
未知环境中基于观察者的多机器人编队控制方法
2011-01-23 05:31曾良才
武汉科技大学学报 2011年3期
雷 斌,曾良才
(武汉科技大学机械自动化学院,湖北武汉,430081)
近年来,机器人编队控制已成为多移动机器人研究的一项关键技术。编队控制是指多个机器人在到达目的地过程中,既保持某种队形又能适应环境约束(如存在障碍物或者空间的物理限制)的控制技术。多机器人研究所要解决的主要问题是机器人之间的协调与合作,对于自主移动机器人编队问题来说,协调主要是使机器人避免与障碍物以及机器人之间发生碰撞,而合作就是保持队形。机器人编队研究可分为两类:①集中式控制,它通过一个集中控制单元来监督整组机器人并分别命令每个机器人的运动;②分布式控制,每个机器人利用局部信息自主运动[1]。目前多移动机器人编队方法[1-2]主要有领导-跟随法(Leader follo wing)、基于行为法(Behavior-based)和虚结构法(Virtual-structure),其中,虚结构法利用集中式控制器,而基于行为法和领导-跟随法通常使用分布式控制器。领导-跟随法、基于行为法和虚结构法都可控制机器人以一定队形运动,但在复杂未知环境中它们均存在一定的缺陷。领导-跟随法在静态环境中可以获得比较准确、稳定的队形,但对动态环境的适应能力不强,机器人之间的避碰等问题没有得到很好的解决,而基于行为编队法对环境的适应能力较强,但在队形稳定性上存在一定的缺陷。为此,本文结合领导-跟随法[3]和VFH+(Vector Field Histogram)避障法[4],提出一种基于观察者的多机器人编队控制方法,并利用Player/Stage机器人仿真平台,对编队控制方法进行了仿真实验。
1 VFH+避障法和l-ψ编队控制
1.1 VFH+避障法
避障是自主移动机器人的一项基本能力,它保证机器人在环境信息未知的情况下,能够安全到达目的地。VFH+避障法是一种用于机器人实时避障的方法,它是对1991年开发的V FH法[5](向量域直方图)的一种改良版本。与V FH法一样,VFH+避障方法的输入是局部环境的栅格图,叫做直方图[5]。为了计算机器人新的运动方向,VFH+避障法利用了一个4级数据缩减的过程[4]。在前3级里,机器人当前位置周围信息由二维栅格图缩减为一维极线直方图。在第4级,该方法通过遮罩的极线直方图和代价函数来选择一个最合适的方向。V FH+避障法首先在遮罩的极线直方图中选择所有的开放区域,然后确定一组可能的候选方向,最后利用代价函数来评价这些候选方向,选择代价最低的那个候选方向作为机器人新的运动方向。VFH+避障法已通过大量实际检验,并成功运用于一种导盲机器人上工作。
1.2 l-ψ编队控制
在l-ψ法中,一个机器人被定义为领导者,而其他机器人被称为跟随者。该方法的基本思想是,跟随者以一定的偏移量(或一定的时间延时)跟踪领导者的位置和导向角。目前有l-ψ和l-l两种队形控制法[3],其中,l代表领导者和跟随者之间的距离;ψ代表两者之间的角度。l-ψ法的关键思想是,控制跟随者和领导者之间实际距离和角度,使其达到期望的距离和角度。但单独采用该方法,往往存在不少问题。例如,当领导者避障时,或是突然停止,则跟随者的反馈量会变得过大,这样就不能保持队形的稳定性。又如,当领导者位置在跟随者后面时,跟随者的导向角就会发生变化,因此该方法很难在实际中单独运用。
2 基于观察者的多机器人编队方法
2.1 编队方法的基本思想
