
一种基于数据驱动的系统建模方法
2010-11-27 00:57:32邵克勇刘远红
长江大学学报(自科版) 2010年1期
邵克勇,韩 巍,范 欣,刘远红
(大庆石油学院电气信息工程学院,黑龙江 大庆 163318)
一种基于数据驱动的系统建模方法
邵克勇,韩 巍,范 欣,刘远红
(大庆石油学院电气信息工程学院,黑龙江 大庆 163318)
提出了一种基于数据驱动的系统建模方法,采用减法聚类和模糊C-均值聚类相结合的模糊聚类算法进行前件RBF网络辨识,自适应地获得精确的聚类个数和隶属度参数;用BP算法训练后件网络的权值,从而仅利用输入输出数据,就建立了T-S模糊神经网络模型,在该过程中充分利用了BP神经网络和RBF神经网络的优点。最后用该模型对一个非线性系统进行辨识,用MATLAB进行仿真,结果表明,该方法具有可行性。
T-S模型;BP网络;RBF网络;模糊C-均值聚类
基于数据驱动(Data-driven)的控制方法是近年来出现的一种新的控制算法[1],该方法只利用已存储的大量输入输出数据,在线学习计算与当前状态相匹配的控制量,便可获得系统所要求的各种动静态品质。Takagi和Sugeno在1985年提出T-S模型,该模型可以直接从输入输出数据中提取模糊规则和辨识模糊参数[2],由于其缺乏自学习和自适应能力,有学者提出了基于T-S的模糊神经网络[3],将模糊逻辑和神经网络融合在一起,其中BP(back propagation)网络和径向基函数RBF(Radial Basis Function)神经网络目前最为成熟、应用最广泛。BP神经网络是全局逼近网络,可实现从输入到输出的任意复杂的非线性映射,并具有良好的泛化能力,但每一次样本学习都要重新调整网络的所有权值,寻优参数多,因此收敛速度慢。RBF网络是局部逼近的网络,可大大加快学习速度并避免局部极小,满足实时控制的要求,但在训练样本增多时,RBF网络的隐层神经元数远远高于BP网络,这样使得RBF 网络的复杂度大大增加,结构过于庞大。由于模糊聚类算法可以把数据分成多个有意义的子类,这样大大减少了隐层节点数,简化了RBF网络,特别适用于多变量系统。鉴于此,笔者基于数据驱动理论,综合BP和RBF网络的优点,建立了一种新的T-S模糊神经网络。
1 T-S模型描述
首先定义一个多输入多输出系统P(U,Y),U是系统输入,U∈Rm;Y是系统输出,Y∈Rq。针对该系统,可以将其分解成q个MISO系统,第i条规则可写为:
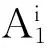
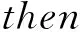
(1)
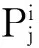
(2)
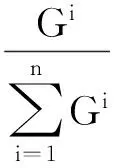
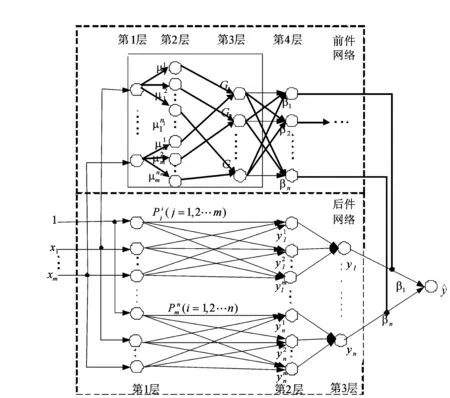
图1 基于T-S模型的模糊神经网络结构
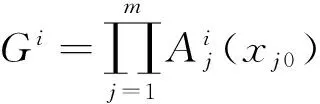
(3)
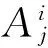
2 T-S模糊神经网络结构
2.1前件网络

第1层为输入层,该层的节点数为N1=m。
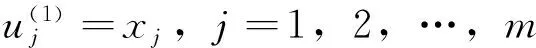
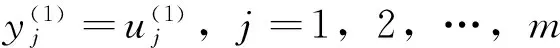
第2层为模糊化层(隶属度函数层),隶属度函数采用高斯函数,该层的节点数为N2=n×m。
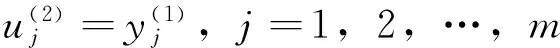
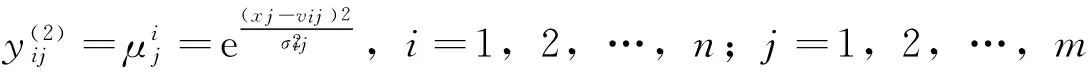

