
最大生成树算法和决策式算法相结合的中文依存关系解析
2012-06-29 05:53周惠巍黄德根杨元生
中文信息学报 2012年3期
周惠巍,黄德根,高 洁,杨元生
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引言
依存关系解析是句法分析的一个重要方法,是自然语言处理的一个重要任务,近年来引起了人们的广泛兴趣。依存关系可以明确地表明中心词之间的句法依存关系,并能方便地转化为语义依存描述。英文依存关系解析[1-2]与日语依存关系解析[3]已经取得了较好的研究成果。中文与英文等其他语言有着明显区别,中文没有严格意义上的形态变化,不同词类之间的界限不十分明显,这使得中文依存关系解析变得更为困难。
大规模语料库的构建,使得人们可以使用数据驱动的方法构建依存关系解析器。数据驱动依存关系解析方法可以分为两类:最大生成树解析方法和决策式解析方法。最大生成树解析方法将句子中的词看作图的顶点,将词间依存关系连线看作图的有向边。机器学习获得依存关系概率(有向边权重)函数,基于概率函数计算有向边的权重。从而将依存关系解析问题转换为在完全有向图中搜索最大生成树(MST)问题。Eisner将最大生成树应用于英语等非交叉结构语言的依存关系解析(O(n3))[4],McDonald使用Chu-Liu-Edmonds最大生成树解析算法[5]解析捷克语等交叉结构语言的依存关系(O(n2))[6]。辛霄将MST算法应用于中文依存关系解析,取得了很好的解析效果[7]。刘挺基于词汇支配度构建了汉语依存分析模型,找出一棵概率最大的依存树[8]。决策式解析方法有效地利用了句子的中间解析结果特征,从一个解析状态转移至下一个解析状态。解析采用贪婪算法,每一步转移都寻求局部最优转移状态,直至解析结束。代表性的决策式解析方法有面向英语的Nivre算法[1]、Yamada算法[2],面向日语的组块逐步应用算法[3]。Cheng将Nivre算法[1]和Yamada算法[2]应用于中文依存关系解析,基于最大熵和支持向量机(SVMs)进行确定性依存关系解析[9]。并使用全局特征和根节点解析器提高解析性能[10]。Xu基于SVMs构建了中文短语依存关系解析器[11]。段湘煜提出了两种模型对句法分析动作进行建模避免了原决策式依存分析方法的贪婪性[12]。Cheng的研究表明,基于SVMs的Nivre算法[1]更符合中文的语法特点[9]。
最大生成树解析方法和决策式解析方法差别很大,本质上是对立和互补的。最大生成树解析方法采用全句的依存树进行训练,解析时使用最大生成树搜索整句的最优依存树,因此具有全局性和完备性。但是,因为不到最大生成树搜索完毕,无法获得任何中间解析结果,所以无法将解析的中间结果应用于后续解析。而决策式解析方法基于状态转移过程进行训练,解析时搜索局部最优转移状态,直至整句解析结束,因此具有局部性和贪婪性。但是,可以将句子解析的中间结果用于后续解析。两种模型均被广泛用于各种语言,取得了较高的依存关系正确率。Nivre和McDonald基于其互补关系[13]提出在训练时结合两种模型的方法,将一种模型的解析结果作为指导特征引入另一种模型[14]。当两种模型的解析正确率相差不大时,结合后的模型显著地提高了原基本模型的依存关系正确率。
本文提出解析时结合两种模型的方法。基于Nivre模型的解析结果和依存度(依存关系概率),修正MST模型有向边的权重,再基于Chu-Liu-Edmonds最大生成树解析算法[6]搜索得到该句的依存树。既有效地利用了Nivre解析模型的中间解析结果特征,又使用了具有全局性的最大生成树搜索算法,避免了因为决策式解析算法贪婪性而引起的解析错误。
