
基于自适应权重PSO的模型参数估计算法
2010-11-27 02:32许久峰苗国立聂金荣程晓天
河南工程学院学报(自然科学版) 2010年3期
许久峰,苗国立,聂金荣,程晓天
(1. 河南省煤炭科学研究院有限公司,河南 郑州 450001;2.河南送变电建设公司,河南 郑州 450051;3.郑州交通职业学院 交通工程系,河南 郑州450011;4.河南省产品质量监督检验院,河南 郑州450004)
传统的参数估计方法已经比较成熟,如常用的最小二乘法、梯度校正法、极大似然估计法[1]等,这些方法都利用梯度下降寻优法来求解,在某种特定的情况下(如对多峰目标函数的求解)可能会陷入局部极值.近年来,越来越多的智能算法应用于参数估计中,如神经网络法[2]、遗传算法[3-4]等.神经网络虽然具有以任意精度逼近线性函数的能力,已经被广泛应用于线性系统的拟合,但是在实际应用中,如何选择合适的网络结构是当前遇到的最大困难之一.利用遗传算法对过程模型参数进行优化估计能够获得比较好的参数估计效果,但是遗传算法易于早熟收敛,此外还涉及繁琐的编码和解码过程且需要较大的计算量.
微粒群优化(PSO)算法是群体智能计算的典型代表,由于微粒群算法具有较强的通用性和全局寻优的特点,引起了众多研究者的关注,并在诸多领域得到了广泛应用.本文从提高优化求解速度的角度对微粒群算法进行了改进,将改进算法应用到模型参数估计中.
1 模型参数估计问题描述
对于SISO系统,模型参数估计问题的一般描述形式为:
y=f(u,θ)+e
(1)
其中,y为系统输出,u为系统输入,θ为待估计的模型参数,e是均值为0、方差为δ的白噪声信号.
参数辨识时采用的准则函数一般定义为输出误差的函数,即:
(2)
所以,模型参数估计问题也即是按照某种优化算法,根据已知数据,估计出使J(θ)为最小的模型参数θ值.因此,模型参数估计本质是一个无约束的多维参数寻优问题.
2 自适应微粒群算法
2.1 微粒群算法简介
微粒群优化算法是美国心理学家Kennedy和电气工程师 Eberhart受鸟类觅食行为的启发而提出的一种基于群体智能理论的新兴演化计算技术[5].PSO算法将问题的搜索空间类比为鸟类的飞行空间,将每只鸟抽象为一个无质量无体积的微粒,用以表征问题的一个候选解,优化所需要寻找的最优解则等同于要寻找的食物.PSO算法保留了基于种群的全局搜索策略,采用简单的“速度—位移”模型,避免了复杂的遗传操作,它特有的记忆也使其可以动态跟踪当前的搜索情况来调整其搜索策略.
假设问题解空间为D维,由m个微粒组成的群体中的第i个微粒可以表示成D维向量,其中第i个微粒的位置表示为Xi=[xi1,xi2,…,xiD],第i个微粒的速度表示为Vi=[vi1,vv2,…,viD],第i个微粒经历的最佳位置(对应于最好的适应度)表示为Pi=[pi1,pi2,…,piD],也称为Pbest.群体所有微粒经历的最好位值表示为Pg=[pg1,pg2,…,pgD],也称为gbest.微粒的速度和位移更新公式,如(3)、(4)所示.
(3)
(4)
式中,w表示惯性权重,c1、c2称为学习因子,r1、r2为在区间[0,1]变化的随机数.
2.2 自适应微粒群优化算法
由式(3)可以看出,算法当前时刻对上一时刻速度继承的多少直接受惯性权重的影响,这直接关系到算法的搜索性能和收敛性,是影响算法搜索行为和性能的关键因素.因此,通过合理设置惯性权重的变化方式来兼顾算法的全局搜索和局部搜索能力,有利于快速准确地找到最优解.实际中,最常见的权重改变方式为线性递减权重法,按式(5)更改惯性权重:
(5)
其中,wmax、wmin分别表示w的最大值和最小值,t表示当前迭代步数,tmax表示最大迭代步数,通常取wmax=0.9,wmin=0.4.
