
指数函数规整群时延的VAD特征研究
2013-04-03 00:13:44王金芳
吉林大学学报(工学版) 2013年1期
王金芳,虢 明
(吉林大学通信工程学院,长春130012)
语音活动检测(Voice active detection,VAD)是检测语音中有/无声的技术。早期VAD利用启发式模型,例如短时能量[1]、短时过零率[2]、高阶统计分析[3]等对语音和非语音实施判别。近期的系统采用特征-模型的方法,包括两个关键部分:特征提取和模型建立。由于上述方法的特征容易受到噪声的影响,在高噪声条件下,其检测性能难以得到保障,如何提取强鲁棒性的特征成为这种方法的关键。在听觉感知方面,Alsteris等[4]证实,短时相位谱起着重要作用。群时延函数(Group delay function,GDF)是相位谱对频率的微分,作为特征,已展示出对语音一定的表征效力[5-7]。经由Murthy等[8]分析和证明,群时延函数具有优良的噪声鲁棒性能。时域信号的卷积,在频域表现为信号相乘,相位则为相加,因此,谐振的存在导致群时延函数本身具有明显的尖峰效应,妨碍进一步处理。一种改进方法是将幅度谱进行倒谱平滑[7],并引入两个参数降低其动态变化范围,得到改进群时延函数(Modified group delay function,MODGDF)[5]。为满足对共振峰的有效估计,改进的群时延函数摒弃了语音信号中的激励成份,只保留声道响应部分,造成MODGDF对原声学空间表征能力下降。本文提出指数函数规整群时延函数(Exponent function warping group delay function,EGDF),在降低群时延谱动态变化范围、抑制尖峰效应的同时,减少特征提取过程的信息丢失。基于GMM的VAD实验表明,在噪声鲁棒性和检测精度方面,本文方法优于改进的群时延函数。
1 群时延函数
设语音信号序列x(n)的傅里叶变换表示为x(ejω),其相位为θ(ejω),则极坐标形式的傅里叶变换为
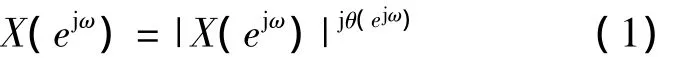
定义群时延函数

