定出现在元音之后,再后加字出现在后加字后面;
⑤ 有下加字的叠加藏字中,若有元音,元音出现在下加字之后,其次是后加字,再次是再后加字;若没有元音,后加字出现在下加字之后,其次是再后加字。但后加字也可能被缺省;
⑥ 没有后加字,就没有再后加字,也就是说有再后加字,肯定有后加字;
⑦ 有上加字的藏字中,若有前加字,前加字出现在上加字之前;没有上加字的藏字中,若有前加字,前加字出现在基字之前;
⑧有叠加字肯定有主字,主字数为1或2;
通过藏字结构中元音位置特征对藏字进行分割,产生藏字的前段和后段。
4 藏字检错算法描述
第七步:主字数为2时,p=第二个主字的位置;
第八步:对藏字字符串进行分割。将p(包含p的位置上的字符)之前的字符串存入preword中,p之后的字符串存入backword中。
第九步:判断preword是否存在于集合pretibet中,若不存在,报错,结束,否则,再继续检查backword是否存在于集合backtibet中,若不存在,报错,结束。
注:p是整型变量,记录分段点的位置。
第一步:
(1)分字。按分字点和结束符号进行分字。

(2)预处理。对各个字的语法单位进行还原。
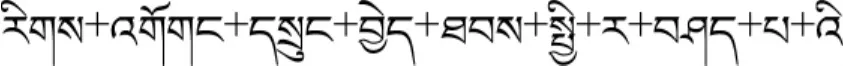
藏字在计算机中实现检错时,主要通过分析有无主字和元音来确定分段点,分割并检测藏字。
藏字检错过程:
第一步:分字和预处理,计算字长,若字长>7,报错,否则转下一步;
第二步:判断藏字中有无主字,若有转第六步,否则转下一步;
第三步:判断藏字中有无元音,若有,转第五步,否则转下一步;
第四步:判断藏字长度。若字长>4,报错;若字长=1,报对;若字长为2,p=1;字长等于3,判断第1个字符是否在集合pr中,若是,再判断第1个字符和第2个字符是否为同组,若不是,则第1个字符是前加字,第2个字符是基字,p=2,否则,第1个字符为基字,p=1,转第八步;字长为4,第2个字符为基字,p=2,转第八步。
第五步:计算元音的位置t。p=t-1,转第八步;
第六步:判断有几个藏文主字。若有1个主字,p=主字位置,转第八步,否则转下一步;
第五步:字长为4,元音前的字符的位置为1,则p=1,转第八步。
第九步:经判断,preword在pretibet集合中,lastword在backtibet集合中。所以,符合语法。再回到第二步,检查下一个藏字。
5 实验
实验时,我们将集合pretibet和lasttibet中的元素分别放入两个数组pretibet和lastibet中,作了排序,检索时用二分法,以提高算法性能。
我们选用了一段文字进行实验,算法正确地检索出6个错误,并做了标记,如下:

6 结束语
当前,藏文信息处理技术落后于汉文信息处理技术,汉文的校对技术不能直接应用于藏文信息处理。本文通过研究藏字的语法和构字规律,提出了一种校对藏字的方法,可有效解决长期困扰藏字校对的困难。该方法可应用于语料库、文字识别[8]、语音识别和出版印刷等领域和行业的研究。
[1] 玛依热·依布拉音,米吉提·阿不里米提,艾斯卡尔·艾木都拉.基于最小编辑距离的维语词语检错与纠错研究[J].中文信息学报,2008,22(3):110-114.
[2] 陆玉清,洪宇,陆军,等.基于上下文的真词错误检查及校对方法[J].中文信息学报,2011,25(1):85-90.
[3] 张磊,周明,黄昌宁,等.中文文本自动校对[J].语言文字应用,2001,1:19-26.
[4] 陈笑蓉,秦进,汪维家,等.中文文本校对技术的研究与实现[J].计算机科学,2003,30(11):53-55.
[5] 张仰森.中文校对系统中纠错知识库的构造及纠错建议的产生算法[J].中文信息学报,2001,15(3):33-39.
[6] 于勐,姚天顺.一种混合的中文文本校对方法[J].中文信息学报,1998,12(2):31-36.
[7] 中华人民共和国国家标准.信息交换用藏文编码字符集基本集(GB16 959)[M].中国标准出版社,1997.
[8] 李元祥,刘长松,丁晓青.一种利用校对信息的汉字识别自适应后处理方法[J].中文信息学报,2001,15(1):46-52.
猜你喜欢
考试与评价·七年级版(2021年1期)2021-08-14 04:25:30
考试与评价·七年级版(2020年1期)2020-10-23 09:10:18
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
小学生时代·大嘴英语(2014年6期)2014-11-04 00:35:50
电脑迷(2014年8期)2014-04-29 07:37:40
卷宗(2011年9期)2011-05-14 17:51:19
计算机应用文摘(2009年11期)2009-04-29 00:44:03
