
基于Snort的入侵检测系统的研究与改进
2011-03-15 14:30郑礼良吴国凤胡晓明刘庆俞林杰华
合肥工业大学学报(自然科学版) 2011年4期
郑礼良, 吴国凤, 胡晓明, 刘庆俞, 林杰华
(合肥工业大学计算机与信息学院,安徽合肥 230009)
由于网络漏洞、管理者疏忽、黑客恶意攻击等因素,Web服务器遭受网络攻击的事件频繁发生[1]。其中以Web应用类型的攻击最多,而大部分Web应用均未采取专门有效的防护措施来应对。入侵检测系统(Intrusion Detection System,简称IDS)的工作主要用于检测该字符串中的子字符串是否与已知的攻击模式相符,并根据预定的方案采取相应的防范措施,如报警等,以降低入侵带来的危害。常用的Snort[2]方法在字符串检测上花费高达70%的执行时间和80%的指令执行时间,效率不理想。
入侵检测系统的实现涉及协议分析、特征匹配、专家系统等多个方面。其中应用最广泛的是特征匹配,即通过规则库中的规则与网络中的数据包进行匹配来判断攻击类型。模式匹配算法(Pattern M atching A lgorithm)是实现IDS的核心算法,同时匹配过程也是最耗费计算资源的处理步骤。在高速网络中,它一直是IDS性能提高的一个瓶颈。在实际的网络应用中,数据包的捕获速度与解释速度不能匹配直接影响到IDS的效率。针对Web攻击,目前采用的主要措施是IDS尽快、尽可能可靠地检测出各种入侵行为[3]。
1 字符串的匹配优化
1.1 规则库的动态优化
在规则匹配的历程中,现行设备不断完善,漏洞在不断增长和变化,最初制定的一些规则很少或根本不会被匹配成功。入侵检测进行规则匹配时要逐个进行,这样就占用了大部分的匹配时间,降低了匹配效率。经分析验证,把匹配的次数和学习得到的权值两者进行比较:当高于权值,则将此规则放在规则库的最前面,顺序由高出权值的多少而定;当低于权值则放在后面,顺序由低出权值的多少而定;当匹配次数小于某个阀值时,则把此规则彻底地从规则库中删除。权值和阀值通过不同环境下的数据学习和综合统计而定,可减少无用的匹配,从而动态地更新规则库中的规则匹配顺序。
权值和阈值主要是通过数据挖掘技术来进行确定,此技术是一种从大量数据中提取人们感兴趣的模式的过程。其对象可以是数据源、文件系统,也可以包括诸如Web资源等任何数据集合。数据挖掘通过预测未来趋势及行为,目标是从数据中发现隐含的、有意义的知识,关联分析能寻找数据库中数据的相关联系。给定一个最小支持度和一个最小可信度,找出那些可信的并具有代表性的规则。其主要操作是在路由器之后,防火墙之前建立一套入侵防护机制,监控每一个局域网络的出入口,利用入侵侦测设备(Intrusion Detection Device,简称IDD)对每一笔进出局域网络的数据信息进行监控。
此外,IDD还过滤不当来源的数据包,对一般事件网络的流量做出响应,这些信息将会汇总到系统控制中心[4](Center of Intrusion Detection System,简称CIDS),从而完成网络数据采集功能[5],如图1所示。
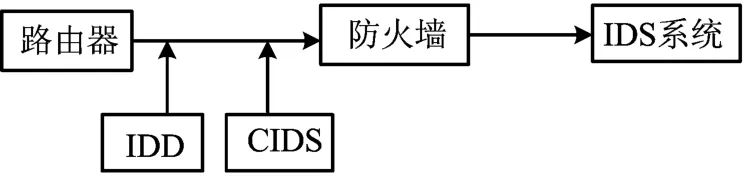
图1 数据挖掘流程
本文的工作就是对数据进行统计分析,给出所需要的阀值和权值。通过这项技术,可以把当前最新、最常见的规则放在匹配的最前沿,并且删除过于陈旧的规则,不仅使规则库更加的简洁,而且提高了匹配的效率。
1.2 2C-BM算法简介
随着各种攻击手段的不断出现,IDS要匹配的模式数量急剧增加,从而对匹配算法提出了更高的要求。模式匹配[6]从方式上可分为精确匹配、模糊匹配、并行匹配等。著名的匹配算法有BF算法、KMP算法、BM算法[7]、BMH算法及一些改进算法,这些算法在不同的条件下有着不同的优越性。现在用于Snort的比较成熟而且高效的模式匹配算法多数为BM算法以及在这个算法基础之上改进的算法,比较常见的有2C-BM算法[8]、BMH算法。Snort按照深度链式搜索算法对规则进行逐条匹配,规则中的每一个选项对应各自的匹配函数,以实现不同类型的匹配操作。这种算法程序结构清晰,具有非常好的可扩展性。
根据综合考察,发现2C-BM算法具有简洁、高效、扩展性强等特点,可以根据自己的需求动态地改变其每次匹配的字符数,如2C-BM算法以每次比较2个字符为主,同样可以扩展到3个或4个,只需将函数中的参数进行相应的修改即可。2C-BM算法具体实施时,主要分为预处理阶段和匹配阶段。
(1)预处理阶段。①构造Hash(w[i]),将匹配串中任2个字符的组合映射到一个值。但若字符集为整个 0x0000—0xFFFF,则可以不用Hash,直接用Hash(w[i])=(unsignedshort) (w[i]);②构造Shift数组,用来计算每个字失配时的偏移量是多少。
