
一种动态时间阈值的会话识别算法
2012-12-07 01:10张晓伟
山东电力高等专科学校学报 2012年4期
张晓伟
泰山职业技术学院 山东 泰安 271000
0 引言
在计算机网络技术不断更新过程中,网络终端用户在寻找所需信息时,会搜索出大量不相关的信息,准确找到所需信息需要进一步筛选和确认,这是因为目前各网站的结构复杂化,网站中包含的内容信息量快速增加。帮助用户快速找到所需的信息资源,是网站设计时所要考虑的重要环节,即在技术上实现搜索资源的快速定位。搜索信息涉及到网络日志的数据挖掘。数据量大、不规范、不完整是网络日志数据的特点,在对网络日志数据进行数据挖掘之前,要对数据进行预处理。通过对网络日志数据的预处理可提高网络日志的规范度。
对网络日志进行预处理主要是指:网络日志的数据净化,网络用户的识别,用户会话的识别及补充路径、识别事务等。会话识别是网络日志数据预处理的重要步骤之一,会话识别的准确程度对后续其它数据的分析起到重要的作用。设计一种什么样的会话识别算法,关系到会话识别的质量。有采用将会话切分成事务最大向前引用的方法 (Park提出);有采用立方结构模式进行数据挖掘的方法(Srivastava提出);有采用基于时间启发式的方法(Spiliopoulou提出);有庄力可博士等人提出的基于时间间隔的会话切分方法。其特点都是采用单一固定的时间阈值,而没有考虑用户个体之间存在的差异,可能会导致会话记录不能准确的划分,影响到会话识别的总体质量。
在网络日志数据预处理中的会话识别算法中,本文提出一种新的算法。新算法中核心是依据网页的内容、网站点的结构,对页面的链入和链出数目一并考虑,有针对性对二者进行权重的综合处理。在会话识别中首先获得一个用户页面访问的时间阈值,利用时间阈值进行用户会话的切分,在切分得到的会话集合中进行筛选,会话中存在链接不感兴趣的页面进行删除,进一步形成有效的页面序列集合。
1 网络日志数据的预处理
对日志数据进行预处理是数据挖掘之前必须进行的一个过程,网络日志就是访问服务器时存储在其上的一组、一组的数据,形成的数据不是结构化的,而是半结构化的数据形式,还不能对这样的数据直接进行挖掘,需要进行预处理。前面提到网络日志数据的预处理主要是指对日志数据的清理、净化过虑、优化组合的过程,删除对数据挖掘过程中冗余的数据。网络日志数据的预处理包括日志的数据净化、网络用户的识别、用户会话的识别、路径的补充及事务识别等阶段。
进行网络日志的挖掘网关键就是首先对网络日志数据的进行预处理,没有设计一个良好的日志预处理算法,就谈不上后续的数据挖掘的质量、效率及准确性,日志数据预处理的重要步骤之一就是会话识别。传统会话识别算法用固定时间阈值的方式来进行预处理,忽略了用户多样、个性的特点,对大于时间阈值的同一个会话页面将分到下一个会话中,产生错分的现象,从而导致网络日志预处理的效率低。
2 传统会话识别算法
设定一个网络终端用户(User)通过浏览器访问,在服务器存储器中形成用户会话(Session),设定用户开始访问网站记录到离开网站进行的所有活动为用户会话,这是由用户访问形成的所有链接的集合。对这些集合数据或者说访问日志记录划分为单一的会话过程就是会话识别。一次会话认为就是用户的一次网页浏览过程,浏览过程就形成了一系列带访问时间次序的页面集合。
定义US(user session)为一个用户会话,US由用户标识、访问页面两个元素构成,即US<userID,RS>,其中userID为用户标识,RS为该时间段用户请求访问的Web页面集合。RS包含所请求页面的标识符Pid、请求的时间Time,则用户会话(US)可以表示为:
