
网页数据抽取中W rapper的维护
2011-04-20 07:27邓莎莎李嘉
上海电力大学学报 2011年4期
邓莎莎,李嘉
(1.上海电力学院计算机与信息工程学院,上海200090; 2.华东理工大学商学院,上海 200237)
随着Internet及其相关技术的飞速发展,Web正在逐渐成为全球的自主分布式计算环境.然而,由于Web上的数据绝大多数是通过HTML语言来显示的,而HTML语言的特点是任何组织或个人可以很随意地在Web上发布内容多样、形式各异的信息,导致Web上的数据处于杂乱无序的状态,数据集成性非常差[1].面对内容庞杂,动态变化的Web信息资源,人们很可能身陷信息的海洋而无所适从.
因此,网页数据抽取越来越受到重视.但网络数据的内容和表现形式动态多变的特性往往增加了网页数据抽取的难度.目前,网页抽取多采用W rapper/Mediator方法.该方法会对某个网页数据源产生单独的W rapper,若网页结构进行微小改变后,往往需要重新构建一个新的W rapper,这样会加大W rapper的产生成本.本文着重讨论基于规则树的网页数据抽取W rapper的方法,当网页结构发生小范围变化后,W rapper自动识别这些变化并自动修改规则,使其仍可以继续工作,从而提高W rapper的自适应性.
1 W rapper维护的研究现状
关于Web数据的抽取问题,比较流行的方法是W rapper/Mediator的方法.该方法并不是将各种数据源的数据集中存放,而是通过W rapper/ Mediator这一体系结构来满足上层对数据的需求.其核心是通过中介模式将各个数据源的数据集成起来,而数据仍然存储在局部的数据源中.它是通过W rapper对数据源的数据进行转换使之符合中介模式,这样就能很好地解决数据仓库方法中存在的数据更新问题.但由于各个数据源的W rapper需要分别建立,因此Web数据源的W rapper维护成为又一难点.
KUSHMERICK[2]提出W rapper维护中的一个子问题——W r a p p e r验证,根据已知的正确结果来分析抽取结果并判断其正确性,从而达到验证的目的.文献[3]通过回归测试及一个给定的阈值来检测页面的变化,一旦发现页面变化则通知设计人员,再由设计人员从新的格式中重新学习获得新的W rapper.
KNOBLOCK等人[4]对页面的微小HTML标识变化给出一种W rapper修复的方法.首先提出了W rapper的生命周期概念,以及如何确保正确可靠地抽取数据的方法.通过机器学习得到所要抽取字段的数据模式的统计分布.W rapper就可以通过比较返回数据模式和统计分布的模式来验证.当发现有显著不同时,系统就会发出通知或者自动调用修复程序.
CHIDLOVSKII[5]提出了基于上下文的自动修复W rapper方法.在修复过程中,采用了一个分类机制,将语法特征和内容特征作为分类的标准,对多页面实行多种分类和多遍扫描,最终得出结论.该方法是建立在微小变化的假设前提下,因此比前面几种方法有优势.
2 研究假设
由于网页数据是复杂多变的,因此本研究基于以下3点假设:
(1)当用户从Web上收集数据时,应很清楚自身的需求,因此无需对HTML文档中全部数据进行抽取,只抽取对用户有用的数据;
(2)W rapper生成的最终目的是将源数据转换成某些易于处理的结构,并不是理解源数据的语义;
(3)当Web页面发生变化后,认为仍保留了一些原有数据项特征,例如元数据、数据类型、抽取模式.
3 基于规则树的W rapper维护结构设计
本文讨论的W rapper维护是基于已构建的基于规则树的Web数据抽取方法,因此有必要简单介绍该方法是如何构建W rapper的.首先,用户使用DTD或者XML Schema定义一个HTML文档的抽取模式;接着,用户在交互界面中将HTML页面上的数据例子和模式中的元素关联起来,建立映射规则;最后,依据用户给出的映射规则生成规则树并生成W rapper.
