
基于区域空间与词汇加权的图像自动标注
2011-05-10 06:27:28李绍滋
天津大学学报(自然科学与工程技术版) 2011年3期
柯 逍,李绍滋
(1. 厦门大学智能科学与技术系,厦门 361005;2. 福建省仿脑智能系统重点实验室,厦门 361005)
基于区域空间与词汇加权的图像自动标注
柯 逍1,2,李绍滋1,2
(1. 厦门大学智能科学与技术系,厦门 361005;2. 福建省仿脑智能系统重点实验室,厦门 361005)
图像自动标注是图像检索与图像理解中重要而又极具挑战性的问题.针对现有模型忽略了图像不同区域对图像整体贡献程度的差异性,提出了基于区域空间加权的标注方法,改善了图像的区域特征生成概率估计.此外,针对现有模型未考虑词汇本身重要性以及词汇分布对标注性能的影响,提出了基于词汇固定权值的标注方法、基于平滑词汇频率的标注方法以及基于词汇 TF-IDF加权的标注方法,对词汇的生成概率估计部分进行了改进.综合以上区域空间改进与词汇改进,提出了 WDVRM 图像标注模型.通过在 Corel数据库进行的实验,验证了 WDVRM 模型的有效性.
图像自动标注;区域加权;词汇加权;相关模型
图像自动标注是指根据图像的视觉内容,由计算机自动产生图像所对应的文本标注信息.图像自动标注对于图像检索很有意义.经过图像自动标注后,用户只需要提交文本关键词进行检索,检索方式相比基于内容的图像检索更加便捷,也更符合大多数用户的搜索习惯.目前商业化的图像搜索引擎,如Google、Yahoo、Baidu等,对图像标注所采用的技术还属于自然语言处理领域,即主要利用网页中图像的上下文信息作为图像的标注,如图像的文件名及URL、ALT标签、锚文本以及图像周围的环绕文本等信息.但这类方法并没有使用图像内部特征,效果也不理想.文中所研究的图像自动标注不同于这些商业化搜索引擎的标注方法,研究主要针对图像的视觉内容产生相应图像的标注,可称为基于内容的图像自动标注.基于内容的图像自动标注对于构建新一代图像搜索引擎具有非常重要的意义.
此外,图像自动标注还属于图像理解的范畴,与人对图像的理解层次相对应,Eakins[1]将图像语义分为3个级别,从低到高依次是视觉特征层、表达层、情感层.其中,视觉特征层包含特征语义,表达层包含对象语义与空间关系语义,情感层包含场景语义、行为语义与情感语义.高的层次通常包含了比低层次更高级更抽象的语义,此外,更高层的语义往往需要通过较低层的语义推理获得.图像自动标注就对应于图像理解中的表达层,主要研究对象语义与空间关系语义.
近年来,图像自动标注领域十分活跃,人们利用统计模型与机器学习方法提出了各种学习模型,建立图像视觉特征与标注关键词之间的关系.2002年,Duygulu等[2]提出了机器翻译模型,将图像自动标注看成是两种语言之间的翻译问题:一种语言由描述图像内容的视觉词汇构成,另一种语言由文本词汇构成.通过Normalized Cut将每幅图像分割为互不重叠的若干区域[3],并对图像中所有区域利用K-Means算法进行聚类,得到视觉词汇类别 blob,图像的标注问题就可以看作是从视觉词汇类别 blob到语义关键词的翻译过程.Monay等[4]提出了LSA模型,通过引入隐变量建立图像特征与关键词的关系.Jeon等[5]提出了跨媒体相关模型 CMRM,利用语义关键字与视觉关键字的联合概率进行标注,采用与机器翻译模型一样的离散特征进行表征区域特征,blob是通过聚类得到,而聚类过程不可避免地带来一定的信息损失.Lavrenko等[6]提出了连续相关模型CRM,它直接利用了图像区域的连续特征值,利用非参数高斯核进行视觉特征生成概率的连续估计.Feng等[7]提出了多伯努利相关模型 MBRM,将图像分割为规则的矩形区域来取代复杂的区域分割算法,同时引入多伯努利分布取代多项式分布来刻画词汇的概率分布.Zhao等[8]提出了TSVM-HMM模型,将判别分类模型(SVM)与生成式模型(HMM)相结合,并选取5%的图像对每个区域进行人工标注,进而提高最终的标注结果.Gustavo等[9]提出了 SML模型,将半监督学习引入图像自动标注中,从而避免了图像的分割过程.Yong等[10]将全局特征、区域特征与上下文特征相结合并应用于扩展的CMRM模型中. Stefanie等[11]利用视觉分众分类(visual folksonomy)思想,对Flickr图像库的部分水果与蔬菜图像进行标注.
