
一种基于HOG的快速人体检测方法
2012-03-17 07:20刘东升刘鹏鹏
电子设计工程 2012年11期
刘东升,刘鹏鹏,王 刚
(西南技术物理研究所 四川 成都 610041)
近年来,人体运动的视觉分析是计算机视觉领域备受关注的热门领域,人的运动分析主要涉及到模式识别、图像处理、人工智能等学科知识,在高级人机接口、安防监控、医疗诊断等方面具有广泛的应用前景和潜在的经济价值,而人体识别作为人体运动视觉分析的基础,得到了世界上广大科研工作者的关注和研究。
人体检测可以分为两类:传统的人体检测和基于统计学习的人体检测。传统的人体检测包括基于肤色、人体轮廓、步态等方法,由于人的多模态性,使得传统的人体检测方法准确性得不到保证;基于统计学习的人体检测不需要进行人体形状抽取,它通过从相应的图像区域提取特征,然后通过统计学习的方法对其训练和识别,基于统计学习的人体识别成为近年来研究的主流方向,目前常用于统计学习的人体特征有 HOG(Histogram of oriented Gradients,梯度方向直方图)、Harr小波特征[2]、SIFT 特征[3]等。2005 年,Navneet Dalal和 Bill Triggs提出了基于梯度方向直方图的人体检测算法[1]。该方法使梯度方向直方图特征来表达人体,提取人体的外形信息和运动信息,形成丰富的特征集,然后使用支撑向量机SVM分类器对这些特征集进行训练,取得了相当不错的效果,Dalal等人最大的贡献在于使用密集和相互重叠的特征描述方法来表达图像区域的HOG特征。这种特征描述方法计算的特征最后综合成了对于目标检测的一种鲁棒性非常高的特征向量空间,相对于传统的HOG特征极大的提高了检测器的检测效果,但是这种算法由于检测速度很慢而难以应用到实际当中。文中通过对HOG特征充分分析,提出了一种快速HOG特征提取算法,并利用线性SVM训练分类,得到一种快速的基于HOG特征的人体检测系统。我们设计的人体检测系统框图如图1。
1 HOG特征提取
笔者设计的人体检测系统框图如图1所示,而特征提取是最基本也是最重要的工作,选择梯度方向直方图特征(HOG)。HOG是将图像均匀的分成相邻的小块,然后在所有的小块内统计各方向的梯度直方图。HOG描述方法与其他特征相比具有以下的优点:HOG表示的是边缘(梯度)的结构特征,因此可以描述局部的形状信息;位置和方向空间的量化一定程度上可以抑制平移和旋转带来的影响;采取在局部区域归一化直方图,可以部分抵消光照变化带来的影响。因此HOG适合做人体识别研究。下面介绍HOG的计算过程以及文中提出的快速算法。

图1 人体检测系统框图Fig.1 Structure diagram of human detection system
1.1 梯度和方向的计算
首先计算两个方向的梯度,采用一种梯度模板计算每个位置的梯度和方向,文献[1]证明了使用最简单的一阶模板[-1,0,1]的效果最好,设 f(x,y)表示像素的值,梯度 h(x,y)和方向 θ(x,y)的计算公式如下:

1.2 块内的HOG以及快速提取
图像按空间位置分成均匀的小块,称为“cell”,在cell内按照设定好的量化间隔统计梯度直方图,应用梯度的幅值进行投影。然后相邻的 cell(2×2)组成一个大块,称为“block”。文献[1]的试验证明使用2×2的block,8×8像素的 cell以及每个cell内梯度方向分成9个方向块时效果最好,即梯度方向将0°~360°分为 9 个方向块,每个方向块大小为 20°,这样在一个block内就形成了4×9=36维的特征向量,其中相邻块之间是相互重叠的,分块时步长按照一个“cell”进行分块。
在Dalal的文章中,对于每一个缩放尺度的图像,使用检测窗口进行遍历扫描,然后计算每一个检测窗口的HOG用于分类器判断。在人体检测系统中,人体检测窗口分别是64×128,窗口大小与正例训练样本大小一致。而Block和检测窗口的遍历步长都为8个像素。对于人体检测系统,一个检测窗口需要计算((64-16)/8+1)×((128-8)/8+1)就是 7×15=105个block内的HOG特征向量,每个block特征向量为36维,一个窗口的HOG特征向量是36×105=3 780维。按照这样的方法,对于一幅320×240的图像,第一个缩放级别(原图)中,检测窗口需要遍历((240-128)/8+1)×((320-64)/8+1)即 15×33=495个检测窗口,也就是说我们需要计算105×495=51 975个block的HOG向量,其计算量非常的巨大。在此做了一个改进,把整幅图像当做一个检测窗口计算其梯度值将其存入一个二维数组,当我们遍历图像时,只需要根据索引得到梯度值进行方向上的投影就行了,这样就大大降低了运算量。把以每一个扫描位置为顶点的256×256图像区域当作一个block来计算,计算的所有block块HOG特征向量存入((240-16)/8+1)×((320-16)/8+1)=1 131 的二维数组中,数组的每一个元素都指向一个block块的36维特征向量。对图像进行检测时,以每一个遍历位置为顶点的检测窗口所包含的区域中的HOG其实都已经计算过了,只要对二维数组进行正确的索引找到对应的7×15=105个block,即可得到一个检测窗口的HOG特征向量。我们的方法总共计算了1 131次block的HOG特征。相对于原来的算法HOG特征的计算速度提高了51 975/1 131=46倍,这对整个人体检测系统的速度提升具有巨大贡献。
1.3 HOG的归一化
为了消除光照变化带来的影响,要在在block内归一化直方图,实验证明:下式的归一化效果最好:

其中V为原向量;V*为归一化后的向量;ε为一很小的常数,目的是为了防止除零。
一个检测窗口内由多个block内归一化直方图组成的结果就是特征向量,一共3 780维,最后使用统计学习的方法进行训练和判断。
2 SVM学习方法
传统的人体检测主要是基于对图像要素的分析。近年来,随着统计学习方法的完善,将统计学习应用到计算机视觉领域已经成为热门的话题并且取得了非常好的效果。得到的HOG特征是高维的特征,而支撑向量机 (Support Vector Machine,简称SVM)[6]在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,已经在模式识别、函数逼近和概率密度估计等方面取得了良好的效果。我们选用SVM方法来训练我们的人体分类器。
SVM的主要思想可以概括为两点:1)它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界;2)它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
推导可以得到SVM最优分类面函数为
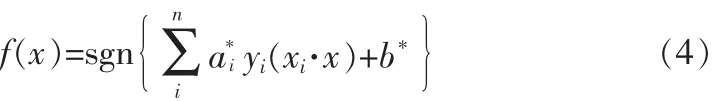
其中a*i为支撑向量的系数最优解,b*是分类的阈值,可以由任意一个支撑向量用式(5)求得:

式(4)只包含待分类样本与训练样本中的支撑向量的内积运算,只需要知道这个空间中的内积运算即可,在最优分类面中采用适当的内积核函数K(xi,yj)就可以实现某一线性变换后的线性分类,而计算复杂度却没有增加。相应的分类函数也变为:

常用的核函数有以下几种:
1)线性核函数:K(x,y)=x·y
2)多项式核函数:K(x·y)=[(x·y)+1]d
采用核函数的方法大大的提高了SVM的学习能力。在文中的人体检测系统中,使用线性SVM二值分类器,因为这种分类器在我们的训练样本集中能够取得最好的效果。这里我们使用分类间隔为0.01的线性SVM分类器,高斯核的SVM分类器虽然能够取得稍微好点的效果,但是计算量非常大,影响了检测器的检测速度。
3 实验结果
为了便于比较,使用 Dalal等人建立的INRIA直立人体数据库进行训练和测试,这个数据库采集了各种姿态、衣着、背景和遮挡下的数千张图片。选取了其中1 208张正例人体图片以及1 214张负例(含人体)图片作为训练样本,样本需要归一化为检测窗口大小64×128。本文实验的环境为Inter(R) Core2(R) Dual 2.20GHz 内存 2.00 GB。
为了与文献 [1]Dalal的算法进行效果比较,文中使用Recall-Precision曲线来描述。如图所示,Recall表示系统正确检测到的正例人体目标与实际正例目标的比值,Precision表示系统正确检测到的正例目标与所有检测到的正例目标的比值。从图2可以发现在检测效果上,改进的直立人体检测算法与Dalal等人的算法几乎差不多,因为直立快速人体检测算法的创新主要是在检测时间上,在检测效果并没有降低下,极大地降低了检测时间,检测一幅320×240大小的图片,文献[1]需要1 225ms,而文中需要 85ms,速度提高了 15倍左右,如表1所示。图3为本文检测系统在一部分图片上检测出的人体结果。
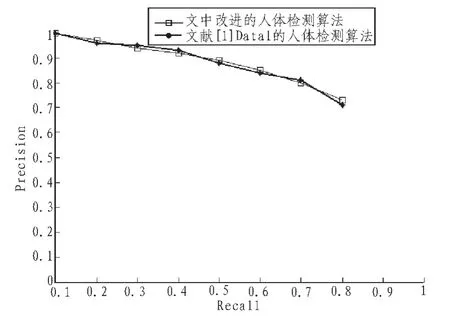
图2 测试数据集上的检测效果对比Fig.2 Detection result on the test data set

表1 320×240图片处理时间对比Tab.1 Time compared on p rocessing 320×240 picture
4 结束语

图3 人体检测结果Fig.3 Human detection result
文中提出了一种基于HOG的快速人体检测方法,实验的结果表明本文设计的人体检测系统在保障了检测率的情况下,极大地降低了检测时间,接近实时,对于视频监控,如果摄像机固定,图像里人体变化较小,那么处理时间会进一步降低,完全能达到实时。因此今后的工作我们可以将我们的方法与动目标检测和跟踪结合起来应用于监控领域。
[1]Dalal, Triggs.Histogram of oriented gradients for human detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2005:886-893.
[2]Paul V,Michael J,Daniel S.Detecting pedestrians using patternsofmotion and appearance[C]//Proceedings of the 9th IEEE International Conference on Computer Vision,2003.
[3]Lowe D G.Object recognition from local scale-invariant features[J].International Conference on Computer Vision,1999,21(2):1150-1157.
[4]Lowe D G.Distinctive image features from scale-invariant key point[J].International Journal of Computer Vision,2004,60(2):91-110.
[5]Brown M,Lowe D G.Invariant features from interest point groups[J].In British Machine Vision Conference, Cardiff,Wales,2002,21(2)656-665.
[6]Vapnik V.The nature of statistical learning theory[M].Springer Verlag,1995.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
保定学院学报(2022年2期)2022-04-07
摄影之友(影像视觉)(2018年12期)2019-01-28
许昌学院学报(2018年4期)2018-05-02
计算机应用(2017年4期)2017-06-27
中华建设(2017年1期)2017-06-07
初中生世界·八年级(2017年3期)2017-03-24
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
