
基于信号子空间的语音增强方法
2012-11-05 06:43曹玉萍
电子测试 2012年6期
曹玉萍
(兰州交通大学电子与信息工程学院,兰州 730070)
0 引言
在现实中,语音信号都是含有噪声的,这阻碍了语音的可懂性,甚至有时严重影响了信号的质量,因此解决噪声污染就非常有必要。语音增强是解决噪声污染的一种有效方法,它的思想是从带噪语音信号中提取尽可能纯净的原始语音。
就目前来说,语音增强的方法可分成两大类:时域方法,如子空间法等;频域方法,如谱减法和维纳滤波法等。这两种方法各有优缺点。子空间的方法提供了一种在语音信号失真和残留噪声之间进行控制的机制,但是计算量较大,但频域方法的计算量较小,但是在信号失真和残留噪声的控制上还没有一个理论机制[1-2]。
在文献[3]中, 作者构建了一个在时域里进行语音增强的新途径——子空间的框架理论。 然而,最初的工作只是对白噪声而言的, 对于有色噪声,作者建议采用附加的预处理,使有色噪声白化。在文献[4]中,作者虽然将这种方法扩展到有色噪声的处理中,但采用了各种假定,因此不是最优的方法。
本文研究的是在白噪声和粉红色噪声下,利用对语音信号和噪声协方差矩阵同时对角变换的条件下的一种语音增强算法。粉红噪音是自然界最常见的噪音,它的频率分量功率主要分布在中低频段,从波形角度看,粉红噪音是分形的,在一定的范围内与音频数据具有相同或类似的能量;从功率或能量的角度来看,粉红噪音的能量从低频向高频不断衰减。利用粉红噪音可以模拟出比如瀑布或者下雨的声音。
1 基于子空间法的粉红色噪声语音增强算法
基于信号子空间方法的基本思想是将带噪语音信号投影到两个子空间中,一个是语音信号子空间,另一个是噪声子空间。通过去除掉噪声子空间,由语音信号子空间可以重构语音信号。将空间分解为两个子空间的方法,可以采用奇异值分解方法,或是特征值分解方法[5]。
1.1 白色噪声环境下的方法
在线性信号模型中,假定纯净的语音信号S为:

其中,RΨ为矢量Ψ的协方差矩阵,Rs的秩为N。
在以上的信号模型中,假定噪声为加性的,且与语音信号相互独立,因此,带噪语音信号可表示为:

其中,εs和εd分别表示语音信号的失真和残留噪声。相应的能量分别为:
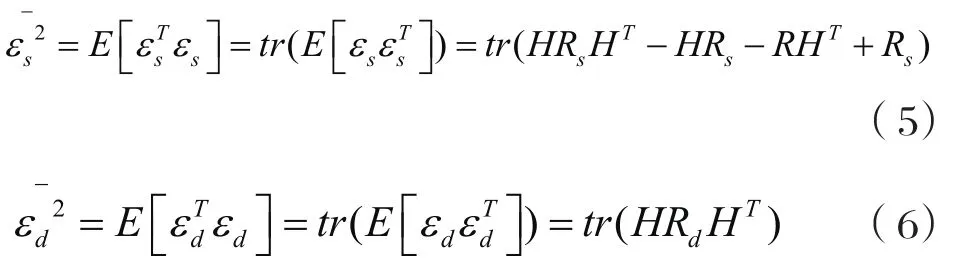
因此,求解下面时域约束条件的方程,就可以得到优化的线性估计器。
在式(7)条件下:

1.2 有色噪声环境下的方法
该方法以频域约束估计器(SDC)为基础,要求在把噪声约束在一门限值下的同时,尽量减少语音信号的失真[7],其核心思想是将信号帧分为语音帧和噪声帧两类。若为语音帧,就采用的特征向量作为信号空间的基向量求解 SDC 估计器;否则,采用的特征向量作为信号空间的基向量求解 SDC 估计器[8]。
算法流程如下:
步骤1:对带噪语音帧采用下式进行分类
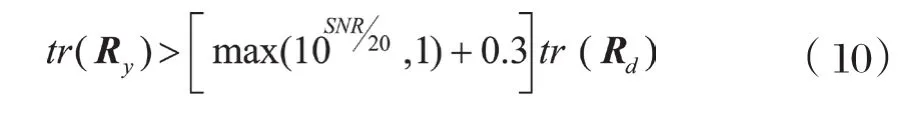
其中,SNR为帧内信噪比,Ry为带噪语音信号的协方差矩阵,Rd为噪声的协方差矩阵。若式(10)成立,则判定为语音帧,否则为噪声帧。
步骤2:若为语音帧,则可以将问题转化为求解约束方程

步骤3:若为噪声帧,则可以将问题转化为求解约束方程

2 粉红噪声环境下的实验仿真
实验所采用的信号均是采样率为8kHz,采样大小16位的PCM量化的单声道音频信号。语音增强算法仿真图中的横坐标为时间(单位:s),纵坐标为幅度。仿真实验是在MATLAB R2007a软件中进行的。
当带噪语音信噪比为-13.597 6 dB时,仿真结果如图1所示。
对带有粉红噪声的语音信号用本文方法进行处理,得到如下的结果:原始语音信号的信噪比为-13.597 6,经过处理后的语音信号的信噪比为-9.658 9,由此可以看出, 带有粉红噪声的语音信号,经过处理后,在信噪比上得到明显的提高。

图1 SNR=-13.597 6 dB的粉红噪声环境下的语音增强算法仿真图
3 结论
根据以上的讨论和分析,给出了一种对混有粉红噪声的信号子空间的语音增强方法,实际上它对加性白噪声也适用。该方法的核心思想就是将带噪语音信号映射到信号子空间和噪声子空间中,并在信号子空间中估计原始信号。它与传统的语音增强算法相比较,语音失真较小,增强效果较好,能够在极大限度地抑制背景噪声的同时减少频谱失真和残余噪声。
由于该方法在运用于语音信号处理中还是一个较新的研究途径,尽管能取得较好的效果,但在含音乐噪声的语音信号的增强效果并不理想,因此这将有待于今后进一步的讨论研究。
[1] M Dendrinos,S Bakamidis,G Garayannis.Speech enhancement from noise:A regenerative approach[J].Speech Communication,1991,10(2):45-57.
[2] Jensen S H,Hansenn P C,Hansen S D,Sorensen J A.Reduction of broad-band noise in speech by truncated QSVD [J].IEEE Trans on Speech Audio Processing,1995,3(6):439-448.
[3] Yariv Ephraim,Harry L Van Trees.A Signal Subspace Approach for Speech Enhancement[J].IEEE Transactions on Speech and Audio Processing,1995,3(4):251-266.
[4] Y Ephraim,D Malah.Speech enhancement using a minimum mean-square error shorttime spectral amplitude estimator[J].IEEE Trans Acoust Speech Signal Processi ng,1984,32(4):1109-1121.
[5] 崔秀美.基于子空间语音增强方法的研究[J].数理医药学,2008,21(3):265-267.
[6] Mittal U,Phamdo N.Signal/noise KLT approach for enhancing speech degraded by colored noise [J].IEEE Trans on Speech and Audio Processing,2000,8(3):159-167.
[7] M.Hawkes,A.Nehorai,P.Stoica.Performance breakdown of subspace-based method: Prediction and cure[J]. Proc. IEEE Int.on Acousts,Speech,Signal Processing,2001,6: 4005-4008.
[8] 牛铜.基于子空间的语音增强算法研究[D].郑州:解放军信息工程大学,2009:7-15.
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
小学科学(学生版)(2020年10期)2020-10-28
疯狂英语·新悦读(2019年10期)2019-12-13
北京航空航天大学学报(2019年9期)2019-10-26
雷达学报(2017年3期)2018-01-19
雷达学报(2017年3期)2018-01-19
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
考试周刊(2016年54期)2016-07-18