各种模型假设各个关键词之间相互独立,并没有考虑词与词之间的关系.而利用词与词之间的相关性可以起到改进标注性能的作用.Jin等[12]提出了CLM 模型,利用 EM 算法计算词与词之间的隐含相关性;TMHD 模型[13]利用 WordNet进行词关系的度量.Liu等[14]提出了 AGAnn模型,对自适应图(adaptive graph)标注的结果应用词与词的相关性进行改善.Kang等[15]提出了互相关标记传播模型CLP,考虑了在相邻的图像之间,利用标记的相关性,同时传播多个标记(每个标记对应一个词汇).
笔者主要针对图像标注模型中的相关模型进行研究,主要包括:针对现有标注模型忽略了图像不同区域对图像整体贡献程度的差异性,提出了基于区域空间加权的标注方法,对图像的区域特征生成概率估计进行了改进.针对现有模型忽略词汇本身重要性以及词汇分布对标注性能的影响,提出了基于词汇固定权值的标注方法、基于平滑词汇频率的标注方法以及基于词汇 TF-IDF (term frequency-inverse document frequency)加权的标注方法,改进了词汇的生成概率估计.综合以上区域空间改进与词汇改进,提出了WDVRM图像标注模型.
1 基于区域空间加权的图像标注
目前的模型都没有考虑图像各个区域在生成概率估计中所起的作用.本节主要针对图像自动标注中的图像区域特征生成概率估计部分进行了研究.
将图像分割成若干个区域有两种方法:①使用图像分割算法,如较新的 Normalized Cut等;②采用固定分块的方法,如将图像分割成若干个固定大小的矩形块.用Normalized Cut分割现在Corel图像库中的图像,会出现大量同一语义对象被分割成不同区域的情况,使得标注性能很难提高.通过实验发现[7],采用固定分块的标注结果比使用分割算法要好得多,固定分块还可以节省分割图像所花费的大量时间,将重点放在如何构造更合理的词汇与图像区域特征生成概率以及更好地刻画词汇与图像之间的关系上.所以采用固定分块的策略,而分块的数目,以及每个块的大小如何选取,上述文章都没有给出解释.
通过对 Corel图像库的研究发现,块大小选取的原则应该是尽可能使得每个块只包含单一目标或物体(即每个块只包含一个语义对象),而又不产生过多相似的块.这就使得分块不能太大,太大的分块会使一个块内可能包含两个甚至两个以上的语义对象,而如果分块取的过小,会出现一幅图像中的相似块太多,使得计算时间大量增加.通过实验发现,对 Corel图像库采用 4×6的固定分块,可以取得很好的效果.通过这种分块策略,每个块刚好都由正方形构成.图 1是采用固定 4×6分块后的结果图,可以发现,绝大多数块的视觉内容都符合上面提出的分块原则,即每个块尽可能地只包含一个语义对象.

图1 固定分块结果Fig.1 Results of fixed blocks
传统的图像标注模型将区域与图像的相似性定义为某个区域与图像中各个区域相似度的平均值.然而,现实情况并非如此,如图像中前景对象区域相比背景区域应该更重要.通过观察大量图像发现,前景目标出现在中间的概率要大于出现在四周的概率,中间区域出现的目标在图像中应该更重要,即中间区域应该赋予更高的权值.也就是说,图像中的每个区域所占的权重不应该都简单地认为相等,而应该对每个区域赋予不同的权重.同时,前景目标区域所占面积一般比背景区域要小不少,如果背景区域与目标区域采用相同的权值,将会使得图像区域特征生成概率偏向背景区域.针对以上结论,提出了基于区域空间加权的图像标注方法.通过实验,选取最佳的24个块权值分配方案,如图2所示.

图2 区域空间权值分配方案Fig.2 Assignment of weighted district space
具体的分配方案为:①中间4个灰色块分配最高的权重 wrs1;②中间块周围的 8个块分配次高的权重;③周围的 8个次黑块分配较低的权重wrs3;④4个角上的黑色块分配最低的权重 wrs4.如何确定各个块的具体加权值将在后面的实验部分给出.
2 基于词汇加权的图像标注
CLM、TMHD、AGAnn等模型取消了估计词汇生成概率时各个关键词之间相互独立的假设,利用词与词之间的相关性起到改进标注结果的作用.然而,这些模型主要考虑词与词之间的关系,并没有考虑不同关键词的重要程度不同,以及词频与词汇分布给图像标注性能带来的影响.本节针对图像自动标注中的词汇生成概率估计部分进行了较为深入的研究.
2.1 基于词汇固定权值的标注方法
通过观察目前普遍使用的用于评测图像标注性能的Corel,5000图像库可以发现,图像的标注词存在着诸多问题:①词汇的语义层次问题,如既有“tiger”、“bear”、“lion”等具体的动物,也有 “animal”这样的动物总称,而且 “tiger”、“bear”、“lion” 等与“animal” 往往不会同时出现在一幅图像中;②复合名字问题,如狮子鱼 “lionfish”,在标注时写成了 “lion”与 “fish”两个词,这给图像标注带来了极大的困难;③词汇的抽象性问题,如标注词汇大量出现诸如“city”、“school”、“autumn” 等无法与图像区域相对应的词汇,即对于标注无具体意义的抽象性词汇.这些问题产生的可能原因是 Corel,5000图像库是由不同人所标注的.
