
基于树库的四六级作文语篇关系分析
2012-01-14 13:35蒋联江
集美大学学报(教育科学版) 2012年2期
蒋联江,赵 以
(集美大学外国语学院,福建 厦门 361021)
基于树库的四六级作文语篇关系分析
蒋联江,赵 以
(集美大学外国语学院,福建 厦门 361021)
语篇关系作为衔接机制对语篇结构的完整性与连贯性起重要作用,以语料库语言学方法,收集大学英语四六级作文素材组成小型封闭生语料库,然后利用RST工具标注作文语篇结构组建RST语篇树库,基于树库的数据驱动学习提出中国英语学习者偏好使用的语篇关系集合及相关触发语的选用特征,结论是语篇关系的正误使用与作文分数等级呈正负相关的线性关系。
语篇关系;触发语;RST工具;语篇树库
作为二语知识产出过程,作文一直是第二语言和外语学习比较难的阶段。如果语篇关系处理不当,过渡不自然就会影响语篇的整体连贯。研究四级作文的语篇关系,有助于揭示作文语篇中句子意义之间的联系。从非结构衔接上讲,句子之间由衔接链和连接成分联系起来[1]274。修辞结构理论(rhetorical structure theory,简称RST)认为几乎所有英语语篇中的小句和句子之间都应该有连接成分,并将其定义为修辞关系,即语篇关系 (discourse relation)。语篇关系可以连接词或触发语(marker)明确表达出来。语篇关系也可以是隐性的。如果两个句子或小句以先后顺序排列即可表达其意义,连接词就不必明晰化,否则反而降低语篇的连贯性。
一 语篇关系和RST理论
(一)语篇关系的树形图表示
语篇关系是修辞结构理论的核心概念。作为美国功能语言学派的主要代表,RST理论被广泛运用于自然语言处理以及语篇分析等领域。该理论提出者在详尽分析上百篇包括广告、科技、信件、以及新闻等日常英语语篇的基础上,提出如下结论:日常英语语篇的语篇结构总是由为数不多的、反复出现的语篇关系维系着[2]355。这些语篇关系可以形式化为两种结构类型,即单核关系 (mononuclear)和多核关系 (multinuclear)。单核关系衔接着核心(nucleus)语段和附属 (satellite)语段。核心和附属语段为语篇中不相重叠 (non-overlapping)的连续语段。与附属语段相比,核心语段的内容对表达作者意图更为重要。删除附属语段,核心语段仍具有语篇意义;反之,删除核心语段则导致作者意图的模糊或缺失。如例1所示,语段1和语段2之间以证据 (Evidence)关系衔接。核心语段1表达作者的观点,附属语段2陈述支持作者观点的证据。
例1:[The truth is that the pressure to smoke in junior high is greater than it will be any other time of one’s life.1][we know that 3 000 teens start smoking each day.2]
常见的单核关系可用树形图表示如下 (1,2代表两个语段;语段1为核心部分,语段2为附属部分;语段间的语篇关系为证据关系)
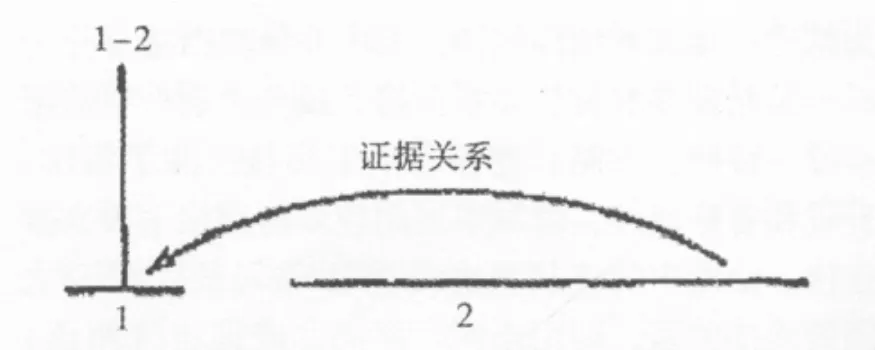
图1 证据关系图解
多核关系,顾名思义,即语篇关系的多个语段都具有核心语篇意义,对作者意图的表达起同等重要的作用。此类关系有对比关系 (Contrast),序列关系 (Sequence)等,可用树形图表示如下:
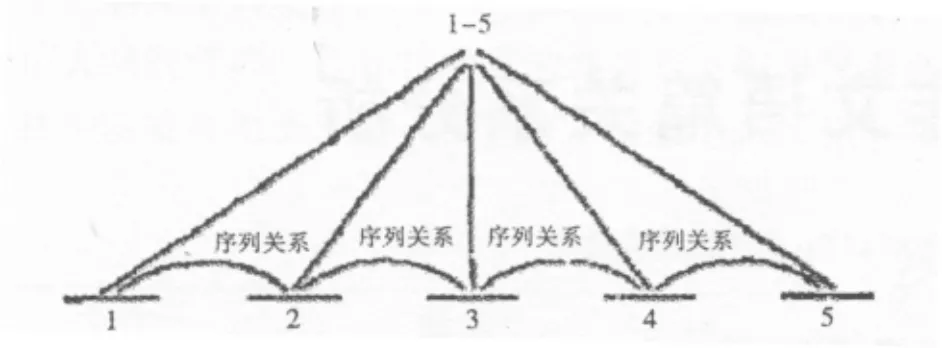
图2 系列关系图解