W rapper建立后存在一个问题,就是当Web数据的页面发生改变时,W rapper就会失效.由于W rapper与页面格式相关,所以当Web站点页面格式发生变化时,生成的W rapper就会失效,也就是说无法从数据源中获取数据或者得到错误数据.实际上,Web页面变化是经常出现的,这也就提出了一个新问题——W r a p p e r的维护,即W rapper失效时,如何修复失效的W rapper使之继续正确抽取网页数据.
3.1 W rapper维护的总体流程
根据研究假设,图1表示的是Web页面出现结构变化的一个实例.比较图1a和图1b可以发现,它们的抽取模式并没有改变,即页面的数据项特征没有发生变化.如果页面的数据项发生改变,则认为需要重新生成W rapper.

图1 Web页面出现的结构变化
W rapper维护主要涉及两个方面的问题:变化的数据项如何识别和抽取实例如何获取.本研究提出一种基于元数据的W rapper维护方法来解决上述问题.研究发现,在许多情况下,变化后的页面仍然保留了原来的数据特征,这些数据特征可以从用户定义的模式和抽取规则中获取,它们可以辅助自动进行W rapper的维护.
图2为W rapper维护模型结构,主要分为3个步骤:
(1)识别数据特征数据特征从给定的模式树和抽取规则中计算得出;
(2)定义语义块根据用户给定的模式树,在HTML树形结构上划分若干个子树,每一个子树或者一些兄弟子树的集合为一个语法块;
(3)修复规则树在同一个或者附近相关的语义块中搜索改变的数据项在规则树结构中的适当位置.

图2 W rapper维护模型结构
3.2 识别数据特征
表1是图1所示页面的数据特征.表1中每一行都有一个唯一对应的ID,它确定一个数据的数据特征.Schema Element存储的是模式树中对应的元素.Path记录的是对应的叶子结点所在新的HTML树中的路径值.值得注意的是,每个模式元素对应3个重要的数据特征,即:超级链接(Hyperlink);数据注释(Annotation);数据属性(ItemAttribute).这3个数据特征表示为一个三元组(H,A,I):
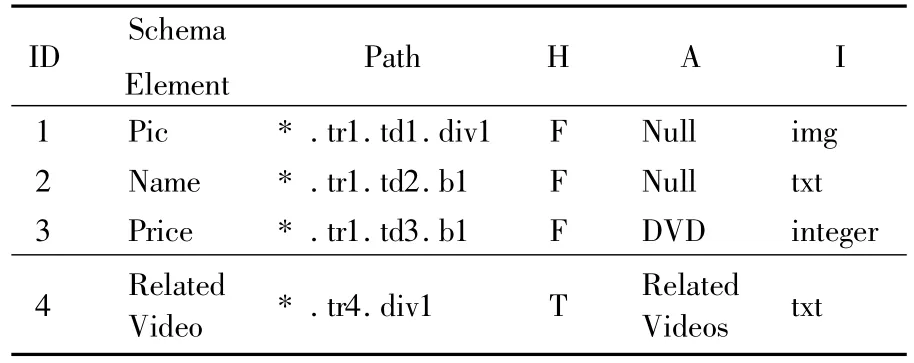
表1 图1所示页面的数据特征
(1)H是一个布尔型数据,取值为F或者T,表示该数据项是否包含超级链接;
(2)A表示在网页上对该数据注释的内容,用它可以识别网页中该数据项是否发生变化;
(3)I定义数据项的属性,通过它可以知道该数据项的数据为何种类型,它也是判断网页是否发生更改的重要依据.
3.3 定义语义块
研究发现,尽管W eb设计者经常调整页面格式,但相同主题的数据一般会放在一起.从将HTML文档看作树形结构的角度来说,改变的数据是放在原来结构中的子树或者其相邻子树中.这种结构也对应于用户定义的模式树结构.基于以上研究,可以在新的HTML树中定义语义块.
定义1如果一棵树同时满足以下条件,则这棵树为原子语义块.
(1)它是某棵树中的一棵子树或者是一些兄弟子树的集合.
(2)它包含的数据与对应模式树的定义完全匹配.
定义2语义块是一个或者多个原子语义块的集合.