式中:下标R和I分别表示实部和虚部;Y(ejω)是信号的傅里叶变换。信号y(n)=nx(n)的傅里叶变换的连续性使得未卷绕(Unwrapped)的相位函数具备连续性。由于实际计算中,相位被卷绕到(-π,π]区间内,如果直接对相位取导数会因卷绕造成群时延函数不具备连续性,因此选择式(2)作为群时延函数常用表达式。根据语音信号产生的源滤波器模型,假设声道冲激响应由若干谐振器和反谐振器级联而成,表现形式即是傅里叶变换幅度的相乘,其傅里叶变换相位谱转化为若干谐振器和反谐振器非卷绕相位谱的叠加。经对式(1)取对数操作,原傅里叶变换域各模块乘积形式转化为群时延域加性形式。谐振时,群时延数值急剧增大,出现局部峰值,而根据式(2),此时的信号幅度接近零,即信号z变换零点接近单位圆,形成群时延函数的尖峰效应,零点越接近单位圆,其幅度越大[8]。图1(c)给出取样率8 kHz,时长25 ms语音片段的群时延函数曲线。可观察到,群时延幅度范围大大高于幅度谱的范围,并且较幅度谱观察不到明显的说话人信息。激励源声门周期是另外一种产生群时延尖峰效应的因素,表现为谐波成份,如图1(a)中周期性的波动成分,对群时延谱精细结构有很大贡献。通常的平滑技术难以消除这些尖峰,尖峰效应的存在使计算难度加大。对于共振峰估计等,只需得到尖峰位置信息,不需要尖峰的强度,所以需抑制尖峰效应,一种方法是丢掉激励源信息,而仅考虑声道信息,即倒谱平滑群时延函数(Cepstrally smoothed group delay function,CSGDF),最初由Yegnanarayana等[7]提出,实施方法是以倒谱平滑版本|Sc(ejω)|2取代式(2)的分母项|X(e)jω|2而得到
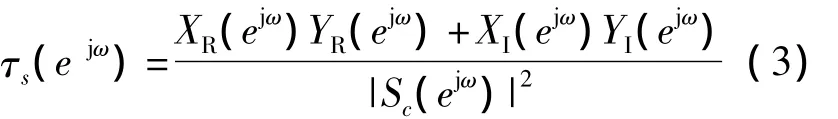
按文献[5]选择最优倒谱平滑滤波器长度l=6,其倒谱平滑群时延函数如图1(d)所示,其动态范围较GDF进一步增加,却可以观察到与幅度谱相似的信息。
接着,Murthy等[5]引入两个参数α和γ,使倒谱平滑群时延函数的动态范围进一步降低,得到改进群时延函数(MODGDF)为
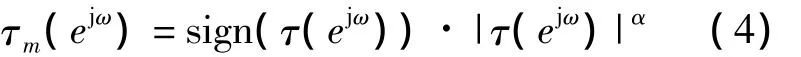
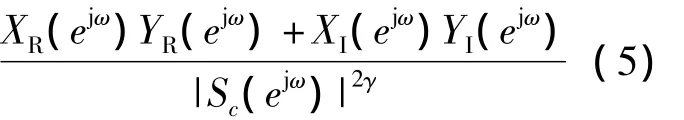
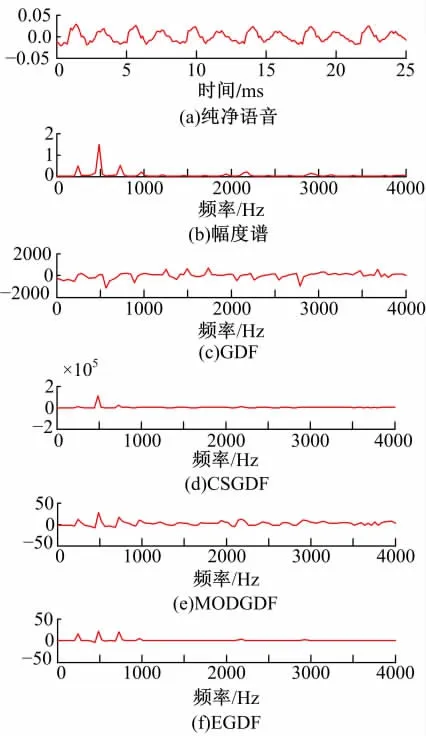
图1 纯净语音、幅度谱及各类群时延谱Fig.1 Pure speech,amplitude spectrum and various group delay spectrums
2 指数函数规整群时延
由于CSGDF和MODGDF的目的是利用其共振峰估计信息,都只是改进群时延函数的声道特性。由于忽略激励源信息,降低了语音表征力。
为了在减小群时延变化动态范围的同时避免丢失语音有效信息,定义指数函数规整群时延函数

其曲线如图1(f)所示,不仅保留了激励源信息,而且缩短了群时延变化动态范围。从幅度谱可观察到明显的共振峰,而各次谐波并不明显;群时延具有很大的动态范围,谐波信息几乎无法辨别; CSGDF谱F2尖峰突出,其它尖峰受到抑制,谐波信息难以辨别;MODGDF谐波信息丰富,动态范围降低约数千倍,虽然能够确定强共振峰F2的位置,但其它共振峰几乎被谐波尖峰淹没;从EGDF谱能明确观察到各共振峰和谐波信息。
将与图1相同的一段语音片段叠加白噪声分别生成信噪比为5 dB、0 dB的带噪语音,其相应的波形分别如图2、图3所示。

图2 带噪语音、幅度谱及各类群时延谱(白噪声SNR=5 dB)Fig.2 Noisy speech,am p litude spectrum and various group delay spectrums(White noise SNR=5 dB)

图3 带噪语音、幅度谱及各类群时延谱(白噪声SNR= 0 dB)Fig.3 Noisy speech,am plitude spectrum and various group delay spectrums(W hite noise SNR=0 dB)
图2(c)、图3(c)群时延谱动态范围较图1 (c)仍很大,尤其值得注意的是,因为噪声的影响,出现许多伪峰值。带噪语音CSGDF谱的问题与纯净语音情况一样凸显。MODGDF除F2尖峰外,其它共振峰尖峰几乎被噪声干扰淹没,频频出现与GDF相似的负峰值。带噪EGDF谱的各共振峰仍然清晰可辨;与带噪MODGDF对比,整个频带噪声受到抑制,并且没有出现伪峰值和负峰值;同GDF和CSGDF对比,群时延动态变化范围大幅降低,与MODGDF不相上下。
比较图2和图3,当噪声功率增加时,GDF和MODGDF变化很大,除大的共振峰外,其他的显得杂乱无章,而EGDF基本没有变化,源和声道信息仍然清晰可辨,表明其优良的噪声鲁棒性。
3 VAD算法及性能评价
3.1 VAD算法
GDF、CSGDF、MODGDF和EGDF倒谱域特征的计算框图如图4所示。