第3层为规则层(RBF的输出层),输出层的权值相当于T-S模型的多项式参数,模糊规则的个数等于RBF网络中心值个数。该层的节点数为N3=n。

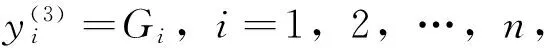
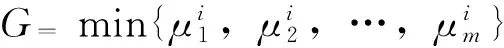
第4层为模糊决策层,该层节点数为N4=n。
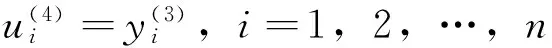
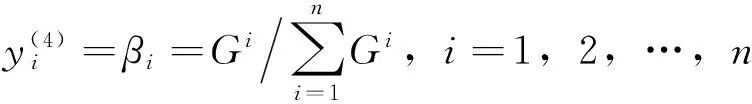
第5层与后件网络的第4层共用。
2.2后件网络
后件网络近似为BP网络,各层作用如下:
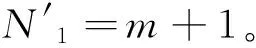
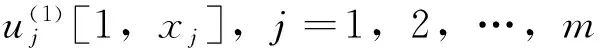
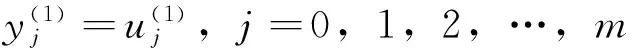
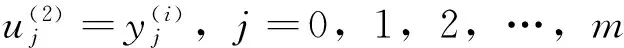
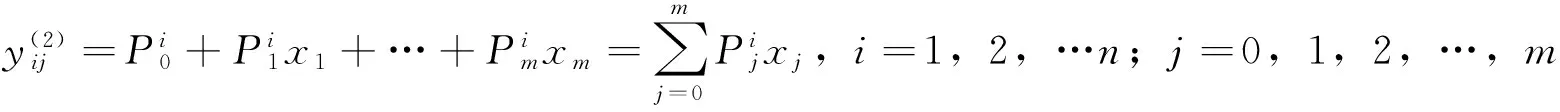


第4层为计算系统的总输出,与前件网络的第5层共用,即:
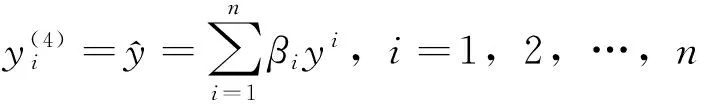
3 学习算法
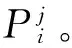
3.1前件网络参数学习
模糊聚类算法包括模糊C-均值聚类算法和减法聚类算法,模糊C-均值聚类算法的优点是用隶属度的方式表征数据点属于某类的程度,但其对初值非常敏感,若在利用模糊C-均值聚类算法前先用减法聚类算法,这样不但可以找到聚类初始中心,还可以根据数据的每一维对聚类中心的影响自动产生较好的聚类个数,不必事先确定聚类个数,而且能收敛到全局最优,提高聚类速度。模糊聚类算法用于RBF网络隶属度函数中心值和宽度的学习。具体的学习过程如下:
1)利用减法聚类确定聚类个数C和初始聚类中心:
①由减法聚类中的定义公式推导,数据点xi处的密度指标定义为:
(4)
常数ra是该点的邻域半径,半径以外的数据点对该点的密度指标贡献甚微。
②取max(Di)所对应的数据点为第一个聚类中心,令xc1为选中的点,Dc1为其密度指标。那么每个数据点xi的密度指标可用公式:
(5)
修正。常数rb定义了一个密度指标函数显著减小的邻域。为避免出现距离很近的聚类中心,一般取rb=1.5ra。修正了每个数据点的密度指标后,选定下一个聚类中心xc2,再次修正数据点所有密度指标。
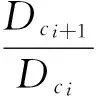
2)用式(6)进行修正,得到最终的聚类中心vk:
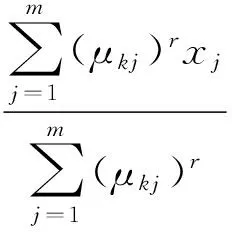
(6)
3)隶属度函数的宽度值σk与其中心值有关,可以通过式(7)计算出来:
(7)
4)用下式修正隶属度矩阵U(l):
(8)
5)用一个矩阵范数‖·‖比较U(l)和U(l+1)。对给定的εgt;0,‖U(l+1)-U(l)‖≤ε则停止迭代,否则取l=l+1,并转向步骤2),最终得到的vk(k=1,2,…,C)、σk分别为RBF网络的基函数的中心和宽度。
3.2后件网络连接权值的学习
BP算法仅需训练后件网络第2层的连接权值。根据梯度下降法[3],权值的学习算法步骤如下:
(9)
从而可得:
(10)
2)取误差代价函数为:
(11)
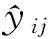