2 最大生成树解析算法和决策式解析算法
最大生成树解析算法将一个句子Sen={w1,w2,…,wn}的依存关系树表示为一个有向图T=(V,A)。其中V={0, 1,2,…,n}表示顶点集合(用词在句子中的序号表示该词),0为虚拟根节点;A⊆[0:n]×[1:n]表示依存关系连线。若依存树中有一条由顶点i指向顶点j的有向连线,则一对顶点i,j∈V间就有一条有向边(i,j)∈A,j≠0。
最大生成树解析算法基于训练语料通过机器学习方法获得有向边权重的定义函数score(i,j,y),即j依存于i的概率。其中y为依存关系类型,本文只解析是否存在依存关系,此处y=1。一棵依存关系树的权重即为这棵树中有向边权重的总和。这样,依存关系解析问题转变为在完全有向图G=(V,E)中搜索最大生成树问题:
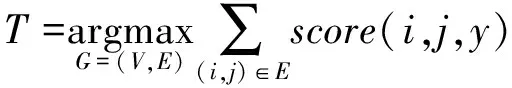
(1)
其中E⊆[0∶n]×[1∶n]表示顶点间的全部有向连线,依存关系连线集合A为E的子集A⊆E。考虑解析效率,本文基于Chu-Liu-Edmonds算法(O(n2))搜索最大生成树。
将支持向量机(SVMs)用于计算MST解析模型中有向图各边依存概率。sigmoid函数可以将SVMs输出的距离函数较好地近似为概率函数[15]。本文基于Chu-Liu-Edmonds算法搜索最大生成树。解析两个词(i,j)依存关系的具体特征见表1。

表1 MST算法的特征向量
在Nivre算法中,解析器可以表示成一个三元组
(1) Right。在当前三元组
(2) Left。在当前三元组
如果n与t不存在依存关系,改进的Nivre算法对Reduce操作和Shift操作做了明确的定义。
(3) Reduce。假如两栈顶元素n与t不存在依存关系,t有父亲节点在其左侧,并且该父亲节点与n存在依存关系,解析器从栈S中弹出t,于是三元组变为
(4) Shift。当Right,Left,Reduce操作条件都不满足时,将n压入栈S中,三元组变为
基于SVMs构建Nivre依存关系解析器。解析当前三元组的两个栈顶元素(t,n)的依存关系时,选取表2所示特征。

表2 Nivre算法的特征向量
3 最大生成树算法和决策式算法的结合
多分类器融合系统近年来受到越来越多的关注,并成为模式识别和自然语言处理等领域的研究热点。将多个分类器的决策结果按一定规则融合在一起,可以得到比其中最优分类器还要好的性能。按照分类器的输出结果形式,可以将多分类器融合方法分为三个层次:抽象层(Abstract Level)、排序层(Rank Level)和度量层(Measurement Level)[16]。抽象层也称为符号层或决策层,每个分类器仅输出该分类器所判断输出的类别标识;排序层,每个分类器按照待分类项属于各类别的可能性大小输出所有类别标识的排序;度量层,每个分类器的输出是一个待分类项属于各类别可能性的度量值。
MST解析模型和Nivre解析模型均为数据驱动模型,因此Nivre和McDonald提出一种在学习时进行结合的方法[14]。将其中一个模型的解析结果作为指导特征引入另一个模型,以此促进两个模型的相互学习。Nivre和McDonald将一个模型称为基本模型B,另一个称为指导模型C。基于指导模型C解析语料,然后将获得的解析结果作为特征加入到基本模型B的训练中,学习获得结合解析模型BC。这种结合方法仅利用了指导模型抽象层信息,简单而且显著提高了依存关系正确率。
提出在解析时融合最大生成树算法和决策式算法的中文依存关系解析方法,利用一种模型(指导模型)的解析结果指导另一种模型(基本模型),促进两个模型的相互融合。结合时分别基于指导模型解析结果的抽象层信息和度量层信息,辅助基本模型进行中文依存关系解析。