针对l-ψ法存在的不足,我们提出一种基于观察者的编队方法,如图1所示。基于观察者的编队方法的基本思想是:指定一个机器人作为观察者,利用V FH+避障法快速、安全地到达指定地点;领导者根据观察者的运动轨迹和传感器信息,并根据队形的可通过性来优化领导者的轨迹,进而控制跟随者以一定的队形运动。使用基于观察者的编队控制方法,通过对观察者的轨迹优化,可以较好地解决领导者运动状态突变对跟随者影响的问题。由图1可看出,观察者的运动轨迹在A区会出现较大的突变,如果单纯使用l-ψ法,则无法保持队形的稳定。由观察者运动轨迹和优化后领导者轨迹可看出,领导者的轨迹更加合理,且保持着队形的稳定性。
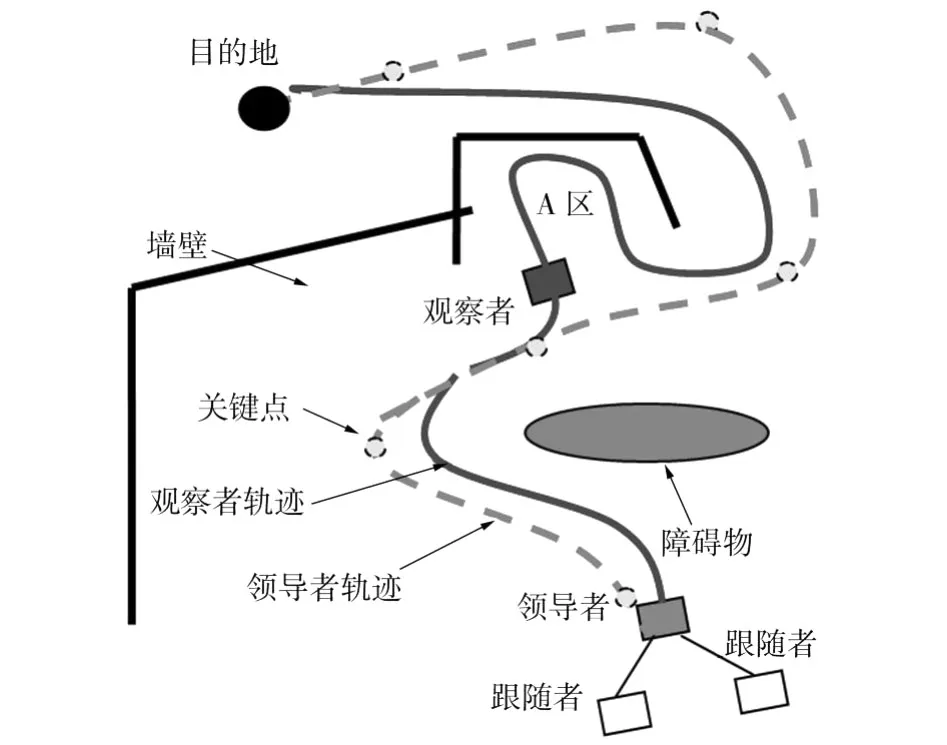
图1 一个基于观察者的编队方法的例子Fig.1 An example of observer-based formation control
2.2 编队结构的控制
图2为基于观察者的多机器人编队结构图。由图2可看出,编队结构主要分为观察者、领导者和跟随者。观察者是利用V FH+避障法搜索一条到达目标点的安全路径,同时根据其轨迹(PO)和传感器数据(SO)及队形宽度(dF)规划出一些领导者路径的关键点(PL);领导者是其沿着这些关键点运动,同时根据传感器信息来调整编队的队形变化,以适应环境的约束,且能自主避碰;跟随者是以一定的角度和距离跟随领导者运动,同时能自主避碰。
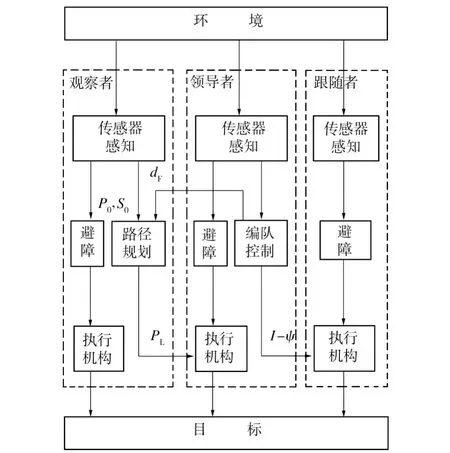
图2 基于观察者的多机器人编队结构图Fig.2 Block diagram of observer-based formation control
编队结构所选择的关键点如下:①去除不合理的位置;②当前队形的宽度可通过:左边不可通过,而右边可通过,使领导者位置向右偏移一定位置,使整个队形通过;右边不可通过,而左边可通过,使领导者位置向左偏移一定位置,使整个队形通过;左右两边都可通过,使领导者保持观察者的位置;③当前队形宽度不可通过,使领导者保持观察者的位置,当领导者到达该位置时,会通知跟随者改变队形,缩小队形宽度。
编队结构的关键点在于如何对观察者的路径进行优化,得到领导者轨迹的关键点,使领导者的轨迹更加合理。根据观察者传感器的数据,我们可以得到该轨迹附近的环境信息,然后对这些环境信息进行处理,就可以规划出领导者的路径。
3 仿真实验
通过Player/Stage机器人仿真平台,我们对多机器人编队控制方法进行仿真实验。Player是一个机器人设备服务器[6],它可使我们简单而完全地控制移动机器人上的传感器和驱动器。Stage是一种在自主机器人和智能传感器系统中用作仿真研究的软件工具[7],它在一个二维点阵图环境中模拟仿真一组移动机器人和传感器等对象,并且能够通过Player来控制它们。特别值得注意的是,用Player/Stage仿真平台开发的客户端控制程序可以经过很少甚至不需要修改就能在真实的机器人上工作。
在Player/Stage机器人仿真平台上,我们设计了一个20 m×20 m的场地,构造机器人编队避过障碍物到达目标点时的仿真环境。4个装备有激光、声纳、位置传感器的仿真Pioneer2机器人随机给定起始位置,其中,机器人1作为观察者,机器人2作为领导者,机器人3、4作为跟随者,机器人2、3、4以三角形编队运动。障碍物的位置未知,目标点位置为6 m、-4 m。客户端在Eclip se条件下利用Java语言编写算法控制程序,并通过TCP socket连接到Player服务器端,仿真实验结果如图3所示。由图3可看出,基于观察者的编队方法可使整个编队的队形保持更稳定,且其路径更加合理高效。
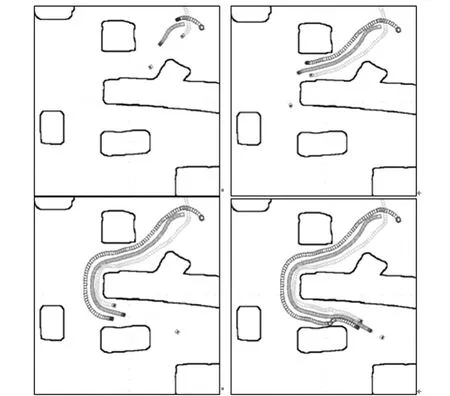
图3 仿真实验结果Fig.3 Simulation results
4 结语