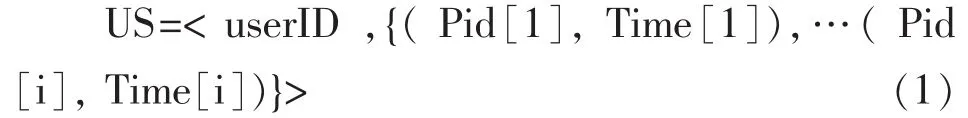
先通过用户识别后,得到用户访问的Web页面序列集合,再设定时间阈值,进一步识别得到用户会话,设定时间阈值(T)为整个用户会话的时间,上式(1)中的会话一定满足下列条件:

传统会话识别算法步聚:
(1)设定时间上界Tvisit。用户在两个相邻页面间的请求时间与时间上界(Tvisit)相比,如果超过整个时间上界(Tvisit),开始一个新的用户会话。设t0表示会话初始页的时间戳,t表示用户请求时间,如果t-t0≤Tvisit,则加入当前会话。
紧急切断阀应具有自动和手动关闭功能,手动关闭功能包括控制室遥控关闭和现场手动关闭[9]。当液位高高或低低报警时通过SIS完成联锁紧急切断功能,及时切断储罐进出口管道上的进出口阀门,避免溢油冒罐或抽瘪储罐的情况发生;同时,在操作站设置紧急切断阀的远程控制开关,或在SIS辅操台上设置紧急关阀按钮,便于操作人员在发生火灾或安全联锁失效等突发状况时能够远程手动切断阀门;另外,安装于火灾危险区域外的现场操作开关可以使现场人员在第一时间发现异常后及时切断阀门,防止事故升级。
(2)若用户是通过历史和参引页上的链接请求进入,应认为是同一会话。
(3)用户两个连续请求的时间间隔为△t,若△t超过在一个页面停留时间阈值T,则认为开始一次新会话,否则,就认为是同一个会话,一般情况下设时间阈值为10分钟。
(4)最大向前参引模型。最大向前参引是指用户在浏览网页过程中,按下返回按钮将浏览前一个网页,即一个会话结束,新一个会话开始。
实际登录网络过程中,由于每一个用户的自身的各方面差异,如形成的习惯、个人的兴趣度、操作的熟练程度及网络速度的不同,导致不同用户的会话时间不同。但是传统的用户识别算法采用预先设定方法,会话时间间隔阈值相同,没有考虑不同用户间差异,产生了超过时间阈值的会话会分到下一个会话中,降低了用户访问效率。
3 优化用户会话识别算法
3.1 优化总体设计思路
考虑到用户访问网络时会话识别的时间与网页内容及网站结构有关,提出一种改进的会话识别算法,总体思路:综合分析网页的内容、网站设计结构、网页对用户的重要程度,同时加入页面链入、链出数因素,形成不同的用户访问Web页面的不同时间阈值,根据得到的不同时间阈值进行会话的划分,对划分后得到的会话集合进行删除候选,删除哪些用户对页面内容不感兴趣的链接页面,形成最终页面序列集合,从而提高会话识别的质量和效率。
3.2 会话时间阈值的改进
前面提到的传统会话识别算法采用时间阈值预先设定的方式,本文按照优化的总体策略对页面进行重新时间阈值的设置,然后再进行会话的识别。考虑加入页面链入、链出数来衡量页面重要程度的因素,设定Li为链入数,表示链接到该页面的页面个数;设Lo为链出数,表示页面所包含的链接页面的个数;设PS表示该页面内容大小,则页面链入数、链出数与PS之比反映出时间阈值的动态变化,用Riop表示。

考虑一个页面的链入和链出的程度一般情况下不会相同,应加入两者的权重系数,可以认为链入相对链出重要。链入权重设定在0.6~0.8之间,链出权重设定在0.4~0.2之间,如果采用黄金点分割(0.618Li,0.382Lo)更具有可操作性。
由于Riop反映了时间阈值的动态变化,利用它生成一个时间阈值因子β。
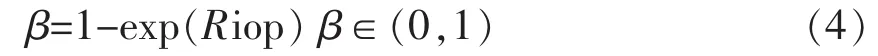