3.1 基于指导模型抽象层信息的结合
基于指导模型抽象层信息的结合,以一种模型为基本模型,利用指导模型的解析结果修正基本模型的解析结果。
McDonald和Nivre基于13种语言的实验表明,MST模型的解析正确率普遍高于Nivre模型,MST模型具有全局性[14]。我们以MST模型为基本模型,利用Nivre模型的解析结果修正MST模型完全有向图的权重,再基于Chu-Liu-Edmonds算法搜索依存树。基于Nivre模型的解析结果指导MST模型的结合方法仅利用了Nivre模型决策层的信息。每种算法均输出1-best结果。
基于MST算法获得MST依存关系树;基于Nivre算法获得Nivre依存关系树。依据两棵依存树修正MST模型完全有向图的权重score(i,j,y)∈R:
(1) 对于MST依存树和Nivre依存树中同时存在的边,将MST模型完全有向图的权重乘以一个权值a,获得新的权重a·score(iMN,jMN,y)∈R。
(2) 对于在MST依存树中存在、而在Nivre依存树中不存在的边,将MST模型完全有向图的权重乘以一个权值b1,获得新的权重b1·score(iM,jM,y)∈R。
(3) 对于在Nivre依存树中存在、而在MST依存树中不存在的边,将MST模型完全有向图的权重乘以一个权值b2,获得新的权重b2·score(iN,jN,y)∈R。

3.2 基于指导模型度量层信息的结合
基于指导模型度量层信息的结合,以MST模型为基本模型,利用Nivre依存树各边的依存度修正基本模型的解析结果。
SVMs为二值分类器,而Nivre算法包含四个操作,为多值分类问题。可以采用pairwise法将二值分类器扩展为多值分类器。首先利用SVMs对(t,i)进行分类,将其分为Right、Left和不存在依存关系三类。再利用规则将不存在依存关系的情况分为Reduce操作和Shift操作。采用pairwise法需要构建三个二值分类器,分别为{Left,Right}、{Right,不存在依存}和{Left,不存在依存}。最后,输出获票最多的类别。
当(t,i)存在依存关系,即解析结果为right和left操作时,本文选用分类器{Left,Right}输出的距离,计算Nivre依存树各边的依存概率。同样利用sigmoid函数将SVMs模型输出的距离近似为依存关系概率值。
基于MST算法获得MST依存关系树;基于Nivre算法获得Nivre依存关系树。依据两棵依存树及Nivre 依存树各边的依存度pMN修正MST模型完全有向图的权重score(i,j,y)∈R:
(1) 对于在MST依存树中存在、而在Nivre依存树中不存在的边,将MST模型完全有向图的权重乘以一个权值b,获得新的权重b·score(iM,jM,y)∈R。
(2) 对于MST依存树和Nivre依存树中同时存在的边,计算其在Nivre模型中的依存概率,并乘以一个权值a,添加到MST模型的完全有向图中,获得新的权重a·pMN+b·score(iMN,jMN,y)∈R。

4 实验
4.1 实验结果与评估
实验采用宾州中文树库(Penn Chinese Treebank, CTB)5.0。由于该树库为短语结构,没有依存关系,我们首先基于中心子节点过滤表将短语结构的宾州中文树库转换为依存结构树库。我们采用1~4 500句的语料做十折交叉验证,语料包含118 703词。因为很难制定逗号两侧的短语的依存规则,我们同Cheng一样,将逗号和句号都作为句子的结束标记[10]。