除了上述问题,图像中不同区域对图像的贡献程度不同,而通过观察图像所对应的标注词集合也可以发现类似的情况.不同词汇对于标注的贡献程度是不同的,图像所对应标注的前景目标如 “tiger”、“plane” 等较一些背景目标如 “sky”、“lake” 等更为重要,同时一些无法与图像区域相对应的标注词对标注是没有任何贡献的,反而还会影响到整体的词汇生成概率分布.此外,图像中的背景区域一般比较大,会占用较多的图像块,而前景目标往往只占用较少的块,所以如果不对前景与背景词汇进行区分,会造成图像的标注结果中背景词汇的生成概率大大超过前景词汇的生产概率,使得标注结果都偏向于背景词汇,对标注结果产生影响.据了解,目前的各种模型都没有针对以上角度进行研究.从自然语言处理领域的命名实体研究得到启发,提出了基于词汇固定权值的标注方法.将所有标注词分为 5类:① 无歧义的前景词,如 “tiger”、“plane”、“cars”等;②有歧义的前景词,如 “plant”、“animals”、“paintings”等;③无歧义的背景词,如 “mountain”、“sky”、“desert”等;④歧义的背景词,如 “water”、“ground”、“night”等;⑤抽象词汇,如 “city”、“outside”、“school”等.这 5 类词汇在计算词汇生成概率时将赋予不同的权重,权重从无歧义的前景词到抽象词汇按从高到低赋予具体的权值,分别记作fw+、fw-、bw+、bw-、aaw ,具体的权值分配方案将在后面的实验部分给出.
2.2 基于平滑词汇频率的标注方法
通过观察 Corel 5000图像库的标注结果可以发现,不同词汇出现的次数差异很大.图 3为 Corel 5000图像库中对所有374个标注词出现次数进行的统计.可以发现,它们符合 Zipf分布的特点[16].其中,出现次数超过100次的词仅有44个,超过50次的词只有81个,超过20次的词有149个,超过10次的词有217个,也就是说大约42%的词出现次数不超过10次,约24%的词出现次数不超过5次.
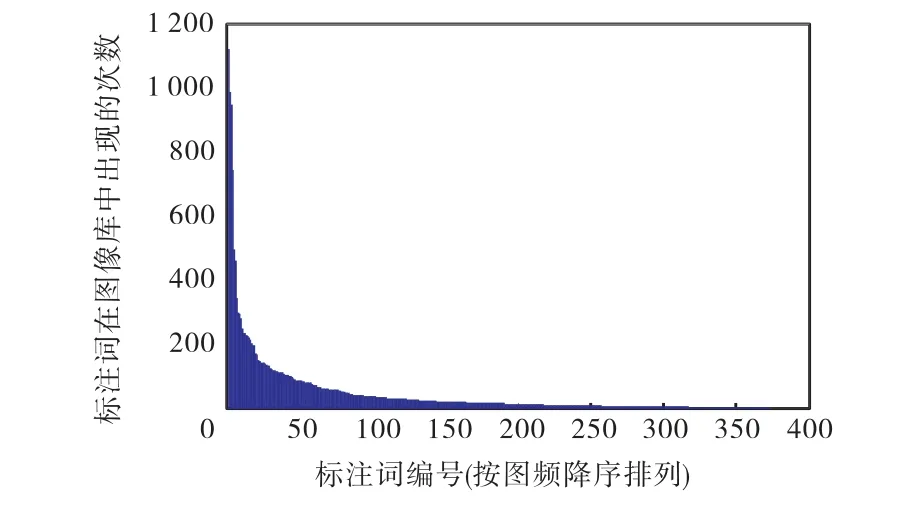
图3 Corel 5000图像库中标注词出现的次数统计Fig.3 Annotation words’ frequencies in Corel 5000 library
通过分析可知,有 40%以上的标注词对应相当少的图像,训练这些标注词是相当困难的.此外,出现次数较多的那些词大部分是背景词,而出现次数较少的那些词往往是更需要的前景词.图像自动标注的任务是同时对图像中的前景与背景进行标注,并没有评估是否标注出更多的前景词,但是当用户主观地评价标注结果好坏时,总是更关心是否有更多的前景词汇被标注出来.目前的各类模型都没有考虑词频以及词汇分布对词汇生成概率产生的影响,如果可以提高那些大量出现的次数较少词的标注结果,将会对系统的整体性能产生很大的影响.针对这种情况,提出了基于平滑词汇频率的标注方法,其基本思想是:对于那些出现次数较多的背景词赋予较低的权重,而出现次数较少的前景词赋予较高的权重,通过对词汇进行加权起到平滑词频对词汇生成概率产生的影响,提升那些大量的出现次数较少词的标注结果,进而提升整体标注性能.