但线性递减权重法有一定的缺陷,需要通过反复试验来确定惯性权重的最大值、最小值以及最大迭代次数,且很难找到适应于不同问题的最佳值.这是因为,在实际问题中每次迭代所需的比例关系并不相同,所以w的线性递减只对某些问题很有效.由微粒的更新公式可以看出,PSO算法在解空间的寻优过程实际上就是一个非线性运动过程,为了兼顾PSO算法的全局和局部搜索能力,采用一种非线性的动态惯性权重设置的方式,使惯性权重的变化随着微粒的适应度值自动变化,其表达式如下:
(6)
其中,f表示微粒当前的适应度值,favg和fmin分别表示当前所有微粒的平均适应度值和最小适应度值.惯性权重随着微粒的适应度值而自动改变,所以称为自适应权重.
当各微粒的适应度值趋于一致或者趋于局部最优时,将惯性权重增加,而各微粒的适应度值比较分散时,将惯性权重减小,同时对于适应度值优于平均适应度值的微粒,其对应的惯性权重较小,从而保护了该微粒,反之对于适应度值差于平均适应度值的微粒,其对应的惯性权重因子较大,使得该微粒向较好的搜索区域靠拢.
3 基于自适应权重PSO的模型参数估计算法
3.1 算法原理
假设待估计的参数为D个,令微粒群的搜索空间维数为D维,将待估计的未知模型参数看成解空间的一个最优解,这样第i个微粒的位置就可表示成一D维向量Xi=[xi1,xi2, …,xiD]. 其中,Xi中的每一个元素代表一个未知的模型参数.微粒在由式(2)构造的适应度函数驱动下,执行解空间内全局搜索策略,对未知的模型参数进行全局寻优,使之与所测系统的模型参数拟合得最好.微粒搜索到的最优解也即是待估计的模型参数.由于PSO算法的性能受惯性权重的影响较大,在此采用基于自适应权重的PSO算法来估计模型参数.
3.2 算法流程
算法的实现步骤如下.
步骤一:根据待优化的问题,设置相关初始参数,如微粒的维数D、种群规模m、惯性权重wmax和wmin、加速度常数c1和c2,算法结束的条件等;
步骤二:初始化群体中微粒的初始位置和初始速度;
步骤三:评价各微粒的适应度值J(θ),将当前各微粒的位置和适应度值存储在各微粒的pbest中,将所有pbest中最优个体的位置和适应度值存储于gbest中;
步骤四:根据算式(3)和(4)更新各微粒的位置和速度;
步骤五:根据式(6)更新惯性权重;
步骤六:对每个微粒,将其适应度值与历史最好位置pbest相比较,如果当前适应度值更优,则用当前适应度值更新pbest;
步骤七:将每个微粒的适应度值与群体经历过的历史最佳位置gbest相比较,如果当前群体中最好的适应度值较好,则将其置为新的gbest,并记录其索引号;
步骤八:根据优化性能指标值,判断是否已达到结束条件,如果达到算法终止条件,则返回当前最佳微粒的结果作为模型参数,算法结束;否则返回步骤四,继续下一循环.
4 仿真研究及结果
为了验证利用自适应权重PSO算法进行过程模型参数估计的有效性,下面分别对两个过程对象(线性模型和非线性模型的未知参数)进行仿真研究.
4.1 线性模型参数估计
已知仿真对象的离散化模型如式(7)所示,模型参数a1、b1未知.通过实验测得系统的阶跃响应数据如表1所示.采用所提算法,估计模型的未知参数.
z(k)+a1z(k-1)=b1u(k-2)+e(k)
(7)
式中,e(k)是服从正态分布的白噪声N(0,1).
