
基于树编辑距离的聚类算法数据记录抽取
2013-01-03 02:42:36宫丽娜祝美莲
赤峰学院学报·自然科学版 2013年12期
宫丽娜,祝美莲
(1.枣庄学院,山东 枣庄 277160;2.中国石油大学(华东),山东 青岛 266580)
1 引言
网页信息抽取为许多网络信息处理应用领域包括网络数据挖掘、网络信息检索等提供了有益的基础.
前人已经进行了很多网页信息抽取方法的研究 (如[3][8];文献[1]给出了一个简短的总结).RoadRunner[2]:自动生成包装器的系统,但是它会产生一些错误的模式,准确率较低.MDR[3]方法是第一个全自动的抽取信息的算法,这种方法完全不需要用的参与.DEPTA[4]算法是MDR方法的一种改进,它假设网页中每两条数据记录之间的视觉空间都要比数据记录之间的空间大,但是这种情况并不是总是成立的.所有这些方法都具有一些缺点.
本文中,提出了一种新的自动从网页中抽取数据记录的方法.首先,构建DOM模型;第二,我们采用了三种启发式的规则来发现网页的主数据区域;最后提出了一种基于树编辑距离的聚类算法,来分离数据记录.通过大量真实网页的实验验证,本文方法具有较高的准确率.
2 主数据区域发现
2.1 DOM树模型
本文方法首先需要将网页的HTML文档转化为DOM树的形式,由于HTML语言本身也不够严谨,因此要对源文件进行预处理.同时我们还要对标签进行过滤,去掉一些没有用的干扰标签.如<select>标签,这个标签下面通常会有很多的节点选择,会给我们后面的分析造成干扰,预处理的时候将其去掉.
2.2 主数据区域发现
通常,列表页面都满足下面几个特征[8]:DOM树中的每条数据记录都是有一系列的连续兄弟子树组成的.而且,能够发现每条数据记录都是由一定数量的完整子树构成的.
从上述特性得知,定位主数据区域我们所要做的就是找到包含所有记录项的最小DOM子树的根节点.本文给出了三种启发式方法,分别从DOM树的不同特征考虑当前节点是否包含所有目标记录项.
2.2.1 最大扇出子树法,思想是:一个节点包含的子节点越多,它就越有可能是包含所有数据记录的最小DOM子树的根节点.
2.2.2 最大内容增大法.计算节点的总的内容量,并减去节点的平均内容量(节点大小除以节点扇出值),作为节点的内容增大量,一个节点的内容增大量越大,它越有可能是包含所有数据记录的DOM子树的根节点.
2.2.3 最大标记量法,考虑子树中包含的HTML标记量,对于没有祖先关系的两个节点,节点包含的HTML标记越多,它排位越靠前.
将上述三种方法分别加一个权重,根据权重计算得到一个加权平均的排序节点列表.列表的第一个节点就是我们所要找的节点.
3 数据记录分割
接下来要研究的是如何将主数据区域中的多条数据记录进行分离.我们采用树编辑距离来表示两棵相邻子树的相似度.
3.1 树编辑距离
计算两棵树的树编辑距离,主要就是要找出两棵树之间的一个权值最小的映射,这个映射可以有如下的定义:
假定X是一棵树,X[i]是树X中第i个子节点.那么T1和T2之间的映射M是满足以下条件的有序数对(i,j)的集合对于任何(a1,b1),(a2,b2)
(1)a1=a2 当且仅当 b1=b2
(2)T1[a1]是 T1[a2]的左邻节点当且仅当 T2[b1]是 T2[b2]的左邻节点
(3)T1[a1]是T1[a2]的父节点当且仅当T2[b1]是T2[b2]的父节点
本文采用简单树匹配算法来求解树编辑距离.令A=(RA,A1,…,Am)和 B=(RB,B1,…,Bn)是两棵树,其中 RA和 RB是 A和B的根节点,Ai和Bj分别是A和B的第i个和第j个第1层子树.当RA和RB的标记相同时,A和B的最大匹配为MA,B+1,其中MA,B是<A1,A2,…,Am>和<B1,B2,…,Bn>的最大匹配.伪代码如算法1所示:
算法 1:STM(A,B)
1 开始
2 如果RA和RB不同
3 返回0;
4 否则
5 设m为节点RA的子树的个数
6 设n为节点RB的子树的个数
7 M[i,0]←0所有的 i=0,…,m
8 M[0,j]←0所有的 j=0,…,n
9 从i=1到m
10 从j=1到n
11 W[i,j]←STM(Ai,Bj)
12 M[I,j]=max(M[i,j-1],M[i-1,j],M[i-1,j-1]+W[i,j])
13 结束
14 结束
15 返回M[i,j]+1
16 结束
给定两个HTML文档,它们对应的DOMTree为T1,T2,T1,和T2中每一个节点标记对应HTML中的一个标签,其中文本节点用<text>节点代替.记树T的节点数目为|T|,定义T1与T2的相似度为:
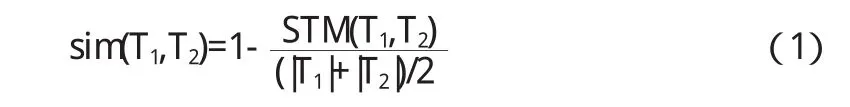
上式中,|T1|,|T2|分别表示两棵树的最大匹配节点数.两棵树的最大匹配节点数越大,则两棵树越相似,即它们所代表的HTML文档也就越相似.