由于所有标注词的出现次数大致符合 Zipf分布,即每个标注词出现次数ivN 与这个标注词出现次数排名iR存在反比关系,即

式中μ和θ均为反比例函数的参数,具体参数值可通过最小二乘法来确定.经过对数变换,式(1)可以转换成

vi在图像库中出现的总次数排名.
2.3 基于词汇TF-IDF的标注方法
针对如何确定某幅图像中最重要的词,即从如何确定对某幅图像最富有“信息量”的词出发,提出基于词汇TF-IDF的标注方法.TF-IDF[17]是自然语言处理领域中常用的方法,在文本分类与文本聚类中使用相当广泛.其基本思想是:如果某个词或短语在某一篇文章中出现的频率很高,同时在其他文章中出现的次数较少,则认为该词或者短语具有很好的类别区分能力,适合用来分类.
把 TF-IDF用于图像自动标注中,将词汇的生成概率与TF-IDF相结合.其中,这里的词条频率fTF为某个词在某幅图像中出现的频率,逆文档频率 fIDF则反映该词汇在所有图像中普遍重要性的度量,即如果某个词在某幅图像中出现,且这个词在其他图像中出现的次数较少,则认为该词对于那幅图像具有很好的语义区分能力,也就是上面提到的该词对于某幅图像富有“信息量”;相反地,如果该词在其他图像中出现的次数较多,则这个词很可能是背景或普遍性词汇,也就是不具备良好的语义区分性.
基于词汇TF-IDF的权值计算公式为
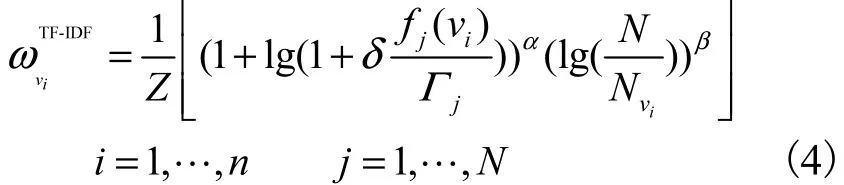
3 WDVRM图像标注模型
本节将介绍提出的结合区域空间加权与词汇加权的图像自动标注模型(weighted district and vocabulary relevance model,WDVRM).该模型基于多伯努利相关模型(multiple Bernoulli relevance models,MBRM),MBRM 模型在图像自动标注领域已经被证明为一个非常成功的模型.对其进行改进,加入了基于区域空间加权的图像区域特征生成概率改进,以及基于词汇加权的词汇生成概率改进.
MBRM 模型属于图像自动标注模型中的相关模型.特征表示采用了图像区域的连续特征值,MBRM模型相比以往模型有两个重大改进:①将图像分割为规则的矩形区域来取代复杂的图像分割算法,在提高标注准确率的同时降低了模型的时间复杂度;②引入多伯努利分布取代了以往模型中使用的多项式分布,通过多伯努利分布来对词汇的概率分布进行建模.
3.1 WDVRM模型
每幅图像I表示为一系列互不重叠的区域集合,DI={d1,… ,dΘ||},这里采用固定分块方法,|Θ|为区域的个数.对每个图像区域 di提取 m维的特征向量Fi,定义图像区域的视觉生成概率为 P (~|I ).词汇F生成概率采用了多伯努利分布,多伯努利分布相比多项式分布式是一个更合理的词汇描述方式,其具体优点可以参见文献[7].假设标注词集合 WI是从|V|个多伯努利分布 PV(~|I)独立采样的结果,其中|V|为标注词个数.一幅图像I的产生就可以由区域特征生成概率与词汇生成概率这两个独立的条件分布构成.
假设图像 G为训练图像库以外的一幅图像,G的特征向量可以表示为 FG={FG1, … ,FG|Θ|},其中FiG为图像G中第i个区域的特征向量.WT为所有标注词汇 |V| 的一个子集.对图像 G的视觉表示与词汇表示的联合概率进行建模,记为 P ( FG, WT).假设联合概率 P ( FG, WT)中,FG与 WT的隐含关系与训练图像集中某幅图像的视觉特征与词汇的隐含关系相似,而这个具体的隐含关系无法得知,所以针对训练集中的每一幅图像都计算其视觉特征与词汇联合概率的期望.联合产生 FG与 WT概率的过程有4个步骤.
(1) 按照概率 PΩ(I)从训练集Ω选取一幅训练图像I.
(2) 对 i = 1,… ,n ′(n′为图像区域个数):①按照条件概率密度函数 PFI(~|I)生成第 i个区域的视觉特征Fi;②利用第 1节提出的算法对 FiI进行区域空间加权.
(3) 按照多伯努利分布 PV(~|I)生成词汇集合WI.
(4) 利用第2节提出的3种算法对 WI进行词汇加权.