假设访问网页时的网页下载时间为Td,浏览阅读时间为Tr,时间阈值T为:

考虑到用户的个体差异及终端设备等情况,对于链接速度较慢的终端用户,允许用户在没有完全下载完成前就可以阅读网页相关信息,如果再把下载时间Td作为用户开始阅读的时间时,就会使会话的识别产生误差,为此,加入一平滑系数α对下载时间Td进行处理,时间阈值修订为:
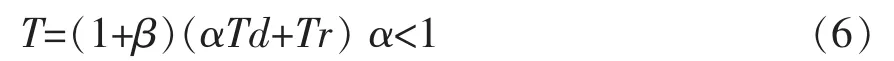
3.3 删除兴趣度低的Web页面
对一个页面浏览时间相对其它页面时间长,浏览次数多,浏览的浏览兴趣度就高,浏览兴趣度是与浏览时间、浏用户览次数等参数有关。设P表示用户的浏览兴趣度,用户从Web页面i进入j页面的浏览时间用Timeij表示,浏览次数用Countij表示,用户在页面j上的浏览兴趣度表示为Pj:
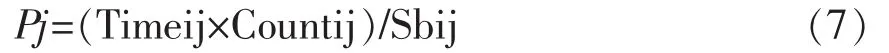
其中,Sbij表示从页面i进入到页面j接收到的字节数。
一个用户在某个Web页面上浏览时间长,说明示用户对该网页内容感兴趣;另外,应考虑到浏览时间还与不同用户的浏览速度有关,在网络日志中,浏览速度用Web页面的接收字节数来表示。上面(7)式中的Pj可以客观反映用户对某一页面的关注程度,因此可以删除不能引起用户兴趣的Web页面。
3.4 优化会话识别算法的步骤
优化会话识别算法的步骤如下:
首先对网络日志数据进行筛选。对用户访问网页形成的网络日志初始数据进行筛选、缩减。
对数据清洗后的日志数据进行用户识别。
根据不同的用户对日志中的数据进行分析处理,确定用户访问网页时的下载时间Td和在线阅读时间Tr。
计算时间阈值因子β,再通过公式(6)计算每个页面访问时间阈值T。
依据时间阈值T进行网络日志的划分,得到用户上网的会话集合。
最后计算用户的页面兴趣度P,对用户兴趣度不高的链接页面进行删除。
4 结束语
随着计算机网络广泛应用的普及和网络技术的更新发展,在网络海量信息中快速准确查询到有用的信息需要技术的不断更新,进行网络日志数据挖掘技术的研究旨在解决这方面的问题。本文是在传统的网络日志挖掘预处理基础上进行了算法的优化,提出改进网络日志数据中会话识别的预处理算法,提高了下一步进行数据挖掘的效率。
[1]杨富华.网络日志预处理中优化的会话识别算法[J].计算机仿真,2011,28(4):123-125.
[2]于飞,丁华福,姜伦.Web日志挖掘中数据预处理技术的研究[J.]计算机技术与发展,2010,20(5):47-50.
[3]李瑞,朱鹤祥.Web日志挖掘预处理中会话识别算法的优化[J].电脑知识与技术,2009,5(11):8616-8618.
[4]方元康,胡学刚,夏启寿.一种改进的Web日志会话识别方法[J].计算机技术与发展,2008,18(11):214-216.
猜你喜欢
保健医苑(2022年1期)2022-08-30
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
小学生(看图说画)(2017年6期)2017-11-06
海外华文教育(2016年3期)2017-01-20
电子设计工程(2014年19期)2014-02-27
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
海外华文教育(2014年4期)2014-01-20
网络安全技术与应用(2011年3期)2011-03-14
河北软件职业技术学院学报(2010年3期)2010-06-06