图4 各倒谱域特征的计算框图Fig.4 Block diagram of various cepstral features
将带噪语音和背景噪声分别建立高斯混合模型,记为λ1和λ0。根据测试语音特征集x,对某一帧信号,分别与上述两个模型匹配,根据得分结果,按照下述准则进行判决决策
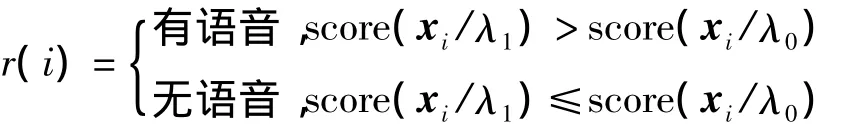
式中:i为帧序号,r(i)表示第i帧的判决结果。
3.2 实验结果
实验语音选自标准语音库TIMIT数据库,其语音采样率为16 kHz,噪声取自NOISEX-92库,将原语音和噪声数据均下采样为8 kHz。预加重系数取0.97,分析窗为矩形窗,窗长25 ms,帧移10 ms。分别按信噪比10 dB、5 dB和0 dB叠加白噪声和Babble噪声生成带噪语音。使用带噪语音(非静音)数据训练带噪语音的GMM,其混合度为20;噪声GMM训练数据截取自测试语音,一般可认为语音信号前200 ms为纯噪声。以GDF、CSGDF、MODGDF和EGDF的倒谱系数为特征进行GMM语音活动检测,检测结果如图5~图10所示。

图5 VAD结果(白噪声SNR=10 dB)Fig.5 VAD results(W hite noise SNR=10 dB)
从检测结果可知,三种信噪比下,EGDF的检测性能都优于GDF、CSGDF和MODGDF。几种情况下,EGDF都能准确检测浊音,其它方法误差很大,噪声的存在使错检增多。对比图5 (e)和图6(e),5 dB结果几乎接近于10 dB的结果,从实验角度证实了EGDF具有良好的噪声鲁棒性。0 dB的检测效果有所下降,因噪声影响导致对浊音的错检增多,且算法对Babble噪声的检测效果不及白噪声的效果,因为其更接近语音信号。

图6 VAD结果(白噪声SNR=5 dB)Fig.6 VAD results(W hite noise SNR=5 dB)