这里每幅图像的标注词个数与图像区域的个数不存在一对一的关系,只是寻找对于整幅图像最适合的若干个标注词.根据上面的概率生成过程,WDVRM 模型中图像视觉表示与词汇标注的联合概率为
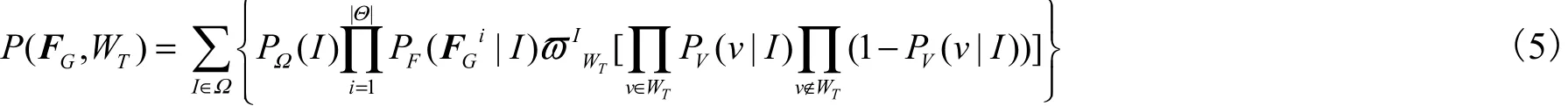
式中ϖI为对词汇加权的权值.WDVRM 模型利用WT式(5)进行图像标注,具体流程为:给定一个未标注图像G,利用固定分块方法将它分为|Θ|个区域,提取每个区域特征 FGi,利用式(5)确定最可能与这些特征向量集合同时出现的词汇子集,作为该图像的标注.
与其他模型类似,在实现的时候,将词汇子集的长度固定为 5.然而在一个较大的词汇集合内,即便对每幅图像只取5个标注词,所出现的组合数仍然很多,几乎是不可计算的.幸运的是每个词在每幅图像中或者不出现,或者只出现 1次,这样就可以假设词汇间是相互独立的,进而对式(5)进行简化,即
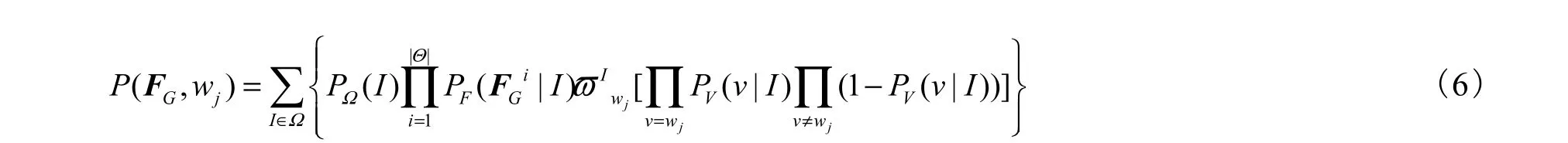
式中 wj为标注词集合内的某一个词,对每个词分别计算它与测试图像出现的联合概率,取联合概率最大的若干个词作为该图像的标注.
3.2 参数估计
主要讨论对式(6)的参数估计问题.PΩ(I)是图像I在训练图像库中出现的概率,由于没有任何的先验知识,所以假设 PΩ(I)服从均匀分布,即 PΩ(I)=1/|Ω|,其中|Ω|为训练图像的数目.
条件概率密度函数 PF( ~|I)是用来生成区域的视觉特征向量 F1,… ,F|Θ|,对PF( ~|I)的分布使用非参数核密度函数进行估计,PF( ~|I)的估计为
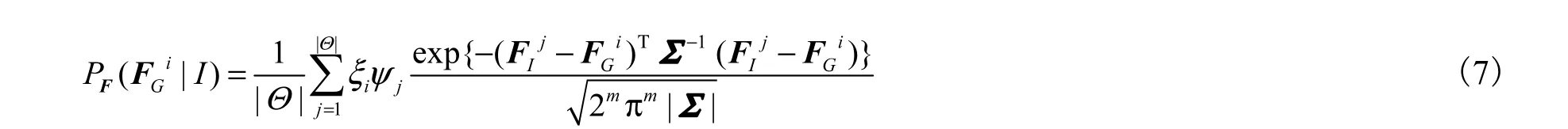
式中:m为特征的维数;|Θ|为图像区域的个数;ξi是测试图像G对第i个位置的区域空间加权;ψj是训练图像 I对第 j个位置的区域空间加权.式(7)对图像 I的每个区域特征 Fj都采用高斯核函数进行估计.高斯核的参数由特征协方差矩阵Σ来确定,Σ = αΛ,其中α为高斯核的宽度,确定P在 FiI附近的平滑程度,Λ为单位矩阵.
PV(v|I)是多伯努利分布的第v个元素,为训练图像库中某幅图像 I产生标注 WI的概率.对每个词采用贝叶斯估计

式中λ1、λ2、λ3分别为基于词汇固定权值、基于平滑词汇频率与基于词汇 TF-IDF 3种方法的加权值.对3种方法加权可以综合这 3种方法的优势:词汇固定权值的改进主要针对词汇本身的重要程度,平滑词汇频率的改进主要针对词汇出现次数,避免词汇生成概率偏向出现次数多的词,词汇 TF-IDF的改进重点是针对词汇的重要性与区分度.