表3显示了四种模型的解析结果。实验结果表明:在CTB语料库上,MST模型的依存关系正确率远远高于改进的Nivre模型(2.5%)。结合模型NivreMST的依存关系正确率较基本模型(Nivre模型)提高了1.72%;而结合模型MSTNivre的依存关系正确率却低于基本模型(MST模型)。由此可见,当指导模型的依存关系解析性能远远低于基本模型时,对基本模型没有正确的指导作用。
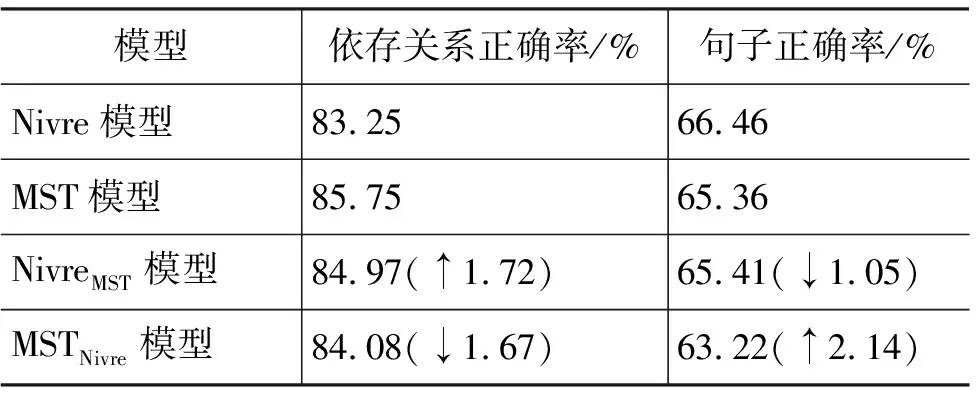
表3 依存关系解析结果
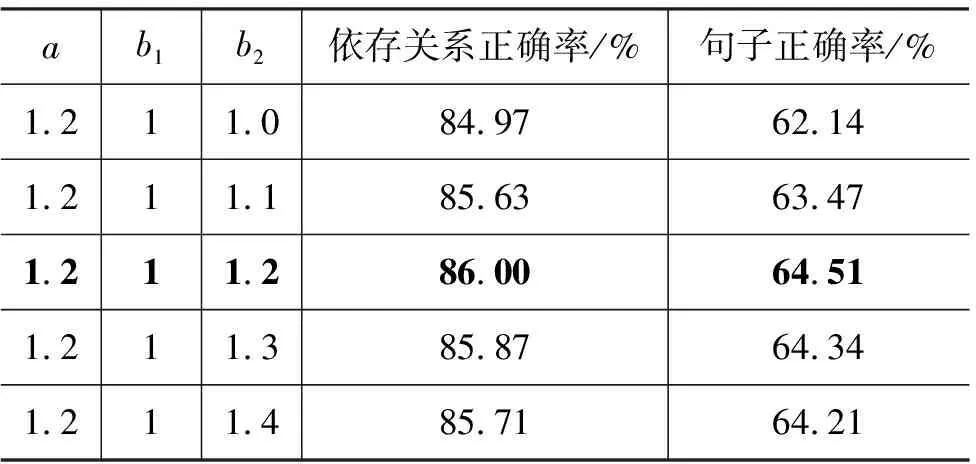
表4 解析时基于指导模型抽象层信息结合的解析结果(a=1.2)
采用本文提出的解析时基于指导模型抽象层信息的结合方法,设权值a=1.2,调节权值b1、b2的比例关系,解析结果如表4所示。
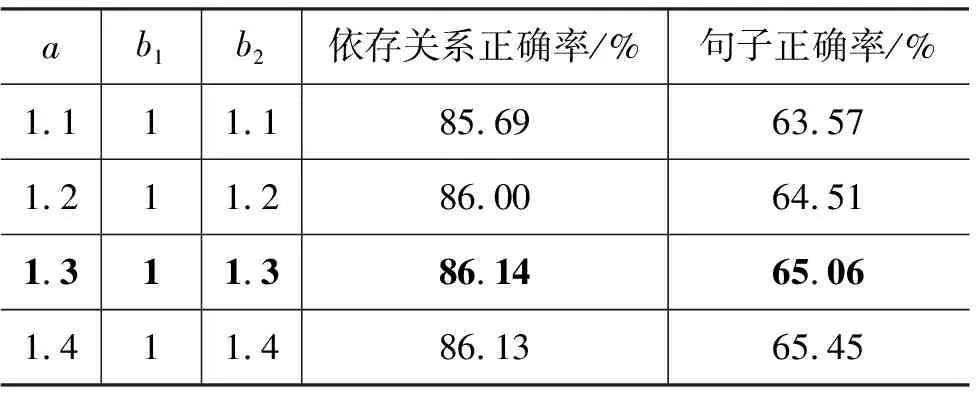
表5 改变Nivre模型影响权值的解析结果
由表4的实验数据可见,我们提出的解析时基于指导模型抽象层信息的结合方法好于文献[14]学习时结合的解析效果。解析时结合的方法比学习时结合的方法获得了更加稳定的解析性能。同时发现,当b1和b2的比值为1∶1.2时,即a与b2的权值相同时,解析效果最好。可见,Nivre模型解析获得的依存关系,无论其在MST模型解析结果中是否存在,影响权值一致时解析效果最好。
改变Nivre模型的影响权值,实验结果如表5所示。通过实验结果发现,当Nivre模型的影响权值为1.3时,结合模型的解析效果最好。
采用本文提出的基于指导模型度量层信息的结合方法,设权值b=1,调节权值a、b的比例关系,解析结果如表6所示。由解析结果可以看出,解析时有效利用指导模型度量层信息可以取得比仅利用指导模型抽象层信息更好的解析效果。其中,当a和b的比值为0.15∶1时,解析效果最好,依存关系正确率达到86.49%。可见,利用Nivre模型度量层信息能够进一步提高结合系统的解析性能。
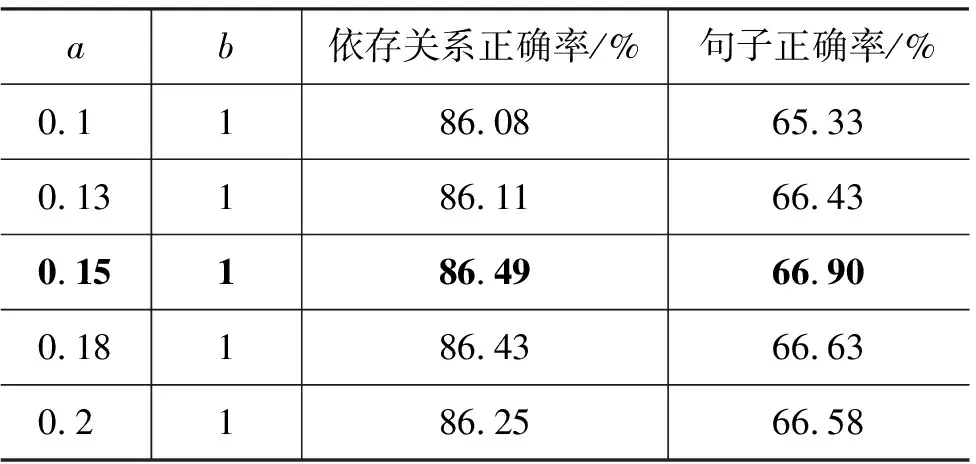
表6 解析时基于指导模型度量层信息结合的解析结果
图1显示了四种模型依存关系正确率和句子长度(句长间隔为2:1-2,3-4,等)的关系。

图1 依存关系正确率与句子长度的关系
实验结果表明:在短句子中MST模型和Nivre模型的解析性能相差不大。但是随着句子长度的增大,Nivre模型的解析性能明显低于MST模型,这主要是由于Nivre算法贪婪性解析错误逐步扩散引起的。基于Nivre模型抽象层信息的结合模型的解析性能好于Nivre模型和MST模型。基于Nivre模型度量层信息的结合模型的解析性能表现更优。这表明,随着句子长度的增大,解析时结合的方法不仅保留了MST算法的全局搜索优势,又有效地利用了Nivre算法的中间解析结果特征,使得其解析性能比MST模型有很明显的提高。而且,利用Nivre模型度量层信息的结合方法比单纯利用Nivre模型的抽象层信息取得了更好的解析性能。
4.2 与以往方法的比较
辛霄采用CoNLL 2008 共享任务语料,比较了决策式解析方法和MST解析方法。结果表明,MST算法取得了最好的解析效果,在WSJ测试语料库上的依存关系正确率达到87.42%[7]。基于CTB语料,我们再现了MST算法,解析结果如表3所示。刘挺使用哈尔滨工业大学汉语依存树库,将树库中的40 000 句作为训练集,在4 000 句的测试集上,获得了约74%的依存关系正确率[8]。Cheng采用Nivre算法,并使用全局特征和根节点解析器提高解析性能。