3.2 聚类算法
由第三节中描述的列表页面的特点知,数据记录可以是一棵或者多棵连续子树的集合,这样可以产生候选的分割方案,设主数据区域的根节点有n棵子树,则可以产生2n-1候选分割方法,算法的效率很低.本文采用聚类算法将子树分类,来减少候选分割方案的数量,来提高算法的效率.
对样本空间进行聚类,需规定样本的相异度值,其由相异度矩阵表达,定义如下.
相异度矩阵(dissim ilarity matrix)用来存储n个样本两两之间的相似性,形式为n×n维矩阵:
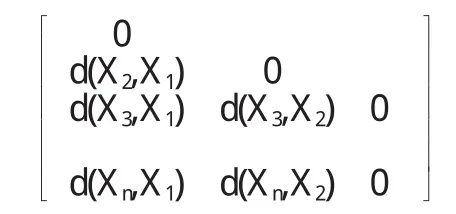
我们用d(X2,X1)来表示样本Xi和Xj相异性,取值非负数.对象i和j越相似,其值越接近0;否则其值越大.
用上一节介绍的STM算法计算两棵子树的距离,首先将每棵子树都作为一个单独的簇,定义一个阈值d0,当两棵子树之间的距离小于d0时,把两棵子树聚类,作为一个大类.阈值d0的大小会影响到簇的数量和规模:如果d0比较大,簇的规模也会比较大大,反之类似.所以选择一个适当的阈值聚类成功的关键,通过多次试验本文选取的d0值为0.15.
设Ci和Cj分别代表两个不同的类,Xi和Xj分别表示Ci和Cj的类中心,则类Ci和Cj之间距离我们采用平均距离进行度量:
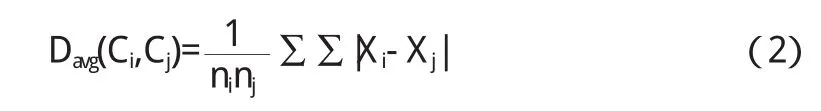
其中,ni和nj表示类Ci和Cj的样本数目.
算法2:聚类
(1)假设每个子树Xi都是一个簇{Xi}.
(2)设d0为相似度阈值.
(3)计算相似度矩阵值D=(Dij)m×m,m是簇的个数.
(4)找到最小的矩阵值D,
如果D值小于d0,
将Xi和Xj合并为一个新的簇,并设m=m-1.
否则结束
(5)如果m>2继续执行(3)
(6)否则结束.
如图1给出了一个简单的聚类结果的例子,10棵子树,聚成了三个类.