(2)匹配阶段。①将被匹配串(记为B)与模式串(记为M)对齐,且它们的长度分别为n和m,指针b→textEnd指向B[m-1],b→currentEnd指向b[m-2],从B{m-2,m-1}与M{m-2,m-1}开始比较;②比较一个字;③2个字相等:若已经比较到B首字符,转④,否则指针b→currentEnd向左移动2个字节,转②; 2个字不等:查Shift表确定偏移量 S1、S2,取Shift=max{S1,S2+1};若(b→textEnd-b→currentEnd)<Shift,转④;否则,b→textEnd向右滑动Shift个字符,转②;④匹配结束。
此算法是在BM算法的基础上进行了改进:一方面把每次匹配比较的字符由1个变成了2个,另一方面遇到失配时,根据不同情况可以通过Shift和Shift+1的值进行跳转,增大了跳转距离,减少了跳转次数。
1.3 改进的匹配算法
由于网络攻击类型增多,IDS要匹配的模式数量也在急剧增加。到2006年10月,Snort公布的ru les已经达到8 525条,其中8 112条就用到模式匹配。规则库的不断增大,仅依靠单模式算法来匹配,不仅检测效率不高,而且漏包现象很严重。本文提供的算法是在2C-BM算法的基础上加入数组定位标记功能,以加快后期模式匹配的速度。
在匹配过程中并非很快找到所需要匹配的规则和并行匹配模式,为了提高匹配速度,本文采用了数组标记的功能,主要是对送进来的匹配项进行字符标记,在匹配的最开始通过2C-BM算法进行字符匹配,同时开启一组数组对已经匹配过的字符,在被匹配串中的位置进行标记记录,具体方法如下。
假设要检测的一组字符串为:Text=“abcde fgbcga”,在开始检测的同时就会记录下字符串中已经匹配过的字符所在的位置。由于部分字符被比较,所以只会记录被匹配过的字符位置。若第1条被匹配到的规则串为opq,则根据2C-BM算法,因为 Text中没有一个与opq中的字符相同,所以每次跳转距离都是最大的,即其本身长度加1。第1次匹配之后,被匹配记录的字符位置有第2、3、4位置的b、c、d,6、7、8位置的 f、g、b,被记录的字符占总字符的54%。第2条被匹配的规则串为bcg,可以用算法匹配的同时,结合数组标记中的记录来找要匹配的字符,同时记录其它刚被匹配到的字符位置。
据实验统计,2C-BM算法随着规则库中规则数目的增加,其匹配成功的时间成不均匀的递增分布,平均时间记为T(2C-BM),数组标记字符达到30%,则字符串匹配成功率达到80%以上,字符记录40%时已经达到90%以上,它们匹配时间分别记为T(3)、T(4),同时T(3)<T(4)≪T(2C-BM)。因此得出结论:当使用2C-BM算法匹配时间T(2C-BM)>T(3)或者T(2C-BM)>T(4)时,字符匹配则通过数组标记法已经匹配成功。定位表中记录的字符越完整,则匹配的准确率就越高,但需要的时间也越长。
本文通过多组实验测试选取,当字符记录达到45%时,则匹配时间和匹配准确率达到最优。假设上面的所有字符都已经记下来了它们的位置,如a[1]={1,11},a[2]={2,8},a[3]={3,9},a[4]={4},a[5]={5},a[6]={6},a[7]= {7,10},分别记录了字母a到g在abcdefgbcga中的位置。下一步给出的比较串Patten=“bcg”,则只需要查找a[2]、a[3]、a[7]中记录的值,查看是否有连续递增的情况。如a[2]中有2、8,再观察a[3]中有没有3或9。如果有继续向下查询,没有则宣告结束,匹配不成功。因为a[3]={3,9},所以再观察a[7]中记录的值是否有4或10,若有则匹配成功,没有则匹配失败。由于a[7]中有10,所以匹配成功。此法不仅在比较串的长度上没有限制,而且对于比较串较短的情况能够很快地给出响应,这一点打破了以往对字符串越长匹配速度越快,越短(一般情况下最短要大于7个字符)匹配速度越慢的限制。
2C-BM算法匹配过程如图2所示,改进匹配算法如图3所示。

图2 2C-BM算法匹配过程
图3中,a[1]记录a的位置,a[2]记录b的位置,a[3]记录c的位置,a[4]记录d的位置,a[5]记录e的位置,a[6]记录f的位置,a[7]记录g的位置,匹配串为bcg,查看a[2]={2,8},a[3]= {3,9},a[7]={7,10},得出a[2]、a[3]、a[7]中有8、9、10这样的加1排序,则匹配成功。
上述2C-BM算法每次进行双位比较,比以往的BM算法有了很大的提高。使用本文中提供的数组定位标记法,则只需比较数组中的记录,查看a[2]、a[3]、a[7]中记录的数字是否有连续递增排序,有则匹配成功,无则跳出直接进行下一次匹配,其优越性是显而易见的。
2 测 试
测试环境为:Intel(R)Core(TM)2 Duo CPU,主频1.8 GH z,内存1G,操作系统为W indow s XP,编译器为Visual C++6.0,数据库系统为SQL Server2000,入侵检测系统采用开源的Snort2.8.5。在这样的环境下,针对匹配机制以及规则库未改进的Snort与改进后的Snort进行了测试比较。
