
基于协同过滤技术的个性化推荐系统研究
2012-03-17 07:20史玉珍
电子设计工程 2012年11期
史玉珍,郑 浩
(平顶山学院 软件学院,河南 平顶山 467002)
在这个信息爆炸的网络时代,面对纷杂的信息资源我们感到无所适从。即便能通过搜索引擎进行信息查询;但是面对统一问题统一答案的查询结果,如何能结合个人需求获取信息是网络环境的新挑战。广大用户希望结合个人习性爱好改变传统的“人找信息”[1]的状况,打造出“信息找人”的格局,基于个性化的信息推荐系统应运而生。
1 个性化推荐系统的必要性
1.1 个性化推荐系统
个性化推荐系统[2-3]就是根据用户的兴趣爱好,推荐符合用户爱好习惯的资源。目前主要有两种类型的个性化推荐系统,一种是以网页为推荐对象的搜索系统,主要采用Web数据挖掘的方法和技术,为用户推荐符合其兴趣爱好的网页,如Google等;另一种是网上购物环境下,以商品为推荐对象的个性化推荐系统,为用户推荐符合兴趣爱好的商品。
1.2 推荐系统分类
推荐算法是整个推荐系统中最核心、最关键的部分,很大程度上决定了推荐系统性能的优劣。目前推荐算法主要包括基于关联规则的推荐、基于内容的推荐和协同过滤推荐和组合推荐算法[4]4种。
1)基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零售业中已经得到了成功的应用。它依赖专家对用户和信息的预先分类,为不同类的用户分布提供不同的服务、产品和不同的优先级,这是一种根据事先定义的If-then规则的静态推荐,具有很大的局限性。
2)基于内容的推荐源于信息检索领域的信息过滤技术,它通过计算资源(商品、电影、音乐、文本等)与资源之间、资源与用户兴趣之间的相似程度来向用户推荐资源,分析资源内容,根据用户兴趣建立用户模型,基于内容的过滤技术对文本资源的过滤效率非常高,但对多媒体资源不适合。
3)基于协同过滤的推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度来对目标用户进行推荐预测。它根据用户或项目(表示任何商品或信息资源)之间的相似性产生推荐结果,具体可分为基于用户的协同过滤和基于项目的协同过滤。基于协同过滤的推荐技术是目前研究较多的个性化推荐技术,推荐的个性化程度高、效果明显,特别适合音乐、电影、图书等领域的非结构化复杂对象的推荐。
4)组合推荐算法(Hybrid Recommendation):由于各种推荐方法都有优缺点,所以在实际中,组合推荐经常被采用。研究和应用最多的是内容推荐和协同过滤推荐的组合。
2 协同过滤技术
协同过滤的概念[5]是1992年由Goldberg等人正式提出的,应用在电子邮件过滤上,并开发出了Tapestry系统。协同过滤算法的思想就是“物以类聚、人以群分”,在日常生活中,人们总会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到推荐系统中来,基于其他用户对某一内容的评价来向目标用户进行推荐。
协同过滤技术基于如下假设[6]:与用户A兴趣度相似的用户B感兴趣的产品是用户A所感兴趣的。并根据用户对其他项目的评分以及整个用户群体的评分记录来预测该用户对某一未评分项目的评分。协同过滤系统[7-9]可以由输入、推荐预测引擎和输出3个部分组成如图1所示,即用户输入评价信息,推荐预测引擎根据用户输入的信息产生推荐预测,以及输出推荐预测结果3个步骤。一般来说推荐预测引擎对用户来说是个“黑盒”,推荐结果的生成过程对用户来说是透明的。具体实施过程如下:
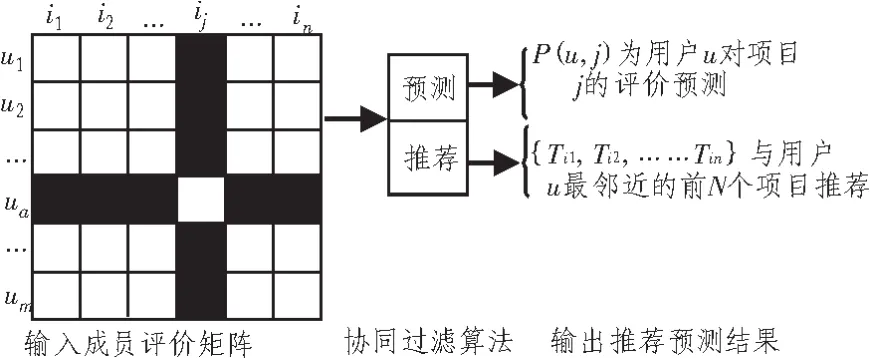
图1 典型协同过滤流程Fig.1 Typical collaborative filtering process
第一步,获得用户的评价、购买行为、用户的兴趣等数据信息[10-12],比如用户对资源对象的浏览、评价、购买等。为了给用户提供有效的推荐,必须先获得用户的兴趣模型,这是协同过滤的关键,如果兴趣模型不准确或是错误的,那过滤结果将是毫无意义的。得到一个用户兴趣模型主要分成两步,先要根据用户的活动状况来获得用户感兴趣的信息群,然后根据这些信息提炼出兴趣模型。所以要求获得推荐的用户,为得到推荐必须对一些项目进行评价,以表达自己的偏好。
第二步,分析和发现用户之间、项目之间的特征模式,比如相似性,作为协同过滤输出或预测的基础。分析用户之间、项目之间的相似性可使用相似性计算方法或统计技术来搜索用户或项目的若干最近邻居。
第三步,根据当前用户的访问过程或阶段,适时产生和输出推荐列表。推荐列表的输出主要有两种形式,一种是预测,另外一种是推荐。预测就是根据用户给定的一组或多个未评价项目,根据预测算法得到该用户对于未评价项目的预测评分值,并进行预测输出。推荐是提供活动用户一个具有N项用户最喜欢的项目列表,即根据用户的偏好推荐可能吸引用户的N个项目,按推荐程度高低排序。
3 协同过滤算法实现
3.1 构建用户_项目评分矩阵
协同过滤推荐算法使用用户对项目(商品)的评分数据作为推荐基础[13]。用户评分数据分为显式评分和隐式评分两类。显式评分是由用户自己对某个项目进行打分,使用数值来表示。隐式评分是由系统评估用户对某个项目的评分,如由用户的浏览日志,购买记录等得出。推荐系统数据的核心是使用一个用户_项目评分矩阵R(m,n),它表示有m个用户集合 U={U1, U2,…, Um}和 n 个项目的集合 I={I1,I2,…,In},其中Ru,i表示用户u对项目i的评分,若用户u未对项目i评分,则 Rui=0。

图2 用户_项目评分矩阵Fig.2 User_project scorematrix
3.2 计算用户之间的相似度
基于协同过滤技术的推荐系统的核心是为一个需要推荐的当前用户寻找其最相似的“最近邻居”集。对于用户相似性的计算,目前方法有很多,主要有3种传统计算方法:余弦相似性、修正的余弦相似性以及Pearson相似性[14]。
现将文中用到公式符号进行如下约定:
I表示全部项目空间;
U表示全部成员用户;
Iuv={c∈I|Ru,c=Ø&Rv,c=Ø}用户 u 和用户 v 共同评分过的项目集合;
Ru,c表示用户u对项目c的评分;
Rv,c表示用户v对项目c的评分;
Ru分别表示用户u对项目的平均权值;
Rv分别表示用户v对项目的平均权值;
Ruvd表示推荐系统所采用的评分制的中值。
3.2.1 余弦相似性
余弦相似性也称为向量相似性(vector similarity)。用户评分被看作是n维项目空间上的向量,如果用户对资源没有进行评分操作,则将用户对该项目的评分预设为0,用户间的相似性通过向量间的余弦夹角度量,夹角越小则相似性越高。则用户 u、v 之间的相似性 sim(u,v)为:
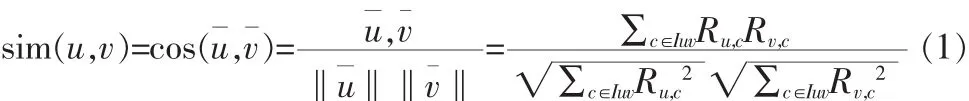
3.2.2 修正的余弦相似性
在余弦相似性度量方法中没有考虑不同用户的评分尺度问题,比如用户甲给他认为最好的项目的评分为4,而从不给5分,他给他认为最差的项目评分为1,而不给2分;用户乙给他认为最好的项目的评分为5,给他认为最差的项目评分为2,如果采用基本的余弦相似性方法,则这两个用户差异较大。修正的余弦相似性度量方法通过减去用户对项目的平均评分改善上述缺陷。则用户u和用户v之间的相似性sim(u,v)为:

3.2.3 Pearson相关系数相似性
用户u和用户v之间的相似性 sim(i,j)也可通过Pearson相关系数来度量,将Pearson相关系数公式中结合推荐系统中评分机制的中间值Ruvd代替,公式即为:

3.3 选择目标用户的最近邻居
协同过滤的核心是为一个需要推荐服务的活动用户寻找其最相似的最近邻居 (Nearest neighbor)集,即对一个活动用户a,要产生一个依相似度大小排列的“邻居”集合N={Nl,N2,…,Ni},a∉N,从 N1至 Ni,用户之间的相似度 sim(a,Ni)从大到小排列。一般有两种思路来选取邻居数目,第一种思路是预先设置一个相似性阈值,所有那些与活动用户之间的相似系数超过该阈值的用户都作为邻居。高于阈值则说明邻居与活动用户之间有较好的相似性。第二种思路是选择k个相似性最大的用户作为邻居用户,k值设置一般为20~50之间。
3.4 目标用户对指定项目预测计算
选取目标用户的近邻后,就可根据这些最近邻居对项目的评分来预测活动用户对某个项目的喜好程度。在协同过滤系统中最重要的步骤就是对目标用户的指定项目进行预测[15],假设用户u对项目i的预测为Pu,i,表示公式为:

其中KNNI(u)表示用户u的最近邻用户的个数。
4 协同过滤技术的评价
评价推荐系统用户评估出的推荐分值与待推荐用户的实际评分值之间的差异程度是评价一个推荐系统好坏的重要指标,MAE(Mean Absolute Error)是被广泛使用的测试评分预测准确度的一个标准[16]。平均绝对偏差通过计算预测的用户评分与实际的用户评分之间的偏差度量预测的准确性,MAE[17]越小推荐质量越高。设N代表用户已实际评分的项目数。pi代表用户的对某项目的实际,qi代表系统计算出的评分值,则平均绝对偏差MAE定义为:

5 结束语
现在协同过滤方法虽然已是最成功的推荐方法,但随着电子商务系统规模的日益扩大,协同过滤推荐方法也面临诸多挑战,其中关注最多的有数据稀疏性、冷启动和可扩展性3个问题。
1)稀疏性问题:每个用户一般都只对很少的项目进行评价,整个数据矩阵变得非常稀疏,一般都在1%以下,这种情况带来的问题是得到用户间的相似性不准确,邻居用户不可靠。稀疏问题是推荐技术中的重要问题之一。
2)冷启动问题:在推荐系统刚启动时,没有用户对项目的评价信息,因此系统无法根据评分矩阵进行推荐。同时当一个新用户或一个项目进入系统,由于其没有评分记录,因此系统无法获取其兴趣点和为他找到相似用户,这时推荐系统就出现了盲区。
3)扩展性问题:协同过滤推荐算法的计算量随着日益增多的用户和项目,系统规模不断扩大,推荐系统往往将遭遇严重的扩展性问题。
[1]曾春,邢春晓.个性化服务技术综述[J].软件学报,2002,13(10):1952-1960.