4 实验结果与分析
4.1 实验建立
为了验证提出方法与模型的有效性,并同其他模型进行公平比较,实验采用了图像自动标注中普遍使用的 Corel 数据集.这个图像库是由 50个 Corel Stock Photo文件夹组成的5,000张图片.每个文件夹包含 100张相同主题的图片,其涵盖了丰富的内容,包括风景、动物、植物、国家、城市、建筑、历史文物、人物、交通工具等.每幅图像有 1~5个词作为其标注,词汇总数量为 374.将数据集分为 3个部分:①训练集 4,000幅图像;②验证集 500幅图像;③测试集500幅图像.其中,验证集包括每个文件夹下的10幅图像,主要用于模型参数的确定,待参数确定以后,将验证集全部加到训练集中形成新的训练集.这样就与其他模型采用的 4,500幅训练图像、500幅测试图像相一致,每幅图像固定返回5个标注词.
每幅图像按照这种提出的分块方法,分为 6×4=24个块,需要对每个块都计算其底层特征.本文的主要工作在于新模型的建立,所以并没有使用一些较新的特征,为了便于比较,采用了与 MBRM 相同的 30维特征,具体包括:9维的 RGB空间颜色矩;9维的Lab空间颜色矩;12维的Gabor纹理特征,包括3个尺度与4个方向.
与其他的模型一样,采用单个词的查准率、查全率与 F度量来评估标注结果.假设某一个关键词为w,cN为标注正确的图像数,sN为检索返回的图像数,tN为测试图像库中包含标注词w的图像数,则

对所有出现在测试集中的关键词都计算以上 3个指标,最后把得到每个词的查准率、查全率以及 F度量取平均作为最终的评价指标.此外,与很多模型类似,实验还统计了至少被正确标注一次的关键词数量,记作 “NZR”.它反映了模型对标注词汇的覆盖程度,是一个很重要的标注性能评价指标.
4.2 性能比较
4.2.1 参数设置
通过在验证集与测试集上进行大量实验,实验部分采用的具体参数值为:

4.2.2 实验结果与分析
首先分别验证只使用基于区域空间加权的方法(记作 WDRM)与只使用基于词汇加权的方法,其中WVRM(Fix)表示只使用词汇固定权值的方法,WVRM(Freq)表示只使用平滑词汇频率的方法,WVRM(TF-IDF)表示只使用词汇 TF-IDF的方法,WVRM(Combined)表示将 3种词汇加权方法进行组合.与MBRM模型进行对比,结果如表1所示.
从表1可以看出,基于区域空间加权的方法有效地改善了图像视觉生成概率,除了查准率比 MBRM稍低,其余3项指标都比MBRM模型要高,但是提升的幅度还不明显.3种基于词汇加权的方法也都是有效的,尤其体现在查全率和NZR这两个指标上,除了基于词汇固定权值的方法以外,另外两种词汇加权方法以及结合3种词汇加权的方法在查全率和NZR指标上相比MBRM均有明显提高.
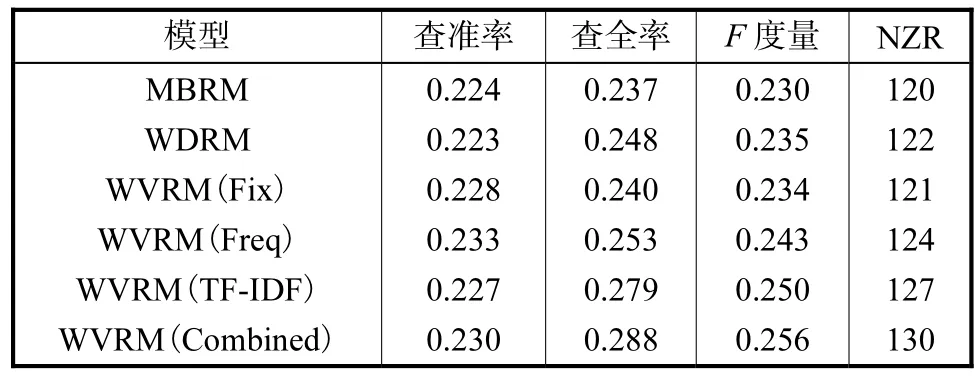
表1 使用区域空间加权与使用词汇加权的对比Tab.1 Comparison between methods of weighted district and weighted vocabulary
下面的实验主要用于验证结合区域空间加权与3种词汇加权方法的模型,实验都加入了基于区域空间加权的方法,分别计算每一种词汇加权方法的标注结果以及 3种方法组合的结果,将提出的 WDVRM模型与现在常见的模型进行对比,包括 TM、CRM、MBRM、CLM、GLM[18]、CLP.实验结果如表 2 所示,在表2中WDVRM(Fix)表示采用词汇固定权值的方法,WDVRM(Freq)表示采用平滑词汇频率的方法,WDVRM(TF-IDF)表示采用词汇 TF-IDF的方法,WDVRM(Combined)表示将上面 3种方法进行组合.
