
基于时间序列模型的中国GDP增长预测分析
2012-01-23 08:50:40何新易
财经理论与实践 2012年4期
何新易
(南通大学 商学院,江苏 南通 226019)*
一、引 言
作为度量一个国家或地区所有常住单位在一定时期之内所生产和所提供的最终产品或服务的重要总量指标,国内生产总值(Gross Domestic Product,GDP)对于判断经济态势运行、衡量经济综合实力、正确制定经济政策等诸多方面,以及在经济研究实际工作中,均起着不可替代的重要作用。
熊志斌(2011)深入分析了时间序列模型与神经网络(NN)模型的优势和劣势,按照两种模型的预测特性,在比较的基础之上,分别构建了ARIMA模型和NN模型,并根据一定算法对两种模型进行了集成。将GDP时间序列的数据结构,根据在非线性空间和线性空间的预测优势,进一步分解为线性非线性残差和自相关主体两部分,即首先用ARIMA分析技术构建线性主体模型,然后用NN模型估计非线性残差,再对序列的整个预测结果进行最终集成。仿真实证结果表明:与单一模型相比,集成模型的预测准确率显著提高,进行GDP预测当然使用集成模型更为有效[1]。桂文林和韩兆洲(2011)认为由于迄今为止,包括季度GDP在内的经季节调整之后的经济数据,中国政府尚未进行公布,不但无法进行国际之间的横向比较,也不利于监测中国宏观经济态势。本文运用1996年第1季度至2009年第4季度的中国实际GDP数据,构建了状态空间模型,使用卡尔曼滤波迭代算法对季节调整模型状态向量的各分量,进行了最优平滑、预测和估计,并使用极大似然方法估计了超参数。经过对GDP的主要季节和趋势特征的分析,计算出了环比增长率指标来监测和分析经济走势,并与国际通用的TRAMOSEATS季节调整模型进行了对比,以便鉴别趋势拐点,制定相关的经济政策[2]。高帆(2010)运用1952~2008年的上海GDP增长率数据,实证研究其内在变动机制,将GDP增长率分解为纯生产率效应、纯劳动投入效应、纯生产结构效应、纯劳动结构效应,并分析了这四种效应之间的交互影响。