就当前主要的机器人编队方法,并针对其存在的问题,本文提出一种基于观察者的多机器人编队方法。该方法主要是利用观察者的运动轨迹信息及其获得的传感器数据信息对领导者的路径进行优化,减少了运动突变和编队死区的存在,因此可以使队形控制获得相对理想的结果。通过Player/Stage机器人仿真平台,该方法可有效地控制一组移动机器人以一定队形无碰地到达指定目的地。
[1] Nguyen Q pH,Huang S,Trinh H.Observer based decentralizedapp roach to robotic formation control[C]∥Proceedings of the 2004 Australian Conference of Robotics and Automation,2004:1-8.
[2] Fredslund J,Mataric M J.A general algorithm for robot formations using local sensing and minimal communication[J].IEEE Transactions on Robotics and Automation,2002,18(5):837-846.
[3] Desai J P,Kumar V,Ostrow ski J P.Controlling formations of multip lemobile robots[C]∥IEEE International Conference on Robotics and Automation,1998:2 864-2 869.
[4] U lrich I,Bo renstein J.VFH+reliable obstacle avoidance for fastmobile robots[C]∥IEEE International Conference on Robotics and Automation,1998:1 572-1 577.
[5] Borestein J,Koren Y.The vector field histogramfast obstacle avoidance for mobile robots[J].IEEE Transactionson Robotics and Automation,1991,7(3):278-288.
[6] Brian P G,Richard T,Vaughan K S.et al.Most valuable p layer:a robot device server fo r distributed control[C]∥Hawaii:Proc IEEE/RSJ Intl Confon Intelligent Robots and Systems,2001:1 226-1 231.
[7] Richard T V.Massively multi-robot simulations in stage[J].Swarm Intelligence,2008,2(2-4):189-208.
猜你喜欢
科学导报·学术(2020年26期)2020-10-21
作文大王·低年级(2019年6期)2019-08-01
中外文摘(2019年8期)2019-04-30
语言与文化论坛(2019年4期)2019-03-29
中国广播(2017年9期)2017-09-30
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15
诗潮(2017年5期)2017-06-01
西北工业大学学报(2015年1期)2016-01-19
中南财经政法大学学报(2015年5期)2015-04-07
通化师范学院学报(2013年4期)2013-02-15
