
基于分词的语句相似度计算的改进
2011-07-25 10:38邸书灵刘晓飞
石家庄铁道大学学报(自然科学版) 2011年4期
邸书灵, 刘晓飞, 李 欢
(1.石家庄铁道大学信息科学与技术学院,河北石家庄050043;2.河北联合大学现代教育技术中心,河北唐山063009)
0 引言
语句相似度计算是自然语言处理领域中比较重要的研究课题,应用广泛。语句相似度是指两个语句相似的程度,即通过一定的算法从信息库中查找与指定句子相似的句子,得到满足用户需求的句子。语句相似度计算主要应用于FAQ系统、信息检索和翻译等方面。
目前有很多计算语句相似度计算的算法,如词形词序综合法[1-4]、语义依存树法[5-6]、编辑距离法[1]和基于关键词的TFIDF法[7]、语义词典法[8]等,这些方法各有优缺点而且仍在不断发展完善。
介绍了词形词序综合法的语句相似度计算算法,它将句子分割成多个短语,消除了局部的次序变化带来的影响,该方法还可保证当一个句子的分句或短语整体发生长距离移动后,仍与原句很相似,而众多短语中关键词的直接匹配,使得词形相似度计算更加准确。但是该方法对分词的依赖性很高,往往分词的质量决定了计算结果的准确性,由于目前的分词算法和系统在歧义处理和未登录词识别方面进展缓慢,致使分词具有很大约束性,算法准度不高,针对基于分词的词形词序综合法相似度计算的缺点对该算法进行了改进。
1 词形词序综合法
词形词序综合法有三部分组成:词形相似度、词序相似度和句长相似度。考虑到在两个句子比较时,根据词形、词序和句长各自对整个相似度计算的贡献,词形相似度起主要作用,句长相似度次要作用,而词序相似度作用最小。
1.1 词形相似度
词形相似度方法是通过计算两个问句的词形即相同词的个数来比较相似度的[1]。首先将两个句子分词,用s1Arr和s2Arr两个数组分别存放两句子分词后的单词,然后在计算出两个句子共同包含的单词个数sum,若共有单词出现次数不相同则取最小出现次数。Len(s1)表示s1分词后的词语数。词形相似度计算公式如下
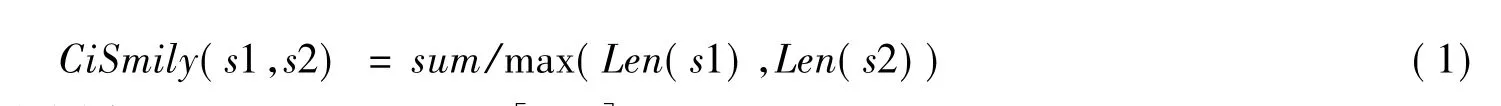
可以看出词形相似度数值范围为CiSmily(s1,s2)∈[0,1]。
例如:s1:“二维的数组有哪些存储方式”,s2:“二维的数组存储方式”。分词后得到:s1Arr={二维,的,数组,有,哪些,存储方式},s2Arr={二维,的,数组,存储方式}。CiSmily(s1,s2)=4/6≈0.667。
1.2 计算句长相似度
两个句子长度越接近就越相似。计算句长相似度采用句子的所有单字的总数,而非分词后词的总数,这样避免了,因使用分词后的词总数而忽略有些词所含单字较多的情况。
句长相似度计算公式,s1L和s2L分别是句子s1和s2所含单字个数
句长相似度的数值范围LenSimly(s1,s2)∈[0,1]。
因此,可以计算出s1:“二维的数组有哪些存储方式”,s2:“二维的数组存储方式”这这两个句子的相似度为LenSimly(s1,s2)=18/21≈0.857。由于两句长度很接近,故长度相似度较高。
1.3 计算词序相似度
共有单词在两个句子中所处位置信息能很好反应句子之间的相似程度。首先计算出s1和s2中都出现且只出现一次的词的集合onews。然后计算出onews中各个词语依次出现在s2中的位置向量,计算出逆序数count。仍然使用同一个例子,可得onews={二维,的,数组,存储方式}。s1中与onews中词对应关系
二维的数组有哪些存储方式
0 1 2 3 4 5
s1的位置向量为{0,1,2,5}。同理可得s2中与onews中词对应关系
二维的数组存储方式
0 1 2 5
s2的位置向量为{0,1,2,5},由于0<1,1<2,2<5不存在逆序,可得逆序数count=0。词序相似度计算公式