(12)
式中,η为学习速率,η=[0,1]。
则k+1时刻网络的权值为:
(13)
如果步长较小时,在误差曲面较平坦的地区,收敛速度慢;步长较大时,又会引起震荡,附加动量因子γ∈[0,1]是考虑上次变化对本次变化的影响,使参数的调节向着底部的平均方向变化,起到了缓冲平滑的作用,相当于阻尼项,从而加速了收敛,有效的抑制了局部极小。此时的权值为:
(14)
3)返回步骤2)重复,直至误差满足要求为止。
4 仿真及结果分析
为方便比较,选用如下一个经典的非线性系统作为仿真对象:
y(k+1)=g[y(k),y(k-1)]+u(k)
(15)
其中:
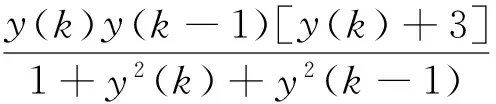
1)产生训练数据。采样时间取1ms,对象的输入信号为u(k)=sin(2πk/30)。在Matlab中进行编程,神经网络的输入为3个,即u(k)、y(k)和y(k-1),可以得到1000组输入输出数据,其中,t∈[0,1],y(0)=0,y(1)=0。
2)用T-S模糊神经网络模型代替非线性函数式(15),仿真时选择迭代次数为100,迭代误差为0.00001,ra=0.4。利用减法聚类算法对所得数据进行聚类,规则组数为6,即采用6个模糊集进行模糊化,再通过模糊C-均值聚类算法求出数据的聚类中心和宽度,构成T-S模糊神经的前件网络结构。
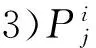
通过仿真计算得到,T-S模糊神经网络模型的均方差为0.00114,常规模糊神经网络模型的均方差为0.0139,可以看出利用模糊聚类训练RBF参数的方法建模精度要高于常规模糊神经网络,即基于数据驱动的建模方法具有很好的逼近能力,能够拟合出系统的输出特性。因此,笔者提出的建模方法计算过程中只有少量的规则参与,辨识参数少,辨识精度比较高。
5 结 论
依据一种基于数据驱动的系统建模思路,提出了一 种新的自动生成模糊系统规则库的设计方法,将BP网络和RBF网络结合,充分利用了BP 网络学习规则简单、有较强的非线性拟合能力和RBF网络训练速度快及不会陷入局部最优的特点。利用减法聚类对模糊C-均值聚类算法进行初始化,确定了模糊C-均值聚类的聚类个数和初始中心位置,这样加快了模型收敛速度,然后进行模糊C-均值聚类,得到RBF网络的中心值和宽度,再利用BP算法得到对T-S模型的后件网络参数,这样仅利用输入输出数据就得到复杂系统的模糊模型。仿真结果表明,T-S模糊神经网络模型计算结果和实际数据误差较小,完全可以满足实际要求,适用于非线性系统的在线辨识。

图2 常规模糊神经网络模型仿真结果 图3 T-S模糊神经网络模型仿真结果
[1]Rhodes C,Morari M,Tsimring L S.Data-based control trajectory planning for nonlinear systems[J].Physical Review E, 1997,6(3): 2398~2406.
[2]Takagi T,Sugeno M.Fuzzy Identification of Systems and its Applications to Modeling and Control[J].IEEE Trans.SMC ,1985,(15):116~132.
[3]丁卫平. 基于BP神经网络改进算法的数据压缩方案[J]. 湖南理工学院学报(自然科学版), 2009,22(4):35~38.
[编辑] 李启栋
TP273
A
1673-1409(2010)01-N063-05
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
电子测试(2017年15期)2017-12-18 07:19:27
自动化学报(2017年7期)2017-04-18 13:41:02
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
智能系统学报(2015年4期)2015-12-27 09:38:39
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
电子设计工程(2015年6期)2015-02-27 12:04:53