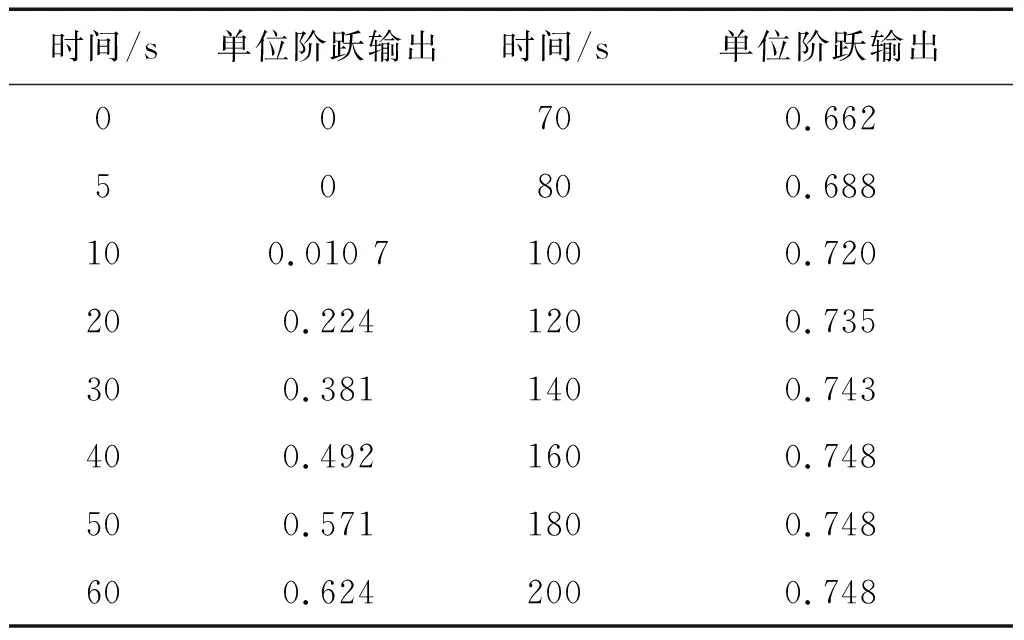
表1 单位阶跃响应下过程的输出数据Tab.1 The output data of process step response
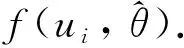
(8)
迭代时需注意,当k=1,2时,z(k)=0.
辨识过程中未知参数a1、b1的变化趋势,如图1所示.将估计值与采用最小二乘法的参数估计结果对比,如表2所示.
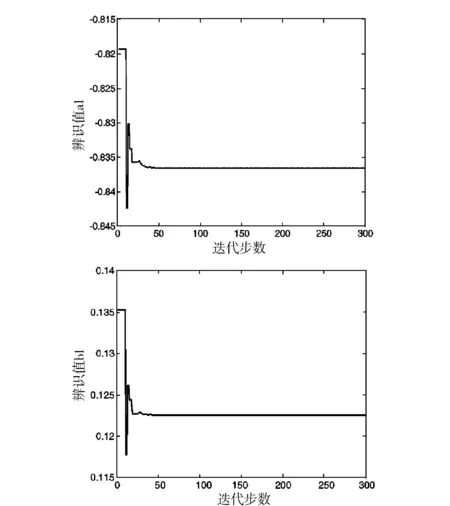
图1 参数辨识曲线Fig.1 Parameter identification curves

参 数a1b1真实值-0.836 50.117 8最小二乘估计-0.829 60.117 2自适应权重PSO-0.836 60.122 5
由表2的参数估计结果可以看出,自适应权重PSO具有很好的参数辨识效果,辨识值接近真实值.在Matlab仿真过程中,最小二乘估计迭代15步用时1.299 9 s,自适应权重PSO迭代300步用时仅为0.945 8 s,自适应权重PSO的搜索效率较高.再从图1参数辨识曲线图来看,a1、b1在迭代进行到50步左右已经达到搜索最优值,算法的收敛速度很快.可见,将自适应权重PSO算法应用到线性模型参数估计中,算法的精度和效率均很高,具有较好的辨识效果.