结果表明:在上海GDP增长率提高的四种效应之中,纯生产率效应起到了关键作用。上海GDP增长率自1978年改革开放之后,在整体上对纯生产率效应的依赖度趋于增强。在1978~1989年期间,纯劳动结构效应是GDP增长的主要因素,由于市场化改革的进一步加大,劳动力跨部门流转在很大程度上得以实现。在1990~2008年期间,纯生产率效应是GDP增长的主要因素,正是由于在此历史阶段,由于资本深化进一步加速,从而有效提高了部门劳动生产率。基于实证的研究结论,可以针对性地制定出今后上海市经济实现持续增长的若干宏观政策[3]。腾格尔和何跃(2010)利用中国季度GDP数据分别构建了ARIMA和ARCH模型,同时利用GMDH自组织方法尝试建模,经过Bon-ferroni-Dunn检验,表明与单一模型相比,组合模型的拟合能力更强。研究表明,基于GMDH组合的GDP模型预测精度更高,无论是经济正常增长时期,还是在经济出现较大波动时期,组合模型的可靠性与准确性都相对较高[4]。
时间序列模型预测是在充分掌握历史数据的基础之上,分析目标对象随着时间改变的发展规律,从而准确预测其未来的变化情况。时间序列建模本质上属于“外推法”,也就是通过对时间序列的处理来研究目标变化,然后利用外推机制将内在规律推演到未来。由于在GDP分析和预测的实际应用中,传统方法运用存在很大的难度[5],而ARIMA模型是目前经济预测中的公认的比较先进的时间序列模型之一,因此本文选用的ARIMA模型对中国1952~2010年的GDP总量进行短期预测,具有重要的现实意义和学术价值。
二、时间序列模型
(一)ARIMA模型的一般介绍