实验采用CTB语料库,训练语料为377 408词,测试语料为63 886词。依存关系解析正确率达到86.18%,句子正确率达到61.33%[10]。Xu构建了基于短语的中文依存关系解析器,采用CTB语料库,训练语料为4 000句,任意另取100句作为测试语料,依存关系解析正确率为77.3%[11]。段湘煜基于动作建模的依存句法分析器优于原始决策式分析器。实验采用CTB语料库,训练语料为434 936词,测试语料为50 319词,依存关系解析正确率达到84.05%[12]。McDonald和Nivre采用CoNLL-X共享任务语料库,依存关系解析正确率达到88.43%[14]。我们基于CTB语料,再现了他们学习时结合的方法,解析结果见表3。
5 结论
本文利用MST算法和Nivre算法的互补关系,提出了解析时结合两种模型的中文依存关系解析方法,分别基于Nivre模型解析结果的抽象层信息和度量层信息指导MST模型。实验结果表明,基于Nivre模型抽象层信息的结合方法取得了86.14%的依存关系正确率,基于Nivre模型度量层信息的结合方法取得了86.49%的依存关系正确率。本文提出的两种结合方法,均比单独的每种算法以及学习时结合的方法具有更好的解析效果,并且基于Nivre模型度量层信息的结合方法比基于Nivre模型抽象层信息的结合方法取得了更好的解析性能。
下一步工作主要包括两个方面:一方面是探索指导模型权重的自动设置方法,一种可行的方法是采用感知机算法,基于训练语料通过迭代,自动获得指导模型的权重;另一方面是减小MST模型训练语料正负样例的比例不均衡,提高MST模型的训练效率,可以通过采用其他机器学习方法或合理删减负例的方法解决训练消耗问题。
[1] Joakim Nivre, Mario Scholz. Deterministic Dependency Parsing of English Text[C]//Proceedings of COLING'04, Geneva, Switzerland. 2004: 64-70.
[2] Hiroyasu Yamada, Yuji Matsumoto. Statistical dependency Analysis with Support Vector Machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies, Nancy, France. 2003: 195-206.
[3] Taku Kuto, Yuji Matsumoto. Japanese dependency analysis using cascaded chunking[C]//Proceeding of CoNLL, Taipei, Taiwan, 2002: 63-69.
[4] Jason M. Eisner. Three new probabilistic models for dependency parsing: An exploration[C]//Proceedings of COLING, 1996: 340-345.
[5] Y.J. Chu, T.H. Liu. On the shortest arborescence of a directed graph [J]. Science Sinica, 1965, 14: 1396-1400.
[6] Ryan McDonald, Koby Crammer, Fernando Pereira. Online large-margin training of dependency parsers[C]//Proceedings of ACL, Ann Arbor, 2005:91-98.