基于以上树形图,RST工具等使得语篇层次上标注语篇结构成为现实。RST理论提出者依据他们的语料提出一套配有详尽的定义和示例的语篇关系集合。这个集合将小句与小句之间的语义关系归纳为24种类型的语篇关系[1]114-115。这个语篇关系集合无法穷尽所有语篇类型中的语篇关系。不少学者基于不同的语料对其进行丰富和拓展。美国计算语言学家Daniel Marcu等收集了383篇Wall Street Journal的文章组成语料库,在RST理论框架下对其语篇结构进行标注,开发RST语篇树库 (discourse Treebank)并进行数据挖掘,提出一个含有53种单核语篇关系以及25种多核语篇关系的集合。美国语言数据联盟 (Linguistic Data Consortium)于2002年发布了RST语篇树库,为语篇分析提供语篇结构层次上标注的语料库支持。
(二)语篇关系的触发语
RST理论认为语篇关系是语篇中不相重叠的连续语段间的连接成分,其本质上是一种语义概念,是衔接关系。张德禄等[1]101指出语篇内部所有用以组织语篇意义的小句及其以上单位之间的意义关系都应该看作衔接关系,它包括各种结构成分之间的意义关系。根据韩礼德和哈桑的观点[3],衔接分为结构衔接和非结构衔接。其中非结构衔接又分为成分关系衔接和有机关系衔接。成分关系衔接包括指称、替代、省略、连接和词汇衔接。除了指称、替代和省略以外,篇章中运用较多的衔接手段当数连接。语篇中的连接概念专指相邻句子 (群)之间的连接关系,即用连词、副词、或词组 (短语)把两个语段联系起来的手段,与RST理论框架下语篇关系触发语的研究有紧密的联系。通过连接性词语的运用,人们可以了解句子之间的语义联系,甚至可经前句从逻辑上预测后续句的语义。韩礼德和哈桑[3]把连接分为四种:增补型、转折型、原因型和时间型。然而这些分类不能代表中国英语学习者的真实语言使用情况。RST语篇树库发布后,关于语篇关系触发语在语篇分析和文本生成中作用的实证研究已经有了语篇结构层次上标注的实体支持[4]16,方便了语言学家在多种语篇类型中研究触发语。
(三)RST理论和四六级作文
RST研究者的工作表明,中国大学英语四六级考试作文可为语篇关系的RST分析提供良好的语言素材,进行语篇树库开发,其预期研究结果可作为语篇衔接关系研究的有益补充。
四六级作文的评阅采取整体评分法 (global scoring),即依据书面表达的整体效果进行评分。这与RST理论的语篇解释不谋而合。RST理论认为在完整连贯的语篇中,其所有语篇组成单位 (unit)须对作者整体语篇意义的表达效果有存在之理据。不同于随意句子组合的是语篇具有统一性和整体性。确定语篇关系,等同于确定了语篇结构以及语篇连贯的基础[5]21。如果语篇关系缺失,或者使用不当,那么语篇结构就不健全,语篇连贯由此受影响。
据此,我们得出研究假设,四六级作文质量与RST结构呈正相关。RST结构完整,代表其语篇关系处理恰当,语篇连贯性好,相应作文得分应高;反之,得分则低。
二 研究设计
(一)组成生语料库
150篇某大学2006年12月大学英语四级考试的作文被收集起来用于组成研究所需的生语料库,作文题目为一篇竞选学生会主席的演讲稿 (Write a campaign speech in support of your election to the post of chairman of the Student Union)。为了兼顾样本代表性和数据推断有效性,每个分数段 (分2、5、8、11及14共5个分数段)各随机选取30篇样本作为生语料来源。语料库总单词数为26 037个。最短作文语篇有单词51个,最长有288个,平均语篇长度为173.58个单词。
(二)标注小型RST语篇树库
1.语篇结构的树形表征。小型封闭语料库建好后需要对其进行语篇结构标注。依据RST理论,文本的语篇结构可以用树形图从以下4个方面进行表征:
首先,树形图的叶 (leaves)对应语篇最小组成成分,称基本语篇单位 (elementary discourse u-nit,简称 EDU)。
