
基于半监督学习的中文多文档子主题划分*
2011-12-17 09:41徐晓丹
浙江师范大学学报(自然科学版) 2011年3期
徐晓丹
(浙江师范大学数理与信息工程学院,浙江金华 321004)
0 引言
随着Internet的发展和普及,跨文本的研究越来越受到人们的重视.将同个主题的多个文本去除冗余信息,按照一定的压缩比有机地融合在一起,即为多文档文摘.随着网络信息量的日益丰富,多文档文摘技术已成为新的研究热点.
目前,对多文档研究较多的是通过聚类的方法生成多文档文摘[1-3],将多文档集合中相同意义的文本单元(句子)聚成一类,每一类便可以理解为一个子主题或是逻辑主题,然后从子主题中抽取句子生成文摘.从子主题的角度生成文摘可以使文摘的覆盖性强而冗余信息少,是一种有效的方法.在该方法中,子主题的确定是其中关键的一个环节,现有的方法主要有基于层次聚类的方法和k-means方法(即k均值聚类算法).基于层次的聚类方法需要预先设定一个终止的阈值,而阈值的确定需要大量的先验知识;基于k-means的聚类方法需要预先给定目标类别数量,而文档中的子主题的数目是未知的.2种方法的效果都不是很理想.
针对上述情况,本文将半监督聚类的思想融入到子主题划分中,通过层次聚类对可信度高的句子进行主题类别标记,生成少量已标记主题类别的句子集,在此基础上对所有句子进行constrained-k-means聚类,通过交叉验证的方法确定子主题的数目k,然后采用k-means聚类生成k个子主题.
1 多文档子主题的表示
多文档集合D由文档di组成:D={di|i=1,2,…,f},每个文档 di可以表示为句子 si,l的集合,di={si,l|l=1,2,…,g},由此多文档集合 D 就可以看成是句子的集合:D={si,l|si,l∈di,i=1,2,…,f,l=1,2,…,g}.其中:i表示集合中的文本号;l表示句子在文本中的位置.
多文档集合的子主题是指多文档集合中意义相同或相似的句子组合,这些子主题代表多文档集合中的各个局部信息,局部信息的综合在一定程度上能代表文档集合的总体信息.因此,多文档集合可以描述成由多个子主题构成:D={Ti|i=1,2,…,h},每个 Ti是一个句子集合.
将多文档集合描述为若干逻辑子主题的集合,是从理解的角度描述多文档集合,在此基础上可以提高多文档文摘的质量和信息的覆盖率.在逻辑子主题的划分过程中,句子之间的语义距离是一个重要的衡量因素,2个句子的语义距离越小,它们被划为同一个主题的可能性就越大.
2 句子的语义距离计算
本文通过计算句子的相似度获取句子之间的语义距离.2个句子的相似度越大,语义距离就越小.基于上述假设,设2个句子A和B之间的相似度为 S(A,B),则句子 A和 B的语义距离d(A,B)为
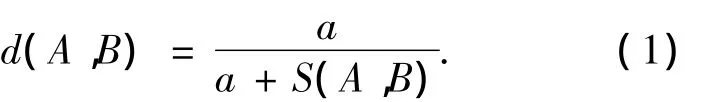
式(1)中,a为可调参数.
句子的相似度通过计算句子所包含词汇之间的相似度获得.设句子A包含的有效词为a1,a2,…,am,B 包含的有效词为 b1,b2,…,bn,则句子 A和B之间的语义相似度S(A,B)的计算公式为
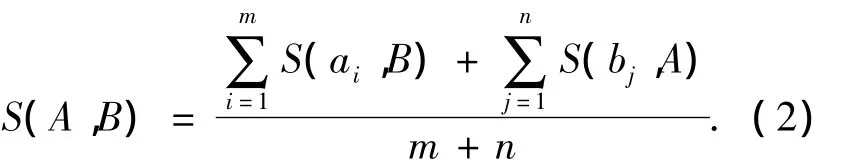
式(2)中:m和n分别表示句子A和句子B的有效词的个数;S(ai,B)表示词ai和句子B的相似度;S(bj,A)表示词 bj和句子 A的相似度;S(ai,B)=max(S(ai,b1),S(ai,b2),…,S(ai,bn));S(bj,A)=max(S(bj,a1),S(bi,a2),…,S(bi,am));S(ai,bj)表示 2 个词 ai,bj之间的语义相似度,计算公式为
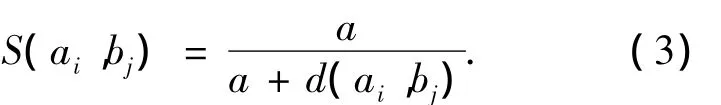
式(3)中,d(ai,bj)表示词 ai,bj之间的语义距离.