这里的完全匹配指的是语义块A中HTML树中叶子结点所包含的、数据满足模式树中对每一个数据项的限制,如不能为空等.从定义可以直观得出,一个原子语义块就是一个最小的可能进行Web数据抽取的单元.
在定义新的HTML树语义块时,利用非递归的方法后序遍历HTML树.当访问到HTML树叶子结点时,会核对该叶子结点中的数据是否与模式树中的某个元素匹配.若该结点重复满足了模式树中具有只能出现一次的元素,则说明该结点是另一个原子语义块的结点,并做上标记.当遍历完成后,定义新的HTML树语义块的工作也就完成了.
完成定义语义块后,得到的是新HTML树的语义块的集合.每一个语义块记录的是数据特征表中ID的集合.
3.4 修复规则树
修复规则,主要是依据语义块对规则树型结构进行修改.
(1)定义规则树的语义块,获得规则树的语义块集合.
(2)将新HTML树的语义块和规则树语义块进行匹配.若完全匹配则说明这个语义块中的HTML树并没有改动,如果是部分匹配或者是完全不匹配,则说明HTML树有改动.
(3)对于那些部分匹配的情况,则表示语义块中对应的HTML树结构已发生变化,根据HTML树语义块记录的数据特征和规则树语义块的数据特征修改规则树中的结点.而对于完全不匹配的情况则返回给用户,重新生成新的W rapper.
4 实验结果及分析
为了验证基于规则树的网页数据抽取方法的性能和效果,选择某企业局域网页上的数据和图1所示页面作为试验数据,并邀请该信息规划科工作人员参与测试过程.
测试环境为:服务端包括HP PC Server LH6000(80 G硬盘,512 M内存,800 MHz PIII Xero CPU);W indowsXP中文版SP3,Oracle9i中文版.客户端包括普通PC机;W indows操作系统,IE浏览器.
4.1 实验方法
首先,需要指定某一个网页,对指定页面生成基于规则树W rapper.在测试易用性指标中,所取页面为企业内部局域网中某一个网页的生成数据.在测试自适应性指标时,改变的页面网址和改变前一致.网址的改变认为是不属于网页维护范畴内.同样,在测试效率指标时,先通过和用户交互的方式对页面生成树结构.抽取的时间指的是生成树结构后到数据导入数据库的时间,实质上为遍历树结构的时间.此外,为了获得更平均的统计结果,规定在相同的网络环境中,每个指标入参的样本集大小为50.因此,每个统计指标的最后结果是50个相同类型不同页面数据的平均值.它们符合置信系数为95%、置信区间不超过5%的要求.
实验中,将基于规则树的网页数据抽取的方法(RuleTree)同其他相关方法(W 4F[6],Chidlovskii[5],SG-WRAM[1])进行比较.
4.2 试验指标
测试指标主要有以下3个.
(1)易用性EU(α)主要是指用户在使用该工具时感到容易和方便的程度.在测试中使用EU (α)指数表示该性能.入参α1,α2,α3分别对应仅熟悉需求的用户、不熟悉需求但接受培训的用户、熟悉需求并且接受培训的用户.EU(α)值为用户在使用该工具将同一页面转换为最终数据的正确率.
(2)自适应性DY(η)指作为数据源Web页面发生局部改变后,工具仍能正确抽取数据的能力.DY(η)入参η1表示在生成的HTML树中,发生改变的数据项相对与原来的位置处于同一棵子树中;η2则表示发生变化的数据项相对于原来位置不在同一棵子树中,甚至在生成的新子树中.
(3)效率Val(δ)主要表示数据的抽取效率.入参δ代表所抽取数据的大小.

4.3 试验结果
4.3.1 EU(α)数据结果及分析
表2记录了α取不同值(α1,α2,α3)时EU (α)的结果.