4.2 动力学模型参数估计
动力学系统辨识是系统辨识学科中的一个重要分支.一般情况下,系统的动力学基本数学模型是已知的,需要辨识的只是动力学方程中的某些待定参数,这类问题属于典型的“灰箱问题”.下面以间歇式反应过程为例,辨识其动力学参数.由理论分析可知,聚合反应过程具有非线性和时变的特点.
对于在间歇反应器进行的某反应,其反应系统为A+2B→C,已知其动力学模型如式(9)所示.
(9)
从间歇反应器中获得的初始反应速率数据表见文献[6]所示,由该测试数据估计动力学模型的未知参数k、n和m.
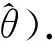
(10)
基于自适应权重PSO的参数估计结果,与非线性回归法估计出的参数值对比,如表3所示.
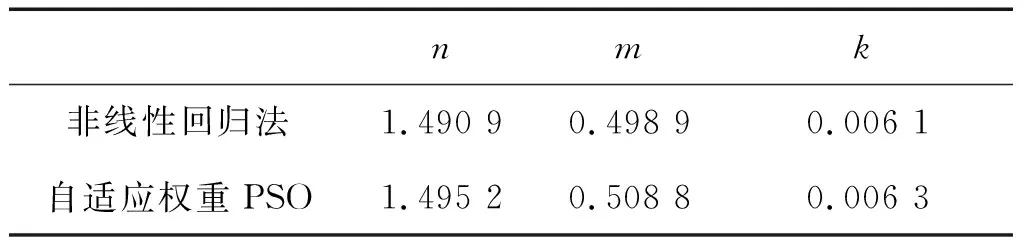
表3 参数估计结果Tab.3 Results of parameter estimation
基于自适应权重PSO的参数估计,在参数估计过程中,未知参数的变化趋势曲线和适应度值变化曲线,如图2和图3所示.
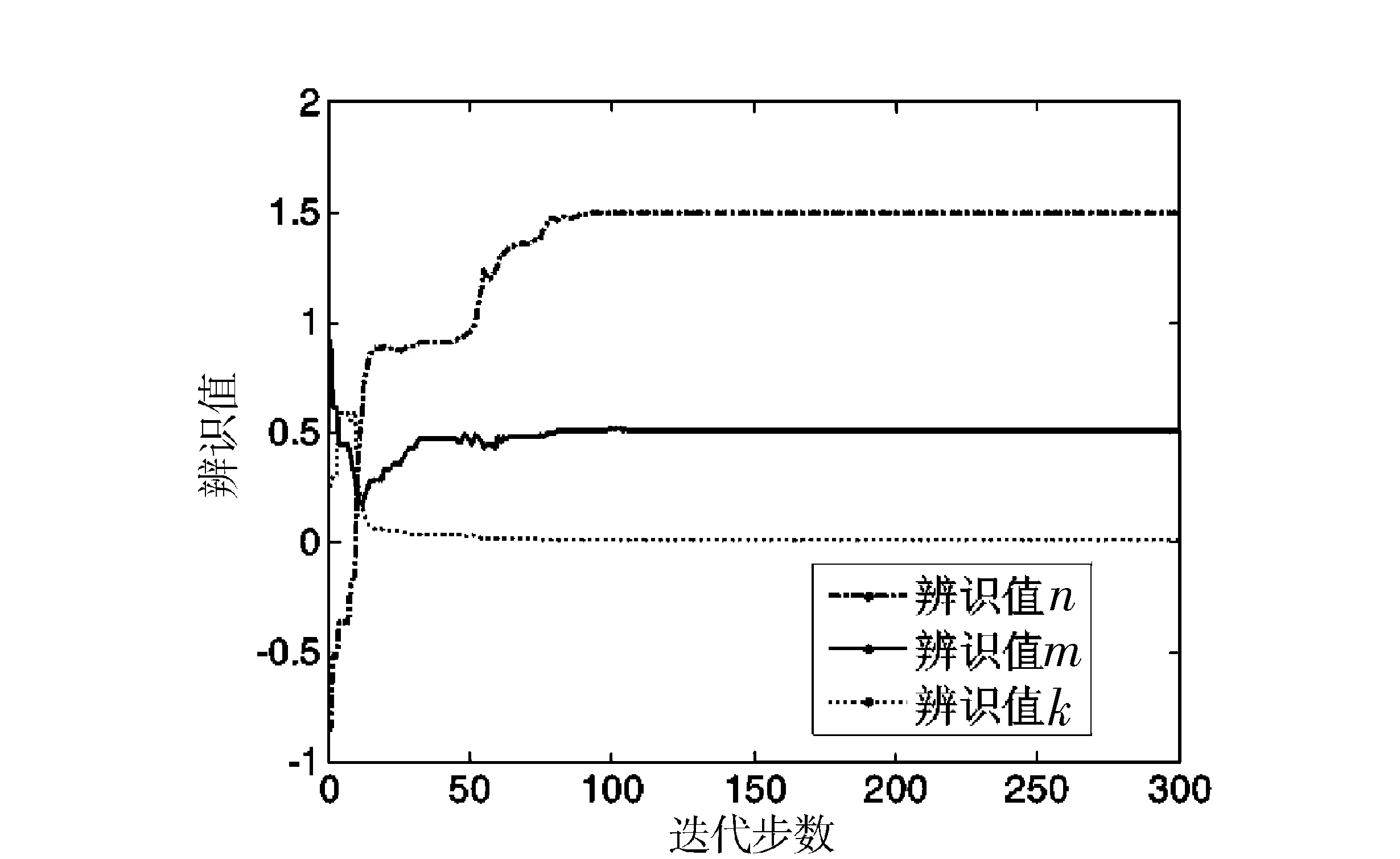
图2 参数辨识曲线Fig.2 Parameter identification curves
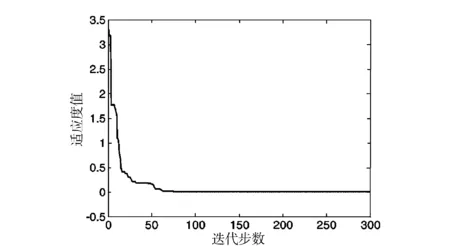
图3 适应度值变化曲线Fig.3 Fitness value curve