其次,树内节点 (internal nodes)对应邻近语段。
再次,节点有其核心属性。核心点 (a nucleus)代表更为重要的信息单位,附属点代表支撑或背景信息单位。
最后,节点间有语篇关系相连。两个或多个不相重叠的、邻近语段间须由语篇关系衔接。
2.标注工具及语料库检索工具。Marcu等人标注其RST语篇树库为我们提供了宝贵的经验。其建库所用软件以及标注指南可从网上查询,网址为http://www.isi.edu/~marcu/discourse。
我们使用的RST工具 (RSTTool)是澳大利亚Mick O’Donnell博士研发的文本分析工具。RST工具包括4个主要操作界面:
首先是文本界面,可进行EDU切分。
其次是文本结构关系界面,可标识语段间语篇关系,建立语篇结构树形图。
再次是结构关系编辑界面,用于编辑和定义语篇关系。
最后是数据统计界面,可提供数据统计分析。
3.切分基本语篇单位EDU及建立语篇结构。切分EDU是建立语篇结构的第一步。依据Marcu等人的研究经验,我们将基本语篇单位锁定为小句(clause),然后利用词汇或句法上的提示语等帮助确定语篇单位界限。以下是两个切分例子,其中<><><>中的阿拉伯数字分别代表语篇树库中的样本序号,生语料库中的样本序号,以及该样本的分数。为了不改变语料风格,我们对例子中的语法错误等予以保留。
例2: [If I pick up students chairmen position,][I will take out a lot of good things][and acivit for students][after study in school.]<5> <51> <2>
例3: [I’m full of experience of working in the student union.][I’ve worked in the student union for two years.][So I can do the work in very effective way.]<10> <1042> <14>
EDU切分后便可依据RST语篇关系定义及示例确定EDU间语篇关系,建立语篇结构树形图。确定语篇关系是语义判断的过程,需要利用Marcu等人在创建树库时使用的删除法或替换法检验是否分配了正确的核心语段或附属语段。删除法指若删除语篇关系衔接的邻近语段中的附属语段,其核心语段仍将充当原本的语篇意义。而删除了核心语段,其邻近的核心语段,其附属语段便会影响到语篇的整体连贯。替换法指附属语段可用其他多种信息来替换而不改变该邻近语段的语篇关系以及语篇意义,而核心语段不具有此类可替换性。
语篇关系集合则须等到整个语篇树库标注完方可最后确定,是数据驱动式学习的过程。
4.标注顺序及检查。分析语篇及建立相应的树形图有着不同的顺序。考虑到四级作文语篇相对较短,容易对语段进行前期预测,因此,我们采用以下标注顺序:首先,在文本界面完成基本语篇单位切分,然后在语篇关系编辑界面将语篇单位间的语篇关系定义好,最后在文本结构关系界面从左至右增量地将邻近节点添加到树形图上。
树形图完成后需要进行句法核实以及语义判断。句法核实是确保树形图有一个单独的根节点。语义判断是检查语篇关系核心或附属属性以及语篇关系的选用等是否判断有误。
三 结果分析
(一)语篇树库总览及语篇关系使用偏好
标注后的四级作文语篇树库包含3 542个EDU,平均每篇作文的EDU数量为23.613个。最短的语篇结构树含9个EDU,而最长的有43个EDU。每个EDU的平均单词数为7.35个。
基于此树库,笔者统计出中国英语学习者在四级作文中总共使用的语篇关系可分为三类,即单核关系,多核关系以及图式 (专指演讲中的称呼语,结束语,以及无法进入语篇的不相关EDU),然后使用非参数检验中的Friedman检验确定正确使用的所有语篇关系的秩次,得出中国英语学习者在四级作文中语篇关系的使用偏好情况。Friedman检验得出秩次统计表如表1所示,该表汇报了每种语篇关系的平均秩次的排列情况。