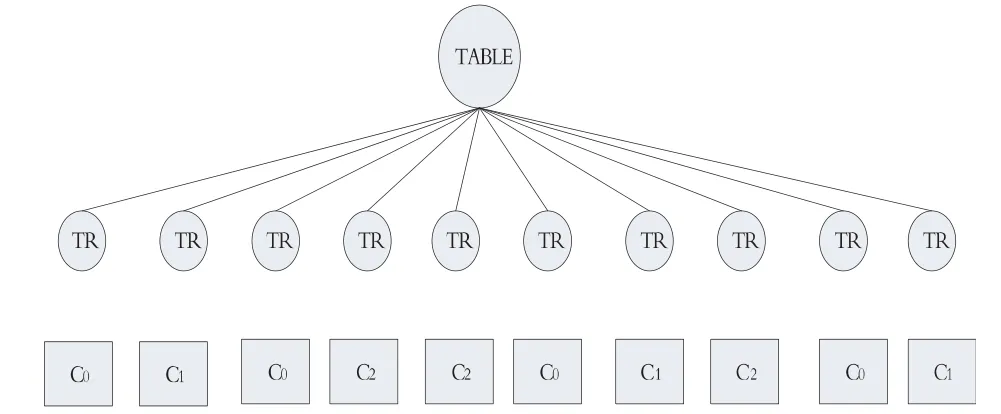
图1 聚类结果示例
前面的预处理步骤完成后,我们下面生成候选数据记录分割方案.我们利用文献[8]中的方法产生候选分割方案:

图2 候选分割方案
3.4 最佳分割方案
为了获得正确的数据记录分割方案,我们依赖列表页面所具有的特征,即每条记录的树结构相似.这样我就可以选择具有最高相似度的候选分割方案作为最终结果,我们为每一条记录添加一个根节点,构造成树结构.然后根据STM算法来计算每条记录之间的相似性.计算公式如下面的公式(3):

根据公式3对图2获得的候选分割方案分别计算其相似性,可以看出,以C0开始的分割方案的相似性最高,这样就选择列表当中的第一种方案作为最佳分割方案.
4 实验分析
4.1 评价标准
本文采用标准指标查全率(Recall)和准确率(Precision)来评价我们的系统的好坏.
4.2 实验
为了检验本为提出的方法的效果,选用了不同类型的200个网页作为实验对象,挖掘网页中的相似记录项.同时将我们的实验结果与MDR算法进行比较,实验的数据如表1所示.
从表1可以看出,对于淘宝和亚马逊等站点,基于本文方法抽取相似记录项,都取得了100%的召回率和100%准确率.经查看网页结构发现网页结构化程度非常高.易趣和CNKI等站点的召回率和准确率相对较低,经查看网页结构,发现这些站点的结构化程度相对较低.从总体上看,实验取得了98.82%的召回率和99.52%的准确率,说明本文方法,对于各种类型的列表网页的信息抽取,取得了很好的效果.本文方法同MDR方法结果进行比较,在准确率和召回率方面都有提高,证明本文方法的有效性.

表1 实验结果
5 总结
本文提出了将最大扇出子树法、最大内容增大法和最大标记量法三种启发式方法结合的思路查找网页的主数据区域.在数据记录分割阶段,采用基于树编辑距离的聚类算法来减少候选分割方案,最后通过给出的公式挑选出最佳分割方案,完成数据记录的抽取.实验证明对各种类型列表页面进行数据记录抽取的效果都很不错.但是本文方法只适用于一个主数据区域的页面,以后将进一步研究多信息块的数据记录抽取.
〔1〕A.H.F.Laender,B.A.Ribeiro-Neto,A.Soares da Silva,J.S.Teixeira,A brief survey of web data extraction tools,ACM SIGMOD Record 31(2)(2002)84–93.
〔2〕V.Crescenzi,G.Mecca,P.Merialdo,ROADRUNNER:towards automatic data extraction from large web sites,in:Proceedings of the 2001 International VLDB Conference,(2001):109–118.
〔3〕B.Liu,Grossman,R.and Y.Zhai,Mining data records in Web pages.KDD,(2003):601-606.
〔4〕Y.Zhai,B.Liu,Structured data extraction from the web based on partial tree alignment,IEEE Transactions on Knowledge and Data Engineering 18 (12)(2006)1614–1628.
〔5〕A.Arasu,H.Garcia-Molina,Extracting structured data from web pages,in:Proceedings of the ACM SIGMOD International Conference on Management of Data,(2003).
〔6〕C.Chang,S.Lui,IEPAD:information extraction based on pattern discovery,in:Proceedings of 2001 InternationalWorldWide Web Conference,(2001):681–688.
〔7〕B.Liu,Y.Zhai,NET:System for extracting Web data from flat and nested data records.In Proceedings of the Conference on Web Information Systems Engineering,(2005):487-495.
〔8〕Manuel A′lvarez,Alberto Pan,Juan Raposo,Fernando Bellas,Fidel Cacheda,Extracting lists of data records from semi-structured web pages,Data&Knowledge Engineering(64),(2008):491-509.
猜你喜欢
小学阅读指南·高年级版(2024年4期)2024-04-28 16:10:16
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:44
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
计算机与数字工程(2019年12期)2019-12-27 06:31:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2018年10期)2018-08-04 03:24:38
计算机应用(2017年9期)2017-11-15 06:02:32
电子制作(2017年2期)2017-05-17 03:54:56