[7] 辛霄,范士喜,王轩,等.基于最大熵的依存句法分析[J].中文信息学报,2009,23(2):18-22.
[8] 刘挺,马金山,李生.基于词汇支配度的汉语依存分析模型[J].软件学报,2006,17(9):1876-1883.
[9] Yuchang Cheng. Machine Learning-based Dependency Analyzer for Chinese[C]//Proceedings of the International Conference on Chinese Computing, Singapore. 2005:66-73.
[10] Yuchang Cheng, Masayuki Asahara, Yuji Matsumoto. Chinese deterministic dependency analyzer: Examining effects of global features and root node finder[C]//Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, Juje, Korea, 2005:17-24.
[11] Yun Xu, Feng Zhang. Using SVM to construct a Chinese dependency parser [J]. Journal of Zhejiang University SCIENCE A, 2006, 7(2):199-203.
[12] 段湘煜,赵军,徐波.基于动作建模的中文依存句法分析[J].中文信息学报,2007,21(5):31-35.
[13] Ryan McDonald, Joakim Nivre. Characterizing the errors of data-driven dependency parsing models[C]//Proceedings of EMNLP-CoNLL, 2007:122-131.
[14] Joakim Nivre, Ryan McDonald. Integrating Graph-Based and Transition-Based Dependency Parsers[C]//Proceedings of ACL-08: HLT, Columbus, Ohio, USA, 2008:950-958
[15] John C. Platt. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods[M]. Advances in Large Margin Classifiers. MIT Press. 1999.
[16] 米爱中,郝红卫,郑雪峰,等. 一种自整定权值的多分类器融合方法[J].电子学报,2009,37(11):2604-2609.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
医学食疗与健康(2022年3期)2022-04-23
通信技术(2021年12期)2022-01-25
中华养生保健(2020年7期)2020-11-16
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
自动化学报(2017年7期)2017-04-18
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