时间序列进行分析的基本思想是:某些数据序列可以看作是随着时间t而随机变化的变量,该序列的单个数据构成序列值虽然不确定,但是整个序列却呈现一定的变化规律,可以用数学模型去近似地描述。人们常常运用时间序列ARIMA模型来进行实证研究,以达到最小方差意义下的最优预测效果[6]。ARIMA模型,英文名称为autoregressive integrated moving average,全称为求和自回归移动平均模型,简记为ARMA(p,d,q),模型结构如下:
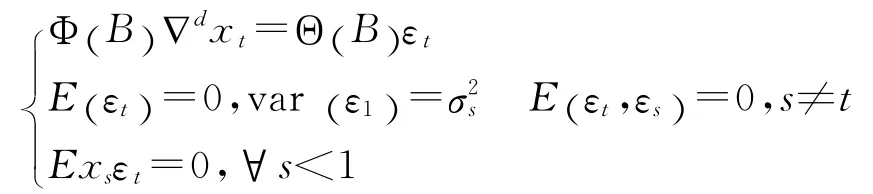
(二)ARIMA模型的简洁定义
定义一:如果通过d次差分,序列yt能够变为平稳,但d-1序列,也就是差分序列并不平稳,那么通常认为序列yt是d阶单整序列,记为yt~I(d)。特别地,如果序列yt不需要进行差分,也即其本身是平稳的,则可称为零阶单整,记为yt~I(0)。
定义二:设yt是d阶单整序列,即yt~I(d),记wt=Δdyt,wt为平稳序列,即wt~I(0),则可对wt建立ARMA(p,q)模型为:
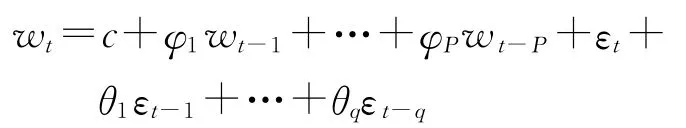
式中,φ1,φ2,…,φp是自回归系数;p是自回归的具体阶次;θ1,θ2,…,θq是序列的移动平均系数,q是移动平均的具体阶次;是一个标准的白噪声序列。
定义三:经过d次差分变换后的ARMA(p,q)模型称为ARMA(p,d,q)模型。
三、ARIMA模型的建模步骤
(一)数据来源及说明
本文研究的样本区间设定为1952~2010年,数据分别来源于《新中国60年统计资料汇编》和中经网统计数据库。为更好地观测数据,本文分别绘制出该历史期间中国GDP的历史统计数据(图1)、一阶差分序列(图2)、二阶差分序列(图3)和取自然对数后的一阶差分序列(图4)。
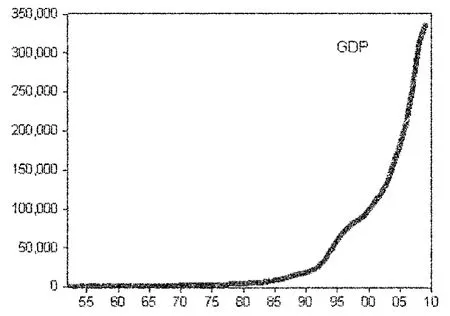
图1 GDP历史统计数据
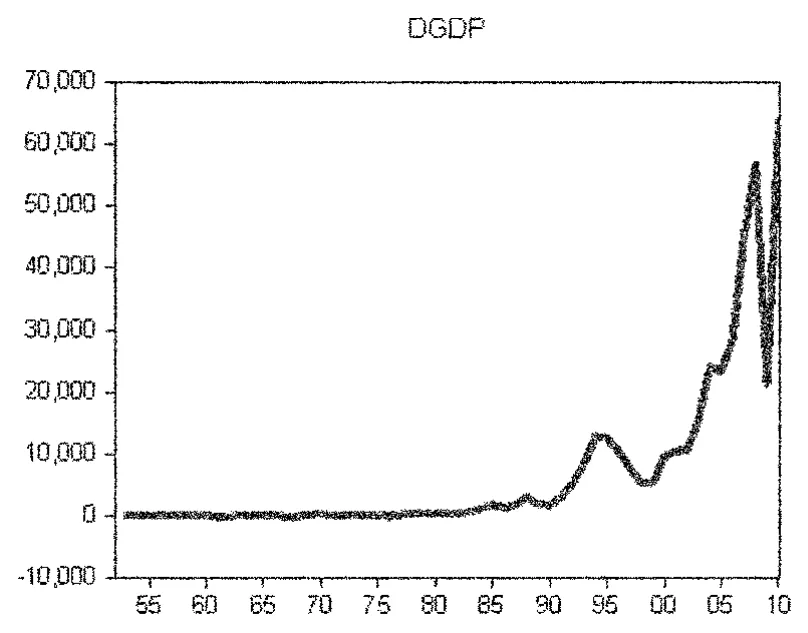
图2 一阶差分序列
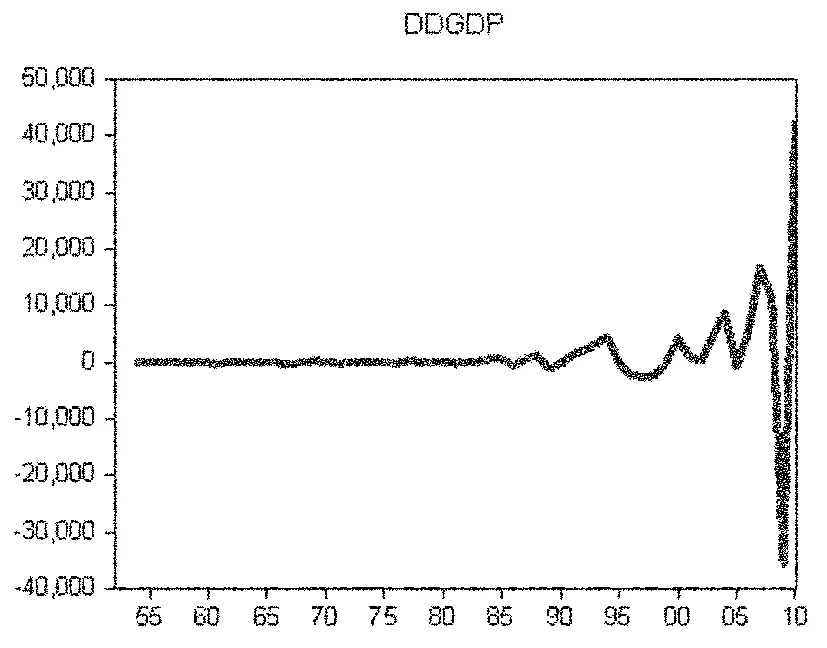