为了计算2个词之间的语义距离,以哈尔滨工业大学信息检索研究中心提供的《同义词词林扩展版》为基础,根据它提供的词的语义编码计算词的语义距离.《同义词词林扩展版》采用层级体系,按照树状的层次结构把所有收录的词条组织到一起.在该词典中,每个词都有一个语义编码,这个语义编码采用5层结构,分别为大类、中类、小类、词群和原子词群.2个词之间的语义关系通过编码来体现,例如“农民”的语义编码为Ae07A01,“牧民”的语义编码为“Ae07B01”.若 2个词的语义编码的第1层、第2层和第3层都是相同的,从第4层开始不同,则说明这2个词的意义比较接近.d(ai,bj)具体计算公式为
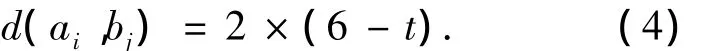
式(4)中:t(2≤t≤6)为它们之间的语义代码从第t层开始不同;当t=6时,表示前面的5层全部相同,语义距离为0,说明2个词为同义词,它们间的相似度就为1.
若2个词的语义代码从第1层就开始不同,但同属于 A,B,C,D 大类或者同属于 F,G,H,I,J大类,则考虑到《同义词词林》大类之间的相关性(如第1至第4大类多为名词,第6至第10大类多为动词等等),将这类词语之间的语义距离设为d(ai,bj)=12,否则就将其设为+∞.
3 半监督聚类的子主题划分
计算出句子的语义距离后,就可以进行子主题的划分.其基本的思想是:将语义距离小即相似性高的句子聚成一类,生成若干个子主题.传统的基于层次聚类的方法中阈值的确定需要大量的先验知识,同时聚类结果不能修正;k-means聚类方法通过多次迭代修正可以取得好的聚类效果,但该方法需要预先知道聚类的个数.本文采用半监督的聚类方法,可以有效地克服上述缺陷,取得较好的效果.
3.1 半监督的k-means聚类
半监督学习的基本思想是:利用有标记数据构造学习机,并对部分无标记数据进行预测,再将无标记数据和对应的预测标记加入到训练集中,重新对学习机进行训练,以提高学习机的性能[4].根据学习任务的不同可分为半监督分类和半监督聚类.半监督聚类方法利用少量的标记数据辅助聚类算法的实现,将提高聚类算法的精度.
现有的半监督聚类算法[5]很多是在传统聚类算法的基础上引入监督信息发展而来,代表性算法是基于经典k-means算法的各种半监督kmeans算法.
k-means算法为:假设有一个无标记的数据集X={x1,x2,…,xn},xi∈Rn,将其分成 k 类 C1,C2,…,Ck,即 Cq={xj}Nqj=1⊂X,每类的均值为 m1,m2,…,mk.其中,Nq为第 q 类的样本数目[6].则第 q类的均值mq的计算公式为
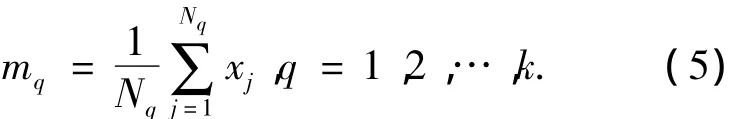
基于欧氏距离[7]、类内误差平方和准则,k-means聚类的目标函数定义为
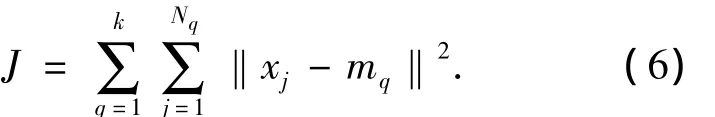
k-means方法中k值和聚类中心的选择对算法有较大的影响.本文采用半监督的思想确定k值:首先,使用层次聚类获得初始的类别k,并把类别中可信度高的样本标记为该类别,获得已标记样本集合;然后,根据已标记样本集合和未标记样本集合修正初值k,修正的过程就是一个半监督的学习过程.