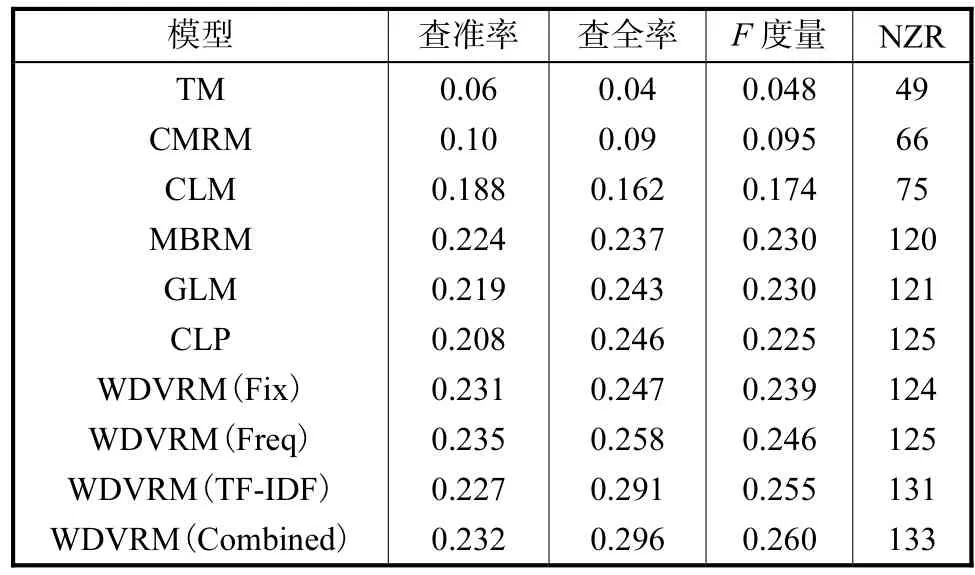
表2 各模型性能比较Tab.2 Comparison of different models’ performances
从表 2可以看出,3种词汇加权方法以及将这 3种方法进行组合都是有效的,各项评价指标基本上都比进行现在流行的几种模型要好.查准率最高的是采用基于词汇平滑的方法,达到了 0.235.最后一组实验综合了3种词汇加权方法,除了查准率以外的另3个指标都是最高的:查全率高达 0.296,比前面模型中查全率最高的 CLP模型要高出 20%;F度量达到0.260,比前面模型中 F度量最高的 MBRM 与 GLM要高出 13%.此外,在至少被正确标注出一次的关键词数 “NZR”这个评价指标上,WDVRM 模型达到了133,比前面模型也提高了不少.
表 2中最后两个方法的查全率以及至少被正确标注一次的关键词数目相比前面各模型有了较大的提高,即通过对词汇进行 TF-IDF加权可以大大优化词汇的生成概率,提高标注词的覆盖程度.采用固定分块的模型效果要好于采用图像分割的模型,比如MBRM与 WDVRM的总体效果要好于 TM、CMRM、CLM 等模型.一个原因是分割算法产生的分割错误会随着计算图像的视觉生成概率而一直传播,而固定分块则不会;此外,采用连续特征的模型(如 WDVRM 与 MBRM 模型)效果要好于离散特征模型(如 TM、CMRM、CLM、GLM 等模型),即连续特征可以更好地估计图像区域特征间的关系,避免聚类blob过程时带来有用信息的损失.
WDVRM 标注模型性能的提升不仅仅表现在各项评价指标的提高,模型的标注结果相比其他模型包含了更多的前景词以及对图像贡献较大、人们更关心的词汇.这方面的改进并不能在现有的评价体系中体现,所以选取了几幅比较有代表性的图像与MBRM 标注结果进行了对比,每个标注词的顺序是按照概率从大到小排列,如表3所示.
通过表3可以发现,相比MBRM模型,前两幅图WDVRM 模型分别多正确标注出了 “bengal”与“windmills”.而如果将这几幅图一起对比,可以很明显地发现,MBRM 方法的背景词大多排在前景词之前,而 WDVRM 模型则很好地突出了图像的目标与重点,模型赋予更高的概率给这些重点词.通过对比,再次验证了 WDVRM 模型对图像区域特征生成概率估计与词汇生成概率估计的改进是有效的.
5 结 语
传统的相关模型中区域与图像的相似性定义为区域与图像中所有区域相似性的平均,并没有考虑到图像中的不同区域对整体相似性的贡献程度不同,为此提出了基于区域空间加权的标注策略,改善了图像区域的视觉生成概率;另一方面,现有的模型都没有考虑词汇本身重要性以及词汇分布对标注性能的影响.因此,提出了基于词汇固定权值的标注策略、基于平滑词汇频率的标注策略以及基于词汇TF-IDF加权的标注策略对词汇生成概率估计部分进行了改进.通过在 Corel数据库上进行的实验表明,WDVRM 模型使得标注性能有了明显提高.下一步的研究工作可通过引入 WordNet,将词汇间的关系与现有的模型相结合.将图像自动标注应用到图像检索中,构建新一代的图像检索系统.此外,还可以考虑对视频进行标注.
[1]Eakins J P. Automatic image content retrieval-are we getting anywhere[C]//Proceedings of Third International Conference on Electronic Library and Visual Information Research.Cambridge,UK,1996:123-135.