显然,学生作文中常用的语篇关系集合包含26种类型的语篇关系 (4-29)。树库中使用最多的单核关系,其次是多核关系。具体的语篇关系中使用最多的是单核的原因关系,而最少的多核的原因—结果关系。对这26个语篇关系变量分布之间的差异进行秩次检验统计得出本例显著水平为0.00,小于 0.05的显著值。其实际卡方值为125.803,远远大于当显著性水平为0.05,自由度为2的临界值5.99,因此这些变量间存在显著差异,即递减之势变化明显。
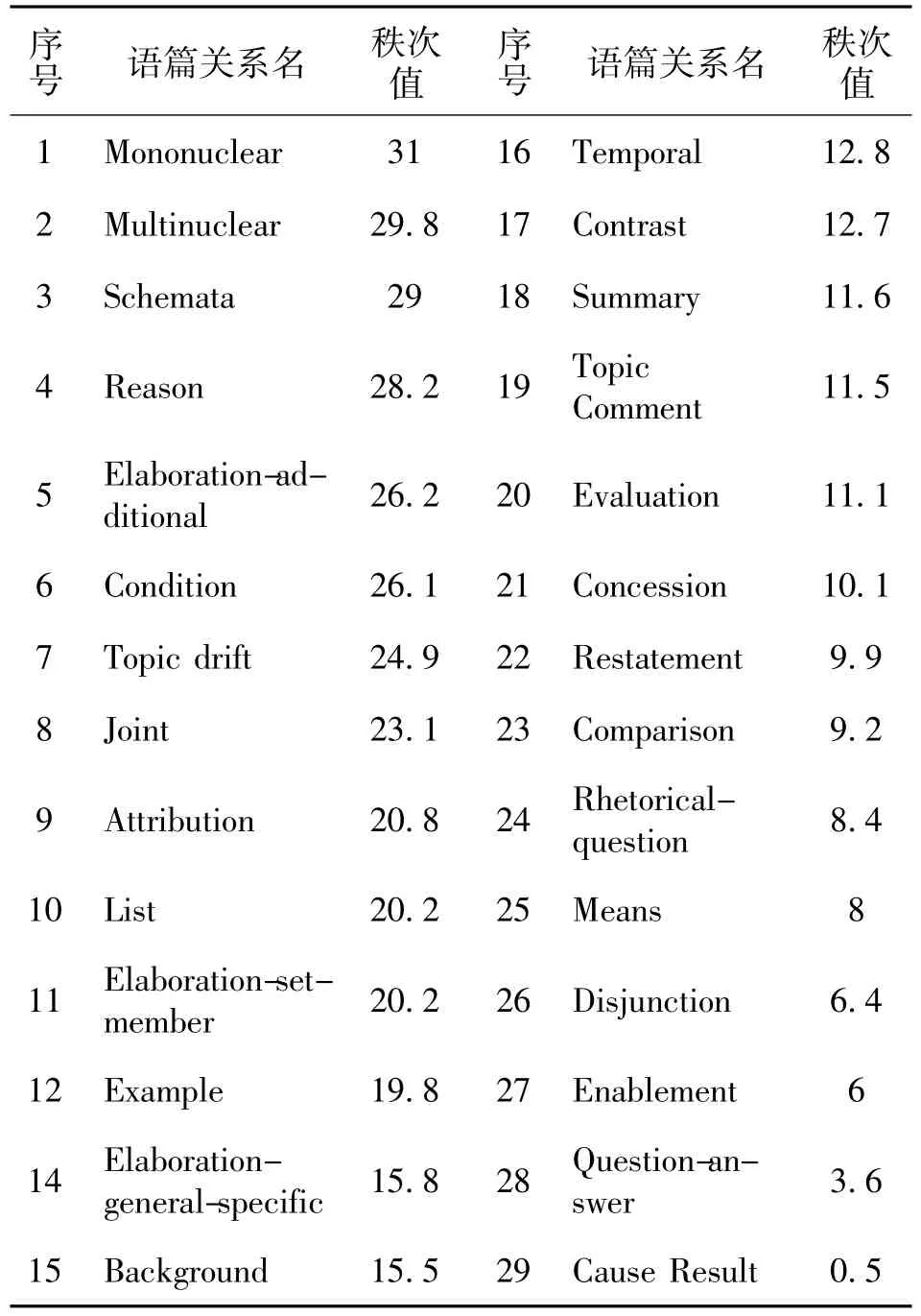
表1 正确使用的语篇关系秩次表
(二)语篇关系的正误使用与作文分数等级
为检验语篇关系的使用情况与作文分数两个变量间的线性关系,偏相关分析被采用。分析所得的零阶相关矩阵表明,作文分数与错误使用的单核关系和多核关系的简单相关系数分别为-0.967和-0.9661,在0.05的显著水平上达到了统计意义。这说明单核关系与多核关系的错误使用与作文分数等级负相关,即错误使用越多,分数等级越低。
偏相关分析也用来检验语篇关系的正确使用与作文分数等级之间的正相关关系。分析所得的零相关矩阵表明,作文分数与正确使用的单核关系和多核关系的简单相关系数分别为0.9600和0.8639,且在0.05的显著水平上都达到了统计意义。这说明单核关系与多核关系的正确使用与作文分数等级正相关,即正确使用越多,分数等级越高。
由此,该文的研究假设得到了验证,即语篇关系的正误使用分别与作文分数等级呈正、负相关的线性关系。语篇关系正确使用越多,错误使用越少,其作文RST结构越是健全,作文语篇更趋于连贯,故而分数等级也会越高,反之亦然。
(三)语篇关系触发语使用偏好
我们利用语料库检索工具统计了学生使用最多的单核语篇关系的触发语,发现学生喜欢用触发语“and”来触发各种语篇关系,其中最为经常触发的语篇关系为增补关系 (elaboration-additional)。学生也喜欢用不同的触发语来触发同一类型语篇关系,如条件关系就有10个触发语,以“if”居多。另外学生也偏向于使用“because”来触发原因关系。这些特征分布在不同分数等级的作文中,详见表2。

表2 触发语词项分布
语篇关系触发语词项随着作文分数等级的递增而逐渐丰富,表明高分作文掌握了更多的触发语来引导语篇关系。然而,表2无法体现触发语在语篇关系衔接的邻近语段之间的位置等特征。RST语篇树库为深入揭示触发语词项在引领语篇关系构建语篇结构时的作用提供了可能性。具体比较两个引导原因关系的触发语“because”和“since”在树库中的使用情况表明树库中所有出现的触发语并不必然引导一定的语篇关系。数据驱动的学习显示存在拼写错误的情况。在引领单核关系时,这两个触发语多出现在附属语段(“because”占 87.5%;“since”占72.72%)。其在语篇关系的邻近语段中也更多的出现的右边语段的位置上。
四 结束语
上述基于小型RST语篇树库的数据挖掘显示,语篇关系的正误使用与作文分数等级呈正负相关的线性关系。正确识别这些语篇关系在学生作文语篇中的运用特征,有助于理解学生的衔接与连贯意识,培养学生宏观语篇能力。语篇关系触发语的特征分析是对衔接机制研究的有益补充,有利于揭示触发语和语篇关系的内在联系。基于RST工具的小型封闭语篇树库的标注与建立为这些研究提供了可靠的语料基础和数据支持。当然,用以建立RST语篇树库的生语料库的语类和语域范围以及语料库的规模有待进一步扩大。
[1]张德禄,刘汝山.语篇连贯与衔接理论的发展及应用[M],上海:上海外语教育出版社,2003.