假设已标记的少量样本集合为L,无标记的样本集合为U,i和j为已标记样本集的标记.取k=2为初始值,在完整的样本集{L,U}上进行constrained-k-means聚类[8],当 k 取不同值时,计算已标记样本集L中被错误标记的样本总数M,使M取得最小值的k值即为k-means算法的最佳初值.其中
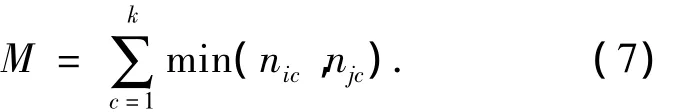
式(7)中:c表示聚类后各簇的标号;nic,njc表示在第c簇中标记为i,j的数据的数量.
根据空簇出现的频率判定k是否已经取到最大值.空簇指的是某一簇中不包含任何标记数据.当空簇出现的频率大于45%(经验值)时,可以认为k已经取到最大值.在k值的优化过程中,如果某一簇内的监督信息满足下式,那么认为此次聚类结果无效:
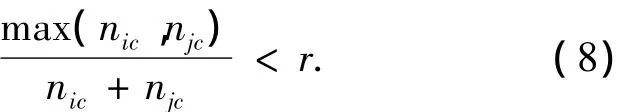
式(8)中,r为一个阈值.阈值r根据反复实验确定,一般认为当nic与njc数量接近时,类标记为c的簇即为无效簇.
3.2 基于半监督聚类子主题划分算法
基于半监督聚类子主题划分算法的步骤如下:
1)预先给定一个初始子主题的数目h(一般取值为3),使用层次聚类方法获得初始聚类T={Ti}(1≤i≤h),其中 Ti是句子的集合,Ti={si,l|l=1,2,…,g'}.
2)对于每个Ti,找出离聚类中心最近的w个句子(w取初始类别的平均句子数目的5%),将其标记为该类别,并将这些句子加入到已标记数据集合L中,形成初始的少量带标记的句子集合L和无标记句子集合U.
3)取k=2为初值,在完整的句子集{L,U}上进行constrained-k-means聚类,当聚类后空簇的频率大于设定值时,结束聚类.
4)计算当k取不同值时L中被错误标记的句子总数M,选择M的数目最少的k为子主题的数目.
5)以上面生成的k值为基础,对所有的句子进行k-means聚类,最后得到k个子主题.
4 实验与评估
本文采用聚类的正确率来评价聚类的结果.首先由专家得到文档集合的主题信息;然后以专家的聚类为标准,比较文档里的每个句子是否被分在正确的主题类中,得到聚类的正确率p作为评价指标;最后采用本文提出的方法进行实验.实验的语料库来自人民网的原始网页,包含军事、国际、经济等8个大类别共5 096个网页.从语料库中抽取10个多文档集合进行实验,每个集合包含5~8篇文章.实验结果如表1所示.