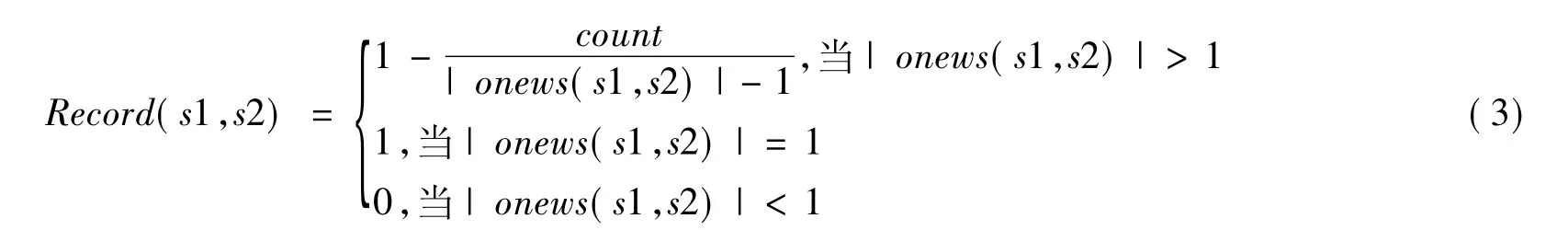
容易得出词序相似度的数值也在Record(s1,s2)∈[0,1]之间。
因此,s1和s2两个句子的词序相似度为:Record(s1,s2)=1。即onews中的词语在两个句子中的顺序完全相同。若Record(s1,s2)=0,说明顺序完全相反。
1.4 语句相似度
语句相似度

式中,λ1,λ2,λ3均为常数,且λ1+λ2+λ3=1,则Sim(s1,s2)∈[0,1]。
根据词形、句长和词序在相似度计算中所起作用的大小,给三个常数赋值,可设λ1远大于另外两个常数,λ1=0.8,λ2=0.15,λ3=0.05。
最终得到s1:“二维的数组有哪些存储方式”,s2:“二维的数组存储方式”两个句子相似度Sim(s1,s2)=0.8*0.667+0.15*0.857+0.05*1≈0.712。
2 存在的问题及改进
词形词序综合法因其容易理解及易于实现,而且其计算结果能达到人们的一半要求,在实际应用中有一定的优势。
但是上述相似度计算方法仍有局限性。该相似度计算方法,对分词的依赖性很强,例如:要比较的是“哈夫曼”和“哈夫曼树”,假如词库中(你也可以使用其他非基于词典词库的分词方法)有“哈夫曼树”但是无“哈夫曼”时,第一句就会分成{哈,夫,曼},而第二句分词后是{哈夫曼树},按照上述算法,这两句的词形相似度为0,总的相似度仅为0.129。这显然不符合实际。因此,需要对以上方法进行改进。
改进的方法是,增加计算两个句子不分词的词形相似度计算,来平衡分词后对相似度计算的影响。即,在式(1)中的sum为两个句子共同包含的单字个数,若共有单字出现次数不相同则取最小出现次数。Len(s1)表示s1中的单字个数。其计算公式不变,单字词形相似度

式(4)中的语句相似度也要更改为
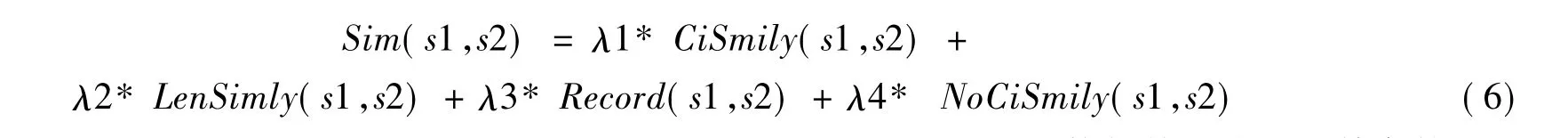
式中,λ1=0.4,λ2=0.15,λ3=0.05,λ4=0.4,λ1+λ2+λ3+λ4=1。使得基于分词和单字的词形相似度计算所占比重相同。经过改进后,“哈夫曼树”和“哈夫曼”的NoCiSmily(s1,s2)=0.75,总相似度为0.429,有了较大提升。
那么,为什么不使用单字的词形相似度计算取代基于分词的词形相似度计算呢?因为单字词形相似度计算也有局限。例如:“多维数组”和“多个二维数组”,因为词库中有“多维数组”,所以基于单字的相似度NoCiSmily(s1,s2)≈0.667,Sim(s1,s2)≈0.653(词序和词长相似度计算不变)说明这两句话相似度很高,但是很显然我们要查“多维数组”,“多个二维数组”就离我们想要的相去较远,因此就要降低它们的相似程度,而使用上述改进的方法CiSmily(s1,s2)=0,Sim(s1,s2)≈0.387。有效的降低了使用单字词形相似度计算造成的较低的查准率。而且从这也可以看出,这样符合语义的要求。
改进后的相似度计算得到的结果更准确也更合理。设置一个阈值作为问句相似的一个条件,当两个问句的相似度高于这个阀值时,就认为这两个问句相似。由于改进的方法是取了两种词形词序相似度的折中,因此总的相似度将会趋于降低,但这并不会影响结果的准确性,只需根据实际情况适当设置阀值即可得到准确结果。而且将此方法应用于上面两种情况下准确性会大大提高。很适合在某一领域的自动问答系统中使用。
3 实验结果分析
本次实验从《数据结构》课程常用问句集中选取16个不同类别,每类有3~4句相似的句子组成,共计50句,并作为样本句,另外依据这些样本句人工构造出50个与样本句相似的句子作为测试集。对测试集中的每句话,分别设计与之相似的语句分别使用改进前和改进后两种方法计算所有句子与其的相似度,并将相似度最大的句子和人工判断出的正确句子做比较,若相同则认为结果正确。实验结果如表1。

表1 实验结果