[2]MANN W.C.,S.A.THOMPSON.Rhetorical structure theory:toward a functional theory of text organization[J].Text,1988,(3):243 -281.
[3]HALLIDAY M.A.K R.HASAN.Cohesion in English[M].London:Longman,1976.
[4]MARCU D.The theory and practice of discourse parsing and summarization[M].Cambridge,Massachusetts:MIT Press,2000.
[5]MANN W.C.,S.A.THOMPSON.Rhetorical structure theory:a theory of text organization[M].Information Sciences Institute(ISI)Reprint no.ISI/RS-87-190,University of Southern California,1987.
Analysis of Discourse Relation in CET Writings Based on Treebank
JIANG Lian-jiang,ZHAO Yi
(School of Foreign Languages,Jimei University Xiamen 361021,China)
As a cohesive device,discourse relation is critical in unity and coherence of discourse structure.The present study annotated a small-scale corpus of CET-4 compositions and constructed a closed RST discourse Treebank with RSTTool.Taxonomy of discourse relations as well as markers used by Chinese EFL students is proposed after a corpora data-driven study.Statistical data is calculated to advocate an either positive or negative correlation between correct and improper use of discourse relations and grade levels of those CET-4 compositions.
discourse relation;marker;RSTTool;discourse Treebank
G 623.31
A
1671-6493(2012)02-0115-05
2011-02-26
集美大学教育教学改革项目 (JY09248)
蒋联江 (1980—),男,福建大田人,集美大学外国语学院讲师,硕士,主要研究方向为功能语言学。
(责任编辑:吴姝)
猜你喜欢
新世纪智能(高一语文)(2020年5期)2020-07-24
教育文汇(综合版)(2020年4期)2020-06-15
天津外国语大学学报(2020年1期)2020-03-25
首都医科大学学报(2015年4期)2015-12-16
语言与翻译(2015年4期)2015-07-18
无机化学学报(2014年12期)2014-02-28
无机化学学报(2014年7期)2014-02-28
无机化学学报(2014年5期)2014-02-28
外语学刊(2011年1期)2011-01-22
当代外语研究(2010年3期)2010-03-20