图3 二阶差分序列
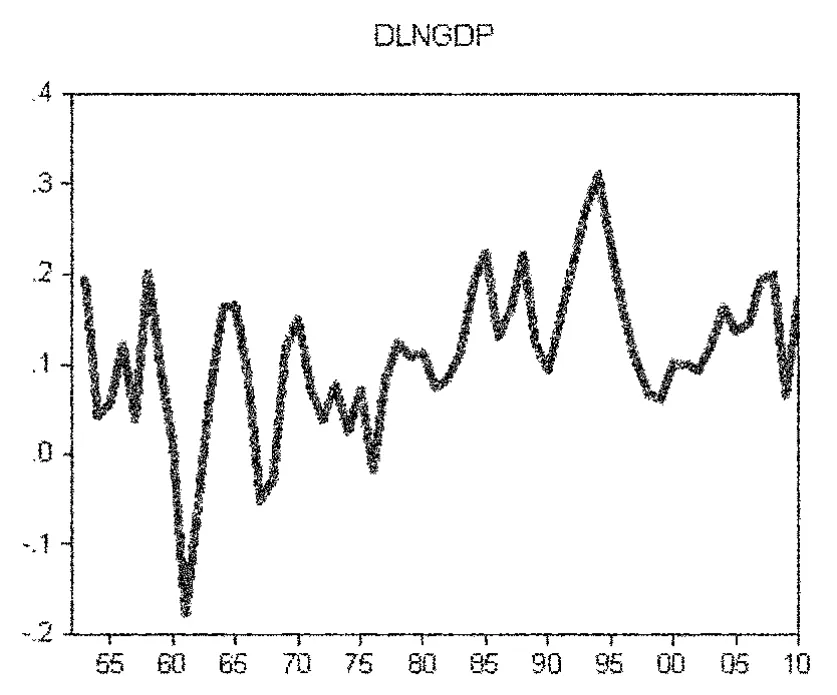
图4 取自然对数一阶差分序列
(二)ARIMA模型中d的确定
ARIMA模型中d是序列yt通过差分变换后成为平稳的单整序列的阶数,因此采用单位根检验方法来检验序列的平稳性以及求得d值,本文选用ADF(augmented Dickey-Fuller Test)检 验[7]。从1952~2010年中国GDP的时间序列趋势图(图1),清楚地观察到GDP的上升趋势非常明显,因此在单位根检验时应该把常数项和时间趋势项都考虑进去,检验结果(见表1)显示,GDP序列以较大的P值,即100%的概率接受原假设,则接受存在单位根的结论。将GDP序列做1阶差分,然后对ΔGDP进行ADF检验,此时选择常有常数项和时间趋势项,检验结果显示,GDP序列以较大的P值,即99.24%的概率接受原假设,就存在单位根的结论。再对ΔGDP做1阶差分,对Δ2GDP做ADF检验,此时选择不含常数项和时间趋势项,检验结果显示,二阶差分序列Δ2GDP在1%的显著性水平下拒绝原假设,接受不存在单位根的结论,因此可以确定GDP序列是2阶单整序列,即d值取为2,GDP~I()2。
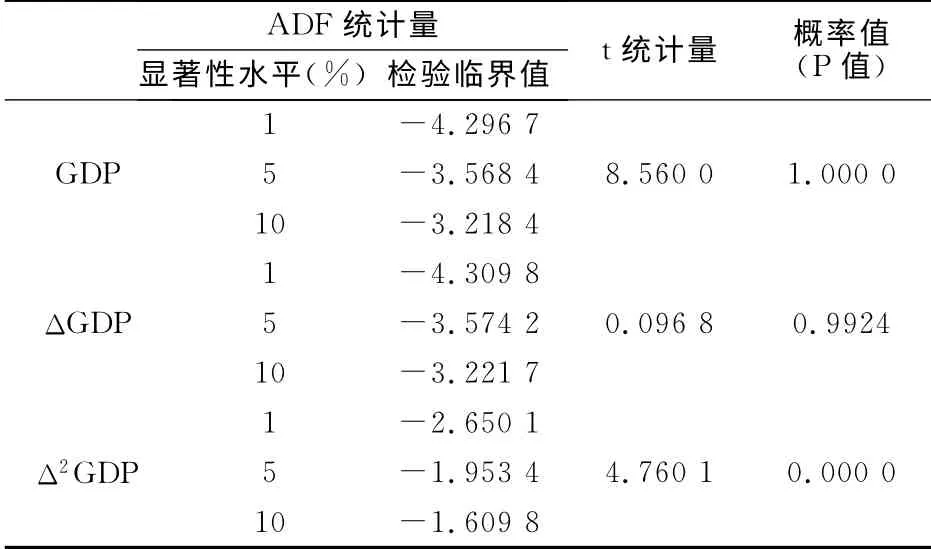
表1 检验中国GDP序列的平稳性
(三)ARIMA模型中p和q的确定
计算Δ2GDP序列的自相关系数(AC)和偏相关系数(PCA)并进行比较,见表2。可知Δ2GDP序列的自相关系数AC在4阶截尾,偏相关系数PCA在2阶截尾,则取模型的阶数p=4和q=4,建立ARIMA(4,2,4)模型。
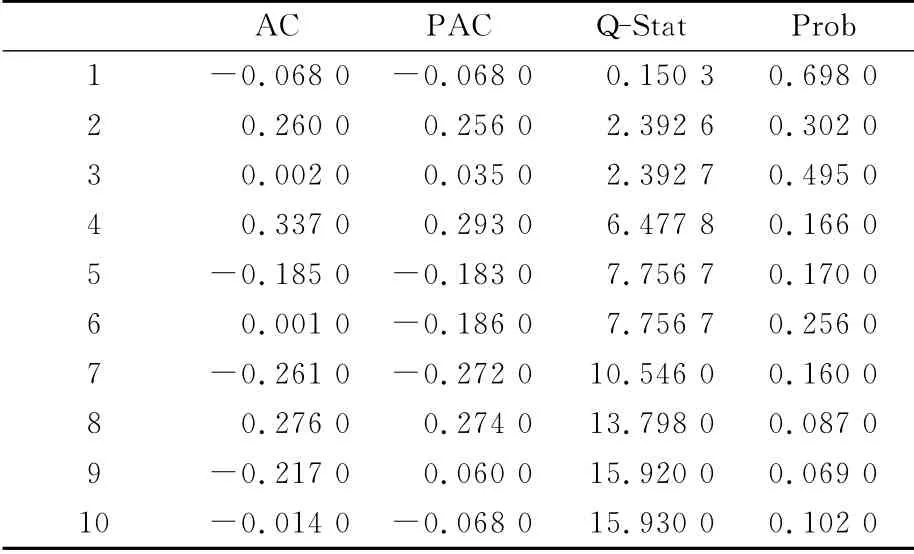
表2 Δ2 GDP序列的自相关系数和偏相关系数
(四)中国ARIMA(4,2,4)模型的预测
利用ARIMA(4,2,4)模型对中国GDP数据进行样本内预测,具体的预测结果及相对误差见表3。