从实验结果可知,改进的方法的效率明显较高,得益于综合了两种词形相似度计算方法,兼顾了基于分词和基于单字算法的优点,因此一般说来改进前可以得到正确结果的,改进后也可以得到正确结果。但是,考虑到用户在输入时对于一些由多个词复合而成的词语,并不一定能完整输入整个词,可能只是输入这个词语的部分或部分的组合或内部词语词序颠倒,将使得改进前的算法的准确率急剧下降,如:“时间和空间复杂度”和“时空复杂度”,按照改进前的算法(词库中有“空间复杂度”无“时空复杂度”)相似度为Sim(s1,s2)≈0.115,这显然不对,改进后Sim(s1,s2)≈0.365,相对于改进前已经有明显的提升,而这也是改进后算法的优势之一。另外,由于改进前基于分词的缺陷,即:过度依赖于分词,有时会出现难以接受的结果,如:用s1:“动态查找表的表示方法”来搜索与之最相似的句子s2:“动态和静态查找表有哪些表示方法”,两者相似度(词库中有“静态查找表”和“动态查找表”)为Sim(s1,s2)≈0.399;但是s1与s3:“有哪些存储图的方法”的相似度为Sim(s1,s2)≈0.459,这样的结果显然错误,在这点上改进后的算法明显优于改进前,改进后s1与s2的相似度Sim(s1,s2)≈0.524,s1与s3的相似度Sim(s1,s2)≈0.445,显然改进后更合理。基于以上的分析,并从实验中得出,若按相似度由高到低排序输出前N(N≥2)个句子,改进后的结果更准确。
本次实验没有去除停用词,若去除停用词将会使算法的准度和性能进一步提高。
4 结语
基于词形词序的相似度计算改进算法分为四个部分,将四部分数值汇总就可得到两个句子的最终相似度。相对来说,词形词序综合算法易于理解和实现,更重要的是计算结果也可靠。由于词形相似度计算在整个相似度计算中所占比重较大,因此本文对基于分词的相似度计算进行了优化,增加了单字词形相似度计算来降低过分依赖分词带来的不合理计算。另外,可以根据实际情况,灵活改变相似度计算中四个参数的值,来控制各部分在总的相似度中所占的比重。
[1]董自涛,包佃清,马小虎.智能问答系统中问句相似度计算方法[J].武汉理工大学学报:信息与管理工程版,2010,32(1):31-34.
[2]王常亮,滕至阳.语句相似度计算在FAQ中的应用[J].计算机时代,2006(2):24-25.
[3]杨思春.一种改进的句子相似度计算模型[J].电子科技大学学报,2006,35(6):956-959.
[4]李玉红,柴林燕,张琪.结合分词技术与语句相似度的主观题自动判分算法[J].计算机工程与设计,2010,31(11):2663-2666.
[5]车万翔,刘挺,秦兵,等.基于改进编辑距离的中文相似句子检索[J].高技术通讯,2004(7):15-19.
[6]李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研,2002(12):15-17.
[7]秦兵,刘挺,王洋,等.基于常问问题集的中文问答系统研究[J].哈尔滨工业大学学报,2003,35(10):1179-1182.
[8]李素建.基于语义计算的语句相关度研究[J].计算机工程与应用,2002(7):75-76.
猜你喜欢
疯狂英语·初中天地(2021年10期)2021-12-21
邯郸学院学报(2020年2期)2020-08-11
韩国语教学与研究(2020年4期)2020-05-17
孩子(2019年12期)2019-12-27
山东青年(2018年7期)2018-11-06
心理与行为研究(2016年4期)2016-12-16
北方文学·中旬(2016年6期)2016-08-01
中华诗词(2016年11期)2016-07-21
现代语文(2016年21期)2016-05-25
江西教育C(2015年4期)2015-05-25