ZENG Chun, XING Chun-xiao.A survey of personalization technology[J].Journal of software,2002,13(10):1952-1960.
[2]武建伟,俞晓红.基于密度的动态协同过滤图书推荐算法[J].计算机应用研究,2010(8):3014.
WU Jian-wei,YU Xiao-hong.Density-based dynamic collaborative filtering books recommendation algorithm[J].Application Research of Computers,2010(8):3014.
[3]黄晓斌.网络信息过滤原理与应用[M].北京:北京图书馆出版社,2005.
[4]周张兰.基于协同过滤的个性化推荐算法研究[D].武汉:华中师范大学,2009.
[5]郁雪.基于协同过滤技术的推荐方法研究[D].天津:天津大学,2009.
[6]黄裕洋,金远平.一种综合用户和项目因素的协同过滤推荐算法[J].东南大学学报:自然科学版,2010(5):918.
HUANG Yu-yang,JIN Yuan-ping.Collaborative filtering recommendation algorithm based on both user and item[J].Journal of Southeast University:Natural Science Edition,2010(5):918.
[7]黄创光,印鉴.不确定近邻的协同过滤推荐算法[J].计算机学报,2010(8):1370.
HUANG Chuang-guang,YIN Jian.Uncertain neighbors’collaborative filtering recommendation algorithm[J].Chinese Journal of computers,2010(8):1370.
[8]郭艳红.推荐系统的协同过滤算法与应用研究 [D].大连:大连理工大学,2008.
[9]Sarwar B,Karypis G,Konstan J,etal.Item-based collaborative filtering recommendation algorithms[C]//In:Proceediings of the 10th International Conference on World Wide Web.New York:ACM Press,2001:285-295.
[10]Sarwar B M. Sparsity,scalability,and distribution in recommender systems[D]. Minneapolis,MN:University of Minnesota,2001.
[11]Sarwar B M,Karypis G,Konstan J,et al.Recommender systems for large-scale e-commerce:scalable neighborhood formation using clustering[C]//In:Proceedings of the 5th International Conference on Computer and Information Technology,2002.
[12]李春,朱珍民.基于邻居决策的协同过滤推荐算法[J].计算机工程,2010(13):34.LIChun,ZHUZhen-min.Collaborative filtering recommendation algorithm based on neighbor decision-making[J].Computer Engineering,2010(13):34.
[13]张雪文.智能推荐系统中协同过滤算法的研究[D].上海:上海交通大学,2008.
[14]王辉,高利军.个性化服务中基于用户聚类的协同过滤推荐[J].计算机应用,2007,27(5):1225-1227.WANGHui,GAOLi-jun.Collaborative filtering recommendation based on user clustering in personalization service[J].Computer Application,2007,27(5):1225-1227.
[15]Terveen L,Hill W,Amento B,et al.PHOAKS:a system for sharing recommendations[J].Communications of the ACM,1997,40(3):59-62.
[16]Iijima J,Ho S.Common structure and properties of filtering systems[J].Electronic Commerce Research and Applications,2007,6(2):139-145.
[17]冯超.嵌入式Linux下的AU 1200 MAE驱动程序设计[J].现代电子技术,2010(8):48-50.FENG Chao.Design of AU 1200 MAE driving program under condition of embedded linux[J].Modern Electronics Technique,2010(8):48-50.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
中学数学杂志(高中版)(2016年6期)2017-03-01
汽车与新动力(2016年6期)2017-01-04
福建中学数学(2016年7期)2016-12-03
浙江大学学报(工学版)(2016年2期)2016-06-05
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