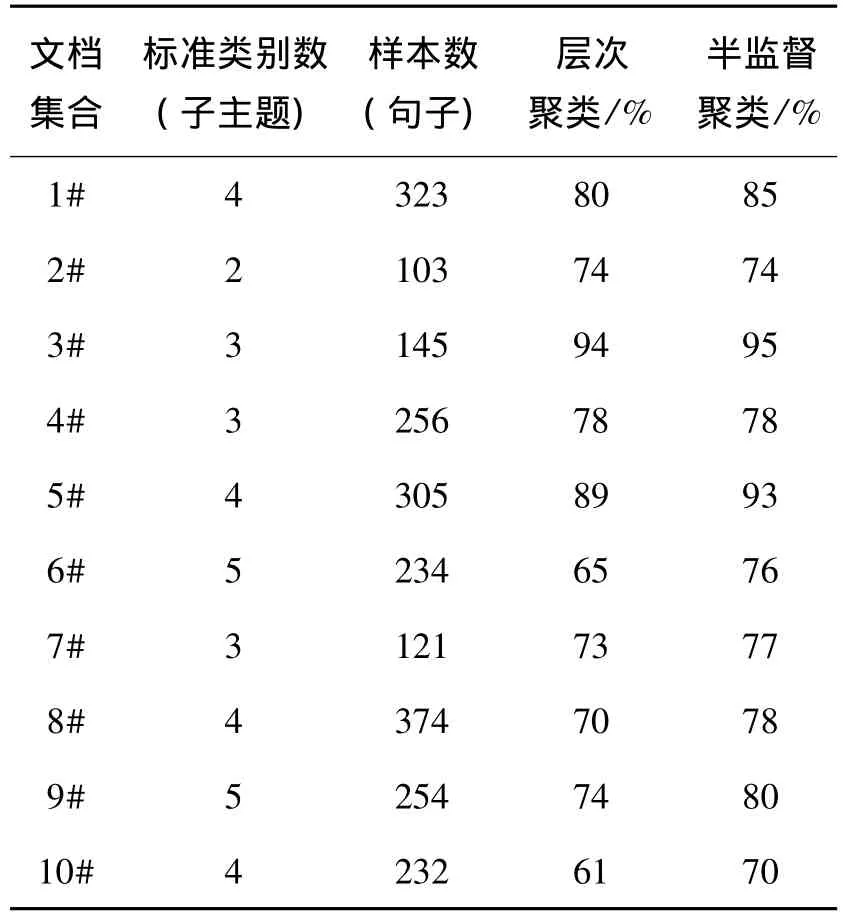
表1 层次聚类法和半监督聚类法的聚类精度
由实验结果可以得到以下结论:
1)使用层次划分的方法对多文档子主题进行识别时,对部分文档不能起到很好的效果.基于层次划分的方法是不可回溯的,一旦某个句子被划分到某个类别后,就不能再发生改变,并且层次聚类的结果需要确定阈值,这个阈值对聚类的结果有很大的影响,这就需要用户对划分对象有一定的了解.
2)本文提出的半监督学习的方法可根据数据本身的特点动态地确定子主题的数目,因此可以相对精确地得到子主题的个数,从而有效地提高了分类效果.
3)聚类的结果受句子相似度的影响较大.
5 结语
本文论述了一种基于半监督学习的子主题聚类方法,该方法尝试运用半监督的思想处理子主题的类别归属问题,半监督聚类的方法有效地弥补了层次聚类和k-means聚类的不足,能根据数据本身的特点获得最佳的k值,实验结果表明该方法是有效的.在下一步的工作中将在此基础上实现多文档的自动摘要.
[1]Endre B,Paul B K,David J N.A clustering based approach to creating multi-document summaries[C]//The 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New Orleans:ACM SIGIR,2001:34-42.
[2]Radev R,Jing Hongyan,Malgorzata B.Centroid-based summarizaiton of multiple documents:Sentence extraction,utility-based evaluation,and user studies[C]//ANLP/NAACL 2000 Workshop on Summarization.Seattle:Association for Computational Linguist,2000:21-29.
[3]秦兵,刘挺,陈尚林,等.多文档文摘中句子优化选择方法研究[J].计算机研究与发展,2006,43(6):1129-1134
[4]Zhu Xiaojin.Semi-supervised learning literature survey[R].Madison:University of Wisconsin,2008.
[5]李昆仑,曹铮,曹丽苹,等.半监督聚类的若干新进展[J].模式识别与人工智能,2009,22(5):735-741
[6]Mac Q J.Some methods for classification and analysis of multivariate observations[C]∥Proc of the 5th Berkeley Symp on Mathematical Statistics and Prohability.Berkeley:University of Califfornia Press,1967:281-297.
[7]Klein D,Kamvar S D,Manning C.From instance-level constraints to space-level constraints:Making the most of prior knowledge in data clustering[C]//Proc of the 19th International Conference on Machine Learning.Sydney:International Machine Learning Society,2002:307-314.
[8]Basu S,Baneoee A,Moonev R J.Semi-supervised clustering by seeding[C]∥Proc of the 19th International Conference on Machine Learning.Sydney:International Machine Learning Society,2002:19-26.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2019年6期)2019-10-08
电脑爱好者(2017年7期)2017-05-06
雷达学报(2017年6期)2017-03-26
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
互联网天地(2016年1期)2016-05-04
长江学术(2016年4期)2016-03-11