在测试中,分别针对Snort日志中的部分数据进行了测试比较。用长度为200 k的网络数据包(取自M IT Linco ln Laboratory的数据集)进行测试,规则采用Snort的规则库,结果见表1所列。从表1可以看出,改进算法相比2C-BM算法在性能上有较大的提高。起初规则少时并不能体现出其优越性,但是随着规则数量的不断增加,改进算法的优点越明显。

表1 多种算法匹配用时比较 m s
实验表明,使用2C-BM算法后的Snort系统在规则数目小于100条的情况下,入侵检测的时间相对于BM算法平均缩短了59.5%左右,而通过动态改变规则库和加入数组定位的匹配方法,则与BM算法相比在规则数目小于100条的情况下,入侵检测的时间平均缩短了62.3%左右,而与2C-BM算法相比则缩短了9.2%。当规则数目大于100小于2 000条的情况下,使用2C-BM算法后入侵检测的时间相对于BM算法平均缩短了65.3%左右,本文通过改进后的匹配方法,与BM算法相比较,入侵检测的时间平均缩短了74.1%左右,而与2C-BM算法相比则缩短了25%,如图4所示。

图4 改进算法与2C-BM算法用时比较
通过上面的实验数据及图3所示可以发现,此方法的优点在于规则条数越多,其匹配速度相对于其它的匹配方法则更快。
3 结束语
本文结合以往改进的算法加入了数组标记的功能,对于庞大的规则库匹配,为使IDS更加智能化地发展,提出了改进方法,并且还对于不常匹配到的规则进行了动态的排序和删除,极大地增强了匹配的灵活性,提高了匹配的速度。在本文算法的基础上,通过对规则库中的规则进行数组标记,在匹配前期可能对匹配速度有一定的影响,但当规则库记录完整时,则匹配工作变得更加快捷。
[1] Garcia A,Juan J P,Katza A,et al.Intrusion detection in W eb ap plicationsusing textm ining[J].Engineering Applications of A rtificial Intelligence,2007,20(4):555-566.
[2] Antonatos S,Anagnostakis K G.Generating realistic w orkloads for netw ork intrusion detection systems[J].ACM SIGSOFT Softw are Engineering Notes,2004,29(1): 207-215.
[3] KA IH ong-mei,ZHU H ong-bing,KEIE,et al.A novel intelligen t intrusion detection,decision,response system [J].IEICE Transactions on Fundamentals of Electronics,Communicationsand Compu ter Scien ces,2006,E89-A(6): 1630-1637.
[4] Xiao-Ling Ye,Ying-Chao Zhang,Chao-Long Zhang.A m obile agent and Snort based distributed in trusion detection sy stem[C]//World Cong ress on Softw are Engineering. Xiamen,China,2009:281-286.
[5] 刘庆喻,叶 震,尹才荣.一种基于攻击特征描述的网络入侵检测模型[J].合肥工业大学学报:自然科学版,2010,33 (2):238-241.
[6] Horspool N R.Practical fast searching in strings[J].Softw are Practice and Experience,1980,10(6):501-506.
[7] 周文秋,吕 岳.一种快速模式匹配算法及其在IDS中应用[J].信息技术,2009,(3):30-32,36.
[8] Pulsone N B,Rader C M.The M IT Lincoln Laboratory KASSPER algo rithm testbed and baseline algorithm suit [C]//Sensor A rray and M ultichannel Signal Processing W orkshop Proceedings,2003:38-42.
猜你喜欢
电脑报(2022年13期)2022-04-12
无线互联科技(2020年11期)2020-12-01
电脑报(2020年24期)2020-07-15
电子制作(2019年13期)2020-01-14
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
林业调查规划(2017年6期)2017-03-27
山东工业技术(2015年21期)2015-07-27
初中生之友·中旬刊(2015年4期)2015-06-10
燕山大学学报(2014年1期)2014-03-11