四、结 论
根据本文所构建ARIMA模型预测,首先进行样本期一期的单点精准预测,然后又将样本期间扩大到2015年,进行样本外多期动态预测,得到2011~2015年五个年度的中国GDP预测结果为485789.81、541186.95、602901.31、671653.27、748245.38亿元,表明未来五年中国的经济增长仍将处于一个水平很高的上升通道。
与传统的趋势模型相比,ARIMA时间序列模型属于外推预测法,具有自己独特的优点。由于传统的预测方法,基本上只是对某种典型趋势特征现象比较适用,但在现实中,许多经济现象所表现出来的时间序列资料却并不具有典型趋势特征,更多情况下可能是一种完全随机性质的,这样传统方法建模就不能吻合随机性质的要求,从而对预测效果带来了很大的影响[8]。先根据一个时间序列进行模型识别,然后进行不断建模试验,并加以相关的诊断技术,根据情况再做出必要调整,识别、估计、诊断等环节反复进行,直到找到最优模型为止,因此对于各类的时间序列来讲,ARIMA模型都比较适合,是时间序列预测法中迄今最为通用的模型[9]。针对非平稳序列,通过差分、取自然对数等方法,ARIMA可将其转变为零均值的平稳随机序列,以便有效进行预测分析。通过AR和MA项的添加,从而使残差进入模型,从而大大提高了模型的精度。但是由于假定时间序列,无论是过去的模式,还是未来的发展模式,ARIMA建模法都视为一致,因此它的预测往往只在短期内比较有效。
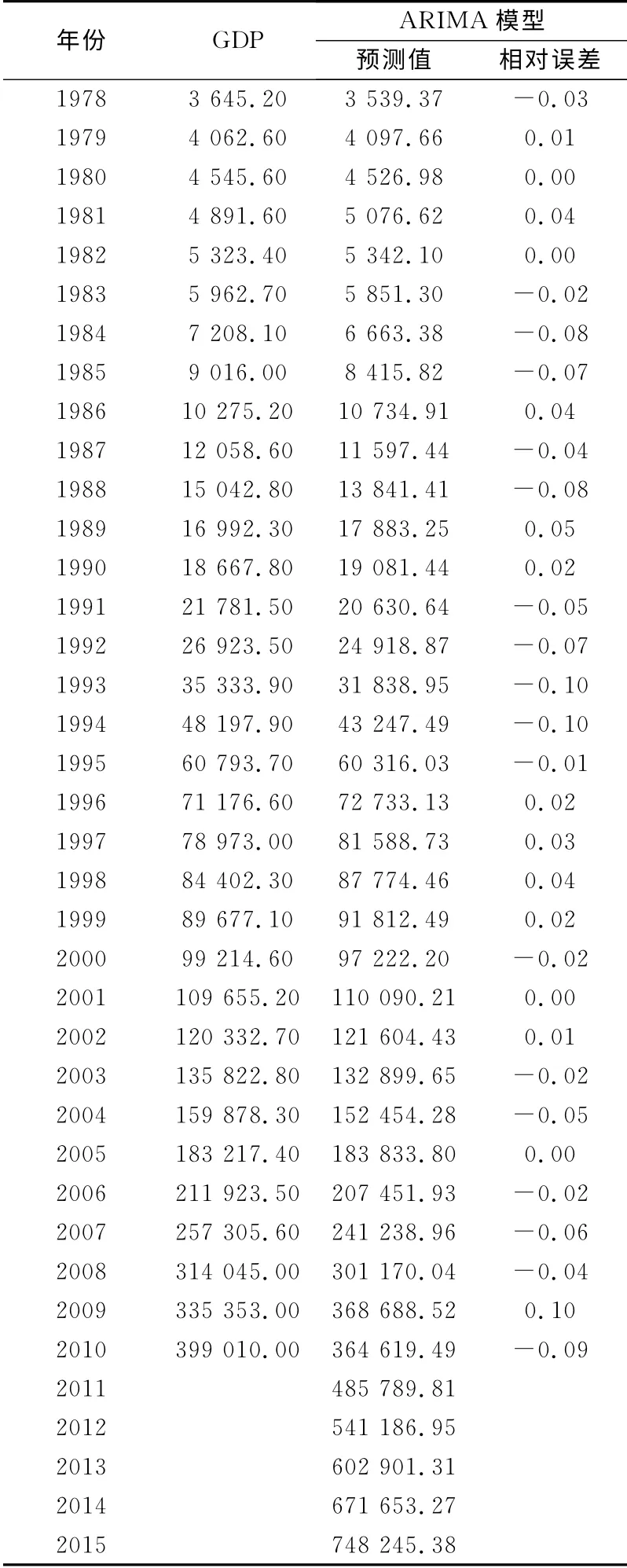
表3 模型拟合结果比较
本文通过平稳线检验、阶数识别、参数估计、模型诊断等过程,对中国1952~2010年的国内生产总值(GDP)构建了ARIMA模型,从拟合的效果来看,当然还有待于做进一步的完善,但本文所做出的精准预测,无疑将为相关部门的工作、规划提供科学依据。