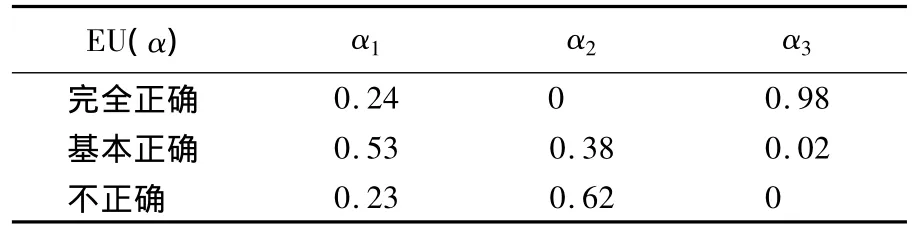
表2 EU(α)试验结果
本试验中,用户水平相当,我们只对α2和α3同时进行了简单培训.从表2可以看出,EU(α3)为完全正确的比率机会达到100%,这表明对于需求熟悉并进行简短培训后的用户完全可以方便灵活地使用该工具进行数据抽取.一个令人惊喜的结果是EU(α1)的正确率远远大于EU(α2)的正确率.这说明工具的使用方法通俗易懂,即使没有经过培训的用户,如果十分了解需求仍然有可能正确地抽取数据.当然,这其中也包含两个权变因素,即用户的素质及需求的复杂程度.
W 4F和SG-WRAM对用户都有特殊的要求.W 4F需要用户会使用HEL语言,Chidlovskii采用一种机器学习的方式,SG-WRAM要求用户能理解并使用所定义的正则表达方式.
4.3.2 DY(η)数据结果及分析
表3记录了η分别取η1和η2时DY(η)的结果.在自适应性的测试中,η1代表的是相对于以前页面,变化的页面中数据项只是在临近位置移动,即HTML树中同一棵子树中叶子结点的左右顺序发生变化.η2表示变化后的页面中数据项发生较大的位置改变,即在HTML树中显示为某一棵子树的叶子结点变为相邻或不相邻子树的叶子结点.
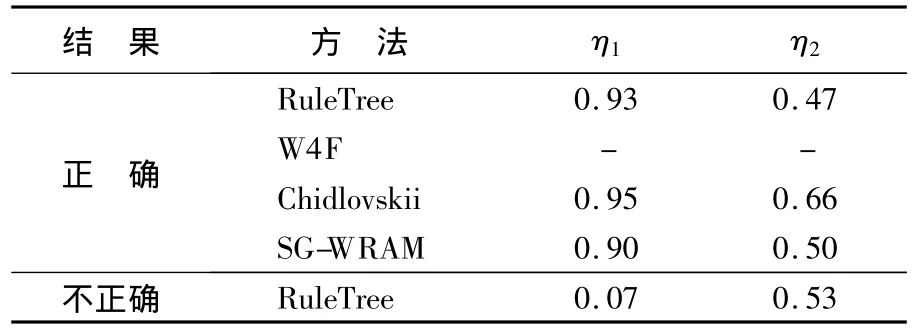
表3 DY(η)试验结果
从表3可以看出,4种方法中DY(η1)为正确的比率较高,相对而言,DY(η2)为正确的比率较低.RuleTree方法通过定义语义块可以快捷准确地辨别变化的数据项位置,并正确抽取源数据,但其语义块对于跨子树特别是跨几棵子树的识别能力较弱;W 4F没有考虑网页变化后的自动维护问题;由于Chidlovskii将网页首先进行分类,根据其语法和内容特征进行判断,准确率相对较高,但是耗时太多,结果也不稳定;SG-WRAM与RuleTree两种方法的实验结果则比较相近.
4.3.3 Val(δ)数据结果及分析
表4记录了δ在不同大小区间数值时Val (δ)的结果.