[2]Duygulu P,Barnard K,Freitas J,et al. Object recognition as machine translation:Learning a lexicon for a fixed image vocabulary[C]//Proceedings of the 7th European Conference on Computer Vision. Copenhagen,Denmark,2002:97-112.
[3]Shi J,Malik J. Normalized cuts and image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(8):888-905.
[4]Monay F,Gatica-Perez D. On image auto-annotation with latent space models[C]//Proceedings of the ACM International Conference on Multimedia.Berkeley,USA,2003:275-278.
[5]Jeon J,Lavrenko V,Manmatha R. Automatic image annotation and retrieval using cross-media relevance models[C]//Proceedings of the 26th Annual InternationalACM SIGIR. Toronto,Canada,2003:119-126.
[6]Lavrenko V,Manmatha R,Jeon J. A model for learning the semantics of pictures[C]//Proceedings of Advance in Neutral Information Processing.Vancouver/Whistler,Canada,2003.
[7]Feng S L,Manmatha R,Lavrenko V. Multiple Bernoulli relevance models for image and video annotation[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington,USA,2004:1002-1009.
[8]Zhao Yufeng,Zhao Yao,Zhu Zhenfeng. TSVM-HMM:Transductive SVM based hidden Markov model for automatic image annotation[J].Expert Systems with Applications,2009,36(6):9813-9818.
[9]Gustavo C,Antoni B C,Pedro J M, et al. Supervised learning of semantic classes for image annotation and retrieval[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007,29(3):394-410.
[10]Wang Yong,Mei Tao,Gong Shaogang,et al.Combining global,regional and contextual features for automatic image annotation[J].Pattern Recognition,2009,42:259-266.
[11]Stefanie L,Roland M,Robert S,et al. Automatic image annotation using visual content and folksonomies[J].Multimedia Tools and Applications,2009,42:97-113.
[12]Jin Rong,Chai Joyce Y,Si Luo. Effective automatic image annotation via a coherent language model and active learning[C]//Proceedings of the 12th Annual ACM International Conference on Multimedia. New York,USA,2004:892-899.
[13]Jin Y,Khan L,Wang L,et al. Image annotation by combining multiple evidence and WordNet[C]//Proceedings of the 13th Annual ACM International Conference on Multimedia. Hilton,Singapore,2005:706-715.
[14]Liu Jing,Li Mingjing,Ma Weiying,et al. An adaptive graph model for automatic image annotation[C]// Proceedings of the ACM SIGMM Workshop on Multimedia Information Retrieval.Santa Barbara,USA,2006:61-69.[15]Kang Feng,Jin Rong,Sukthankar R. Correlated label propagation with application to multi-label learning[C]//Proceedings of the 2006IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York,USA,2006:1719-1726.
[16]Alex S,Yannick M,Didier S. Theory of Zipf's Law and Beyond[M]. Berlin:Springer-Verlag,2009.
[17]Wu Ho Chang,Luk Robert Wing Pong,Wong Kui Lam,et al. Interpreting TF-IDF term weights as making relevance decisions[J].ACM Transactions on Information Systems,2008,26(3):1-37.
[18]Tong Hanghang,He Jingrui,Li Mingjing,et al. Graph based multi-modality learning[C]//Proceedings of the 13th Annual ACM International Conference on Multimedia. Hilton,Singapore,2005:862-871.
Image Automatic Annotation Based on Weighted District Space and Vocabulary
KE Xiao1,2, LI Shao-zi1,2
(1. Department of Cognitive Science,Xiamen University,Xiamen 361005,China;2. Fujian Key Laboratory of the Brain-Like Intelligent System,Xiamen 361005,China)
Image automatic annotation is a significant and challenging problem in image retrieval and image understanding. Existing models ignored that different regions of images had different contributions to the overall images. So an annotation method based on weighted district space to improve the generation probability estimation of regional features of the images was proposed. On the other hand, existing model did not take into account the importance of vocabulary as well as vocabulary distribution which impacted the annotation performance. Three methods to overcome the above problems were proposed, including: fixed vocabulary weight method, smooth vocabulary frequency method and weighted vocabulary’s TF-IDF method. These methods can improve the generation probability estimation of vocabulary. By integrating all above improved methods of weighted district space and weighted vocabulary, WDVRM image annotation model were proposed. Experiments conducted on Corel datasets have verified that the WDVRM model is quite effective.
image automatic annotation;weighted district;weighted vocabulary;relevance model
TP391
A
0493-2137(2011)03-0248-09
2009-11-27;
2010-06-03.
国家自然科学基金资助项目(60873179,60803078);高等学校博士学科点专项科研基金资助项目(20090121110032);深圳市科技计划基础研究基金资助项目(JC200903180630A).
柯 逍(1983— ),男,博士研究生,kevinkexiao@163.com.
李绍滋,szli@xmu.edu.cn.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
开放教育研究(2020年2期)2020-03-31 01:54:14
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
自动化学报(2017年7期)2017-04-18 13:41:02
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
现代语文(2016年21期)2016-05-25 13:13:44
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