图7 VAD结果(白噪声SNR=0 dB)Fig.7 VAD results(W hite noise SNR=0 dB)
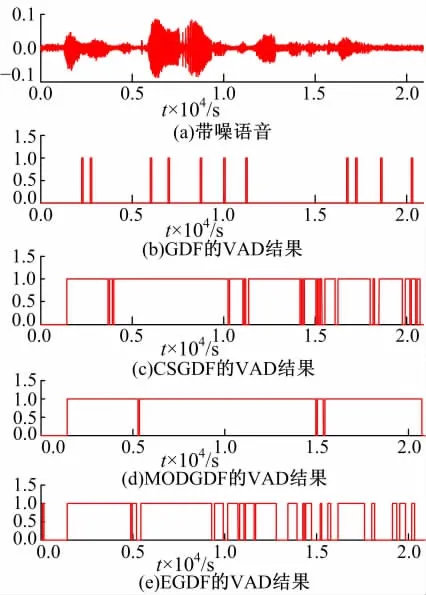
图8 VAD结果(Babb le噪声SNR=10dB)Fig.8 VAD results(Babble noise SNR=10dB)
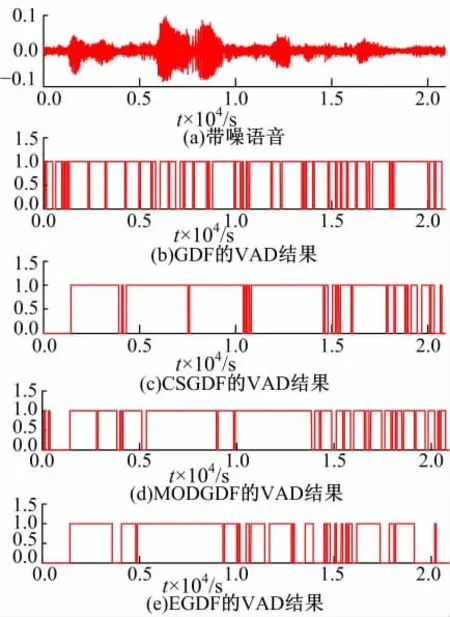
图9 VAD结果(Babble噪声SNR=5 dB)Fig.9 VAD results(Babble noise SNR=5 dB)
4 结论和展望
导致群时延函数尖峰效应的根本原因是语音信号z变换零点接近单位圆。本文提出指数函数规整的群时延函数,在计算初始群时延函数基础上,对其表达式中的功率谱采用指数函数规整,消除其在某一点为零的可能性,同时降低群时延的尖峰效应。GMM语音活动检测实验表明,本文方法不但优于其他的群时延函数,而且在噪声条件下具有良好的鲁棒性,验证了文献[8]所言。今后的研究重点是进一步改进群时延函数,以加强其在更低信噪比下的鲁棒性。
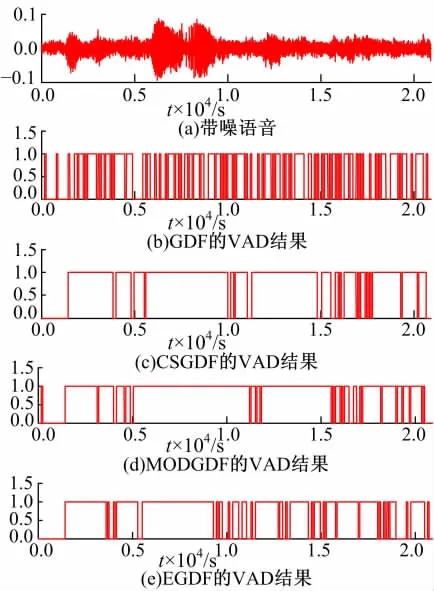
图10 VAD结果(Babble噪声SNR=0 dB)Fig.10 VAD results(Babble noise SNR=0 dB)
[1]Dong E,Liu G,Zhou Y,et al.Voice activity detection based on short-time energy and noise spectrum adaptation[C]∥In 2002 6th International Conference on Signal Processing(ICSP'02),Beijing,China,2002:464-467.
[2]Sangwan A,Chiranth M C,Jamadagni H S,et al.VAD techniques for real-time speech transmission on the Internet[C]∥In 5th IEEE International Conference on High Speed Networks and Multimedia Communications,Jeju Island,Korea,2002:46-50.
[3]Nemer E,Goubran R,Mahmoud S.Robust voice activity detection using higher-order statistics in the LPC residual domain[J].IEEE Transactions on Speech and Audio Processing,2001,9:217-231.
[4]Alsteris L D,Paliwal K K.Short-time phase spectrum in speech processing:a review and some experimental results[J].Digital Signal Processing,2007,17:578-616.
[5]Murthy H A,Gadde V.Themodified group delay function and its application to phoneme recognition[C]∥In 2003 IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP'03),Hong Kong,China,2003:68-71.
[6]Murthy H A,Madhu Murthy K V,Yegnanarayana B. Formant extraction from phase using weighted group delay function[J].Electronics Letters,1989,25:1609-1611.
[7]Yegnanarayana B,Murthy H A.Significance of group delay functions in spectrum estimation[J]. IEEE Transactions on Signal Processing,1992,40:2281-2289.
[8]Murthy H A,Yegnanarayana B.Group delay functions and its applications in speech technology[J].Springer,2011,36:745-782.
猜你喜欢
国防科技大学学报(2021年5期)2021-10-10 04:35:42
少儿美术(快乐历史地理)(2020年7期)2020-11-26 06:25:46
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
电子科技(2018年4期)2018-04-08 02:06:40
百科探秘·航空航天(2017年11期)2017-12-20 07:31:38
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
电子设计工程(2015年4期)2015-01-25 10:51:12
太空探索(2014年4期)2014-07-19 10:08:58