根据自适应权重PSO和非线性回归法估计的模型参数(表3中参数估计结果),求出模型拟合值,并与实际值对比,如表4所示.
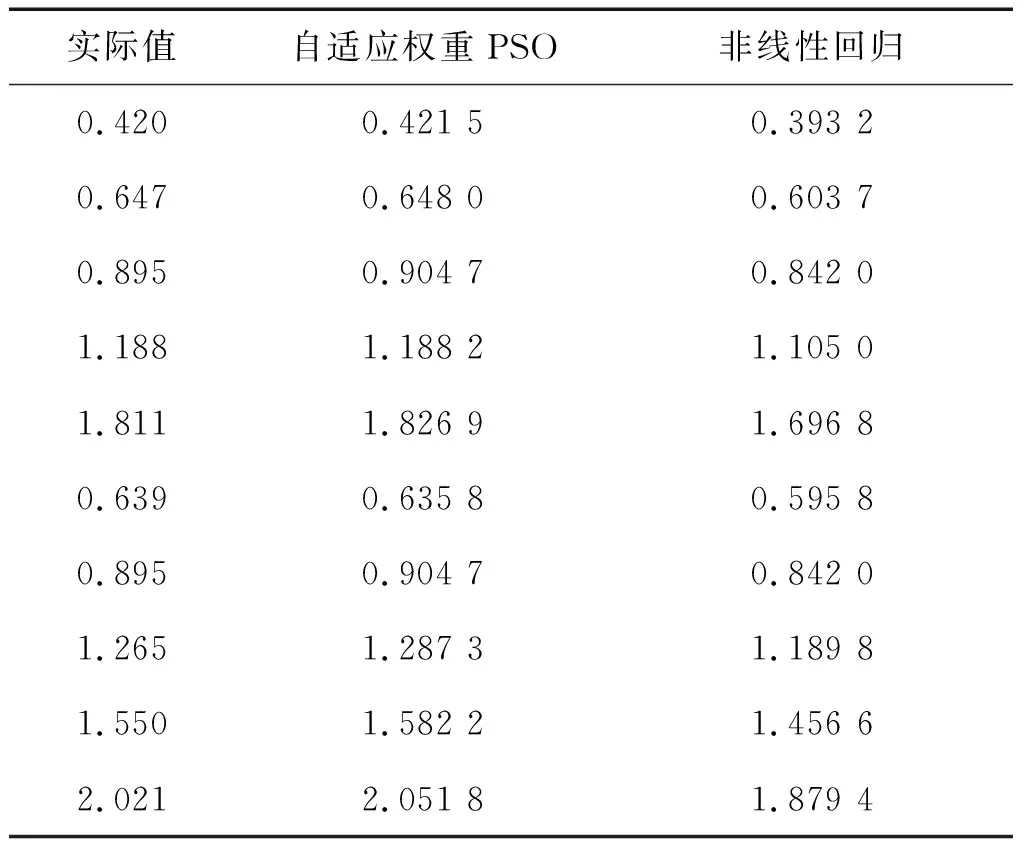
表4 实际值和拟合值Tab.4 Actual values and fitted values
由图2参数辨识图可知,k、n和m在迭代进行到100步左右已经收敛到最优值.采用非线性回归迭代用时0.946 2 s,而自适应权重PSO迭代300步用时仅为0.643 0 s,辨识速度较快.为比较两者的辨识效果,根据表4的拟合值,采用剩余标准差式(11)来衡量辨识的精度.
(11)
非线性回归的模型剩余标准差为0.011 2,而自适应权重PSO的模型剩余标准差为0.002 4.可见,采用自适应权重PSO估计的非线性模型参数具有更好的辨识精度,也进一步证明了该算法的可行性和有效性.
5 结 论
本文将自适应权重PSO算法应用于模型参数估计,并详细介绍了算法实现的步骤和方法.通过对两个实例的仿真研究,证明了该算法在线性模拟参数估计和非线性模型参数估计中均是可行的、有效的.与传统的参数估计算法相比,该算法无论在效率还是精度上均有更好的性能.同时,该算法也为模型参数估计提供了一条新的途径.
参考文献:
[1] 潘立登,潘仰东.系统辨识与建模[M].北京:化学工业出版社,2004:80-91.
[2] 张镇,郑敏.基于过程神经网络时变系统的参数辨识[J].江南大学学报:自然科学版,2008,7(6):637-640.
[3] 袁晓磊,白焰,董玲.基于遗传编程的非线性系统辨识[J].控制工程,2009,16(1):52-55.
[4] 刘长良,姚万业,翟永杰,等.一种改进的遗传算法及其在热工过程控制中的应用[J].自动化仪表,2002,23(9):13-16.
[5] KENNEDY J,EBERHART R C.Particle swarm optimization[C].In:Proc.IEEE international Conference on Neural Networks,1995:1942-1948.
[6] 黄华江.实用化工计算机模拟—MATLAB在化学工程中的应用[M].北京:化学工业出版社,2004:231-233.
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
中华环境(2021年9期)2021-10-14
中华环境(2021年8期)2021-10-13
中华环境(2021年7期)2021-08-14
北京航空航天大学学报(2020年10期)2020-11-14
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
疯狂英语·新悦读(2017年6期)2017-06-24
统计与决策(2017年2期)2017-03-20
小学科学(学生版)(2016年1期)2016-10-09