[1]熊志斌.基于ARIMA与神经网络集成的GDP时间序列预测研究[J].数理统计与管理,2011,(2):306-314.
[2]桂文林,韩兆洲.基于状态空间模型的中国季度GDP季节调整(1996~2009年)[J].数量经济技术经济研究,2011,(7):77-89.
[3]高帆.上海GDP增长率的因素分解及其政策含义[J].上海经济研究,2010,(4):99-109.
[4]腾格尔,何跃.基于GMDH组合的中国GDP预测模型研究[J].统计与决策,2010,(7):17-59.
[5]喻胜华,邓娟.基于主成分分析和贝叶斯正则化BP神经网络的GDP预测[J].湖南大学学报(社科版),2011,(6):42-45.
[6]肖文,周明海.劳动收入份额变动的结构因素——收入法GDP和资金流量表的比较分析[J].当代经济科学,2010,(3):69-76.
[7]王维国,王霞,颜敏.时间序列多个突变点的贝叶斯推断——对我国GDP序列的实证分析[J].数学的实践与认识,2010,(9):45-53.
[8]华鹏,赵学民.ARIMA模型在广东省GDP预测中的应用[J].统计与决策,2010,(12):166-167.
[9]倪晓宁,包明华.DEA方法在潜在GDP估算中的应用[J].统计与决策,2011,(2):24-26.
猜你喜欢
数学年刊A辑(中文版)(2023年4期)2024-01-04 05:47:32
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
理化检验-化学分册(2020年12期)2020-03-02 12:07:24
中国特种设备安全(2018年10期)2018-12-18 02:16:46
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
山东工业技术(2016年15期)2016-12-01 05:30:56
信息安全研究(2015年3期)2015-02-28 20:17:57