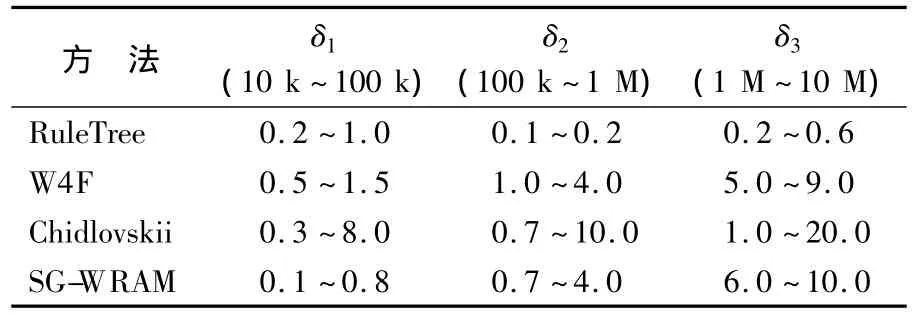
表4 Val(δ)试验结果
本试验中δ的取值是由源数据转换到中心数据库中数据的大小决定的.以RuleTree方法为例将表4的数据作如下处理.
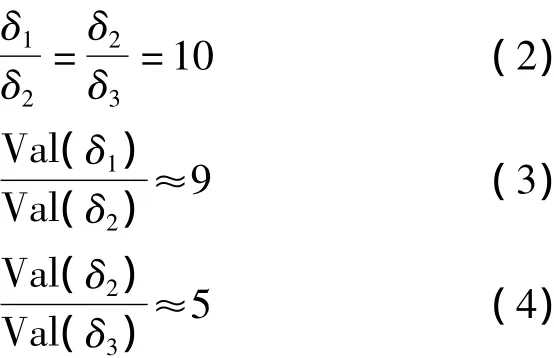
由此可知,在RuleTree方法中,当需要处理的数据大小以10倍速度增长时,其抽取时间的增长率却低于10,表明需要抽取的数据越多,抽取的效率会有所提高.其原因在于只要通过遍历生成的规则树就可以将数据和数据模式对应起来,直接抽取数据即可.同时,树型结构采用类似B+树的双链表存储结构,这样只需访问链接数据的链表就可以完成抽取工作.
W 4F是利用类似SQL的查询语言抽取数据的,因此当需要抽取的数据越多时,其速度就会越慢.Chidlovskii是利用机器学习的方法,其抽取速度和学习能力相关,因此速度极不稳定.SGWRAM方式是通过临时解析定义的正则抽取规则,与W 4F方法一样,在需要抽取的数据激增的情况下效率就会变低.
5 结语
从试验结果来看,基于规则树的W rapper维护在易用性、自适应性和高效率上表现良好.它对于需求明确的普通用户,只需要在简单培训后基本上能独立进行网页页面的抽取.特别是当页面数据发生较小改变时,不需要用户参与就能自动修改树型结构,正确地抽取数据.而最后和用户交互生成的规则树可以正确表示用户需求.当用户定义好一个树型结构后,抽取速度很快,特别是在一定的范围内,随着抽取数据的增加,抽取效率还会有所提高.
[1]MENG Xiao-feng,LU Hong-jun,WANG Hai-yan,et al.Data extraction from the web based on pre-defined schema[J].Journal of Computer Science and Technology,2002,17(4): 377-388.
[2]KUSHMERICK N.W rapper verification[J].World W ide Web Journal,2000,3(2):79-94.
[3]KUSHMERICK N.Regression testing for wrappermaintenance[C]//Proceeding of the AAAI,Heidelberg,Germany,1999: 74-79.
[4]KNOBLOCK C,LEMAN K,MINTOA S,et al.Accurately and reliably extracting data from the web:a machine learning approach[J].Data Engineering,2000,23(4):33-41.
[5]CHIDLOVSKIIB.Automatic repairing of web W rapper[C]// Proceeding of the Third International Workshop on Web Information and Data Management,Atlanta,USA,2001:24-30.
[6]SAHUGUET A,AZAVANT F.Building light-weightW rapper for legacy web data-source using W 4F[C]//Proceeding of the Very Large Data Bases(VLDB),Edinburgh,Scotland,1999: 738-741.
(编辑胡小萍)
猜你喜欢
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
数学物理学报(2018年1期)2018-03-26
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
浙江大学学报(工学版)(2015年2期)2015-05-30
电子设计工程(2014年12期)2014-02-27
土木建筑工程信息技术(2013年4期)2013-10-17
计算机工程与设计(2011年7期)2011-09-07
